
5
Using Improved Sampling and Other Methods to Reduce Response Burden
The lead-off sessions on the second day of the workshop, according to session chair David Hubble (Westat and member of the steering committee), were designed to lay the foundation for matrix sampling, discuss modeling and imputation associated with matrix sampling, and evaluate the implications of this technique for reducing burden.
CENSUS BUREAU RESEARCH ON MATRIX SAMPLING
Mark Asiala (Census Bureau) focused on a report written by a group of Census Bureau staff who looked at the feasibility of using matrix sampling or other techniques to reduce respondent burden. His discussion covered highlights of the report, options considered, examples of how one might implement these options, statistical challenges identified, and recommendations that came out of that report (U.S. Census Bureau, 2015b). The motivation for the report was to consider means to reduce respondent burden. The review began with consideration of the findings of the Census Bureau’s 2014 content review (U.S. Census Bureau, 2014), which had several phases. The first phase was to justify each question on the American Community Survey (ACS) by looking at the frequency that the estimates for that particular topic were needed, the level of geography that was needed, and the legal justification for the use of that question by the various federal agencies. In essence, he said, the first phase was intended to identify any candidate questions for removal. The second phase, which led to the feasibility study, took the rich database developed for the first phase, which had information on every topic and the frequency it was needed. This phase
assessed whether the questions could be asked of fewer respondents on only a subsample of the forms or if there were other means of reducing burden short of completely removing a question from the form.
The internal Census Bureau team that did the investigation was composed of people from many different areas within the agency, including those with expertise in operational aspects and statistical aspects, as well as subject matter experts who brought their understanding of the data and how they would be tabulated and used. The team developed four different options for the ACS (see Box 5-1).
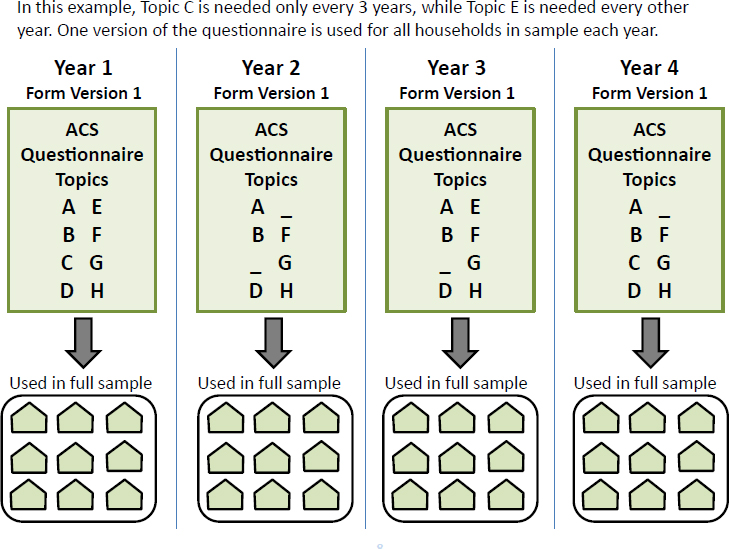
Asiala explained that the first option—periodic inclusion of questions that were not required every year—would mean that questions could be asked some years and not others and thereby burden could be reduced.
Options 2 and 3 were variants of a matrix-sampling approach. Option 2 would target matrix sampling for a small set of questions—those not needed for production of small-area estimates that could be asked less frequently. Option 3 was a more aggressive approach to matrix sampling in which a broad set of questions would appear on only some questionnaires and not on others, yielding more dramatic improvements in reducing respondent burden.
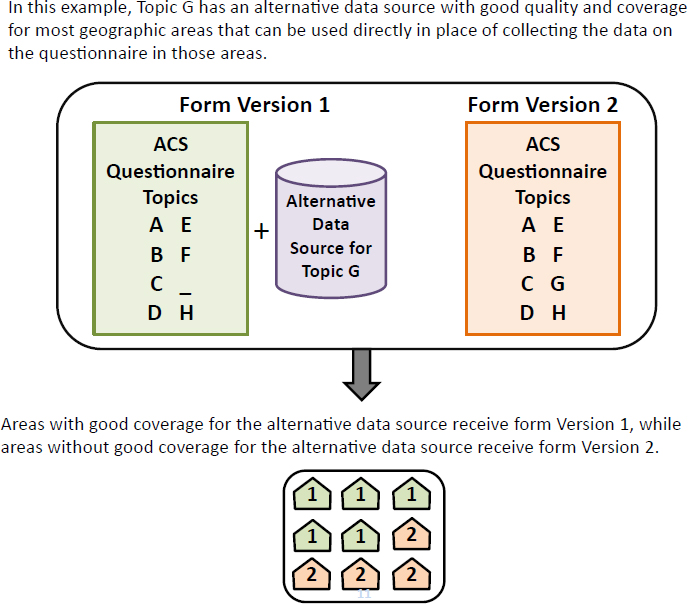
Option 4 was a hybrid approach that would use administrative records to fully substitute for survey data in those areas where the records were
strong. When records coverage was low or the quality did not meet an established threshold, the question would remain on the form.
Two criteria were used to identify the topics considered for options 1 and 2. The first was that there were no required or mandatory uses in the law or case history that required use at the Census tract level, although it could be needed at the county, state, or higher level. The second criterion was that all mandatory or required uses were needed at a frequency that was less often than every year. The team identified topics as potential candidates for the matrix sampling. These topics are subject to further verification with the individual federal agencies, but they provided good examples to consider in a feasibility study.
Asiala laid out each of the options in greater detail, giving examples of how the approaches would be operationalized. The options appear in the following illustrations, shown as Figures 5-1 through 5-4.
SOURCE: Mark Asiala presentation at the Workshop on Respondent Burden in the American Community Survey, March 9, 2016. Available: http://sites.nationalacademies.org/cs/groups/dbassesite/documents/webpage/dbasse_173161.pdf [September 2016].
