
In the final session of the workshop, panelists considered steps needed to incentivize and promote data sharing and reuse. Liz Roberts, senior director and global public policy lead at UCB Biosciences, discussed how trial sponsors could make shared data more useful to secondary data users. Colin Baigent, deputy director of the Clinical Trial Services Unit and Epidemiological Studies Unit (CTSU) at Oxford University, provided examples of how individual participant data (IPD) meta-analysis can lead to new and important findings that impact patient care. Amy Nurnberger, program head of data management service at the Massachusetts Institute of Technology (MIT), discussed the roles and relationships of institutions and other clinical research stakeholders in sharing trial data, and the value of engaging libraries in data management activities. Georgina Humphreys, clinical data sharing manager at Wellcome Trust, discussed Wellcome’s broad approach to maximizing the value of research data and how open sharing of clinical trial IPD can lead to direct impacts on patient care. The session was moderated by Roberts. Closing remarks were then provided by Joanne Waldstreicher and Jeffrey M. Drazen.
SPONSOR PERSPECTIVE
Liz Roberts, Senior Director and Global Public Policy Lead, UCB Biosciences
Roberts drew on her experience in industry, primarily as a data generator, but with some experience as a data user.1
Value Proposition for Data Sharing
The concept of value-based transparency means sharing information that adds value, not sharing for the sake of sharing. In this regard, Roberts said there is little value, per se, in pharmaceutical clinical trial sponsors listing their trials for IPD sharing. A website with a long list of trials does
___________________
1 Roberts stated that these views are her personal views, and not necessarily those of her company or any other company.
not add value in itself. To be of value, researchers need to be able to find the right trials for their proposals. She said this requires data generators and users working together toward their shared goal “to find new scientific insights and advance human health care.”
Advancing human health care is one of the main value-based motivations for pharmaceutical companies to share data, Roberts said. As has been noted by other speakers, she said there is an increasing recognition of the role of trial participants and that responsible sharing of data is a sign of respect for their contribution. She emphasized that sharing must be done responsibly, and there are legal frameworks (e.g., data sharing and use agreements), secure sharing environments, and other structures to help ensure this.
To be of value, Roberts said, data must be shared in a way that works for data users. Otherwise, she said, all the effort that goes into sharing is wasted. Data generators and data users need to work together to find solutions to the challenges of data sharing, Roberts emphasized. To illustrate, she said there have been many cases where her company has approved a data request, signed the data use agreement, and uploaded the anonymized IPD that was requested by a research team, only to find that they never returned to access the data in the system. She said these missed opportunities suggest that the right value proposition has not yet been found.
Challenges and Solutions
A paradigm shift is needed in the clinical research environment, Roberts said, and she offered several solutions for further consideration.
- Standards. The need for standards has been discussed by many panelists. Roberts said that volumes of documentation accompany IPD. Although companies share the same information (e.g., clinical study reports, case report forms, protocols, statistical analysis plans, etc.), it is likely in different formats, which is a challenge for researchers to navigate.
- Clarity in data-sharing policies. Policies for which data are shared and when vary across clinical trial sponsors, and it can be challenging for researchers to know when data might be available for analysis. Roberts observed, for example, that some will share Phase 1 trial data, while others are less comfortable in doing so. Data might be made available to share after publication of the primary manuscript, or after regulatory approval in one or more countries. Greater clarity is needed in company policies regarding the availability of trial information, she said.
- Therapeutic area data pooling. Roberts suggested that, for a particular therapeutic area, companies could agree to use the same data standards, use the same trusted third party to anonymize data using the same algorithm, and pool their datasets, making them available to researchers. She acknowledged that there could be obstacles to overcome, but that this approach could help to reduce the challenges researchers face when navigating the different formats used by different companies.
- Findable, accessible, interoperable, and reusable (FAIR)2 multi-stakeholder platforms. Another potential solution is the development of a multi-stakeholder platform to make it more transparent for researchers to find the data they need for analyses. The goal is to maximize the clinical utility of the data being shared, Roberts said, while ensuring that participant privacy is protected. There is a lot of information being shared on platforms and company websites, she said, and the challenge is for the research community to be able find it. Trial datasets that are shared need to be FAIR, and she noted the value of digital object identifiers.
