
4
Adversarial Artificial Intelligence for Cybersecurity: Research and Development and Emerging Areas
Wenke Lee, professor of computer science and co-director of the Institute for Information Security and Privacy at the Georgia Institute of Technology, moderated a panel on emerging areas in the use of artificial intelligence (AI) among adversaries and for studying adversarial behavior. To set up the discussion, he reflected on the evolution of AI in the context of cybersecurity, with a particular emphasis on machine learning (ML).
Lee recalled Rao Kambhampati’s overview of the long history of AI and argued that the history of ML for cybersecurity is also a long one. He noted that many cybersecurity researchers shied away from AI in the 1990s, but that some, including himself, did pursue research in this space as early as the late 1980s. Since then, significant progress has been made, and it has become widely accepted that ML could support cybersecurity functions such as anomaly detection, malware clustering, alert correlation, and user authentication. Lee shared the following three insights that he sees as particularly important in applying ML for cybersecurity:
- False positives are a significant problem that must be addressed;
- Deployed ML models need to be explainable in order for security professionals to trust them—a particular challenge for deep learning (DL); and
- Feature engineering—using knowledge about particular domains to create features used by ML algorithms—is important for successful cybersecurity applications of ML.
ADVERSARIAL ATTACKS ON MACHINE LEARNING
In general, cybersecurity is an adversarial and adaptive activity. It follows that ML used for cybersecurity purposes is itself vulnerable to adversarial manipulation—that is, attackers may learn enough about the ML model to design ways of tricking or altering it to render it ineffective for defense. He noted that research in this space began in the early 2000s, and he highlighted some of his own past results on noise injection as examples. In one case, his team was able to fool an ML model for worm detection by sending out a fake network flow in addition to the real attack flow, essentially manipulating the model’s training data. He also described how an adversary can perform experiments to understand what attacks the model can and cannot catch by simply sending test packets and noting whether or not they make it through. From there, the distribution of accepted traffic can be deduced, and noise added to an attack flow to make it appear normal.
Lee pointed out that such challenges also exist with DL systems, although in some cases they may be overcome. He made use of DL-based computer vision to illustrate this point, noting that an adversary can sometimes
fool a model by altering just a few pixels, causing the model to mistake, for example, a truck for a dog. These alterations are not easily recognizable to human eyes and occur in so-called high-frequency pixels. It turns out that these signals can be removed without altering the image quality as perceived by a human simply by filtering out the high-frequency data from the image file—easily achieved via the common practice of image compression. In this way, domain knowledge can help to defend against such adversarial manipulations. According to Lee, this example illustrates that practical operational constraints may actually limit the freedom and abilities of an adversary. He suggested that this is an area that should continue to be explored, and that operational context should shape our understanding of realistic attacks and defenses.
Lee introduced the panelists: David Martinez, associate division head of the Cybersecurity and Information Sciences Division of the Massachusetts Institute of Technology (MIT) Lincoln Laboratory; Yevgeniy Vorobeychik, associate professor of computer science at Washington University; and Una-May O’Reilly, founder and principal research scientist of the AnyScale Learning for All (ALFA) Group at MIT. The presentations were followed by a plenary discussion.
EMERGING AREAS AT THE INTERSECTION OF ARTIFICIAL INTELLIGENCE AND CYBERSECURITY
David Martinez, MIT Lincoln Laboratory
Martinez discussed the implications of AI for cybersecurity, providing an overview of security risks of AI-enabled systems and examples of how AI can be deployed across the cyber kill chain. His comments drew upon a recent MIT Lincoln Laboratory study1 on AI and cybersecurity and a workshop2 hosted jointly with the Association for the Advancement of Artificial Intelligence.
He began with a perspective on the outlook for cybersecurity. First, he suggested that adversaries are or will be working hard to leverage AI in cyberattacks, setting up a race between attackers and defenders to see which side can advance and leverage AI faster—a major motivator for working to demonstrate capabilities. Second, the Internet of Things is changing the landscape by opening up new forms and avenues for cyberattacks. Third, he suggested that defenders will need to be concerned about all parts of a system, including data at rest, in transit, and in use. Finally, he suggested that data privacy and laws such as the European Union’s General Data Protection Regulation will increasingly come into play in the years ahead. He then proceeded to focus on the intersection of AI and cybersecurity.
Security of Artificial Intelligence-Enabled Security Systems
Taking an end-to-end perspective, Martinez noted that AI- and ML-enabled systems are not just vulnerable via adversarial attacks on the algorithms themselves. He walked through the structure of common architectures for AI, noting the different stages (initial data inputs, data conditioning processes, algorithms, and human-machine teaming; see Figure 4.1) and ways in which they are vulnerable to cyberattack. Because the majority of data being collected today are unstructured, a significant amount of data conditioning is generally required before ML algorithms can be applied. Subsequent to application of the algorithms, a spectrum of activities can be undertaken in order to transform information into useful knowledge and insights, all of which present opportunities for attack.