SOURCE: Mark Asiala presentation at the Workshop on Respondent Burden in the American Community Survey, March 9, 2016. Available: http://sites.nationalacademies.org/cs/groups/dbassesite/documents/webpage/dbasse_173161.pdf [September 2016].
For option 1, in which some questions would be periodically included, a topic could be included in year 1 and year 4 but not in the years in between and another in years 1 and 3, but not 2 and 4. This option would mean that there would be only one form each year. The Census Bureau has experience with switching from one form to a different form by year.
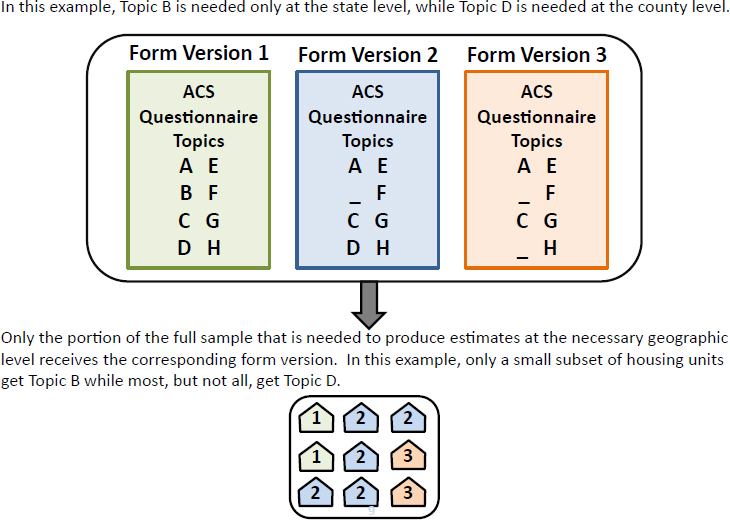
Asiala contrasted this approach with option 2’s targeted approach utilizing multiple questionnaires in a given year. For example, if a topic is needed only for estimates at the state level, it could appear in form version 1 but not in versions 2 and 3. If a topic is needed for estimates at the county level, it could appear on form version 1, which includes all variables, and on version 2, but not version 3. In this option, the frequency with which questions appear on the different forms would be determined by the required reliability needed for the particular topics.
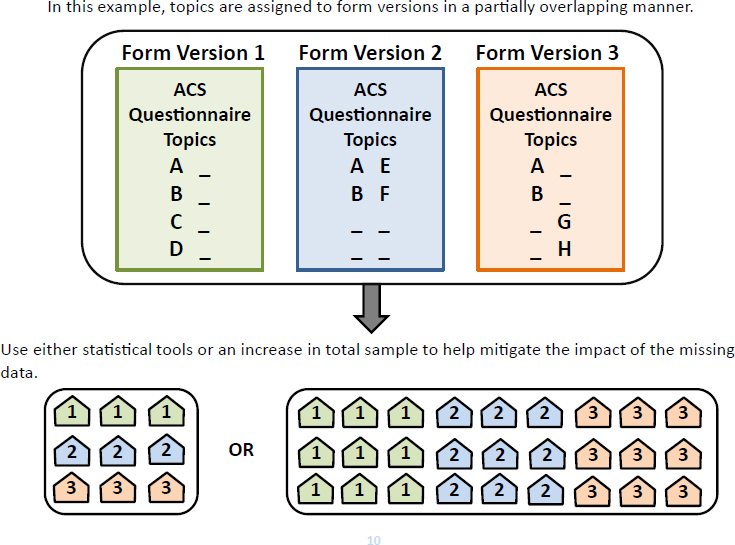
Option 3 takes option 2 further, Asiala stated. Rather than consider-
SOURCE: Mark Asiala presentation at the Workshop on Respondent Burden in the American Community Survey, March 9, 2016. Available: http://sites.nationalacademies.org/cs/groups/dbassesite/documents/webpage/dbasse_173161.pdf [September 2016].
ing a narrow set of topics, all characteristics or all questions would be available for matrix sampling. Option 3 could mean, for example, that only some topics appear on every form, while other topics appear, on only one of three forms. A drawback of this option is some loss in reliability if adjustments were not made. One option could be to use statistical tools to mitigate some of that loss in reliability. Another option would be to expand the initial sample in order to increase the amount of information gathered from respondents about particular topics.
Option 4 is similar in that an alternative data source would be used except in areas with insufficient coverage. In those areas, the traditional form would still be used. If, for example, an allocation shows administrative records could be used for five-ninths of the country and four-ninths would still need the form, the reduction in burden would be nearly half for those questions.
SOURCE: Mark Asiala presentation at the Workshop on Respondent Burden in the American Community Survey, March 9, 2016. Available: http://sites.nationalacademies.org/cs/groups/dbassesite/documents/webpage/dbasse_173161.pdf [September 2016].
Asiala reported that the team adopted a number of criteria to identify the options that were viable candidates for more research. The criteria include operational and processing complexity, statistical complexity, impacts on reliability and accuracy of the data, data availability, the richness of the resulting data products, and a nominal sense of the expense of an option. The ratings—high, medium, and low—were based upon the team’s professional judgment, taking into consideration operational, statistical, and subject matter considerations.
He reported that the challenges of option 1 were mainly operational, but changing from one form to another already happens in the ACS on a regular basis and this option would perhaps make it more regular. The team concluded that this option applied only to a small set of topics and,
for that set of topics, the changes could be instituted comparatively easily in contrast to the other options.
The team also concluded that for the administrative records option (option 4), there were a lot of topics for which administrative records could potentially be used so the potential for burden reduction is significant. However, in order to select this option, much groundwork to investigate the quality of those administrative record sources and the appropriateness of the use of those administrative record sources would be needed. This option is something that the Census Bureau should continue to explore, Asiala said.