Key Players
Roberts highlighted three key functions in the data-sharing process that add value. The role of the independent review panel (IRP) in assessing the scientific merit of data requests submitted to platforms is an important element of the data-sharing process, she said. The sponsor should not be the judge for what research should be allowed. Funders are essential for their support of clinical trial data generation outside of industry research and development, she continued, and there are valuable data being shared by academic researchers. Finally, the International Committee of Medical Journal Editors (ICMJE) policies that address prospective trial registration, data-sharing statements in manuscripts, and the inclusion of a data-sharing plan in trial registration have enabled sponsors to plan up front and to better coordinate the roles within the company that are involved in the process of data sharing.
Looking Forward
A host of incremental improvements can be made to enhance clinical trial data sharing, such as reducing the cycle times for completing data-sharing requests, Roberts said. But she believed it is time to focus on a paradigm shift in the environment. She emphasized the need to “start
___________________
2 See footnote 3 on p. 64.
with the end in mind” by picturing the future and designing trials accordingly, rather than attempting to retrofit solutions.
RESEARCHER PERSPECTIVE
Colin Baigent, Deputy Director, Clinical Trial Service Unit and Epidemiological Studies Unit, Oxford University
Baigent discussed extracting value from shared clinical trial data to enhance patient care from his perspective as an IPD meta-analyst and as a data sharer through his role as director of the Medical Research Council (MRC) Population Health Research Unit.
Societal Value of Sharing Clinical Trial Data
A variety of different analyses can be conducted using randomized controlled trial data, and Baigent mapped them according to their relative societal value (see Figure 9-1). The predefined primary outcomes of a randomized controlled trial are analyzed by the principal investigators and the research team. Subsidiary analyses are also done (e.g., for secondary outcomes), most often by those involved in the conduct of the trial, and analysis of exploratory outcomes can be used to inform new research. Baigent pointed out that these three types of analyses “respect the randomized structure” and should therefore not be impacted by bias. Non-randomized analyses that ignore the treatment allocation might also be done, but these are subject to bias, especially index event bias. As shown in Figure 9-1, Baigent said that exploratory and non-randomized analyses are generally of lower value to society. At the other end of the scale is IPD meta-analysis, which he argued is “the highest form of value that one can derive from [re-use of] a randomized trial.” He added that a value assessment of the different types of analyses of randomized controlled trial data is needed.
The Value of IPD Meta-Analysis of Shared Data
To illustrate the ways in which IPD meta-analysis can lead to new and important findings, Baigent described an analysis of data by the Cholesterol Treatment Trialists’ (CTT) Collaboration.3 CTT was established in 1994 to conduct systematic analyses of IPD from statin trials, which, at the time, were individually of insufficient size to study mortality out-
___________________
3 See https://www.cttcollaboration.org (accessed February 10, 2020).
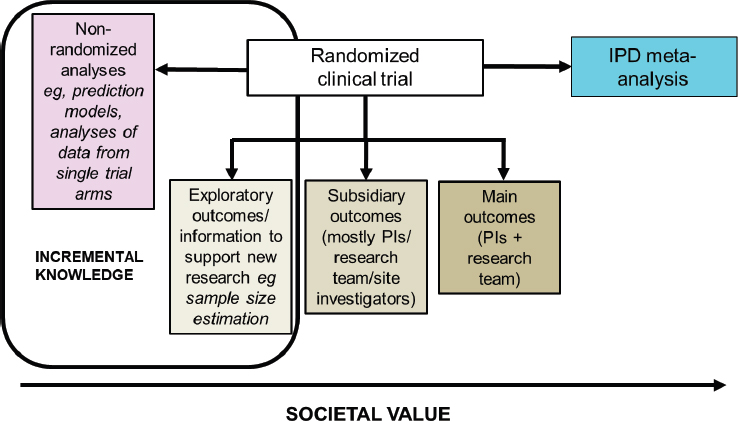
NOTE: IPD = individual participant data; PI = principal investigator.
SOURCE: As presented by Colin Baigent, November 19, 2019.
comes. There were no data-sharing platforms at the time, he noted, and collaborators were requested to share a very specific, standardized dataset from their trial (baseline data; vascular events; cancer; all-cause mortality; demographics; and lipid profiles at baseline, 1 year, and at the final visit). CTT has assembled data from 28 statin trials of 175,000 participants, and its meta-analyses have produced 10 major publications that have collectively been cited more than 10,000 times. This long-term database is maintained by the CTSU at Oxford, and Baigent emphasized the need to preserve such databases independent of the potential uncertainties of data-sharing platforms. He then discussed several of the ways that IPD meta-analysis of shared trial data can provide increased value.
