
6
Recent Trends in Machine Learning, Parts 1 and 2
ON OPEN SET AND ADVERSARIAL ISSUES IN MACHINE LEARNING
Terry Boult, University of Colorado, Colorado Springs
Terry Boult, University of Colorado, Colorado Springs, said that the first part of his talk would explore issues with unknown inputs and open-set recognition in deep networks. He explained that human systems excel at both recognition tasks and noting when they do not know what an object is. However, researchers are not yet building open-set recognition problems and need to be considering how to deal with unknowns in the environment. Classic machine learning tends to deal with binary or multiclass classification (i.e., everything in training and testing comes from one of the known classes). However, other common problems include face verification, object detection, and open-set recognition. In this last case, there are multiple known classes and many unknown classes. Boult defined open-set recognition as a mixture of two very different problems: multiclass recognition and anomaly/novelty detection. Very different types of errors must be balanced, and risks associated with rare events must be considered. Handling unknown unknowns is especially important in the Intelligence Community (IC).
The problem of unknown unknowns can be formalized by balancing two risks: open space and empirical (Scheirer et al., 2013). Open space is defined as the space far from the known samples. The risk, then, is labeling anything other than the unknown. Boult cautioned against using the threshold classifiers’ confidence to address this problem because this focuses on the boundary between the known and unknown classes, which is ill defined for open-set problems. Classic machine learning presumes all classes are known, and it classifies all of the feature space; this does not apply to open-set problems.
To address this problem, Boult’s team developed an extreme value machine (EVM) in which the boundary between classes is described in every machine learning problem using a margin distribution theorem to derive extreme value theory-based non-linear models that are provably open set and can do incremental learning (Rudd et al., 2018). And, as new data are added to the classes, other classes can shrink and change shape efficiently. Boult next discussed how to use deep networks for open-set problems (Bendale and Boult, 2016). With a normal network, AlexNet makes a prediction and output comes from a SoftMax classifier. However, people started finding ways to attack deep neural networks with adversarial
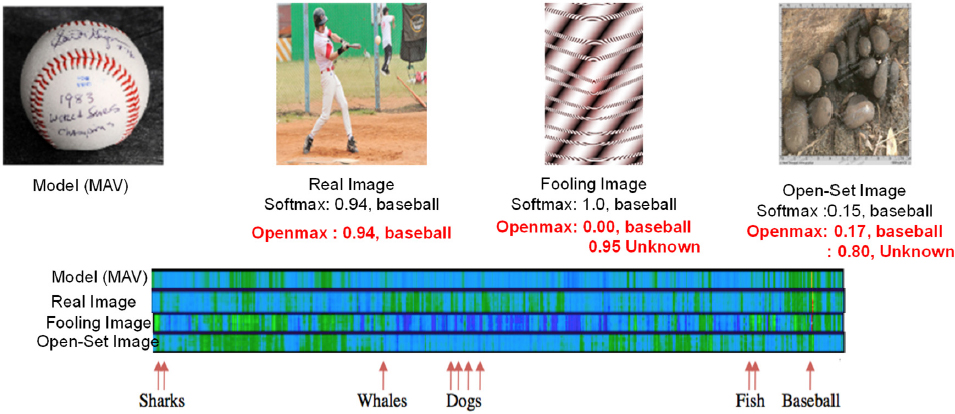
images. Boult’s team set out to correct the high confidence errors and created OpenMax, an attempt at open-set deep networks. OpenMax takes one of the deep feature layers, using that to represent a particular class by taking positive instances of that class, and builds extreme value distribution to provably solve open-set problems. OpenMax looks at distance and representational space and provides probability-based estimates for image classes; the adversarial image is not consistent with other representations, so the OpenMax labels it as unknown (see Figure 6.1). He said that this could be done with open-set images: OpenMax can recognize something that it is not trained to handle, making this approach slightly better than the standard SoftMax.
Boult said that they expected the accuracy gap between SoftMax and OpenMax to be greater than 20 percent and the F-measure gap to be greater than 2 percent. So, they performed a test with known unknowns and unknown unknowns. With SoftMax, features for unknown inputs generally overlapped the known classes because the network was not designed to map things it did not know about. Boult and his team observed that there was a difference in entropy and magnitude: while the open set limited the response outside the ring of data, most of the unknowns had smaller magnitudes of deep feature representations. He described this as a natural outcome of looking at unfamiliar objects. However, OpenMax aims to represent unknown mappings with smaller magnitudes and the known mappings with larger magnitudes, with the feature vectors being pushed to the center. This was accomplished by introducing two new losses: entropic open-set loss, in which the entropy margin increases as do the SoftMax scores for the unknowns, and ObjectoSphere loss, in which the deep feature magnitude margin is increased, minimizing the Euclidian length of the deep representation for the unknowns. He explained that while the background classifier performed well, there were still many things outside the wedge. He pointed out that OpenMax performed poorly with a two-dimensional problem, while the entropic open set and the ObjectoSphere performed well. Classic open-set approaches do not really solve the problem of deep unknowns, Boult explained; using ObjectoSphere loss begins to address the learning of deep features that can handle unknown inputs.