The hardware on which computations are carried out presents its own set of vulnerabilities. He reiterated the point that the current utility of ML-based techniques has been enabled by advances in computing technologies—in particular, the application of graphics processing units (GPUs) for computing on large data sets. The security of the supply chain for these hardware components is thus a particular concern.
___________________
1 MIT Lincoln Laboratory, 2019, Artificial Intelligence: Short History, Present Developments, and Future Outlook, Lexington, MA.
2 D.R. Martinez, W.W. Streilein, K.M. Carter, and A. Sinha, 2016, “Artificial Intelligence for Cyber Security,” Association for the Advancement of Artificial Intelligence Technical Report WS-16-03, part of the Workshops of the Thirtieth AAAI Conference on Artificial Intelligence: Technical Reports WS-16-01–WS-16-15 by the AAAI Press, Palo Alto, CA, https://aaai.org/Library/Workshops/ws16-03.php.
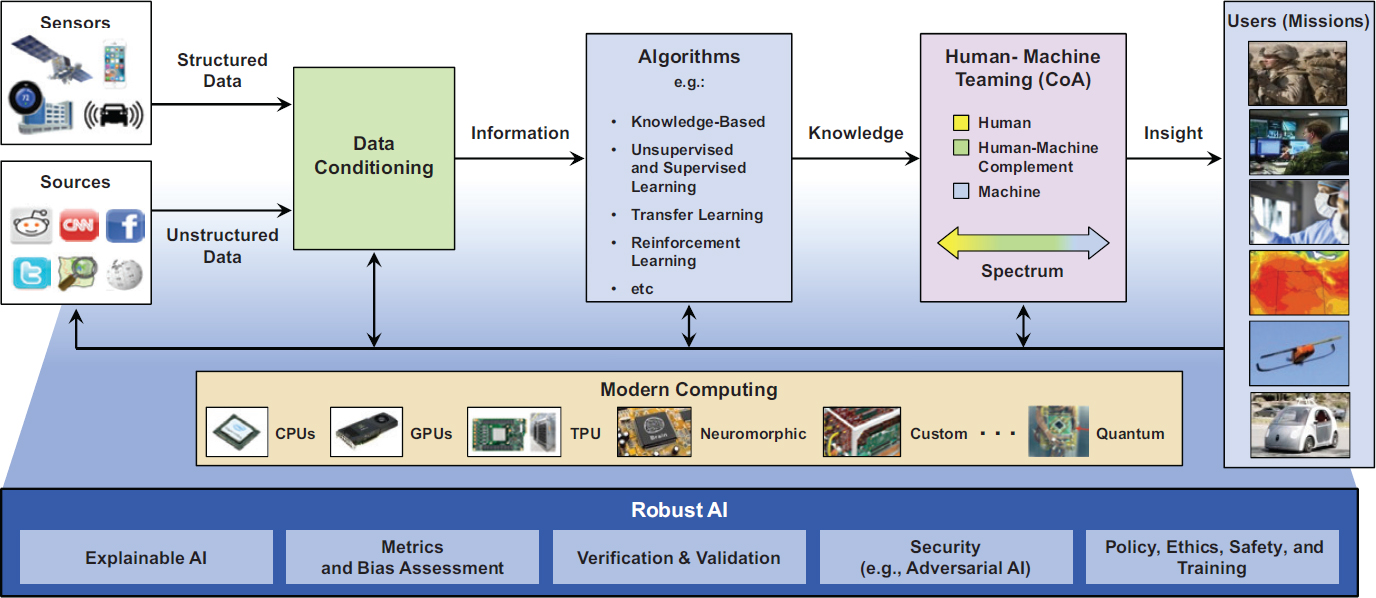
In his view, the most important thing is for systems to be robust. A major challenge is that there are not currently useful metrics for assessing the end-to-end robustness of a system. He also pointed out that the effectiveness of a system does not necessarily improve just because AI is being used, or because an algorithm in use is elaborate or complex; sometimes simple algorithms or systems are the ones that best support users’ needs, including decision support for cyber analysts. In addition, he suggested that policymakers should be more informed on the technologies in question so that policies and tools are more effective and complementary.
Attack Surfaces of Machine Learning Algorithms
Martinez described how an adversary might try to attack an AI-based system across three main phases of development: training a model on large amounts of data, cross-validation of the model, and testing the model on new data. Potential attacks include the following:
- Evasion attacks, in which the characteristics of an attack are carefully adjusted to cause misclassification by the system, allowing the attacker to evade detection; and
- Data poisoning, in which training data is modified so that the model’s training leaves it weakened or flawed.
In the research and development (R&D) community, the techniques for attacking ML systems categorize as either white box attacks, in which the adversary has knowledge of the data and the algorithm itself, or black box attacks, in which the adversary uses the output to make inferences about the model.