Effects on Particular Outcomes
IPD meta-analysis allows for analysis of intervention effects on individual components of an outcome. Baigent explained that individual trials generally record a limited number of outcomes, and findings are often reported relative to a composite outcome (e.g., heart attack, stroke, death). The first CTT meta-analysis in 2005 studies the effect of lowering low-density lipoprotein (LDL) cholesterol on the incidence of major vascular events. Data were assembled on 13,000 events that occurred in the treatment and control groups of 14 statin trials (data are numbers of events, not numbers of patients with events). Baigent showed that the
effects of lowering LDL on each of the different types of vascular events (coronary events, stroke, and coronary revascularization procedures) were similar for a given reduction in LDL cholesterol. However, when the individual components of these outcomes were evaluated, it became clear that the number of hemorrhagic strokes was not reduced. These findings are not apparent when considering the trials individually. In addition, IPD meta-analysis allows for reporting of relative risk reduction per/mmol reduction in LDL cholesterol (which accounts for dose variation across trials).
Timing of Treatment Effects
IPD meta-analysis allows for understanding the timing of a particular effect. Baigent described a different analysis that showed the effect of lowering LDL cholesterol on major vascular events over time. The data suggest that the effect during the first year of statin treatment is half of what it is in later years. This finding is also not apparent from the individual trial data, he said. This finding from the meta-analysis is important for the design and interpretation of trials of LDL-lowering therapies. For example, he said the trials of PCSK9 inhibitors were about 2 years long, and the effects were less than expected. By analyzing shared data on statin therapy, it was able to be determined that this finding was related to the short duration of the PCSK9 trials.
Definition of Whom to Treat
IPD meta-analysis can be used to determine whom to treat. Most trials are powered so that they determine whether to use a treatment for a particular condition. The example Baigent described showed the protective effects of lowering LDL cholesterol in individuals with different baseline LDL cholesterol levels. The IPD meta-analysis found that participants still experienced the protective benefit of lowering their LDL cholesterol levels with statin treatments regardless of their levels at the start of the trial. This is of value, he said, because people can have low LDL cholesterol levels and still be at high risk for a cardiac event. The meta-analysis shows that lowering LDL cholesterol is still beneficial for high-risk patients who do not have high LDL levels.
Unanswered Questions in Need of New Trials
IPD meta-analyses can help to define the research agenda. Baigent described data from a presentation given originally to the U.S. Food and Drug Administration that showed the effects of statins according to base-
line renal function. The meta-analysis found that data from individuals with a low glomerular filtration rate were limited. Identifying this gap led to a randomized controlled trial of 9,500 patients, which found that reducing LDL cholesterol is effective in reducing vascular events in this particular subpopulation, members of which, he said, were not being prescribed statins at that time.
Patient Safety
CTT is currently conducting an IPD meta-analysis of all adverse events recorded in the trials in its database. Baigent said that misinformation about the adverse effects of statins is spreading, and the analysis will look for evidence of any association of statin use with increased risk for a range of adverse events.4 A challenge, he said, is that the original request for trial data was for a defined standard dataset, as discussed above. For this meta-analysis, CTT had to ask for a new dataset from the original trials and then merge the new and old datasets. Clarifying the risk of adverse events will be of high value to patients on statin therapy, he said.
Baigent added that, for a variety of reasons, it has not been possible to leverage all of the data-sharing platforms to gather and maintain the necessary data for this analysis (e.g., the need to maintain the data locally). In this regard, he emphasized the importance of data structures that can support IPD meta-analysis in the long term. A viable approach, he continued, is to enter data use agreements (DUAs) with trial sponsors to share their data, as has been done in the past.
Potential Next Steps
These examples demonstrate how IPD meta-analysis is a high-value use of shared randomized controlled trial data and “can provide enormously important data to help manage patients,” Baigent concluded. However, data-sharing platforms are not ideally suited for IPD meta-analysis when multiple sponsors are involved. In particular, data need to be maintained locally for flexibility in analysis (e.g., multi-variate modeling).
Various platform metrics have been discussed throughout the meeting (e.g., numbers of data requests, datasets provided, publications). What is needed, Baigent said, is new, rigorous research that classifies and evaluates the range of different outputs from data sharing, including outputs that are of societal value.
___________________
4 See https://www.sciencedirect.com/science/article/pii/S0002870316000326 (accessed April 1, 2020).
Baigent concurred with the remarks by other panelists that the focus should change from making all trials available for sharing to making the most informative data available (e.g., from pivotal studies) and encouraging their reuse. He agreed that attention should be on collecting and maintaining data in a form suitable for sharing, but not necessarily routinely depositing it somewhere.