Next, Boult’s team used ObjectoSphere for open-set face recognition. Face recognition has to deal with unknown non-faces and unknown probes, so they trained a three-layer ObjectoSphere net with VGG2 input features and forced all unknowns toward the origin. ObjectoSphere performed better than the baseline and better than EVM and generally better than the gallery fine-tuned SoftMax. Boult said that in the near term, he would like to see open-set recognition algorithms used for well-behaved, low-moderate dimensional feature spaces. In the long term, he hopes to see better network models for open-set recognition as well as high-dimensional open-set algorithms. Research areas to improve include realistic open-set data sets/protocols and a better understanding of the image and feature relationships. Boult added that when
accuracy is used as a measure, performance is typically worse because it is impossible to preserve the robustness and there are few protocols set up to do so. Rama Chellappa, University of Maryland, College Park, interjected that the Intelligence Advanced Research Projects Activity’s (IARPA’s) Janus1 had a protocol for open-set recognition. Boult acknowledged Chellappa’s comment but pointed out that today’s definition of an open set is different. Anthony Hoogs, Kitware, Inc., observed that Boult’s capabilities list assumes a recognition problem as opposed to a detection and recognition problem, which is of particular importance in the IC. He suggested exploring detection when the spatial extent of the object is unknown because the class is unknown. Boult said that a background classifier was added to aid in detection; open set is more challenging because the only meaningful questions are detection and recognition. He explained that doing face recognition without counting scores for non-faces causes real problems—this is a key difference from the Janus protocol. An audience participant asked about the trade-off between generalization accuracy and open-set accuracy. Boult said that the first question to ask is how generalization accuracy is being defined. The next question to consider in open set is how distance is generalized: how far is too far? He emphasized the need to avoid generalizing more than is consistent with the data. Using the margin distribution theorem can be helpful in this instance.
Boult next discussed another type of unknowns for deep networks: the relationship between open-set and adversarial examples. Adversarial examples are image perturbations that are invisible to humans but can easily fool deep networks. An open set is naturally thought of in “image space,” but the methods work in “feature space.” Adversarial examples show that for current deep neural networks, the two spaces are often not well related. While open-set recognition tries to deal with inputs that are far from known training samples, adversarial examples are “imperceptibly” close to known data and different from hill-climbing adversarial images. Adversarial examples show that we do not understand how or what networks learn, but they can provide insights to improve deep network learning theory, he continued. He explained that adversarial perturbations are unnoticeable for humans. One can relate image and feature spaces by considering the following questions about the root causes of imperceptible adversarial images:
- Does adversarial training improve robustness to other types? For some adversarials, no amount of training has made any difference in robustness.
- Is it aliasing caused by aliasing and/or down sampling?
- Do adversarial examples develop because we “stop” near the boundaries?
- Is an adversarial example caused by SoftMax/strict classification layer in networks?
- Does our OpenMax approach improve robustness?
- Does threshholding distance in center loss protect from “adversarial images”?
- Can attributes help resolve adversarial issues for face recognition?
- Are all networks/classifiers subject to adversarials?
- Can we use adversarial examples to improve privacy?
- Can we build networks that estimate uncertainty that captures both open-set and adversarial properties?
Adversarials provide insights about the theories needed for networks and how they generalize, Boult explained.
In response to a question as to whether adversarial examples occur naturally, Boult said that adversarials do not have to be machine generated; they can occur if there is noise in a system. In order to attack deep features, Boult explained, one has to attack what is in the middle instead of only the output. Boult introduced a deep-feature adversarial approach called the layerwise origin-target synthesis (LOTS); using examples of object-recognition and face-recognition, he showed how LOTS’ adversarial examples can successfully attack even open-set recognition systems, such as OpenMax, by matching features. In the study of adversarial system-level attacks, he noted that all prior work attacked just the network input image to change
___________________
1 For more information on the Janus research program, see Intelligence Advanced Research Projects Activity, “Janus,” https://www.iarpa.gov/index.php/research-programs/janus, accessed February 19, 2019.
the network output. His work matched an image’s deep feature representation. He provided an overview of examples of full-system attacks using LOTS. Using 12 adversaries, LOTS attacked every single gallery template with a success rate over 99 percent. He also shared unpublished results on one-shot black-box attacks: there was no hill climbing on the system to be attacked; they used only a surrogate network and then a test attack. Untargeted attacks were weak on some systems but were somewhat successful and portable across multiple commercial systems. Targeted attacks vary, so Boult wanted to understand why and when they are portable. Boult found that minimal perturbations are rarely portable, and they are better when the surrogate network has the same structure.
Boult hopes that in the near term, capabilities will include an iterative LOTS system having the ability to attack all kinds of systems, with LOTS attacks being reasonably portable. He believes LOTS can be used to build physical attacks and camouflage. An open research question is whether manipulation feature learning, as addressed by ObjectoSphere, could improve the adversarial example issue. Boult emphasized the importance of having a systematic, scientific approach in the adversarial space. An audience participant asked about adversarial retraining and whether hardening the network by trying to build this type of attack will detect or defeat the attack and morph the image in a way that makes sense. Boult said that in his experiments, no matter how much training with adversarials was done against LOTS, it made no difference; neither accuracy nor robustness improved. In response to another audience participant’s question, Boult acknowledged that there are many open questions about how to handle unknowns in high dimensions, and he encouraged more work in this area.
