
7
Challenges and Disincentives for Sharing and Reuse of Data
The third panel to consider key challenges to clinical trial data sharing and reuse examined challenges and disincentives. Matthew Sydes, pro-
fessor of clinical trials and methodology in the Medical Research Council (MRC) Clinical Trials Unit at University College London (UCL), discussed four key challenges to sharing and reuse of data from his perspective as a researcher. Ramin Daron, vice president for data architecture and technology at Takeda Pharmaceuticals, drew from his experience as a sponsor of clinical trials and discussed the importance of effective partnerships to facilitate data sharing and discover new insights. Sharon Terry, president and chief executive officer of Genetic Alliance, shared her perspective as the head of a patient-focused research advocacy organization and the parent of two children with a genetic condition. The panel was moderated by Dina Paltoo.
RESEARCHER PERSPECTIVE
Matthew Sydes, Professor of Clinical Trials and Methodology, Medical Research Council Clinical Trials Unit, University College London
Sydes shared an observation from serving as chair of the Scientific Committee for the International Clinical Trials Methodology Conference (ICTMC) in Brighton, United Kingdom, in 2019. This was a large conference of primarily academic clinical trialists and methodologists, and he said that of 500 abstracts, only 4 (less than 1 percent) were focused on methodological issues of clinical trial data sharing.1 Sydes then discussed four challenges to sharing and reuse of data from his perspective as a researcher.
Using Data in a Valid Way and Utility of New Knowledge
As a clinical trialist, Sydes said he is working to “maximize the highest quality science to have the greatest societal benefit,” both in association with clinical trials and in related research. He highlighted some of the challenges of ensuring that shared trial data are used in a valid way and that the new knowledge generated from data sharing is useful.
Opportunity Costs
There are opportunity costs to be aware of when clinical trialists become engaged in supporting secondary research, he said. As discussed throughout the workshop, it takes effort to create datasets suitable for sharing, including both designing trials from the start with the intent to
___________________
1 ICTMC 2019 meeting abstracts are available at https://trialsjournal.biomedcentral.com/track/pdf/10.1186/s13063-019-3688-6 (accessed February 10, 2020).
share as well as preparing the relevant documentation after trial completion. These activities are costable (i.e., a monetary value can be assessed), he said. However, effort is often expended to support datasets after release. Data users might contact the trial investigators with questions about the data, and this engagement can lead to greater involvement in the secondary research than expected. Supporting these uncostable secondary activities presents an opportunity cost. Secondary research can lead to important findings, but Sydes noted that an issue is the degree to which the MRC (the core funder of the MRC Clinical Trials Unit at UCL) expects these activities to be supporting this work.
Protecting Trial Integrity in Secondary Uses
Sydes emphasized that “trials are analyzed by highly qualified teams” according to pre-specified statistical analysis plans that provide details about planned primary, secondary, and exploratory analyses and that account for the potential for statistical errors associated with multiple testing. Extensive subgroup analysis by trial teams is often criticized as essentially searching the data for findings (“trawling the data”). He said some International Committee of Medical Journal Editors journals exclude subgroup analyses from abstracts, even when they have been detailed in the statistical analysis plan. He added that there are also concerns about the reproducibility of results from some less well-planned studies, which he noted is currently a particular concern in the psychological literature.
Protecting the integrity of the original clinical trial and fostering integrity of secondary analyses are ongoing challenges. To help address this, Sydes offered several suggestions applicable to researchers requesting data for secondary analyses:
- Data requesters could be required to define analyses in advance. Sydes said that guidance for developing statistical analysis plans for clinical trials could inform secondary analysis plans as well (e.g., Gamble et al., 2017).
- Applicant qualifications could be logged.
- An “approved researcher status” could be created to register vetted researchers.
- Users of shared data could be asked to repeat analyses from the original trial to demonstrate that they understand the datasets.
- Specific training courses could be developed for new researchers requesting data for secondary uses. Sydes added that completion of training could be added to one’s curriculum vitae and noted on data request applications.
Rationale for Accessing Trial Data
Sydes said it would be interesting to better understand the motivations for accessing shared clinical trial data. His unit has been logging users’ intent and has found that many data requesters are planning to conduct individual participant data meta-analysis, while others are seeking linkage to biological samples. Sydes speculated that some of the applicants for data access are not actually interested in individual clinical trials (i.e., comparative data) but are instead seeking “prospectively collected, high-quality data.” For example, they might be seeking data estimating event rates in a particular population, and a particular trial is a means to obtain a sample set. He also speculated that if researchers could obtain access to real-world data, such as routinely collected data in the electronic health record (EHR), that might better suit their analysis needs and reduce the applications for access to clinical trial data. He acknowledged that there are challenges specific to accessing and sharing routinely collected data that are beyond the scope of the workshop, but noted that there are parallels with some of the challenges discussed thus far for sharing of clinical trial data.