INSTITUTIONAL PERSPECTIVE
Amy Nurnberger, Program Head of Data Management Services, Massachusetts Institute of Technology
Nurnberger, Program Health of Data Management Services at MIT Libraries, discussed stakeholder roles in sharing trial data and the value of engaging libraries in data management activities. She adapted the five laws of library science by S. R. Ranganathan to data science: “Information, or data, [are] for use, … for every person there is information they are looking to use, for every piece of information there is a potential user, … save the time of the user, … the library is a growing organism.”
Realizing the Value of Data Sharing
Nurnberger asserted that the value of data sharing is worth the cost but said there is “infrastructure debt” to be addressed to fully realize that value. First, as has been discussed, Nurnberger said that clinical trial data need to be FAIR. She pointed out that the FAIR principles, as outlined, refer to machine actionability of data (i.e., computational capacity to interact with data). This capacity is still evolving, and with it, the potential of FAIR data. As an example of building on the promise of FAIR data, she mentioned the Personal Health Train being developed by the Dutch Techcentre for Life Sciences.5
Another issue is the need for a data-sharing incentive structure and the ability to award credit. Nurnberger suggested looking to other disciplines for technologies and lessons. She also referred participants to the Make Data Count project.6 She called on participants to advocate for and use persistent unique identifiers for their datasets, which enable tracking of citations as an output of trial registration.
A persistent concern is the limited number of publications stemming from shared data. Nurnberger recommended reaching out to researchers who have not followed through on their data request to find out why. In
___________________
5 See https://www.dtls.nl/fair-data/personal-health-train (accessed February 10, 2020).
6 See https://makedatacount.org (accessed February 10, 2020).
other disciplines, she said, concerns about being able to trust the data or whether the data will be fit for a researcher’s intended use are among the reasons that shared data are not employed. She mentioned the Data Nutrition Project as an example of how the quality of a dataset might be communicated to interested researchers.7
Clinical investigators and researchers are not trained in data management or making data FAIR, Nurnberger continued. Data professionals—including data stewards, curators, librarians, archivists, and others—are part of the infrastructure that needs to be built up and better leveraged for clinical trial data sharing. She mentioned the EDISON project of the European Commission, which is working to build the data profession.8
Responsibility for Data Sharing
Nurnberger diagrammed the complex “constellation of responsibilities” for data sharing. She focused her comments on the roles and relationships of institutions, funders, and researchers—but first acknowledged some of the other key contributors that have promoted a cultural shift toward sharing and transparency. These include publishers (especially the ICMJE policies that address data sharing); societies and associations (including the National Academies’ Roundtable on Aligning Incentives for Open Science); and industry efforts to share data through platform initiatives (e.g., Yale University Open Data Access Project, Supporting Open Access for Researchers, Vivli, CSDR, and others).
Institutions
Institutions are the operational frameworks in which research is conducted, Nurnberger said. Institutions have roles and responsibilities associated with the following:
- Fulfillment of grant terms
- Promotion and tenure
- Legal concerns, such as compliance with data privacy and data-sharing regulations, legal interoperability of data, and balancing legal risk and academic responsibilities in DUA
- Institutional review boards and ethical participant consent
- The research environment (e.g., facilities, technology, infrastructure, grant support systems, libraries)
___________________
7 See https://datanutrition.org (accessed February 10, 2020).
8 See https://cordis.europa.eu/project/id/675419 (accessed February 10, 2020).
With regard to the research environment, Nurnberger noted that the European Commission has recommended that 5 percent of research expenditure be allocated to research data management. In the United States, she said, libraries have shifted personnel and services to support the research environment. Libraries have expertise in data management, metadata, and privacy, for example, and she encouraged participants from academia to engage their libraries.
Funders
Funders have a broad scope of operation and influence. They establish requirements and structures. Nurnberger suggested that an important role for funders is following up with grantees. Requirements encourage change, she said, but they can be ineffective without follow-up.
Researchers
Researchers have many responsibilities, such as grant term fulfillment, and are essentially responsible for “adherence to everything,” Nurnberger said. She noted that investigators often spend time on data management activities for their projects, which should be handled by data managers, and she called on funders and institutions to support data managers for research teams. She also called on researchers to make their support for technology and library initiatives known to their institutional administration.
Researchers also have responsibility for the research culture, she said. They shape the culture through their participation in research, publishing, peer review, service on editorial boards, and roles as program officers in funding agencies. That culture is perpetuated in the promotion and tenure processes and is passed on to students. She encouraged researchers to devote course time to “considering the implications of data management and sharing to instill a respect for the practice and its practitioners.” Researchers will not necessarily handle the data management, but there needs to be an awareness that it must be done, she said.