GENERATIVE ADVERSARIAL NETWORKS (GANS) FOR DOMAIN ADAPTATION AND SECURITY AGAINST ATTACKS
Rama Chellappa, University of Maryland, College Park
Rama Chellappa, University of Maryland, College Park, pointed out that for certain problems, such as face recognition, deep learning has worked well. He provided an overview of the many ways in which the world of computer vision has changed in the past 6 years. While the field used to be focused on physics and geometry, it is now focused on data. The field of computer vision has also witnessed impressive performance—notably on tasks such as face verification as well as object and face detection and recognition—and efforts continue (such as the IARPA Janus program) for unconstrained face verification and recognition. The field now uses multiple networks based on ResNet and InceptionNet, and researchers have achieved the true acceptance rate around 90 percent at the false acceptance rate of 1 in 10 million for the unconstrained face verification problem on a challenging face data set, according to Chellappa. Deep learning techniques are being used for the IARPA Deep Intermodal Video Analytics (DIVA) program,2 and human analysts and computer vision systems continue to work together to achieve optimal performance, with the human making the final decision for the problem. Chellappa emphasized that adversarial examples are not actually a new problem; outlier detection has been an issue for years. He suggested that adversarial examples are much easier to combat with a human in the loop.
Chellappa discussed deep learning efforts for unconstrained face verification in more detail. Since 2014, this work has been supported by the IARPA Janus program and is a collaboration among the University of Maryland, Carnegie Mellon University, Columbia University, Johns Hopkins University, the University of Colorado, Colorado Springs, and the University of Texas, Dallas. This team is working on multitask learning in deep networks and network-of-networks problems. They have achieved state-of-the-art performance on face verification, search, and clustering tasks using a relatively small training data set, and their work has important implications for the field of forensics. Chellappa also discussed their work in
___________________
2 For more information about the Deep Intermodal Video Analytics research program, see Intelligence Advanced Research Projects Activity, “Deep Intermodal Video Analytics (DIVA),” https://www.iarpa.gov/index.php/research-programs/diva, accessed February 19, 2019.
hyperface architecture, which utilizes deep neural networks. By sharing features, multiple tasks could be completed to address detection problems (e.g., pose estimation, age estimation). A good gallery of images is typically needed to build a three-dimensional (3D) model; however, for this project, they determined that 3D models were not needed. Performance increased with a focus on feature distribution. Chellappa presented face recognition and verification results on many publicly available challenge data sets made available by the IARPA Janus program. Hoogs observed that many programs rely on closed data sets that can only be viewed by the performer. As a result, papers are often rejected because the reviewers cannot evaluate the methods based on the data. If these programs’ practices were more aligned with the open standard of the field, Hoogs continued, people would participate more often. Boult added that this lack of open data is not only impacting one’s ability to publish but it is also limiting how and when problems could be solved. For example, if people who are not funded by these programs had access to the data, they might be able to provide better ideas to the performers and the government. He emphasized that the practice of sequestering data is bad for advancing science.
Chellappa next described an experiment with forensic examiners, human super-recognizers, and face recognition algorithms (Phillips et al., 2018). The experiment compared recognition capabilities of algorithms versus humans, and the results indicated that the best algorithm was performing much like a forensic examiner. Enabling human–machine collaboration combines the strengths and weaknesses of each and results in more accurate predictions. He noted the tremendous opportunity for learning of all kinds when humans and machines work together, especially in digital pathology and other health applications.
Chellappa’s next topic was on adversarial learning using generative adversarial networks (GANs). He is most interested in GANs and domain adaptation to model the domain shift between the source and target domains in an unsupervised manner. GANs are excellent models that can be conditioned on learned embeddings and prompt the following questions: Can we extract knowledge of the target distribution using a generative process during training? Can we perform adaptation in a task-agnostic manner? With a conditional GAN, he continued, one works on the features themselves instead of on the data. Deep convolutional neural networks and GANs are popular because they perform well in domain transfers where many other approaches would fail.