Applications of Artificial Intelligence Across the Cyber Kill Chain
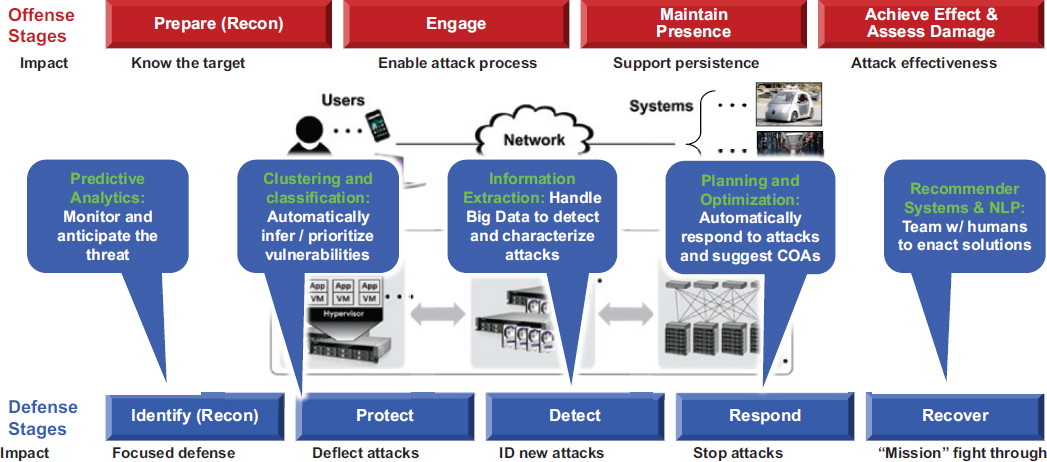
Martinez offered Lincoln Laboratory’s formulation of the cyber kill chain (see Figure 4.2).3 On the offensive side, he identified several key stages: prepare, engage, maintain presence, and achieve effect and assess damage. While it may take an adversary days or weeks to prepare for an attack, the event itself can occur rapidly.
On the defensive side, Martinez pointed to ways that AI can offer important advantages across the multiple stages of identifying, preventing, responding to, and recovering from attacks. For example, predictive analytics can help monitor and anticipate threats, while clustering and classification can automate the process of inferring or prioritizing vulnerabilities to help deflect attacks. As new attacks occur, information extraction can be used to detect and characterize attacks, while planning and optimization tools can automatically respond and suggest a course of action for stopping an attack. Finally, AI-based recommendation and natural language processing systems can team with humans to enact solutions and recover from attacks. To illustrate these ideas, Martinez presented three examples, focused on the application of AI for identification and classification of threats.
The first example involves counterfeit detection in computer hardware. Detecting counterfeit (and potentially compromised) device components is extremely challenging for defenders. Martinez’s team was asked to develop simple ML techniques capable of rapidly screening a large number of parts to identify suspicious components. The solution they devised used supervised learning (via support vector machines) to compare rapidly many components against a “gold standard,” using measurable values such as power, frequency, and voltage as features. This model showed great success in flagging potential fakes for closer examination.
The second case focused on prioritizing vulnerabilities based on their likelihood of being exploited, to help minimize the false-positive rate in detecting inform an optimal allocation of cyber defense resources. He suggested that, because there are so many known vulnerabilities (tracked by the National Institute of Standards and Technology in a National Vulnerability Database), it might not always be practical or effective for cyber defenders to look for all of them. Martinez’s team used natural language processing and logistic regression to compare the knowledge about vulnerabilities with actual instances of exploitation to estimate the risk that a vulnerability will be exploited, enabling a more effective detection protocol that reduced false alarms. The system outperformed the common vulnerability scoring system (CVSS) used in current practice, which is based on a fixed formula.
___________________
3 Rapporteurs’ note: There are multiple formulations of a cyber kill chain, including the one presented here and the Lockheed Martin model presented in Chapter 2.
Similarly, in the third case, ML was used to help cybersecurity analysts find documents of greatest relevance to their work, saving them time and keeping them from having to filter through documents unlikely to be useful. Analysts had been examining large quantities of documents, only 1 percent of which were germane to their work. Martinez’s team created a model for prioritizing documents, creating word clouds, and passing them through logistic regression algorithms to characterize relevance. The model was successful, enabling analysts to focus on a smaller pool of documents, 80 percent of which were relevant to their task.