The key challenge identified for matrix sampling is that there will be holes in the data in cases where a question is not asked and there is no response. It would be possible to do cross-tabulations in the traditional sense of using only data from respondents who were asked all questions involved in the cross-tab, but using data only from this limited population would result in considerable loss in precision in the estimates, he said. The team supported creating a complete microdata file unless some other statistical means for accomplishing cross-tabulations would be feasible. If the Census Bureau does not create a complete microdata file, this would introduce concerns about the user friendliness of the public-use file. On the other hand, constructing a complete file introduces issues with the techniques for imputing the missing data. The issues include how to deal with the potential loss of precision of the estimates, the tools that could be used to mitigate some of that loss, and, since the ACS publishes a margin of error for every estimate, how to properly reflect that variance due to imputation in the variance estimates published.
Asiala reported the results of a literature review to find examples of other large demographic surveys that use matrix sampling and to identify statistical methods that such surveys use in their implementation. The team found a number of simulation studies and proposals for matrix sampling for particular surveys. These studies generally concluded that matrix sampling could be done with relatively low impact on bias and that it was possible to mitigate a certain amount of the reliability impact. However, the team did not find any good examples of surveys using matrix sampling in ways applicable to the ACS.
The literature search also considered estimation approaches that relied on imputation techniques to fill in holes, including both multiple imputation (Raghunathan and Grizzle, 1995; Thomas et al., 2006) and hot deck techniques (Gonzalez and Eltinge, 2007). In addition, literature discussing best linear unbiased estimators (Chipperfield et al., 2013) and generalized regression (Merkouris, 2015) was reviewed. One takeaway was that the papers stressed the importance of optimizing how topics are grouped by the different forms that get used in the matrix sampling. Asiala concluded
that grouping has a substantial impact on the efficiency or the productivity of these various methods.
The team’s empirical explorations were geared primarily toward option 2 (targeted matrix sampling) with the aim to identify the amount that a subsample reduces burden for topics that do not need tract-level detail. To test the effect of subsampling, the team started with the nine topics identified, five of which were required only at the state level and four at the county level. The team then estimated the potential reduction in sample for the target geography and a target coefficient of variation (CV), concluding that the extent to which a topic could be subsampled depends on its prevalence and the geography.
Using a target CV of 10 percent for a state-level estimate (generally considered to be reasonable), the team could achieve a subsampling rate on average across the country of only about 25 percent for low-prevalence items. However, for high-prevalence items, the team achieved substantial reductions—the equivalent of a 1 in 20 sample or a 95 percent reduction for those higher-prevalence items.
At the county level, the team looked at target CVs of 10 percent, 20 percent, and 30 percent. The research confirmed that some counties currently do not have a CV of 20 percent for the tested characteristic so subsampling is not possible for that group. However, larger counties can be subsampled, and a reduction of about 60 percent could be achieved.
From this Census Bureau research project came a number of specific recommendations, which Asiala summarized as follows: (1) implement Periodic Inclusion (option 1) wherever possible given relatively low operational and statistical complexity; (2) assess administrative record sources (option 4) that could be used to partially remove questions from the form, recognizing that this option could translate to significant reductions in burden with relatively few undesirable impacts; and (3) for matrix sampling (options 2 and 3), recognize that there are potentially large impacts on costs and also negative impacts on accuracy and richness of survey estimates, and that the ACS would seek input to help develop research into efficient and effective designs for use of matrix sampling.
UTILIZING MATRIX SAMPLING TO REDUCE RESPONDENT BURDEN
Two discussants, Jeff Gonzalez (Bureau of Labor Statistics) and Steve Heeringa (University of Michigan), followed Asiala’s presentation on Census Bureau research on matrix sampling.
Gonzalez said he would take a broad perspective on utilizing matrix sampling to reduce respondent burden, provide a definition of matrix sampling, discuss the design of matrix samples, identify implications of simple
matrix-sampling designs, suggest design features that should be considered in conjunction with matrix sampling to achieve further reductions in burden, and highlight statistical and operational considerations when implementing a matrix-sampling design.
He said the motivation for matrix sampling comes from a body of literature on survey methodology that suggests that high respondent burden, low survey response rates, and questionable data quality may each be associated with lengthy surveys. One possible solution to address issues related to burden while improving data quality and nonresponse properties of the survey is to administer a reduced-length questionnaire. However, it is difficult to eliminate questions from the original questionnaire because stakeholder needs vary and rarely are there expendable questions on surveys. This has led the ACS to consider the possibility of dividing the lengthy ACS questionnaire into subsets of questions and then administering each subset to subsamples of the full sample. This is referred to as matrix sampling, he explained, but it is also referred to as a split questionnaire design—these designs ensure that every question is administered to at least some portion of the sample.
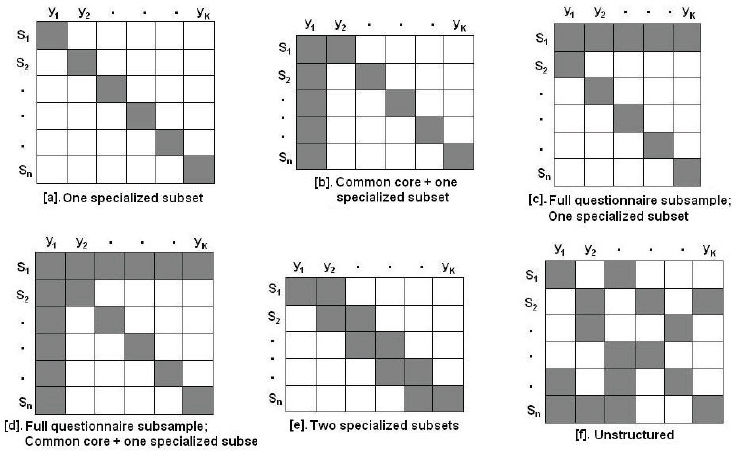
Gonzalez offered several illustrative examples of matrix-sampling design, each with special features to consider when meeting various survey objectives. In the six designs in Figure 5-5, the shaded square represents collected data; the open squares represent data missing by design. The rows denoted by Sn represent subsamples of the full sample, while the columns denoted by Yk represent a specialized subset of questions.