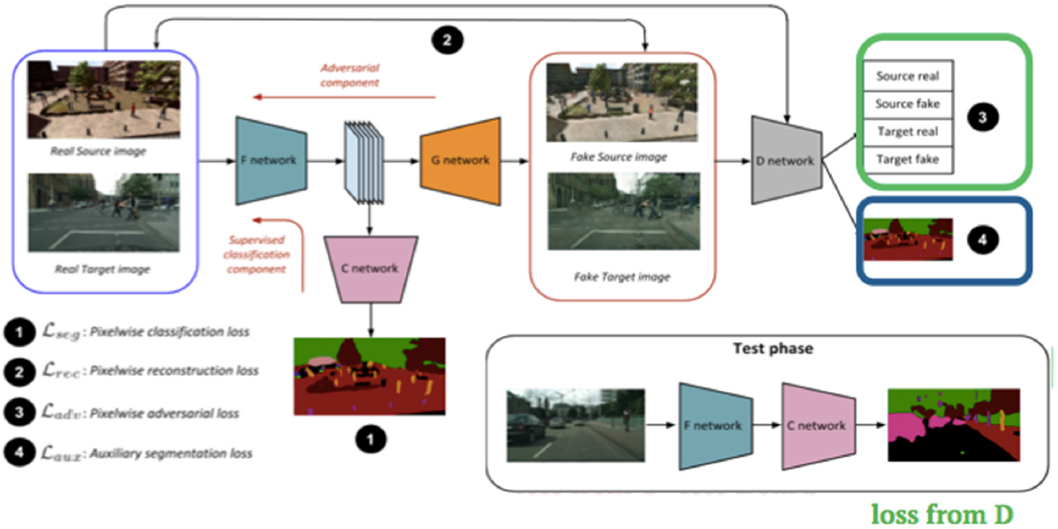
Another problem in domain adaptation is semantic segmentation. Chellappa described an experiment aimed at utilizing synthetically generated labeled data and unlabeled real data to reduce the domain shift when evaluated on real data. Typically, learning algorithms perform poorly on samples drawn from a distribution other than training data, and deep models trained on synthetic data do not generalize well to real data. However, labeling real data is difficult and time consuming. Chellappa proposed a GAN-based training approach to learn a common feature space where the distance between source and target distributions is minimized. Contrary to several other approaches to domain adaptation, this addresses the large-scale semantic segmentation task, which increases the practical significance of the work. The pipeline consists of two main components: a supervised component and an adversarial component. The loss term consists of three parts: (1) the supervisory loss from the classification net, (2) the auxiliary classification loss from the discriminator, and (3) the domain prediction loss from the discriminator. All of the networks are trained in an end-to-end fashion. During test time, the network is deployed as a simple standalone network without the GAN components (see Figure 6.2).
Chellappa and his team also performed quantitative experiments over two large-scale adaptation settings: SYNTHIA3 to CITYSCAPES4 and Grand Theft Auto-5 to CITYSCAPES. The results on SYNTHIA to CITYSCAPES shows a mean intersection over union gain of 9.1 over a stronger source-only baseline network compared to previous approaches. Similarly, results on GTA-5 to CITYSCAPES also revealed a significant improvement in the baseline performance and as compared to previous approaches. It can be clearly observed that the improved generator quality results in an improved performance. He said that the field is improving in the creation of synthetic data and added that because GANs have hundreds of thousands of data, they are useful tools.
___________________
3 The SYNTHIA data set is available at http://synthia-dataset.net/, accessed February 19, 2019.
4 The CITYSCAPES data set is available at https://www.cityscapes-dataset.com/, accessed February 19, 2019.

He explained that, given our robust statistics literature, it should not be a surprise that even small perturbations can break deep learning networks, which are hierarchical nonlinear regression models. He next discussed two current defense approaches: Defense-GAN (i.e., an algorithm to detect outliers; see Figure 6.3) and (2) Network-based solution (based on compact convolutional and L2-SoftMax loss function). He reiterated that the output of the deep network should be looked at by the human in the loop. He said that the Defense-GAN is robust to Carlini-Wagner attacks; however, he noted that there is still work to do since no universal solution exists. The Defense-GAN is only a partially robust approach at 55 percent accuracy. Chellappa added that there is a theoretical justification for the Defense-GAN in the context of bounds (Fawzi et al., 2018) and said that bounds are important.
Chellappa suggested that networks could be fortified by hiding layers in a deep network to identify when the hidden states are off the data manifold and map these hidden states back to parts of the data manifold where the network performs well (Lamb et al., 2018). He said that because GANs are data-sensitive, not problem-specific, additional work is needed. He suggested that people in adversarial research put things in perspective in terms of how the work will be used and what issues will arise. With compact convolution, another way to structure the network, it is possible to constrain features to lie on a hypersphere manifold. Humans can distinguish the differences in adversarial examples with compact convolutional network sample perturbations. Medicine is another domain worth further consideration in the context of deep learning and artificial intelligence, according to Chellappa. At the 2019 Digital Pathology and Artificial Intelligence (AI) Congress: USA, he continued, GANs and domain adaptation for clinical research and health care will be an important topic.
Chellappa closed his presentation by discussing the medium- and long-term research opportunities for the field of computer vision. In the medium term, he hopes researchers will explore the robustness of deeper networks; work with multi-modal inputs; increase theoretical analysis; investigate how humans and machines can work together to thwart adversarial attacks; and demonstrate on more difficult computer visions problems (e.g., face verification and identification, action detection, detection of doctored media). He suggested that approaches based on MNIST (Modified National Institute of Standards and Technology database) data might not be effective for real computer vision problems. In the long term, research opportunities include adaptive networks (i.e., changing the network configuration and parameters in a probabilistic manner with guaranteed performance); humans and machines working together; and design networks that incorporate common sense reasoning. Boult noted that the fundamental problem, which is the existence of attackers, has to be addressed at some point. Hoogs said that Kitware, Inc., has a large group in medical image analysis. The medical community has been slower to implement new imaging technologies than other communities, but a 2018 conference on AI for radiologists emphasized deep learning. He described this as evidence that a revolution is impending and noted that regulatory and acceptance issues central to the medical field might also be of interest to the IC.