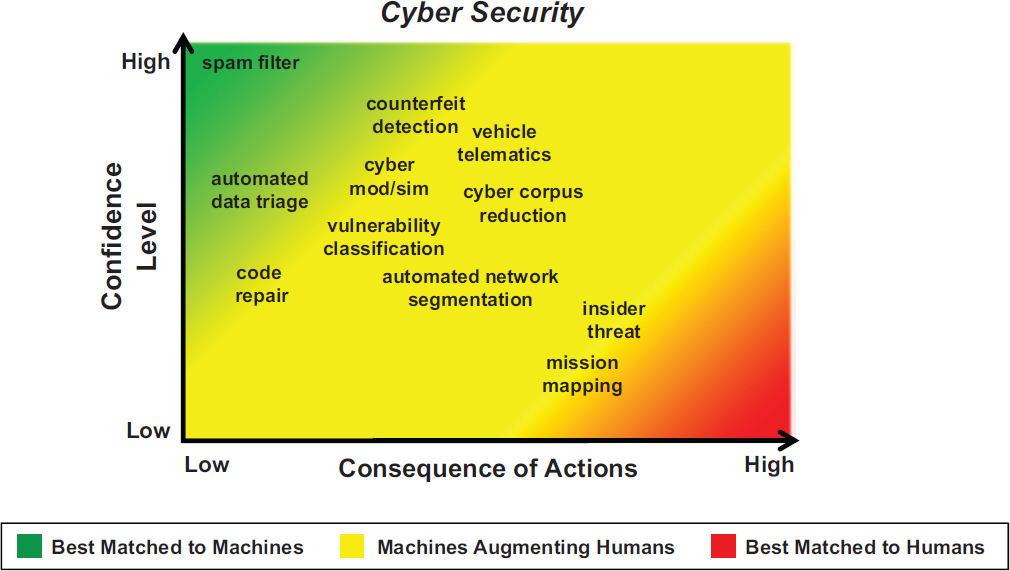
Martinez emphasized the importance of recognizing the complementary capabilities of ML and humans in making decisions, and strategically assigning tasks to an algorithm or an analyst in order to optimize efficacy and minimize risk. Such assignments can be optimized by assessing the level of confidence in a machine’s decision and the consequences of the actions that would be taken as a result of the decision. If confidence in the machine is low and consequences are high, a human should make the decision. If confidence in the machine is high and consequences are low, as in the case of spam filtering, for example, then the problem may be best addressed by a machine. Tasks for which an algorithm performs with mid-range consequence or confidences may be best assigned to a human augmented with a machine. He provided a picture of how different cybersecurity tasks fall into this framework, reproduced in Figure 4.3.
Future Needs
To further develop AI for cybersecurity, Martinez identified three primary needs. The first is to get a better handle on the needs and desired capabilities in this space. Toward that end, Martinez suggested bringing researchers and users together for more effective interactions and examining available tools being developed in industry and academia. The second is to create an ecosystem to support effective evaluation, which includes establishing performance metrics or gold standards, as well as increasing the availability of test data. Finally, Martinez stressed the need to test and iterate rapidly, including getting feedback from users.
Martinez concluded by reiterating two key ideas. First, he noted that the security risks of AI are not limited to adversarial attacks on learning algorithms, but extend across all levels of the systems architecture. Second, he emphasized AI’s potential for improving cybersecurity and highlighted the value of creating an ecosystem and infrastructure in which to do in-depth evaluation and perform near-term, rapid demonstrations of new solutions.
IS RobustML REALLY ROBUST?
Yevgeniy Vorobeychik, Washington University
ML is naturally suited to solving the fundamental cybersecurity problem of detection—for example, detection of malware, intrusions, or spam. For example, an ML-based malware detection model may be trained to detect suspicious files by learning from a collection of labeled examples. A common approach is for a model to make connections between characteristics, or features, extracted from the files and their labels (either “malicious” or “benign”). ML is commonly used in this manner for cybersecurity.
However, Vorobeychik noted, it is possible for attackers to evade ML-based detection. In particular, attackers may manipulate malware files so that an ML-based detection model will fail to identify them as malicious—an approach commonly referred to as evasion attack. Vorobeychik’s team has been working to develop ways of strengthening, or hardening, ML-based detection systems against evasion attacks through additional training, or iterative retraining, to yield more robust ML. This is done by learning a model on an original training data set, generating new instances with some evasion method and adding them to the data set, then retraining the model on the new data set, and repeating until iteration criteria have been met.
He went on to define some important terms and concepts and then described his group’s experimental work and findings on the efficacy of different forms of robust ML against evasion attacks, using the specific case study of detecting PDF-based malware.4
___________________
4 L. Tong, B. Li, C. Hajaj, C. Xiao, and Y. Vorobeychik, 2017, “A Framework for Validating Models of Evasion Attacks on Machine Learning, with Application to PDF Malware Detection,” arXiv preprint, arXiv:1708.08327.
PDF Malware Detection Models
Vorobeychik identified two classes of ML-based PDF malware detection models. The first type uses a content-based approach, relying on features such as Javascript tags, author names, and file sizes to identify potential malware. A key example of this class is a tool called PDFRate; this model can quantify feature values as either binary or as normalized real values. The second type uses a structure-based approach, making use of the cross-referencing between objects embedded in the PDF as the key features in the learning model.5 In order to make these detection models robust against a real-world evasion attack, they must be trained against examples of evasion attacks.
Feature-Space Attack Models versus Realizable Attacks
Vorobeychik defined a class of models, called feature-space attack models that could be used as an approximate representation of evasion attacks. These attack models have two key properties: first, the attacker can make arbitrary changes to features; and second, the cost of those changes is measured relative to an instance of ideal malware. Vorobeychik distinguished these attack models from realizable attacks—attacks that might actually be made against a deployed system—noting that feature-space attack models are not truly an accurate representation of what actually happens with malware. Nonetheless, his team posited that they might enable a defender to harden an ML-based detection model against a realizable evasion attack.