All Stakeholders
All stakeholders are responsible for working together to create a workable research environment, Nurnberger said. Shared responsibilities include developing platforms and standards (building, supporting, and using them), and addressing workforce issues.
Participants and Providers
At the center of the constellation are participants and providers who have a responsibility to be educated and conscientious, and “to remind us who we are responsible to,” Nurnberger said.
Be FAIR and CARE
As discussed above, FAIR is focused on machine interactions. Nurnberger described the CARE Principles for Indigenous Data Governance, developed by the indigenous data sovereignty community, which include Collective benefit, Authority to control, Responsibility, and Ethics.9 Nurnberger said these principles, which recognize that people have a role and responsibility in good data practices, are also relevant to clinical trial research and should be considered when addressing issues of data incentives, policies, standards, and governance.10 “Having the practices, platforms, and policies for good data management, or husbandry, in place to make FAIR data sharing feasible also means that they are there to support legal requirements of [data protection regulations] and moral imperatives of CARE,” she concluded.
FUNDER PERSPECTIVE
Georgina Humphreys, Clinical Data Sharing Manager, Wellcome Trust
One of the key impacts of unavailable data is the inability to reproduce the results of published studies. Humphreys summarized that more than half of researchers could not reproduce their own experimental results, and more than 70 percent could not reproduce the work of other researchers.11 In addition, pharmaceutical companies report not being able to replicate more than 75 percent of the conclusions in the peer-reviewed literature, which she said impacts translation of findings to practice and ultimately affects patient care. As a funder of clinical science, she expressed particular concern about the impact of irreproducibility on patient care, and she discussed Wellcome’s approach to maximizing the value of research data.
___________________
9 See https://www.gida-global.org/care (accessed February 10, 2020).
10 Nurnberger stated that her adaptation of the CARE Principles to clinical trial data sharing was done with the permission of the indigenous data sovereignty community.
11 See https://www.nature.com/news/1-500-scientists-lift-the-lid-on-reproducibility-1.19970 (accessed March 30, 2020).
Open Data Sharing for Direct Impact on Patient Care
One suggested solution to the problem of irreproducibility is to make the data more available, she said. Wellcome Trust has an open-access data policy, and Humphreys said there is emerging evidence across disciplines suggesting more frequent citations of research articles that are linked to open data.
As an example of the impact of open data sharing, Humphreys described the work of the WorldWide Antimalarial Resistance Network (WWARN), where she noted she worked before joining Wellcome. WWARN was founded in 2009 to collate prepublication data from clinical trials of antimalarial drugs for the primary purpose of mapping and tracking drug resistance. The intent was to use this information to influence decisions on resource allocation to better address emerging drug resistance. The challenge, Humphreys said, was that researchers were not willing to share their data, especially prior to publication. To encourage sharing, WWARN created collaborative study groups for researchers to share and analyze IPD. Contributing researchers participated in the secondary analysis process and were authors on many publications. She added that any analyses containing prepublication data would be embargoed until the data contributor had published their work. This approach led to publications with more than 100 authors, she acknowledged, but it demonstrated the potential of precompetitive sharing of data to directly impact patient care.
Humphreys described a specific example in which IPD from more than 7,000 patients across 26 studies of the antimalarial drug, dihydroartemisinin-piperaquine, were pooled for meta-analysis.12 Over 3 years, a team of five to six people collated, curated, and analyzed the data and found that many younger children were being underdosed (at levels below the World Health Organization [WHO]-recommended therapeutic range), and that the treatment was ineffective. As a result of this study and subsequent modeling studies, WHO updated their malaria treatment guidelines—which, she said, had a direct impact on the treatment of children in malaria-endemic countries.
Maximizing the Value of Research Data
Data sharing is “the right thing to do,” Humphreys said, and many of the reasons why were discussed throughout the workshop. However, one single activity will not overcome the challenges of sharing clinical trial
___________________
12 See https://www.wwarn.org/working-together/study-groups/dp-dose-impact-study-group (accessed February 10, 2020).
data, and she said that Wellcome is taking a broad approach to maximizing the value of research data, including the following activities:
- Implementing the Wellcome outputs management policy13
- Ensuring that Wellcome research outputs are FAIR (e.g., through the Wellcome Open Research publishing platform and a pilot program with Springer Nature)14
- Enabling open research through support of activities that promote a sharing culture and facilitate sharing (e.g., support for National Academies activities; IRP secretariat for Vivli and CSDR; signatory on the Declaration on Research Assessment)
- Awarding funding specifically for innovation in open research
Funder Reflections
As one of the funders of this workshop, Humphreys reflected on the themes and lessons she took away from presentations and discussions.
