
The next panel to discuss key challenges to clinical trial data sharing and reuse focused on infrastructure sustainability. Georgina Humphreys of Wellcome Trust discussed challenges associated with the costs of sharing from her perspective as a funder of clinical trials. An industry perspective was provided by Pandurang Kulkarni, chief analytics officer and vice president of Biometrics and Advanced Analytics at Eli Lilly and Company, who discussed the experience of Lilly with sharing data first on its own website, then via ClinicalStudyDataRequest.com (CSDR), and now as a member of Vivli. Sean Coady, program officer in the Division of Cardiovascular Sciences at the National Heart, Lung, and Blood Institute (NHLBI), discussed data-sharing infrastructure sustainability challenges from the perspective of an individual from the National Institutes of Health (NIH) institute. The panel was moderated by Timothy Coetzee.
FUNDER PERSPECTIVE
Georgina Humphreys, Clinical Data Sharing Manager, Wellcome Trust
The Wellcome Trust was established as a global charitable foundation in 1936 through an endowment from Sir Henry Wellcome, Humphreys said. Wellcome is “dedicated to improving health for everyone.” Based in the United Kingdom, Wellcome currently spends about £1 billion ($1.3 billion)1 supporting research every year and, Humphreys said, intends that the outputs of that research “be accessed and used in ways that maximize benefit to health and society.” She described Wellcome as “a passionate champion and advocate of open access and data sharing … driven by long-standing policies.”
Researcher Challenges
Humphreys shared findings from the Springer Nature survey Practical Challenges for Researchers in Data Sharing. She noted that this was a cross-disciplinary survey of more than 7,700 researchers and was not specific clinical research, but the findings are similar to results from a survey of clinical trial researchers that Wellcome and other funders recently conducted.
Researchers surveyed identified the following concerns about data sharing2:
___________________
1 Estimated dollar figures at the time of the workshop.
2 A white paper describing the survey findings is available at https://partnerships.nature.com/wp-content/uploads/2019/08/Whitepaper-Practical-challenges-for-researchers-in-data-sharing.pdf (accessed February 10, 2020).
- “Organizing data in a presentable and useful way.”
- “Unsure about copyright and licensing.”
- “Not knowing which repository to use.”
- “Lack of time to deposit.”
- “Costs of sharing data.”
Wellcome does, in fact, cover the cost of sharing data, and there is a prompt to include an outputs management plan in the funding application, Humphreys said. However, applicants often do not include an outputs plan or a specific cost estimate for curation and sharing.
Cost/Funding-Associated Challenges
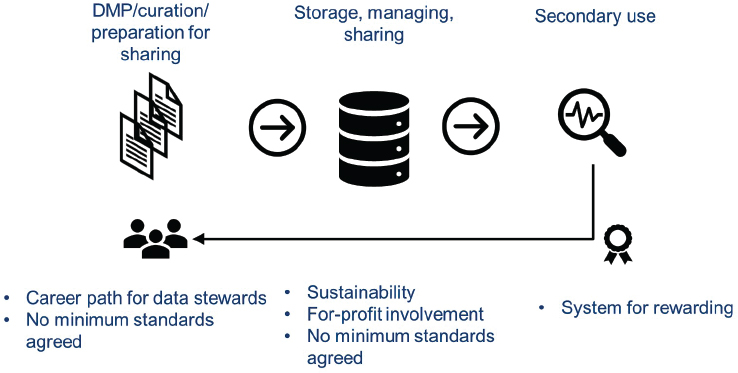
Humphreys discussed some of the cost/funding-associated challenges and concerns in three segments of the data-sharing process: (1) the data management plan, curation, and preparation for sharing; (2) storage and management of sharing; and (3) secondary use (see Figure 6-1).
Data Management Plan, Curation, and Preparation for Sharing
One area of concern is building the skill base needed for developing the data management plan, curating the data, and preparing the data for sharing. One option Humphreys described is to permanently embed data stewards in institutions that sponsor clinical trials to support all of the necessary data-sharing activities at the institution. This would help
NOTE: DMP = data management plan.
SOURCE: As presented by Georgina Humphreys, November 18, 2019.
to build institutional skill and expertise in data sharing. She mentioned examples of these efforts already being conducted on a pilot basis in the Netherlands and the Republic of Ireland. One question is how these new positions should be funded. She said Wellcome considers the financial burdens of this endeavor to be an institutional cost that should be supported in the core budget.
Another issue to be addressed is the lack of minimum agreed data standards. Humphreys pointed out that there are standards for pharmaceutical companies that will submit data for product licensure, but there is not yet any agreement on data standards among academic researchers.
Storing Data and Managing Data Sharing
There is a range of options, and costs for storing data and managing the sharing of data, Humphreys said, from a simple deposit to the more involved processes used by platforms that manage requests for data.
Sustainability is a key concern when considering the costs of data storage and management of sharing, Humphreys said. As has been discussed, different funding models are used to support repositories such as grants with fixed timeframes and pay-per-project or membership fee models. A question when addressing sustainability is the expected or needed life span of the repository. She said multiple funding models might need to be used.