They identified several realizable evasion attacks for the case of PDF malware detection. The first, called Mimicry,6 operates by adding benign-looking content to an area of a PDF file that is not read by PDF readers, mimicking the features seen in benign PDFs and thus tricking content-based malware detection. A second example, called EvadeML7 uses genetic programming to perform a wide range of manipulations on a PDF file, including adding, removing, and replacing its embedded objects in order to alter the structural patterns that might otherwise be flagged as malicious. This is a more general—and more powerful—tool for evasion attacks.
These examples are realizable attacks because they modify the actual PDF rather than its extracted features, they have actual malicious effects after the modification, and they avoid detection.
Experimental Results
Experiment 1: How Robust Is RobustML?
Vorobeychik’s team set out to determine the following: Can detection models be made robust using a simplified evasion model as a proxy for examples of actual, realizable evasion attacks? More specifically, can ML-based detection models trained on unrealistic feature-space attacks be robust against realizable attacks? He termed this approach RobustML.
The team studied several PDF malware detection tools, including the content-based PDFRate algorithm and the structure-based Hidost classifier, developing models under the following three different training regimes:
- No training against evasion attacks,
- Training against EvadeML itself to establish a baseline defining maximum robustness, and
- Training against a feature-space attack model (the RobustML approach).
They then measured the resulting models’ efficacy against both evasion attacks and simpler attacks that do not incorporate adversarial learning.8
___________________
5 The tool SL2013 and its revision, Hidost are examples of this type of model.
6 N. Srndic and P. Laskov, 2014, “Practical Evasion of a Learning-Based Classifier: A Case Study,” IEEE Symposium on Security and Privacy, doi: 10.1109/SP.2014.20.
7 W. Xu, Y. Qi, and D. Evans, 2016, “Automatically Evading Classifiers: A Case Study on PDF Malware Classifiers,” Network and Distributed System Security Symposium, doi: 10.14722/ndss.2016.23115.
8 A model’s robustness against evasion attacks was defined as 1 minus the success rate of the EvadeML attack against it (reflecting the fact that an attack’s success rate decreases as robustness increases). Its efficacy against traditional attacks can be quantified in terms of the AUC—the area under the receiver operating characteristic (ROC) curve, a plot of the true positive rate versus the false-positive rate.
Surprisingly, the team found that training against the incorrect feature-space model rendered the content-based classifier, PDFRate, nearly 100 percent robust against EvadeML attacks—although the price of robustness in this case was reduced performance on non-adversarial data (i.e., data without evasion attacks). When applied to the structure-based classifier Hidost in a second demonstration, RobustML fell short, achieving only about 70 percent robustness against EvadeML attacks.
Vorobeychik’s team then asked whether the performance of the feature-space approach could be improved by connecting the models to the actual domain, thus capturing results that are more relevant to the task. They explored the approach of using only the features of PDFs that change if malicious functionality is removed, called the “conserved features”—features that can only be clearly defined when using a binary feature space.
Experiment 2: Can the Feature-Space Approach Be Improved by Using Conserved Features?
In Vorobeychik’s experiments, the number of conserved features was extremely small relative to the overall feature space: 8 out of roughly 6,000 features in the case of SL2013, 7 out of roughly 1,000 for Hidost, and 4 out of about 120 for the version of PDFRate with features classified as binary, rather than real, values. This raises several questions: First, can we identify them using statistical techniques? Second, is it possible to make sure they are conserved in a meaningful sense, for example, by choosing a classifier that only uses such features? Most importantly, how can conserved features be used to improve the feature-space RobustML?
In demonstrations, Vorobeychik’s team was able to show that by keeping most of RobustML the same but making it so that the conserved features of the adversarial model against which the malware detector is trained are not modified, the model could achieve a robustness rate of 100 percent for Hidost and 90 percent for SL2013. For PDFRate, the new approach maintained a high robustness while also improving AUC (the area under the receiver operating characteristic curve).
Broader Implications
Can similar results be achieved against realizable attacks beyond EvadeML? Is ML hardened with a feature-space model of attacks (using conserved features) generally effective against other realizable attacks? In further tests, Vorobeychik found that RobustML remained robust (albeit not perfectly so) against a reverse mimicry attack and a GAN-based attack. In addition, the team created a custom attack that exploits a feature extraction bug in the Mimicus implementation of PDFRate. This attack defeats a classifier that is hardened using EvadeML, but RobustML (with conserved features) remains robust.
To determine whether the RobustML type of defense would work in a broader array of circumstances, for example in the domain of computer vision, Vorobeychik outlined three elements of a realizable attack in this sphere: first, that a physical entity is modified (such as by placing stickers on a stop sign); second, that there is a malicious effect; and third, that the attack avoids detection. Vorobeychik ended his presentation by posing the question: Does RobustML defend against physically realizable attacks on deep neural networks for computer vision?