- More input is needed from researchers in low- and middle-income countries, Humphreys noted, because these researchers face different challenges and have developed different solutions compared with researchers in high-resource settings.
- More input is needed from the data generators’ institutions, said Humphreys. Secondary data users discussed the challenges of DUAs and other legal hurdles to successful data requests, and Humphreys suggested that institutions are not always included in discussions of these issues.
- Humphreys added that shared data are not being leveraged effectively for secondary analyses. Pharmaceutical companies and others have invested in systems and platforms for data sharing, but the number of requests to use these data is much lower than anticipated, Humphreys observed. In addition, data requesters frequently “drop out” and do not access the data after receiving approval, or do not complete and publish their proposed studies.
- The costs of conducting secondary analyses remain high, and data harmonization is a challenge, Humphreys summarized. One approach to addressing these issues that was discussed was increas
___________________
13 See https://wellcome.ac.uk/funding/guidance/data-software-materials-management- and-sharing-policy (accessed February 10, 2020).
14 See https://wellcomeopenresearch.org/for-authors/data-guidelines (accessed February 10, 2020) and https://www.springernature.com/gp/campaign/Wellcome-RDS-Pilot, respectively (accessed February 10, 2020).
-
ing the use of standards in prospective data collection, Humphreys recalled. This endeavor will take time, she said, and she cautioned against “enforcing sharing” in a way that leads to the availability of datasets that are of no value for secondary use.
- Bring people together, Humphreys advised, around purpose-driven data sharing and use. As shown in the examples of WWARN and Project Data Sphere, research programs can drive data sharing, Humphreys said; involve those who will use the results (e.g., policy makers, ministries of health).
- Including the voice of the patient in deciding the use of their data is essential, Humphreys reiterated; honor their role as the true sources of the data.
- Learn from the clinical trial registry experience, concluded Humphreys, with regard to driving information sharing forward and creating a paradigm shift.
DISCUSSION
Access to IPD for Meta-Analyses via Platform or Directly
Waldstreicher shared that many research proposals do not require maintaining data locally and can be performed within a secure platform environment. She clarified that, for IPD meta-analyses, data-sharing platforms are meant to supplement—not replace—working directly with original researchers to obtain clinical trial IPD. Platforms can allow IPD meta-analysts to find studies and also benefit from independent review of proposals. Waldstreicher’s company and others will work with researchers to try to provide data for analyses that cannot be completed within the platform or within the company’s secure website. Roberts agreed that her company and others do try to meet the needs of data requesters when the data of interest are housed in multiple platforms. She said these efforts are currently case by case, but also said that she was hopeful for a broader solution in the future.
Baigent shared his experience with seeking datasets from 19 placebo-controlled trials conducted by different statin manufacturers. He said he had experienced manufacturer reluctance in providing the data directly, and was instructed to go through the data-sharing platforms that each company was using. Multiple problems were encountered, he said (e.g., delays in obtaining permission to extract data, inability to upload software efficiently). The solution, he said, was to directly lobby within the companies to seek access to the IPD, and, in many cases, agreements were ultimately reached. Baigent shared his understanding that companies have a vested interest in using their own platforms that they have
been developing, but he added that there are also circumstances when it should be understood from the start that certain data would need to be maintained locally by the researchers. Even when an analyst is interested in datasets from only one company or platform, Baigent noted, the inability to house data locally means that meta-analysts must upload their own analysis software behind the platform firewall.
Mandating Data Sharing
Tim Feeney asked whether ICMJE might have a role to play in promoting the cultural shift toward data sharing through establishing publication requirements, as was done for prospective trial registration. Humphreys said that, at a recent meeting of the Science and Technology Select Committee of the UK Parliament, an ICMJE journal editor suggested that idea. She said the editor believed that ICMJE could require that study results be posted in a registry prior to publication. Humphreys added that the same concept could apply to funders. She said a cross-funder survey of 174 clinical researchers found that half believed funders should mandate sharing of funded data, and half believed that mandating data would lead to sharing of data that are not meaningful, simply to meet the requirement. Concerns were also expressed that it is too early to mandate sharing data because there is no system yet to award credit for sharing.
Baigent summarized that there is broad agreement that data from randomized controlled clinical trials should be shared. The pooled clinical trial data supporting an IPD meta-analysis, however, is often not suitable for sharing, as the data sharing agreement (DSA) with each one of the multiple trial sponsors usually requires a confidentiality agreement for the data user to be allowed to maintain the data locally within their institution. IPD meta-analysts are often criticized for not sharing the data supporting the analysis, he said, but it is often forgotten that they do not own data from individual trials, and are generally legally prohibited from sharing with third parties due to data-sharing agreements. He urged caution in creating rules that would potentially place these high-value projects in legal jeopardy.