RECENT ADVANCES IN OPTIMIZATION FOR MACHINE LEARNING
Tom Goldstein, University of Maryland
Tom Goldstein, University of Maryland, explained that his talk would focus on theoretical perspectives on adversarial examples. He said that most people are familiar with evasion attacks in which malicious samples are modified at test time to evade detection. These attacks will fail in situations when one cannot control the properties of test time data. Another type of threat model is a poison attack in which the adversary controls the training data and manipulates the classifier during training. Poison attacks present substantial security risks and typically are initiated by bad actors or inside agents or enabled by harvesting system inputs or scraping images from the web.
Goldstein described the poisoning process, using an image that has been classified by ImageNet as an airplane, which is then attacked by an image of a “poison” frog. An image of a frog is attacked with a perturbation, and the new image is added to the training set. At test time, the classification of the airplane changes to a different class without anyone ever manipulating the test image itself (see Figure 6.4).
Goldstein explained that these attacks could be created in one of two contexts: transfer learning or end-to-end re-training. In transfer learning, a standard pre-trained net is used, the feature extraction layers are frozen, and the classification layers are re-trained. He described this as a common practice in industry in which it is possible to make a “one-shot kill.” In end-to-end re-training, a pre-trained net is used and then all layers are re-trained. This approach requires multiple poisons.
Goldstein provided an example of the transfer learning approach to creating a poison image via a collision attack. With the same base image (frog) and target image (airplane) as before, the goal is for these terms to collide in the feature space. When solving the optimization problem, the objective is low. A poison
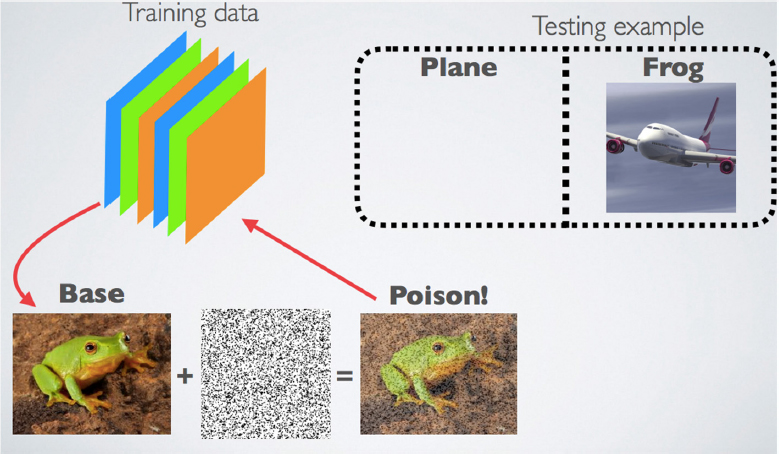
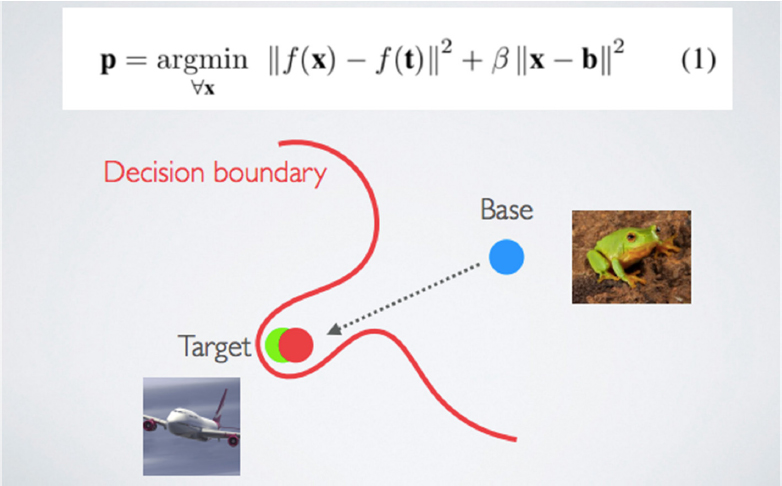
image that looks like a frog collides with the airplane image in the feature space and is correctly labeled as a frog. The decision boundary moves and classifies objects in the feature space as frogs, so then the airplane will be classified as a frog at test time (see Figure 6.5).