The subset (a) at the top row, left position, represents a matrix-sampling design in which each subset of the full sample receives one specialized subset. Gonzalez stated that this design is adequate for estimating univariate statistics from the portion of the sample that receives that specialized subset, but is unlikely to satisfy the complex data requirements for the ACS. The subset (d) has the specialized subset feature with two additional features—a full questionnaire subsample, which is a portion of the sample that receives the full body of questions, and a common core set of questions that every sample member receives. This design, according to Gonzalez, could satisfy a broad range of data products for the ACS. He discussed other options, including subset (f), which depicts a completely unstructured matrix sample design in which the subsets vary dramatically by the sample members.
While the literature suggests that matrix-sampling designs can improve the overall quality of a survey and perhaps reduce burden, he observed, there are potential disadvantages of implementing these types of designs. First, there is a loss of information obtained in the survey by creating incomplete or missing data by implementing these types of designs. There is also the potential to introduce additional sources of variation such as measurement errors due to context effects. In addition, there is a reduction
SOURCE: Jeffrey Gonzalez presentation at the Workshop on Respondent Burden in the American Community Survey, March 9, 2016. Available: http://sites.nationalacademies.org/cs/groups/dbassesite/documents/webpage/dbasse_173170.pdf [September 2016].
in the precision of estimates from those questions that are matrix sampled. Finally, survey operations are more complicated and case management systems must be modified in order to keep track of the various forms.
Balanced against these disadvantages, Gonzalez referred to work on matrix sampling or split questionnaire designs by Chipperfield and Steel (2012) that identifies three key benefits: (1) sample size requirements to meet survey objectives often differ by survey items, so it makes intuitive sense to allow that difference in survey data collection procedures; (2) leveraging information can enhance design and analysis; and (3) reducing the length of questionnaire through matrix sampling has the potential to reduce burden.
Gonzalez then turned to a further definition of burden in order to assist in exploring how matrix-sampling designs can be utilized to reduce respondent burden. As discussed earlier in the workshop, burden is a perception of the respondent. It is multidimensional in that it concerns not only length of the survey, but also other factors, such as the effort required to respond to the questions, the difficulty of the questions, the sensitivity of the questions, and the frequency of being contacted.
With that background, Gonzalez discussed how matrix-sampling designs can be used to reduce respondent burden. The key question is, given this multidimensionality of respondent burden, how can the Census Bureau or other national statistical organizations design matrix-sampling forms to reduce respondent burden? How can the impact in terms of burden reduction be measured? He observed that simple implementations of how matrix sampling reduces burden can be measured via objective criteria, such as the number of questions or the length of the interview, but, he asked, how are the other dimensions measured? He posited that three substantive issues arise when addressing other dimensions of burden: (1) how to allocate survey items to forms and then forms to subsamples of the full sample so as to improve on those other dimensions of respondent burden; (2) what additional design features to combine with matrix sampling to achieve further reductions in burden; and (3) the extent, if any, that burden reduction affects quality and precision.
With respect to the first issue, the typical design of a matrix sample is such that survey items are allocated to forms and then randomly distributed on those forms to subsamples of the full sample. Previous research has tested various allocations of items to forms, including random allocation. The research has assigned questions to matrix-sampling forms without regard to any characteristics of the questions, permitting item stratification methods or correlation-based methods in which highly correlated items are placed on different forms to be employed. Gonzalez stated the literature suggests that the ability to address dimensions of respondent burden other than length can be affected by this allocation process. For example, employing a technique like item stratification can ensure that forms are balanced with respect to stratification classes where the strata are formed by sensitivity, effort, or difficulty.
Furthermore, Gonzalez said, the greatest impact on burden reduction may not be achieved with random distribution of forms to subsample members because auxiliary information about the sample unit is often ignored. Since the ACS collects information from heterogeneous target populations, the survey methods literature concludes that collecting information on heterogeneous target populations from standardized instruments may be suboptimal. Incorporating auxiliary information about sample units in the ACS can have positive effects on data quality and burden reduction.
Gonzalez said a second implication of the typical design is that matrix samples are ineffective for rare-event items and small geographic or other domains, often because to obtain information for rare items or small geographic domains, questions are added to the set of questions that every sample member receives. If there are no questions eliminated from the original questionnaire, there is no reduction in burden.
In order to achieve better outcomes with respect to respondent burden,
Gonzalez advocates the use of combining or other design features in conjunction with matrix sampling. The other design features include responsive or adaptive designs. They are analogous to multiphase designs and require midcourse design decisions and unit-level survey changes based on the accumulating process in survey data. The basic motivation for considering these designs is that the decisions are intended to improve the cost and error properties of the resulting statistics. In the context of the ACS, the multiple phases are the follow-up procedures of initial or soft refusals.
He stressed that adaptive design decisions require the availability of useful auxiliary information, an understanding of how that auxiliary information can be modeled to determine the best type of matrix-sampling design, and knowledge about how to combine the multiple phases of data collection to produce desired estimates. These topics are being actively researched. He added that an adaptive or a responsive design in conjunction with a matrix-sampling design has the potential to tailor the interviewing experience to the sample unit in a manner that may increase motivation with the survey request. The theory is that this method would elicit more thoughtful and thorough responses from the respondent. Furthermore, by incorporating auxiliary information, it may be possible to mitigate frustration or concerns of inconvenience when respondents feel that they have been contacted too many times or have spent too much time on the response task.
The second design option under consideration involves the integration of data sources, which would comingle ACS or other survey data with information provided in other data sources such as administrative records, other surveys, or organic data sources to either replace, edit, impute, or use in estimation in some way. The motivation for considering these methods is similar to that of matrix sampling, that is, to reduce respondent burden, improve some dimension of data quality, and yield some cost savings. There are, however, concerns with integrating data sources dealing with access to or capturing those alternative data sources, quality, and the ability to link the alternative data sources to the ACS data. Although there may be concerns with privacy in the use of administrative records, Gonzalez observed, respondents already think government agencies share information. Also, when a respondent provides consent to link to the survey data, the respondent benefits from the reduced perceived time spent completing the survey request.