Oversight Process for Access to Shared Data
Another challenge for sharing data is the oversight process for clinical trials. Sydes explained that in the clinical trial unit where he researches, oversight is a three-part system: a trial-specific Trial Steering Committee (TSC) that is assembled for each trial involving independent members; an Independent Data Monitoring Committee (or referred to by some as a Data and Safety Monitoring Board, Data Safety Monitoring Committee, or Data Monitoring and Ethics Committee); and a Trial Management Group (responsible for day-to-day trial activities).
Requests for data span the length of a trial and beyond (see Figure 7-1). Sydes said a few requests might be received during trial recruitment or early in the trial before the primary analysis (e.g., event rate data from the control arm). Most requests are received after the primary analysis is completed, and requests can continue for some time after the trial is completed. The TSC usually fulfills the data access role, Sydes said, but they and the other oversight committees generally disband after the trial, if not earlier. This leaves a void in reviewing data access requests and results in trial investigators filling requests. He said they are now working toward establishing a unit-wide Data Access Committee, with the intention of ultimately contributing trials to an external data repository and thereby reducing the trial team’s input into how the trial data are used for secondary research in the longer term. Sydes observed that there is limited discussion of when the process of reviewing data access requests should move from internal to external.
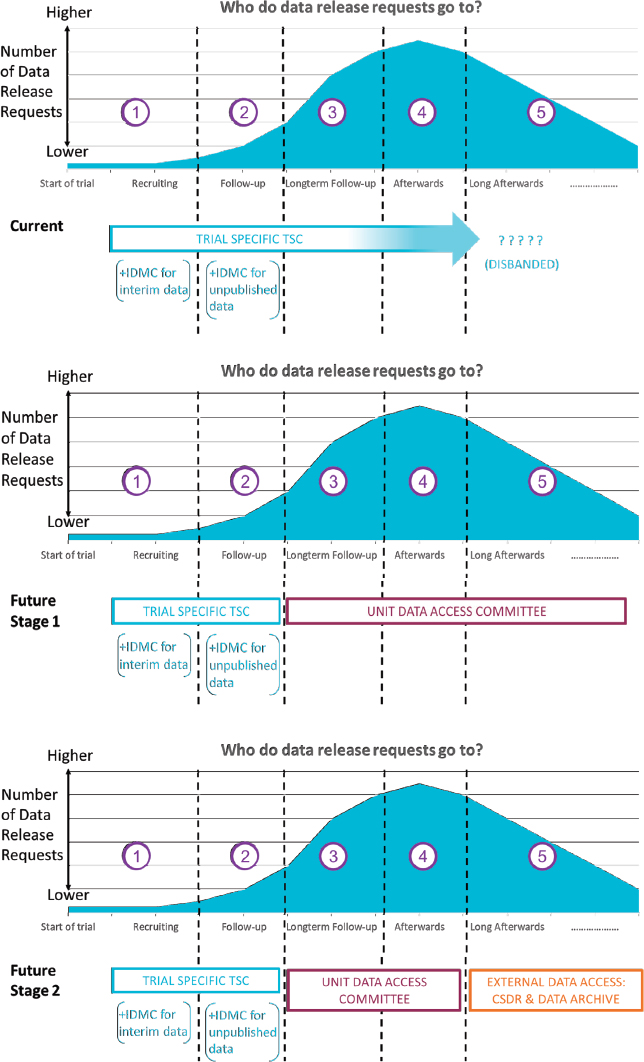
NOTE: CSDR = ClinicalStudyDataRequest.com; IDMC = Independent Data Monitoring Committee; TSC = Trial Steering Committee.
SOURCE: As presented by Matthew Sydes, November 18, 2019.
Recognition of Data Generators
The last challenge discussed by Sydes was addressing the need for recognition and reward of researchers involved in generating and sharing clinical trial data. Using an example of three people in the entertainment industry, all with the last name of Jones (a well-known American actress, a UK actor, and a makeup artist), he illustrated the value of a database that links individuals to their body of work. Using the Internet Movie Database (known colloquially as IMDb), one can find information about individuals (e.g., all roles a person in the industry has filled across projects, regardless of whether they had top billing as a star or worked behind the scenes) and about projects (e.g., every person credited for a film and their role).