In another example, Goldstein showed how he used an ImageNet classifier to classify fish images as fish. He then added a poison image to change the classification of the test images, thus creating poison dogs. After adding that image to the data set, the fish images are classified as dogs at test time. In this instance, it only took one poison image to change the behavior of the classifier at test time. Terry Boult, University of Colorado, Colorado Springs, asked if recomputing happens at every stage, since the feature representations are evolving, and Goldstein responded that since one is only training the deeper layers of
the network, one only needs to fool the feature representation that comes out of the feature extractor. He added that adversarial end-to-end networks are more complicated than this transfer learning case. He continued that these are called “clean label” attacks because the poisons are labeled “correctly”; the performance only changes on selected targets. These attacks are easily executed by outsiders and are difficult to detect (i.e., the picture of the base frog and poison frog look identical, so an auditor would not notice any differences). A workshop participant asked how broadly the attack works if one has a slightly different image of an airplane, for example, and if it would still be misclassified. Goldstein said that his team is working on getting this approach to work with a broader class of objects. In response to another question, Goldstein noted that detecting poison examples is similar to detecting adversarial examples. An audience participant asked if there is a way to leverage and protect the privacy of people’s images online. Goldstein replied that when a person posts their picture online, it is labeled. Depending on the context, the picture could be targeted with either an evasion attack or a poison attack. Goldstein added that if a person does not want someone to train a classifier on him, they could add perturbations to the image to make it impossible to train a classifier on the image.
Goldstein turned to a discussion of end-to-end training, in which multiple poisons are required. In this case, the feature extractors learn to ignore adversarial perturbation. He showed a plot from multiple experiments that compared the number of poisons in terms of success rate and concluded that watermarking plus poisons leads to success. With about 50 poisons, the rate of successful attack was approximately 70 percent. In another example, it took 60 poison dogs to cause a bird to be misclassified in end-to-end training (i.e., without a pre-trained feature extractor, many more poisons are needed).
Speaking specifically of adversarial examples from a theoretical perspective, Goldstein explained that there has been constant back and forth between attacks and proposed fixes; ultimately, the state-of-the-art defenses are only partially robust. So, the fundamental question becomes whether adversarial examples are inevitable. To answer this question, most people assume that human perception is not exploitable and that high-dimensional spaces are not too strange—two assumptions with which he disagrees. Goldstein presented a toy problem to better understand adversarial examples: Using a sphere, one can make a simple classifier that slices the sphere into two areas, Class A and Class B. Class A covers 50 percent of the surface area of the sphere. The question of interest is whether there are adversarial examples for objects in Class A. To answer that question, an ε has to be defined (i.e., how powerful is the attacker?) and one computes the ε expansion of Class B (i.e., epsilon equals 0.1). Next, Class B is expanded by 0.1 units. The ε boundary covers Class A. Areas that are covered have adversarial examples and can be moved into Class B with small perturbations. The ε expansion covers 55 percent of the sphere, which means that most areas remain safe. In higher dimensions (e.g., 100 dimensions), even though ε is still 0.1, with random sampling, 84 percent of Class B is covered, which means most things have adversarial examples. At 1,000 dimensions, 99.8 percent of things sampled are within epsilon expansion, so almost everything is an adversarial example. This random sampling process produces adversarial behavior, and this is the most robust classifier one could construct. Levy and Pellegrino’s 1951 isoperimetric inequality theorem states that the ε-expansion of any set that occupies half of the sphere is at least as big as the ε-expansion of a semi-sphere. So, in 1,000 dimensions, more than 99 percent of things will have adversarial examples. It does not matter how the class is designed; this assumes that the data are uniformly distributed and that the data live on a sphere, neither of which are true in the real world.
Thus, Goldstein shared a more realistic example of image classifiers. He defined an image as points in a unit cube; a class as the probability density function on the cube, bounded by Uc (i.e., a distribution that can be randomly sampled); and a classifier as the entity that partitions the cube into disjoint sets/labels every point in the cube (which is measurable). Using this method, it is possible to prove, in certain situations, that most things are adversarial. One would assume that in higher dimensions, things are more susceptible to adversarial attacks, but that is not actually the case. He also noted that sparse adversarial examples result when perturbations are hidden in high-frequency images. Goldstein explained that people believe high dimensionality is responsible for adversarial examples because it is hard to fool low-dimensional images in MNIST, for example. However, high dimensionality is not responsible for adversarial examples. There are 1 million ways in which MNIST is different from ImageNet; these are
completely different problems, which are more complicated than what people have assumed. Goldstein performed an experiment in which the image class is kept constant while the dimensionality is changed so as to isolate dimensionality as a variable. He clarified that adversarials are not necessarily worse on the larger MNIST. The dimensionality does not affect adversarial susceptibility, and this holds true in the real world—experiments with real neural nets agree with the theoretical results.
Goldstein explained that the CIFAR data set is more susceptible than the MNIST data set, and ImageNet is more susceptible than CIFAR. He conducted another experiment to show that adversarial susceptibility does not depend on dimensionality, but it does depend on the complexity of the image class. Complex image classes have low density. Returning to the question of whether adversarial examples are inevitable, Goldstein asserted that such a question is not well posed because the answer depends on the epsilon and p-norm chosen, as well as a number of other things.