ARTIFICIAL ADVERSARIAL INTELLIGENCE FOR CYBERSECURITY
Una-May O’Reilly, MIT
O’Reilly’s team at MIT’s Computer Science and Artificial Intelligence Laboratory works with AI in the context of cybersecurity. She presented her work in the field of artificial adversarial intelligence, the use of AI to simulate adversarial behavior in cyber engagements. She emphasized that this field is distinct from adversarial AI, the study of the vulnerability of ML models and training processes to adversarial manipulation.
Simulating Adversarial Cyber Engagements
O’Reilly discussed her bio-inspired framework, called Rivals, for simulating scenarios in which two parties in conflict with each other interact and learn from the experience, retreating to fight again another day. She noted
that this approach does not need large collections of real-world data; rather, it is based on self-contained models and simulation.
The goal of the work is to inform network designers about the resilience or robustness of their network design before it is deployed, beyond simply assuming that future threats will mirror those seen in the past. The ability to anticipate the most disruptive attack that might result from an attacker-defender arms race can help designers to plan courses of action for improving network resilience.
A Framework for Simultaneous Learning
Rivals is built on two main assumptions: first, that it is possible to measure the success of each of two adversaries as they engage with one another; and second, that both adversaries are intelligent, meaning that they can take information from one engagement and use it to inform a different tactic or strategy in the next. While previous work has considered active learning on the part of the defender, as with moving target defenses, O’Reilly’s approach takes into account the possibility of learning on both sides. Rivals can be implemented such that the defender learns but not the attacker, that the attacker learns but not the defender, or that both are learning simultaneously. In each scenario, the active learner optimizes its strategy to best achieve its specific goal.
O’Reilly noted that the framework was originally built to study extreme distributed denial of service (DDOS) attacks on peer-to-peer networks, in order to understand how the adversary could optimally target them, and how they could optimally defend themselves by changing configuration. Her team also used the system to understand how network segmentation could be used to limit the spread of malware on the network. In order to explain how the Rivals framework operates, O’Reilly described an ongoing research project called Dark Horse.
Use Case: Network Scanning Attacks and Defenses
Dark Horse makes use of the Rivals framework to simulate one phase of the advanced persistent threat (APT) attacks targeting a software-defined network (SDN) that deploys a deceptive network view in its defense—that is, it is capable of creating fake network nodes and traffic to misdirect an attacker.
Rivals considers the reconnaissance phase of the cyber kill chain, where a network has been invaded, and the attacker has achieved persistence, but not yet started to move laterally across the network. At this point, the attacker is launching scans to probe the topology of the network and characteristics of its nodes in order to find the locations of valuable assets. In the Rivals’ model, the attacker will learn and adapt to optimize success at this goal. The defender in this scenario is seeking to prevent the scans from being effective. The defender does this by presenting a deceptive view of the network such that the attacker’s scans yield partially false information. Can ML help to optimally configure the deceptive defense, by anticipating how the attacker will learn from the scan results?
To investigate this, O’Reilly created an engagement environment, via a simulated SDN, capable of mounting deceptive defenses (via deception servers and a deceptive network generator). In this simulation, there are two adversaries: one, the attacker, may use software for scanning the other’s system (as an attacker would to find vulnerabilities) and the other, the defender, defends its own network by changing parameters of the deceptive network in order to trick the adversary. Experiments could thus be performed to simulate attacks and defensive operations, and to measure the success of the defender and attacker based on how long it takes for the defender to detect a scanner, how long the scanner runs, and other factors. These measurements can be fed back to the simulated defender and attacker, allowing each to learn ways to adapt their behavior and improve.
Tactical Learning
O’Reilly’s team aims to understand and describe the behaviors of the two adversaries at all levels, including high-level strategy and tactics; the means—that is, the techniques, procedures, and tools used to defend or carry out an attack; and the low-level implementations. For example, the implementation of operations on a network, which includes both normal behavior and adversarial behavior, lead to data that may be observed and collected. The team used measurements at the implementation level to enable learning at the tactical level.
The attacker, at the tactical level, gets to decide how many Internet Protocol (IP) addresses to scan, how to batch them, and the order in which they’re scanned, with an overall goal of scanning as many nodes as possible without being detected. The defender, at the tactical level, gets to create the deceptive view, deciding how many subnets to include and how the real nodes are placed in the subnets (e.g., randomly or purposefully, clustered or spread evenly). The defender’s choices affect the attacker’s options and outcomes, creating complexity in the environment.
In the simulations, O’Reilly can place a ML module behind either the defender, the attacker, or both, enabling one or both entities to learn from the measured outcomes of a particular strategy, tactic, or implementation, and optimize a new approach toward achieving the objective. For example, when the defender is able to learn but the attacker is not, ML is used to find the best defense against the particular scans that are launched. As more scans are launched, this provides the defender with more information to support a decision about the most robust overall strategy—which amounts to a tool for decision support. If the attacker is able to learn but the defender is not, the attacker over time uses ML to determine the best attack possible against each particular defense configuration. When both parties can learn, they each extract information from their engagements that help to inform future tactics.