Gonzalez cautioned about additional statistical and operational concerns to consider when deciding to implement matrix-sampling designs. Matrix design introduces data collection issues because, as the number of matrix-sampling forms increases, data collection management gets more complicated. Modification of processing systems is required to keep track of completion rates by forms. Also, each form may have a differential error
property, and there might be differential error properties of the same forms across different modes of data collection that are used in the follow-up procedures as well.
A second set of issues deals with response tasks or cognitive issues, he said. There may be context effects in that responses to questions can be affected by prior items administered in the questionnaire, which may provide cognitive cues to the respondent.
A final set of issues relates to data production and analysis, he said. Implementation of a matrix-sampling design will require modifications to the data processing systems no matter whether imputation, weighting, or modeling is used, and it will require a large investment to modify the current systems. The key point is that as the number of forms increases, processing complexity increases and missing data patterns arise.
In conclusion, Gonzalez stressed tradeoffs among burden reduction, total survey quality, and costs. He suggested several high-priority questions for an expert panel to consider when deciding on implementing a matrix-sampling design for the ACS. The first is the meaning of burden reduction—remembering that burden is not simply the length of the questionnaire but includes other dimensions such as sensitivity of questions and difficulty of the response task. The second question relates to the additional design features that should be considered in conjunction with matrix sampling to achieve greater reductions in burden and improve overall survey quality and maintain or reduce survey costs. These include responsive designs and integrating data sources, but there are other features that could be considered with matrix sampling. The third question relates to how the existing ACS data, either survey data or paradata, can be used to inform the matrix-design process. Decisions must be made about allocating survey items to forms and distributing those forms to subsamples of the full sample, modifying the design to account for soft or initial refusals, modifying the matrix-sampling design to account for those soft refusals, and developing criteria to evaluate the new design features.
PLANNED “MISSINGNESS” DESIGNS AND THE ACS
Heeringa focused on planned “missingness” designs, a term he said he prefers to define a broad class of designs that includes matrix samples as a special case. He stated he would cover burden and information needs in the ACS; research-based results, empirical findings, and common-sense observations on planned missingness data designs; four options for incorporating planned missingness or matrix sampling in the ACS; and methodological and empirical issues that are involved.
He explained that the burden of the ACS can be classified as individual respondent burden, aggregate sample burden, system (data producer)
burden, and data user burden. Each of these types of burden is driven by information needs, which are, in turn, defined by time, content, and spatial and other domains of analysis, such as subpopulations. Each of these information drivers can be collapsed to reduce burden. For example, the ACS produces data on tracts and on block groups only once every 5 years and develops annual estimates only for areas with a population above 65,000. Linking the drivers to matrix-design issues, he observed that the ACS is already a matrix design over space and time.
He pointed out that the literature discusses three major approaches to design—multiphase sampling, split questionnaire design, and a hybrid of the two. Multiphase sampling was proposed by Navarro and Griffin (1993), who examined potential uses of matrix sampling and related techniques in the 2000 census, and has been enhanced by combination with small-area estimations (Gonzalez and Eltinge, 2010). The 1970 census had this type of a design with a 15 percent sample (Form 2 items) and a nested 5 percent sample (Form 1) of households completing the larger set of questions in addition to the Census short form, and it has proven quite effective over the years. Other examples are the National Health and Nutrition Survey and the National Comorbidity Survey Replication.
The split questionnaire design (SQD) is a pure matrix-sampling design and is usually exemplified by a set of core questions and then modular components. In contrast to the multiphase design, which creates a monotonic missing data problem, the SQD creates a generalized missing data problem. In Heeringa’s assessment, the SQD works in surveys and measurement settings where there are many measures that can be modularized into correlated sets of items or blocks of items; for this reason, it is often used in educational testing or educational measurement.
Heeringa concluded that the SQD works when the full survey process is designed for a split questionnaire design or redesigned from the ground up. He referred to a research project for the National Children’s Study to determine whether matrix sampling might be a solution to the study’s serious problem of cost and complexity. The conclusion of that study was that a split questionnaire design or a split measurement design was not feasible because the survey already had built a large infrastructure, large expectations, and a large interest in diverse sets of items.
He further emphasized that split questionnaire designs work best when there are descriptive and predominately univariate estimation problems. He referred to a research project to develop norms for tests in the president’s physical fitness testing program (President’s Council on Physical Fitness and Sports, 1985). The challenge was that kinesiologists were changing the set of tests that children were taking from one period to the next, so the research had to set norms for new activities as well as calibrate them with the old for a long list of activities. The data were collected in a national
probability sample of classes and schools. The solution was to break the tests into three modules and assign each child or each classroom two of these modules. The method yielded distributions for each test on two-thirds of the sample, and correlations between modules based on two-thirds of the sample if the tests were in the same module and in one-third of the sample if in different modules. According to Heeringa, the method was successful because it started from the ground up and involved a simple set of measures that were correlated and could be modularized.
He offered three suggestions for estimation and inference for planned missingness designs:
- Full measurement on a subsample of the entire sample strengthens the precision of estimates and the coverage properties of the intervals because it yields a training set of data to inform the full multivariate relationships among the variables. While it does not reduce the burden for the people who have to complete the full set, it does reduce aggregate burden and improves statistical precision.
- Core content should always be included for all individuals as opposed to simply having random modules assigned to individuals.
- Regardless of the strategies—multiple imputation, EM, or FIMI estimation—the fraction of missing information will be smallest when the modularized content has high correlations between the modules and heterogeneity within the modules.