Goldstein summarized key takeaways from his presentation: (1) adversarial robustness has fundamental limits, and those limits cannot be escaped; (2) adversarial robustness is not specific to neural nets, so clever approaches do not offer an escape; and (3) the robustness limit for neural nets might be far worse than intuition suggests. He noted that the community still has a long way to go in designing better defenses, there are no “certifiable” defenses, and the best defense is still a black-box model. Chellappa asked a question about how Goldstein’s work relates to the work of Fawzi et al. (2018), who claim that all classifiers are prone to attack. Goldstein noted that Fawzi et al.’s work uses a different set of assumptions, so it is difficult to compare the two.
FORECASTING USING MACHINE LEARNING
Aram Galstyan, Information Sciences Institute, University of Southern California
Aram Galstyan, University of Southern California, opened his presentation with a discussion of a 1.5-year-long project on hybrid forecasting of geopolitical events before moving to a brief discussion about machine learning. Geopolitical forecasting begins with an individual forecasting problem (IFP). An example of an IFP is “Will the United Nations Security Council adopt a resolution concerning the Democratic Republic of Congo between 15 October 2018 and 15 December 2018?” Each forecasting question should have well-defined resolution criteria, Galstyan explained. The goal of forecasting is to try to solicit probability distribution on possible outcomes, not to try to determine whether something happened. The accuracy of a given forecast can be evaluated using a Brier score, which measures the accuracy of probabilistic predictions.
He described IARPA’s Aggregative Contingent Estimation (ACE) program5 from a few years ago that enhanced forecasting accuracy by combining the judgments of many forecasters who were not expert analysts. The ACE competition revealed that people with no prior forecasting experience could be trained to be good forecasters. The leader of the group who won the competition wrote a book entitled Superforecasting: The Art and Science of Prediction, which stated that the untrained were able to generate forecasts as accurate as those of trained analysts. The Hybrid Forecasting Competition6 succeeds the IARPA ACE program and is developing and testing hybrid geopolitical forecasting systems. These systems integrate human and machine forecasting components to create maximally accurate, flexible, and scalable forecasting capabilities.
Galstyan’s project, Synergistic Anticipation of Geopolitical Events (SAGE), is a collaboration among multiple universities and companies. The SAGE hybrid forecasting framework/pipeline is the fairly
___________________
5 For more information on the ACE research program, see Intelligence Advanced Research Projects Activity, “Aggregative Contingent Estimation (ACE),” https://www.iarpa.gov/index.php/research-programs/ace, accessed February 19, 2019.
6 For more information on the hybrid forecasting competition, see IARPA, “HFC Hybrid Forecasting Competition,” https://www.hybridforecasting.com/, accessed February 19, 2019.
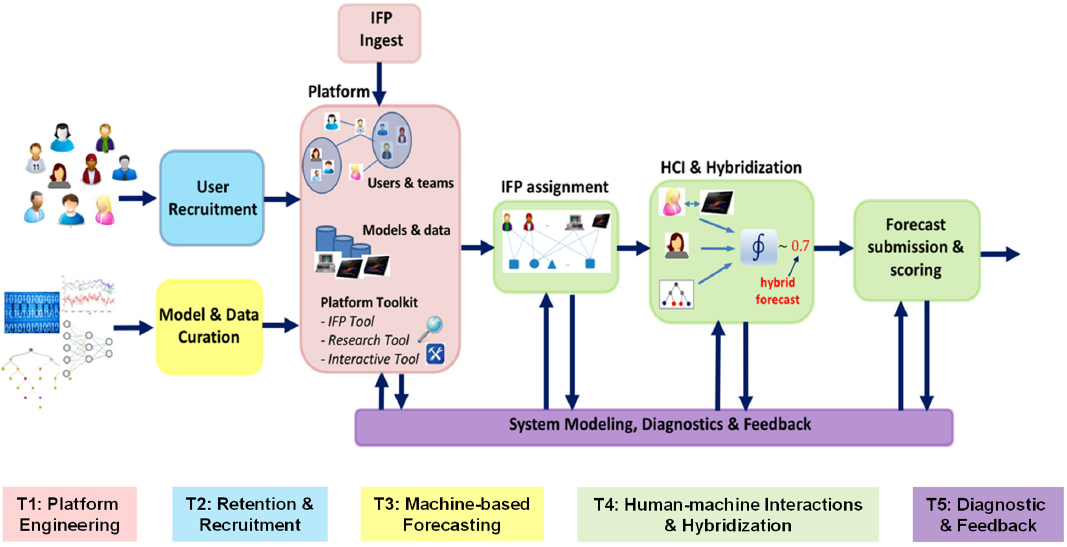
complicated system used to generate an automated forecast, with five interrelated tasks: (1) platform engineering (i.e., a web-based platform where users study forecasting questions and generate forecasts), (2) retention and recruitment (i.e., keeping volunteers engaged and interested in this time-consuming activity), (3) machine-based forecasting, (4) human-machine interactions and hybridization, and (5) diagnostic and feedback (see Figure 6.6). He emphasized that this research is interdisciplinary, drawing on expertise in forecasting, human judgment, machine learning, decision making, human–machine interfaces, and textual analysis.