Sydes proposed that a similar type of database is needed for those who contribute to clinical trials (Sydes and Ashby, 2017). Recognizing contributors with authorship goes against strict journal guidelines for authorship and is not practical given the thousands of people whose work contributes to a clinical trial. For example, there are pharmacists, radiologic technologists, data managers, and numerous others who help to facilitate clinical trials and produce the dataset, who are not generally recognized. To illustrate, he described a large-platform trial that has been ongoing for several years that has thus far produced 11 editorials and 30 papers.2 Collectively about 150 people have been authors on those publications; however, 3,500 additional staff are currently listed on delegation logs, and about 100 others are former staff who have or had roles on the team.
Perhaps an “IMDb for clinical trials” could use digital object identifiers, ORCID IDs,3 or other unique identifiers to link researchers and datasets they have contributed to, and enable better recognition of these contributions, Sydes suggested. Such recognition could help to alleviate some of the concerns about data sharing. He noted that there are logistical issues to consider, such as whether one digital object identifier would be issued per trial, or one for each version that is uploaded to a data-sharing platform, or whether there are differences between academia and industry with regard to recognition. He added that new models for recognition would need buy-in from promotion committees and publishers.
Other Challenges
Other challenges briefly mentioned by Sydes included anonymization (e.g., how and when to properly anonymize/de-link datasets), and how to return results of trials to participants, especially results of secondary analyses (e.g., who has responsibility, who funds).
___________________
2 See https://clinicaltrials.gov/ct2/show/NCT00268476 (accessed March 30, 2020).
3 See footnote 3 on p. 12.
SPONSOR PERSPECTIVE
Ramin Daron, Vice President, Data Architecture and Technology, Takeda Pharmaceuticals
Daron acknowledged the workshop discussions thus far on the challenges associated with data quality, incentives, costs, and infrastructure, and focused his remarks on several other issues, including the importance of effective partnerships. Expanding the knowledge base about the complex biology of disease “takes the work of many,” Daron said, and involves partnerships that enable access to both data and expertise. Drawing from his experience as a sponsor of clinical trials, Daron listed three elements of effective partnerships and alliances:
- Ability to execute. This includes elements such as standardization, normalization, and stabilization to increase efficiency.
- Ability to learn and grow. Daron observed that adaptability and willingness to try new approaches can seem at odds with standardization and other elements of efficient execution, and it is important to develop an understanding of what stakeholder needs are (e.g., open access, restricted access).
- Shared value. Alignment of goals and objectives better enables partners to resolve issues and overcome challenges to move forward.
Case Example: Overcoming Internal Data-Sharing Challenges
To illustrate the importance of partnerships, Daron describe an example of overcoming data-sharing challenges internally within Takeda. Historically, only certain teams have had access to the data for particular clinical trials, he said. Researchers often find themselves at odds, with some on the “defense”—striving to maintain the integrity of the trial and the validity of the interpretations—and others on the “offense”—eager to identify novel insights and new approaches.
The company decided to try to move the mentality about internal data sharing from “why do you want access?” to “why can’t you have access?” Daron said there was a need to “build trust and transparency between the different functions and the teams” and to define shared goals for the use of the data. In reviewing the organizational and functional aspects of the company and assessing the internal competencies and capabilities, it was found that simply sharing data more broadly by creating data libraries would be insufficient. There was also a need for libraries of analytics and utility.
Takeda has worked to develop these libraries and the internal capabilities for data interoperability and reuse (e.g., data standards, analytics). He said this has allowed the company to maintain the integrity of its clinical trials while also facilitating the identification of errors before database lock. Better internal sharing of trial data has also enabled new insights and enhanced the efficiency of translational research.
Case Example: Learning from Failures
Another example of the value of data sharing is the potential to gain new insights from failed clinical trials that did not meet predefined outcomes, Daron said. Examining data from failed trials for anomalies and aberrations can, for example, find subpopulations who responded exceptionally well to an investigational treatment even though the overall trial results were not statistically significant. These types of findings can help to elucidate the biology of the disease or the mechanisms of action of the product. As a result, the company has begun “deep phenotyping” of participants with anomalous results to better understand the reasons behind them. Daron said Takeda is also reaching out to other pharmaceutical companies and academic researchers to potentially share data and increase the statistical power for these small populations.
PATIENT PERSPECTIVE
Sharon Terry, President and Chief Executive Officer, Genetic Alliance
Terry shared her perspective as the head of Genetic Alliance, a patient-focused research advocacy organization and as the parent of two (now adult) children with a genetic condition. She is also the founder of a research advocacy organization and biospecimen bank for that condition. Terry shared that when she established the disease foundation 25 years ago, she insisted on data sharing by the researchers studying that condition. (In a process she described as herding cats by moving the food, data sharing was a condition of access to biobank samples.) Terry said her interest is in making data sharing easier. This will require an “industry shift,” and she suggested looking to other industries that have transformed themselves for lessons.