Heeringa offered a series of ways that a planned missingness approach could help the ACS. He supported the periodic inclusion of questions (option 1 as described by Asiala) because the ACS program has experience with questionnaire changes at the start of the year. Under this option, he proposed annual estimates based on 1 year of data for the nation, states, and places of 65,000 population and over, and that for those periodic annual estimates, standard weighting and estimation would apply. He proposed an alternative approach to the current practice of collapsing over time (i.e., 5 years) to support spatial estimates by introducing a 5-year rotation of annual topical modules, noting that collapsing over time (i.e., 5 years) yields a five-module split questionnaire design. He did not support split questionnaire designs on an annual basis because the analysis would be very complex. His recommendation was to modularize by year and treat the 5-year interval as a split questionnaire design.
Heeringa also addressed a series of methodological and empirical issues in applying planned missingness in the ACS. It is important, he said, to be mindful that too much modularization may lead to unanticipated context effects in the questions. The planned missingness approach would require
the Census Bureau to optimize and streamline processing all through the data handling, data acquisition, form assignment, imputation, and weighting steps. The estimation step would be enhanced by utilizing composite estimation and other small-area estimation methods that borrow strength by blending small-area model-based estimates with direct survey estimates. Other survey aspects, such as cross-tabulations, would require rethinking, and custom tabulation systems for geographic units would need to be developed. Finally, ACS products such as Public Use Microdata Samples (PUMS) and analytic datasets would need attention, and the Census Bureau may wish to consider implementing a user-managed approach to the planned missing data.
GENERAL DISCUSSION
Workshop steering committee cochair Joseph Salvo observed that the 1970 census started from a strong base—the long form had a substantial sample with items asked of 5, 15, and 20 percent samples. The ACS starts from a different point. Its small-area data samples at the tract and blocked group levels have high levels of sampling variability. In his view, introducing a split questionnaire could affect the quality of the small-area estimates. Heeringa replied that small-area estimates are important. He summarized recent experience with using models to improve estimates of the foreign-born population by tract level. He said the results were encouraging: the estimates of the foreign-born after 1990 for every block group when summed to the tract level matched very well (within the limits of sampling error already imposed on these block group level estimates). This approach borrowed strength from relationships that had been measured more accurately at a higher level and assumed that those relationships held with appropriate covariate control.
A participant with experience in matrix sampling in an education application observed that the primary strength of this methodology is that measuring education proficiency in math, science, and other subjects yields a list of items, not a single item like the ACS. The ACS is interested in individual variables, not necessarily a summary level. The education context may not be necessarily compatible with the ACS context. Asiala responded that the real power of the ACS comes from cross-tabulations and looking at the relationships among variables.
MODELING AND IMPUTATION
This session, chaired by John Eltinge (Bureau of Labor Statistics) featured presentations and discussion on modeling and imputation and on maximum likelihood approaches to compensating for missing data.
Modeling and Imputation Discussion
Michael Brick (Westat) continued the discussion on matrix sampling, noting the process has been used in many educational settings. An early childhood longitudinal study uses matrix sampling, in that it samples from items associated with cognitive abilities and math abilities to produce a score for the child. Those scores are correlated with other individual characteristics in order to assess progress over time at the individual level. This is a very different type of setting from the ACS, he noted.
He also observed that the length of the questionnaire has been used as a measure of burden for a long time, but it is not the right measure. The right measure is what respondents feel about what they have just been put through, but that is a hard thing to measure. Thus, measuring length becomes the usual metric.
He made several suggestions regarding practical implications of improving sampling and estimation processes with a missingness design for the ACS:
- The design processes should be simple. Any changes will fail if users are not satisfied, he asserted. Most users want to get a table about their area, and they want to run it and be able to present it clearly. If it is not simple, the ACS will not be used as often as it currently is being used. For example, because mass imputation is associated with any type of missingness design—whether multiple imputation, fractional imputation, or hot deck imputation—there is a risk of misleading readers about how much information is associated with those data. The casual user who produces tables and cross-tabulations may have difficulty, he said. The way around this is to plan the analysis and impute for the planned analysis, which takes a sophisticated user. As it is, sophisticated users need more ability to get to the data and use them in a reasonable way.
- The analysis should be consistent with changes in the data collection procedure. Brick advocated for coordination between design and analysis, although he acknowledged the difficulty because the ACS has been conducted in much the same way for so long. Some changes will call for starting again with new systems that are appropriate to the new design, rather than trying to tweak the old systems. The data files must be restructured as well, he said.
- Only data collected on the ACS form should be labeled ACS data. Administrative data should clearly be labeled as such, and he stressed that linked data are not ACS data. This is needed because the quality of administrative data will change over time and space as organizations that collect and process the data change. An example of how to treat non-ACS data is the phone-service item. Many
commercial organizations produce data on phone service, and Census Bureau analysis makes clear that the commercial data are not the same as the ACS data. Imputing or substituting the commercial data for the ACS could be misleading and would not, in the end, reduce burden. However, administrative data have a huge role in imputation of ACS data, and the Census Bureau needs to allow users to link the administrative data in an easy way.
Matrix Sampling, Maximum Likelihood Approaches, and Multiple Imputation
Paul Biemer (RTI International) began his discussion with reference to the National Longitudinal Survey of Adolescent to Adult Health (Add Health), for which he serves as one of the statistical directors. When the survey converted from personal interviews to Web and mail collection, there was consideration of breaking up the questionnaire like a matrix sample. The program decided against developing a matrix sample due to the fact that it is a longitudinal survey and the matrix sample would create missing variables on the last wave and increased complexity. The Add Health solution was to break the questionnaire into two parts and treat them sequentially. This fall the program will experiment with that approach, testing the full questionnaire versus two modules given to the respondents sequentially, with incentives to complete both.