Roberts agreed and recalled the remarks made about the definition of “all trials.” There are other reasons why sharing data might not be possible or meaningful. Nurnberger agreed with the need for caution regarding mandates. She suggested that the potential sharing of derived datasets could be discussed when negotiating the DSA, including how to ensure traceability of the data.
Datasets from Tertiary Analyses
Alex Sherman raised the special issue of sharing information from tertiary analyses. When shared data or biospecimens (e.g., cerebrospinal fluid, DNA) are used for omics and generate large sequencing data files, should these omics data files be associated with the shared original data? Or are these sequence files the property of the researcher who did the sequencing?
Humphreys and Roberts were not aware of any agreed standard on this issue. In general, Humphreys said, journals require that the source of any data used is acknowledged in the publication (e.g., persistent identifier for the dataset used), and Vivli will store the derived datasets. Humphreys suggested that if an IRP was used for access to the primary datasets, and then the same IRP is used for access to the derived dataset, it would reduce the need to reach out to the multiple primary data generators every time there was interest in using the derived dataset. Nurnberger said each of the original datasets used to create the derived dataset will likely have licensing or sharing agreements that indicate the sharing expectations for the derived dataset. In addition, for the scholarly record, it is important to share the derived dataset in some way, and she advocated for the use of dynamic data citations to the original datasets. Roberts suggested that further discussion was needed between data originators and researchers on this topic.
Specialists in Data Sharing
Matthew Sydes recalled that the remarks about research team members focused on data sharing and about engaging the data management experts in library services. He asked whether organizations conducting clinical trials should be establishing positions for specialists in data sharing. Roberts said that in her company of about 7,500 employees, several staff members specialize in data sharing. The best solution for an organization depends on its size, structure, and other factors, she said. A question to be addressed, Humphreys said, is how those positions would be funded and sustained. Humphreys then shared support for the concept of a central core resource of dedicated experts, rather than a person on each trial team being assigned the task for a given project. As an example, she said that a pilot being conducted in Ireland uses a portion of the funding from each grant to cover the cost of 15 data stewards in different institutions across Ireland, with each project also contributing a small portion of their total budget.15 Nurnberger agreed with the concept
___________________
15 See https://www.hrb.ie/news/latest-news/news-story/article/hrb-to-offer-training-opportunity-to-create-irelands-first-fair-data-stewards (accessed March 15, 2020) for more information on the pilot program.
of trial teams having access to a core, centralized service of specialists in data management and sharing. Baigent said his department of about 600 staff members is establishing a team that will be responsible for data sharing. Large departments generate volumes of data, and there is a need for data-sharing expertise that is maintained by institutions, he noted. Humphreys added that data stewards have a role up-front in the development of data management plans or output management plans. These data stewards, she said, can provide perspectives on what the costs of data sharing might be for a given project—which can then be included in a funding application.
Pathways to Sharing: Precompetitive Consortia, Direct Collaboration, and Platforms
Ida Sim summarized the three main models of sharing data that have been discussed throughout the workshop, noting that each has different requirements and provides different support to researchers: (1) the precompetitive consortium model that brings groups of investigators together to pool data to discuss a research question (e.g., WWARN); (2) direct collaboration between data generators and data users for reanalysis of the data; and (3) facilitation of sharing by an independent third-party (i.e., platform). Sim observed that the platform model has the highest resource requirements for preparing data for sharing and processing requests for access. The task now is to reflect on where and how to provide enabling support to return the most value.
Humphreys added that the models must be FAIR and transparent. She suggested that some researchers are left out of the data sharing that takes place through consortia and direct contact (i.e., the data are not accessible to them by those pathways). Baigent said there is value to collaborating directly with those who have the greatest knowledge of the data and who can help interpret the overall results. Collaboration and collective interpretation by researchers with very different perspectives can also lead to better science, he said.
Nurnberger proposed a fourth model, in which clinical trial data are used by others outside of the clinical trial community, in particular, for machine learning or applications of artificial intelligence. Some important questions to consider going forward, Nurnberger pointed out, include Where will research go next? What needs to be done so that data are useful 10 years from now? How can the investments made in these studies be extended even further?