The Missing Perspective
Terry described how the perspective of the patient as both generator and user of data is still not present in research. Institutions and organizations are the decision makers, and questions are still asked and answered
from the perspective of researchers. “Every single one of us is a patient,” Terry said, and researchers need to bring that perspective to their work.
Ongoing discussions about value versus the risk/cost of clinical trial data sharing are primarily about the benefit/risk for researchers and study sponsors, she observed, and not about what is needed from a participant perspective. She suggested that institutions conducting trials often use issues such as participant privacy or the costs of data sharing as excuses for not sharing. Instead of transparency being the norm, terms such as “risk of audit” suggest a fear of transparency, she said.
Although secondary use is discussed primarily from the perspective of researchers, Terry noted several examples in which the public is using shared data for research. Shared data are commonly used by disease advocacy groups, as well as by interested individuals and affinity groups such as Pennsylvanians concerned about the health impacts of fracking or parents concerned about soccer-related head injuries. Terry cited the success of the Systolic Blood Pressure Intervention Trial Data Analysis Challenge and called for greater sharing of data with the public for their use, and better engagement of the public in the citizen science–type of activities that are common in other fields.
Case Example: Platform for Engaging Everyone Responsibly
Terry described Genetic Alliance’s Platform for Engaging Everyone Responsibly (PEER) as an example of a public data-sharing initiative.4 PEER, launched 10 years ago, is a cross-disease database in which individuals enter and control the sharing of their own health-related data with advocacy organization–sponsored registries. PEER currently has approximately 50,000 individual users representing about 100 diseases, with participation from 25 disease advocacy organizations. PEER recently partnered with LunaPBC, a public benefit corporation, for platform support.
Despite initial concerns about sustained participation, Terry said that PEER participants have remained interested. She credited this interest to the ongoing engagement that is at the core of the initiative. PEER participants answer questions asked by validated patient-reported outcome instruments and can upload EHR and genomic data, all of which remain in full control with regard to sharing. PEER participants can also receive shares of the genomic data platform, LunaDNA, for contributing their genomic and other information. They can decline the shares, hold the shares, or donate them. Terry explained that Luna received approval
___________________
4 See http://www.geneticalliance.org/programs/biotrust/peer (accessed February 10, 2020).
from the U.S. Securities and Exchange Commission for this, and is the only company granting shares in exchange for data as a currency. Terry acknowledged the concerns expressed by many in the field that commerce should not be part of data sharing. She countered that commerce is already involved in data sharing, and there is financial benefit for everyone except the individuals whose data are being shared.
Terry announced that PEER will soon be conducting a clinical trial in the platform in collaboration with a company. PEER participants will be messaged anonymously through the platform and can choose to be part of the trial. She explained that the sponsor will add data to each participant record in real time, which means there is no lag time in the return of data to trial participants, and also facilitates use of data as they are generated. PEER also has a “virtual data analysis sandbox,” which she explained allows researchers to conduct analyses on data in the platform, as well as securely upload their own analysis tools and proprietary datasets for use, and to share findings to the PEER participants’ records. Terry said this sandbox approach reduces some of the infrastructure burden for academic investigators, and also allows for reproduction of analyses and longitudinal follow-up. She added that PEER has a system for credentialing researchers and for data use agreements.
A key challenge is that there has been minimal interest in supporting a “people-run entity” that is not associated with a company or an academic institution, Terry said. Support has come from a variety of sources, including, she said, “cake sales and car washes.” Support from a company for the upcoming clinical trial is an important step, she said, and she added that she looked forward to the outcome of the study.
DISCUSSION
Paltoo asked panelists about data-sharing challenges that might be encountered in association with special or unique populations. As an example, Terry said that concerns about data sharing have been expressed by Native American populations and by patients with sickle cell disease. A feature of PEER allows advocacy communities to create a default data-sharing setting for participants to use. She said members can choose to use it or not, but that “most people will follow their gatekeeper or their key opinion leader” regarding sharing. She emphasized that one size does not fit all. Each individual has preferences, and the platform allows each community to set parameters. Many communities tend to want to share data only with researchers who are aligned with the community, and whom the community already knows and trusts, Terry said. However, after having a positive experience with sharing their data, many do agree to expand their circle.
Sydes raised the issue that consent for pediatric populations is given by parents or guardians, and technical re-consent is required when the child reaches legal age so the status could change. Sydes also reiterated the point from an earlier discussion that if data are not shared from the entire trial cohort, that can lead to bias in any subsequent analyses, including meta-analyses (i.e., the patients shared do not fully represent the trial data).
This page intentionally left blank.