Instead of matrix sampling, Biemer suggested other options. For example, the Census Bureau might consider multiple imputation. However, since analytic results from multiple imputation may be affected by the imputation model, he posited using a full information maximum likelihood (FIML) approach. He said that this approach is an alternative to imputation because it compensates for missing data; however, it does not replace missing values with imputed data. The records containing missing values are retained for the analysis by putting the missing data mechanism in as part of the likelihood for the data analysis model. He stated that Mplus users (and users of a package called Latent Gold) are used to dealing with these multiple equation models, and the missing data mechanism model would just be another variation.
Biemer listed four advantages with using FIML in the modeling: (1) the method does not fill in missing items but adjusts the estimates; (2) it is more efficient than multiple imputation to which it is theoretically equivalent; (3) because it is a maximum likelihood approach, the standard errors are correct; and (4) it solves the problem of how to impute for a categorical variable. However, the method also has a disadvantage in that it assumes a probability distribution (because it is a likelihood approach). While that characteristic is not a problem when dealing with categorical data because
multinomial distributions are usually assumed and those assumptions are not difficult to satisfy, for continuous outcomes it is necessary to assume normality. Another disadvantage, he said, is that it becomes a more complex type of modeling if more complex missing data mechanisms are used. The missingness might depend upon some variables in the core, or it could be some variables in the modules themselves.
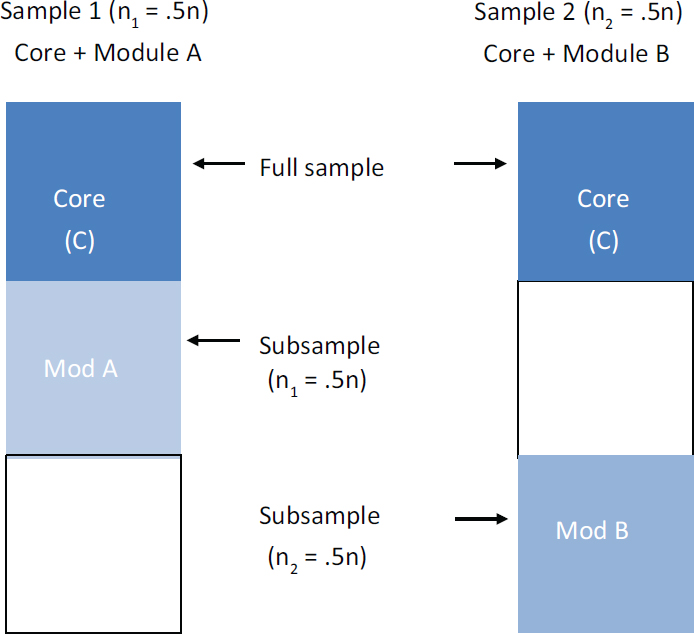
He then laid out a simulation of maximum likelihood methodology in practice (see Figure 5-6). The simulation contained two questionnaires, both with a set of core variables and a module and two samples.
For each of the modules, only half the sample is available. For the core, a full sample is available. By modeling this with the FIML approach, it is possible to take advantage of the correlations between the core in module A and the core in module B to create point estimates that have better precision. Likewise, correlations between A and B can boost the precision of the estimates from module A.
Biemer continued his simulation to develop two subtables, crossing C (an item from the core that is given to 100 percent of the sample) with A (an item from module A) and B (an item from module B), as depicted in Figure 5-7.
In the absence of information on A × B, it is not possible to produce that subtable, but the subtable can be obtained by cross-classification information through FIML. The cell numbers would be estimates based upon a model, and how good they are depends upon how well the model fits. The notation in this table is unweighted, but weights can be inserted using packages such as Mplus, Latent Gold, or, as Biemer used, LEM.
Biemer described how this works in notation (see Figure 5-8). Based on an approach developed by Robert Fay, indicators are defined—two indicators for the missingness, one for module A and one for module B, column R and S (Fay, 1984).
In Figure 5-8, R and S are response indicators for A and B, respectively, where RS = 12 denotes table CA, RS = 21 denotes CB. Biemer uses log-linear path models to specify relationships among C, A, B, R, and S. The response mechanisms that are assumed depend on the model assumed for R and S—either an assumption that the response indicators R and S are related to the core (a missing at random assumption) or an assumption that they are related to some missing variable like A or B (a not missing at random, ignorable nonresponse). In this methodology, both ignorable and nonignorable response mechanisms can be estimated. He noted that matrix sampling, on the other hand, is primarily concerned with ignorable (missing at random) response mechanisms.
In matrix sampling, the data are missing completely at random, in which case R and S are related to anything except each other or, in worst case, missing at random where R and S might be related to some variable
SOURCE: Paul Biemer presentation at the Workshop on Respondent Burden in the American Community Survey, March 9, 2016. Available: http://sites.nationalacademies.org/cs/groups/dbassesite/documents/webpage/dbasse_173165.pdf [September 2016].
in the core because, depending upon a response in the core, the ACS might decide to ask some questions in module A or module B. He also asserted that precision of the model could be enhanced by involving other variables that might be correlated.
Biemer stated he is using FIML in analyzing the National Crime Victimization Survey—a panel survey with significant missingness. If complete case analysis were used, a huge number of cases would be discarded in the analysis. Based on this experience, he urged the Census Bureau to explore FIML, stating it is a viable approach for interval and model estimation and matrix sampling and is an alternative to multiple imputation methods. The standard errors are asymptotically equivalent for FIML and multiple

SOURCE: Paul Biemer presentation at the Workshop on Respondent Burden in the American Community Survey, March 9, 2016. Available: http://sites.nationalacademies.org/cs/groups/dbassesite/documents/webpage/dbasse_173165.pdf [September 2016].
imputation, and with FIML, it is possible to boost precision by bringing in the correlates, even those that are on separate modules. The downside, he said, is that the Census Bureau would need to write its own software or use specialized software like Mplus or Latent Gold. He noted that other software packages are now coming online with FIML procedures.