Galstyan noted that the most challenging questions are those without historical precedent and for which statistical models cannot be used. He also believes that there should be no human in the loop for forecast generation. Instead, models should run out-of-the-box after the forecasting question is generated. Tailored models are not built; the fully automated pipeline is used, generating a reading list for users, which can be used to help make an informed decision. For the sake of simplicity for users, Phase 1 of the project has only one model, the AutoRegressive Integrated Moving Average (ARIMA) model for time series forecasts, and it is not a machine learning model. Once the data are received, the system automatically gets the parameters for ARIMA, generates forecast and confidence intervals, and shows the visualization of the model output to the users. A knowledge graph ontology is needed for this process because most of these questions are about events (i.e., all data are represented as events or time series). One issue in this process is scalability; even after some filtering, 150,000 articles from Lexis Nexis are tagged. Using smart sentence segmentation, it is possible to overcome this magnitude of information and find relevant content for users. He explained that Phase 1 had three different experimental conditions in order to see what the machine models added to the forecasting process. Condition A is a baseline (i.e., the user is shown no machine outputs); Condition B is a base rate (i.e., the user is shown historical data); and Condition C shows both the historical data and machine forecast. Next, a general aggregation approach is used to aggregate the individual forecast from the user with the machine forecast into a single forecast. He noted that much literature on crowdsourcing exists for how to aggregate this information. Essentially, a weighted average (where weights dynamically adapt based on performance of different forecasters on different questions) is used. The following findings emerged from the first year of the project: (1) the best accuracy was achieved in Condition B; (2) there is
statistically significant improvement in performance in the second half of the randomized controlled trial and improved accuracy of the machine models; (3) something is always going to break (i.e., data will sometimes have missing values or the right data will be unavailable); and (4) machine model accuracy improved over time as the pipeline became more stable.
Galstyan next discussed SAGE and algorithmic aversion; in other words, to what extent do human forecasters trust predictions made by machine models? For example, in an example of misplaced trust, forecasters in Condition C were affected by machine predictions. They adjusted their forecasts toward the forecast of the machine models, even when the machine forecast was inaccurate. This explains why the accuracy in Condition C was poor. An audience participant wondered if the forecasters choose the model prediction because there are no consequences associated with an incorrect decision. Galstyan explained that even though the forecasters were volunteers, the opportunity was considered prestigious and thus people still did their best work. However, he said that the participant’s point of concern is valid, and discussions have begun about offering prize money to the best-performing forecasters. In response to a question from another audience member, Galstyan replied that there is a positive effect from the confirmation bias: when the machine forecast agrees with the human forecast, the human moves even further in that direction. In response to another question, Galstyan said that training materials explain to the user how ARIMA works, but users are not told how the model came up with a particular forecast. One of the hypotheses people have explored is that humans do not trust machine predictions because they do not trust a black box and do not know how things work. He does not know how much that trust would change if the process for generating the forecast were to be explained, because even if a user does not understand how a forecast was generated, there is still an influence of the machine model.
Finally, Galstyan discussed SAGE and forecasting rare events. An example IFP could be “Will Austrian journalist Max Zirngast be released by Turkish authorities by October 1, 2018?” The objective is to generate machine forecasts without any historical data upon which to build a meaningful model. Similarity-based forecasting is used. To do this, a bank of similar historical IFPs is leveraged to make a forecast. He noted that it is clear that forecasting questions are not independent; outcomes of IFPs can be interdependent. So it is necessary to explore dependencies and correlations and come up with a predictive model. Galstyan described two geopolitical event data sets: (1) Global Database of Events, Language, and Tone7 and (2) Integrated Crisis Early Warning System.8 Each includes coded interactions between sociopolitical actors, and both use the conflict and mediation event observation (CAMEO) coding scheme. These data sets and their coding schema can be used to do zero-shot forecasting, in which the question is parsed into a CAMEO code and mapped. The related CAMEO codes are leveraged to build a model for a particular event. Past events contain useful information for predictions of future events, so the past history of events can be leveraged to come up with better-than-random accuracy. Carefully constructing the training data set allows performance better than the baseline, according to Galstyan.
He emphasized that the best performing methods combine the efforts of humans and machines. He presented a roadmap for the Intelligence Community, including using hybrid sensemaking systems (i.e., analysts working synergistically with different machine models to come up with situational awareness). In the final section of his presentation, Galstyan discussed covariance estimation at scale. He said that it is difficult to understand how two variables are related when the number of samples is less than or equal to the number of variables. He listed a series of broad approaches to estimating covariance: Bayesian methods, sparse methods, and factor methods. He introduced a new factor method, Total Correlation Explanation (CorEx), which finds hidden factors that are uniquely informative about relationships. CorEx outperforms GLASSO, used in the sparse method, in the undersampled regime. And, Temporal CorEx performs significantly better than the state of the art and could also be used to detect anomalies. The most important aspect of this new method is the scalability and its ability to run on a large data set, Galstyan concluded.
___________________
7 The Global Database of Events, Language, and Tone data set is available at https://www.gdeltproject.org/, accessed February 19, 2019.
8 The Integrated Crisis Early Warning System dataverse is available at https://dataverse.harvard.edu/dataverse.xhtml?alias=icews, accessed February 19, 2019.