Because real-world networks and attackers do not have the same degree of agility, O’Reilly’s team designed the simulation to operate in a lockstep fashion, such that the attacker learns while the defender stays static, then the attacker freezes while the defender learns, and so forth. This simulation reveals that the same strategy may have different levels of success when one side or the other can learn versus when they both can. Although it is somewhat abstract, O’Reilly said the simulation offers insights that could be useful for informing network design and anticipating cyber arms races.
PANEL DISCUSSION
Lee moderated a discussion touching on additional aspects of the panelists’ work and how their approaches relate to broader real-world cybersecurity problems.
Selecting Effective Models
John Manferdelli, Northeastern University, responded to Vorobeychik’s work, noting that it offered valuable insights into the underlying techniques of AI-based malware detection. He also commented that the incentives for using AI may be misaligned with their actual utility for solving a particular problem; commonly, another approach may actually work better or with a more predictable outcome. Sven Krasser, CrowdStrike, asked how ML-based approaches can better reflect the constraints around realizable attacks (also called problem-space attacks), which are typically very complicated. For some file types, he noted, it can be extremely difficult to formally express the constraint space, and it can be challenging to come up with data for building realistic models that adhere to these real-world constraints.
The crucial question, Vorobeychik responded, lies in the selection of the model. The right model might not be obvious, and even a wrong model may work well for a specific purpose. Rather than placing so much focus on finding the particular model that best represents a particular attack, he suggested focusing on evaluating the efficacy of alternative models. Simpler or more mathematically tractable models are generally easier to work with, and are a good place to start, he noted.
Manferdelli also asked whether O’Reilly’s team could determine whether its model of the attacker and what it gains from an attack was sufficiently accurate. O’Reilly acknowledged that the work is a simulation in early stages and not necessarily reflective of all real situations. She noted that the team got the idea for the approach when working on a tax-avoidance project, which came with a surprise constraint: no actual data was provided to the research team. Without data, the team was forced to explore different AI approaches that it might not have otherwise considered. It ended up writing rules-based software that modeled the tax law and a model for auditing (the main defense mechanism against tax evasion) making it relatively easy to model mechanisms of avoidance.
The work yielded new ways of understanding how adversaries coevolve and cause arms races, O’Reilly said, which she ultimately applied to the cybersecurity realm with Dark Horse. While there are still ways to make the
simulation more realistic—which O’Reilly suggested could be advanced by better exchange between companies and herself as an academic researcher—she said the work is attracting some interest among network operators who see the value in understanding what an optimized attack and defense looks like and how they co-optimize when both sides learn.
Increasing the Costs of Attack
Wenke Lee reiterated that part of the arms race between attackers and defenders is about making the attacker’s job harder. For example, in a scanning scenario if the defender gets good at detecting fast scans, the attacker has to switch to slow scans, impeding their progress. By raising the bar and the level of effort it takes to overcome the defenses, the defender may be able to drive the attacker to simply move on to an easier target.
O’Reilly built on this point with an analogy: If you and your friend are running from a bear, you only have to be faster than your friend. She said her team strives to incorporate this idea in their work, in the case of the Rivals framework, by more accurately modeling the resource costs faced by both sides. By forcing an attacker to spend more resources and more time, you can reach a point where a real-world attacker would likely shift to another target.
Krasser noted that the different costs involved in different types of attacks can also influence whether an attacker may seek to use AI tools. For phishing attacks, for example, the costs of failure are minimal: an attacker can send lots of emails at low cost and even get direct feedback when they are successful, a situation that lends itself well to AI. For a network intrusion, the adversary is motivated to be more careful in order to avoid detection and may be more reticent to use a conspicuous ML tool. If an adversary is detected, the defender will learn about the entry point and the vulnerabilities leveraged. In particular, divulging a previously unknown vulnerability is extremely costly to an adversary. Raising the costs of practicing an attack is one way to slow the attacker’s progress, he suggested.
O’Reilly added that it is possible to identify malware and image attacks even when the input dimensionality is large, but for network data sets, where the activity is dispersed, asynchronous, and coming from different sources, it is much harder for a detection model to succeed. This means it is important to think about network attacks at different levels, develop a hypothesis about where attacks are most likely to emerge, and retrain the sensors to direct the monitoring effort accordingly, she said.
Connecting Research Results to the Real World
Phil Venables, Goldman Sachs, asked whether the panelists had researched actual attacks in which adversaries used AI to detect deception, such as to identify a deception network or honey pot. Vorobeychik responded that his work focused on attacks developed by cybersecurity researchers, rather than real-world attacks, but that within this sphere the EvadeML attack could be viewed as AI, because it uses genetic programming9 to automatically search a large space of possible attacks. O’Reilly added that her coevolutionary algorithm similarly uses genetic programming on both sides.
Lee pointed to work of the Intel Science and Technology Center for Adversary-Resistant Security Analytics10 at the Georgia Institute of Technology. In particular, the MLSploit project is creating a platform to test ML models. When supplied with a model and some sample data, the platform can automatically generate examples that evade the model, providing helpful feedback to security researchers.