DISCUSSION
Colm O’Muircheartaigh (NORC at the University of Chicago) commented on an agenda for the next year or two—actions that are necessary for the ACS moving forward. The undertaking will be complicated, he said. If the goal is to produce estimates of one variable at a time, there is no need to intercorrelate variables, and various split questionnaire designs will work adequately in many cases. On the other hand, he said taking associations among all possible pairs requires more complicated designs. He referred to the experience of the redesign of the Add Health survey, for which he served
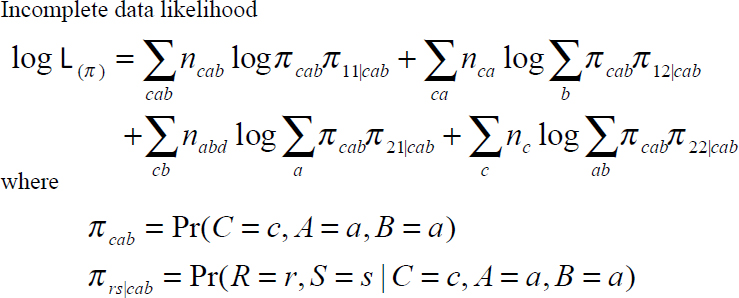
SOURCE: Paul Biemer presentation at the Workshop on Respondent Burden in the American Community Survey, March 9, 2016. Available: http://sites.nationalacademies.org/cs/groups/dbassesite/documents/webpage/dbasse_173165.pdf [September 2016].
on the board of advisers. The field operation for that survey had become so large that it was impossible to collect all the data for all of the respondents. It was decided to drop some modules rather than split the sample, because Add Health is a longitudinal study and modularizing causes a loss of the longitudinal benefits and complicates analysis.
In order to appropriately design an approach to reducing burden, he urged the Census Bureau to consider a series of questions: What does the agency want to collect about the population over this period of time? Who are the clients? What are the statutory obligations? What are the user stakeholder obligations? What data should be collected? Is it appropriate to take an equal probability sample across the whole country? For example, designing for reliable data for every county, most of which have a very small fraction of the population, results in unnecessarily large samples in counties with larger populations. Is it appropriate to use the same sampling fraction for New York as for a rural county in Idaho?
He stated, in thinking about burden, the metric should be aggregate burden—the total effort caused to the sample by collecting the data. The largest savings in burden could come by reducing the number of respondents, so he urged a rethinking of the need for the size of sample by area. He suggested a “thought experiment” for the leadership at the Census Bureau to consider how to design an ACS by starting with the proposition that it needs to collect data about certain things for certain people for certain uses.
Heeringa commented on the presentations in this session. First, he agreed that the FIML method is a good exploratory tool, particularly for tabular data in which the inputs are categorized, even age distributions or groups. The method provides an indication of the ability to recover information or conversely the fraction of missing information from these sorts of planned missing data designs.
He also noted mass imputation, which was created by Donald Rubin to permit imputation of rectangularized datasets because software could not handle anything but complete data, would strike out cases with any missing data (Rubin, 1987). He observed that software today allows imputation directly in the analysis stream. If there is planned missingness, at least for the analytic uses within the census and by research users, he said he would provide the data in its missing data structure (and user guides) and then allow people to use the available software to construct their analysis. In making his recommendation, he noted that hierarchical consistency is desirable and in some cases necessary—block group totals should add to tract totals, which should add to county totals and then to state totals.
Biemer added that the National Survey of Drug Use and Health uses imputation for missing items, but the large number of items on the survey means not all are imputed. For those items that are not imputed, FIML is an alternative to prevent throwing out cases with missing data. It is possible to do mass imputation but leave open the option for FIML, he said.
Asiala stated that the sample design reflects, in part, the inherited practice from the decennial census long form for a sequence of adding more sampling rates over time. In 1990, there were three sampling rates, which grew to four sampling rates in 2000. The ACS has had five sampling rates, ranging from around 1.8 percent at the lowest up to 10 percent. As part of the 2011 reallocation of the ACS sample, the total number of sampling strata was increased to 16. The rates now vary from 0.5 percent per year for the largest tracts up to 15 percent for the smallest jurisdictions.
He reported consistency in data products is ensured by (1) a practice that, for all the tabulated data products, disclosure avoidance and any necessary data swapping occur prior to weighting the data, and (2) direct estimates are made from a weighted dataset. In this way, at any level of nested geography, by design there will be consistency all the way through.
Mathiowetz commented about matrix sampling and its relation to overall burden. One of the measures of burden is the length of the questionnaire and the number of contacts or interactions with the Census Bureau to process it. This measure would suggest that the people at the very tail end who have been asked to answer by Internet, by mail, by phone, and finally by face-to-face interview have the largest amount of burden. With matrix sampling and planned missingness, some of those people would have responded in total to the original full request. Perhaps rather than doing
planned missingness, she suggested, the Census Bureau should consider a nonresponse questionnaire for those who are in the process toward the end. This practice would reduce the amount of information for those who have had multiple contacts and would link matrix sampling with a responsive design for nonresponse.
Heeringa and O’Muircheartaigh concurred that the idea is promising. The difference from the matrix sampling discussed earlier is that immediately a burden propensity is inserted into the process to produce an estimate. In addition, different sequences of methodology in terms of contacting respondents are worth considering. There are cost implications that should be considered as well, so this would be a major stakeholder issue for the ACS.
Brick observed that the literature on the length of the questionnaire suggests that only drastic changes would significantly affect burden. This is an important research question, he said. The experience at NORC, reported O’Muircheartaigh, has been that repeated phone calls seem to be what cause the most aggravation. Respondents do not mind as much if an interviewer shows up frequently because at least the survey is investing some effort.
A participant asked about how to identify where the burden is in the questionnaire. Understanding the source of the burden requires a focus on the ACS instrument itself. The participant opined that the instrument itself places a different burden on different people because it is not a static instrument. The most difficult questions are the ones repeated for every individual in the household, which raises the possibility of reducing burden by subsampling within the household and administering the difficult financial questions to just one person.
