CLOSING REMARKS: FINDING VALUE AS WE MOVE FORWARD
Waldstreicher reflected on the progress made since the 2015 Institute of Medicine report Sharing Clinical Trial Data: Maximizing Benefits, Minimizing Risk (IOM, 2015). She observed that this workshop included discussions about sharing data across platforms for meta-analyses—while 5 years ago, the discussion was simply about how to facilitate data sharing, and the platforms of today did not exist.
Waldstreicher also pointed out some limitations of frequently used metrics, noting the insufficiency of measuring success by simply counting the number of publications resulting from data sharing. Other secondary uses of data that should be measured were discussed, including the use of data to inform methods development or to improve the statistical power of new studies. The importance of learning from failure was also raised; sharing data from failed studies is important, she said, so that researchers across companies and sectors can work together. Waldstreicher reiterated the point by Deborah Zarin that the possibility of auditing trials could help “raise the bar” and inspire researchers to collect data in a fashion that better facilitates sharing.
During the past 5 years that data sharing has been increasing, none of the anticipated unintended consequences have materialized, Waldstreicher noted. Across all of the platforms discussed and stakeholder perspectives shared, there were, for example, no reports of attempts to reidentify participants, no purported safety issues, and no principal investigators who had their findings “scooped” by others analyzing data they had shared.
Work still needs to be done, Waldstreicher said. There was much discussion about the need to enable analysis of data across trials and across platforms, and there was discussion of the merits of having a single platform. Each stakeholder generates data for their own purposes. Companies need data for product licensure, Waldstreicher added, while for researchers in academia data can be a currency for career advancement. Ultimately though, data are generated for the public good, “to make a difference for patients,” she said. The perspectives shared by Moses Taylor, Jr., and Sharon Terry, Waldstreicher noted, illustrate the importance of secondary use of data both for general public health and for individual participants—as well as the need to keep the participant perspective at the core of data sharing. She reiterated a phrase that Bernard Lo had coined saying that “data sharing is important because this is the science that is the foundation of medicine and medical care.”
Drazen agreed with Waldstreicher that there has been encouraging progress over the past few years, and the question now is how best to move forward. He suggested stratifying the different types of clinical
trials that are conducted based on the relative level of interest in the data generated. First, there are trials that are designed to inform and influence clinical practice. Often, these trials are sponsored by companies developing products, but they may also be sponsored by agencies such as the National Institutes of Health in the United States and MRC in the United Kingdom. Designed for regulatory submission, these trials are well documented and conform to principles of good data husbandry. He pointed out that numerous decisions can be made over the course of a study, so there should be a focus on improving habits so this information is documented in a way that makes it easy to understand how the study was conducted.
The second type of trial analyzes the effect of an intervention to better understand the biology of disease. Drazen said this type of trial is generally smaller (i.e., less statistical power), and there may be less interest in these datasets. However, the data may be of interest to researchers seeking to better understand disease biology, so “good enough” data husbandry is still important.
Finally, numerous trials are carried out to examine biological or physiological endpoints. Data from these types of studies are potentially shareable and therefore should involve some consideration of what would be minimally sufficient for data sharing.
Drazen then outlined a few general categories of data use. One category includes cases in which data are used either to check the outcome of a trial or to combine data across trials for advancing medical knowledge and practice. While these types of data applications can be of value to the medical and academic communities, there are concerns to be considered. Drazen observed that 5 years ago, trialists were concerned about potential adversarial uses of their data. Today, adversarial thinking on the part of trialists has evolved to be more flexible and focus on the potential advantages of data sharing. He added that third party platforms can serve as valuable intermediaries in this process. Another category of data use described by Drazen includes cases in which data are used to supplement a trial that lacks statistical power to address a particular question. Collaborative approaches to combine data from across multiple studies can help to advance the field, Drazen said. He noted that researchers seem willing to engage in this type of collaborative work, and he hopes to see more of this in the future. An additional category of data use, Drazen added, includes the application of shared data to examine the result of placebo treatment for people with a particular condition. This application might use shared data to help power a trial (e.g., to determine the frequency of a given complication when no treatment is administered).
These types of trials and categories of use can come together in many ways, Drazen said. In moving forward, he suggested that mandates for
sharing may not be needed. Funders can be influential in promoting sharing. Drazen suggested they might require data sharing for large-scale clinical trials, while encouraging data sharing for trials to understand the biology of a disease. Underlying all types of trials, Drazen reiterated, is the need to adopt standards that better facilitate the sharing and use of datasets. He stated that by keeping the focus on patients and improving care, everything else will fall into place.
This page intentionally left blank.






