Martinez noted that his work is based on the defender side, not the attacker side, but posited that in both contexts there is a need for well-validated data sets. Observing that ImageNet and the Modified National Institute of Standards and Technology (MNIST) database have been useful in the realms of image and character recognition, he asked whether equivalent data sets could be made available in the cybersecurity realm to test and validate
___________________
9 Rapporteurs’ note: Genetic programming involves developing an optimal program out of a suite of potential candidate programs by maximizing performance for a given task, through processes analogous to evolution and natural selection. See also Wikipedia, “Genetic Programming,” last edited July 28, 2019, https://en.wikipedia.org/wiki/Genetic_programming.
10 Georgia Institute of Technology, “Intel ISTC-ARSA Center at Georgia Tech,” http://www.iisp.gatech.edu/intel-arsa-center-georgia-tech.
algorithms. He added that his division has experience with using publicly available surrogate data sets for training models, the best of which can later be adapted to a different data set of particular interest that is not widely shared.
Jay Stokes, Microsoft Research, raised the question of whether releasing data sets risks putting too much useful information in the hands of adversaries. O’Reilly said that she assumes adversaries can replicate the work of any cybersecurity researcher. Even if they must devote more people and resources to do it, it is inevitable that they will have these capabilities. Since the two sides are ultimately matched in terms of capabilities, the more important question, she suggested, is how to drive the engagement toward equilibrium where it becomes too expensive for either side to do anything other than the status quo.
Kambhampati echoed the notion that if a cybersecurity researcher can accomplish something, it is likely that an adversary can, too. While some have advocated for holding back on releasing models in order to protect against their misuse, Kambhampati reasoned that sharing models and actively trying to break them is essential to evaluating systems’ robustness while avoiding the trap of a false sense of security. Lee added that in his view, the benefits of releasing attack data outweigh the risks, primarily because most attackers, seeking the cheapest option, will keep using the same attacks for as long as they work. Revealing an attack can also force attackers to invest more time and resources in developing new methods, slowing them down.
O’Reilly noted that she encountered this issue with the tax-avoidance project. While the team did not release the code it developed for identifying tax-evasion schemes, it faced a dilemma: How much information should be included in the associated publication to make it useful for above-board research without revealing tools that could be used for avoidance? The case was a valuable learning experience for the team and students—it demonstrated the importance of discussing ethical considerations and what it means to be a trustworthy AI/ML researcher early on in a project.
Influencing Attacker Behavior
A participant wondered whether adversarial ML approaches could be used to not only deflect attacks but also to actually manipulate an attackers’ behavior—for example, to trick them into revealing information that would enable attribution of the source of an attack. O’Reilly responded that anything is possible and that the paradigm of adversarial engagement and using ML to replicate the arms race is solid, but that things get complicated when this approach is applied to specific use cases: What behaviors get modified? What are each adversary’s goals? What measurements can you make? Lee added that a Multdisciplinary University Research Initiative project he is involved with is pursuing this question through games—for example, by exploring how a defender can anticipate an attacker’s moves and plant false flags or lure the adversary into being exposed. However, this is simulation only and does not involve real data and scenarios, he noted.
Game Theory Modeling
Tyler Moore, University of Tulsa, asked how game theory complements O’Reilly’s approach to studying strategic interaction in the context of security. O’Reilly responded that game theory is indeed likely to be useful, although it will be necessary to go beyond simplistic theories, like the prisoner’s dilemma and Nash equilibriums, in order to represent the complexity of the adversarial dynamics seen in cybersecurity. She noted that she has been examining ways to use Stackelberg games and other types of game theory at the tactical level and push it down the stack to represent threats and behaviors at a level where learning can occur. Moore added that game theory literature has become more complex, but complexity might not be what’s needed; he suggested that useful high-level cybersecurity insights could be potentially gained just by more clearly identifying the interests of the players and the costs they face.
Vorobeychik clarified his view of the difference between Moore’s suggestion, which may be better described as best-response dynamics, and O’Reilly’s framework, which is more of a game. He also countered what he perceives as a misconception that game theory is simplistic. Game theory, he said, is about precisely modeling the structure of the environment and then applying tools to devise solutions. Since today’s tools are effective for finding solutions, the challenge in his view lies in modeling the structure in a precise way. To this end, O’Reilly’s framework is the
right approach, he said: One needs a high-granularity model of the strategy spaces, and clearly defined outcomes and game structures, and from there existing tools can provide a good sense of how to start solving them.
O’Reilly added that coevolutionary algorithm researchers have established defined outcomes and ways of measuring them. In her work, many variations of attacks and defenses were tried; with the right solution concept in the algorithm, it is possible to drive the system to equilibrium. In her view, the genetic algorithm is just as capable of coming up with the equilibrium as game theory. Kambhampati added that expressiveness is not the problem—it’s really the inference, and learning the model parameters. Being able to use game theory to complement this work would be useful, he concluded.