Transparency of for-profit involvement in data storage and management is also a concern. Funders need to be aware of the structure of the system they are supporting. Humphreys said funders that receive government or public-based support might find it difficult to justify funding a for-profit model.
As in the first area, the lack of agreed-to standards is also a challenge for data storage and management. Humphreys raised a concern that there are often no minimum standards, even in some of the recommended findable, accessible, interoperable, and reusable (FAIR)-aligned data repositories.3
Secondary Use
A concern with secondary use that was raised throughout the workshop was the need to create a system to reward those who contributed data to repositories. Humphreys noted the value of using ORCID IDs4
___________________
3 See https://fairsharing.org/databases (accessed March 15, 2020) for examples of FAIR-aligned data repositories.
4 See footnote 3 on p. 12.
and digital object identifiers, which can help funders assess an applicant’s track record of data outputs as part of the funding decision. Wellcome asks applicants to submit an output management plan, which she said can include code, data, publications, and samples.
Example: Curation Cost Calculation
To illustrate the cost of data sharing, Humphreys described the work of Catrin Tudur Smith of the University of Liverpool to evaluate the resources needed to share individual participant data (IPD) from a clinical trial. Tudur Smith and a team of experts—including a statistician, a data manager, and a clinical trial manager—prepared IPD from two clinical trials for sharing, documenting the time spent and calculating the cost per team member for their time (Tudur Smith et al., 2017). Humphreys reported that one trial required 50 hours to prepare the datasets for sharing at an estimated cost of more than £3,000 ($3,900), and the other trial required about 40 hours at a cost of about £2,500 ($3,250).5 She added that this does not take into account the costs of addressing inquiries by data requesters in the future.
Humphreys concluded that designing trials with sharing in mind, including adhering to data standards prospectively, could help to reduce the costs of preparing clinical trial data for sharing.
INDUSTRY PERSPECTIVE
Pandurang Kulkarni, Chief Analytics Officer and Vice President of Biometrics and Advanced Analytics, Eli Lilly and Company
Kulkarni shared how he gained an appreciation for the complexity of clinical trials after moving from academia to industry. Large trials can have thousands of participants, years of follow-up, numerous variables, and large datasets. He said it can be challenging to understand the information associated with a large clinical trial unless one has had experience conducting clinical trials.
As part of its ongoing commitment to transparency, in 2014 Lilly launched a company website for researchers to submit requests for access to Lilly clinical trial data. Later that year, Lilly transitioned data-sharing activities to CSDR, and in 2019 Lilly joined as a member of Vivli. To date, Lilly has spent more than $3 million on infrastructure for analysis and data anonymization, Kulkarni said, and dedicates about three full-time equivalent staff resources per year. Moving the data-sharing process to
___________________
5 Estimated dollar figures at the time of the workshop.
Vivli has reduced some of the staffing needs and costs, he continued, and Lilly is working to reduce the costs of standardizing and anonymizing the data. He added that, in 2014, FDA implemented requirements for adherence to certain standards for regulatory submissions (e.g., the Clinical Data Interchange Standards Consortium [CDISC] Study Data Tabulation Model [SDTM] and Analysis Data Model [ADaM] standards),6 which means that Vivli member companies are all submitting data that have been standardized in a similar fashion. The parameters of what Lilly shares proactively are summarized in Box 6-1.
A participant observed that Lilly’s $3 million spent on data-sharing activities is likely a very small fraction of the company’s overall research budget. Kulkarni agreed but said that the $3 million could have been used to instead support the development of a therapeutic molecule. The company fully supports investing in data sharing, and he clarified that his
___________________
6 Further information on SDTM and ADaM are available in the FDA Data Standards Catalog. See https://www.fda.gov/industry/fda-resources-data-standards/study-data-standards-resources (accessed February 10, 2020).
point was to emphasize the need to use the data resources that are being made available for sharing.
Lilly Data Request Process
The process for accessing Lilly clinical trial data begins when a researcher searches for Lilly studies on the Vivli data-sharing platform and then submits a hypothesis-testing proposal for the studies of interest, Kulkarni said. Lilly ensures that the data are available to share, and Vivli might ask for clarifications on the proposal. The completed proposal is reviewed by the independent review panel (managed by Wellcome Trust), a data use agreement (DUA) is signed, and the data are then made accessible in the secure research environment for the researchers’ analyses. John Grecula of The Ohio State University asked about any authorship conditions in the DUA. Kulkarni said Lilly only requires that publications acknowledge the use of data from a Lilly-sponsored clinical trial.
Kulkarni said that Lilly had originally considered anonymizing every dataset created, but, given the significant expense, it decided to wait to see how many requests for data were actually received. The number of requests has been relatively low, and Lilly has decided to anonymize on a per-request basis, he said. He added that automation of the process has decreased the time needed.
More than 350 Lilly clinical trials are now listed on Vivli, Kulkarni said. Since 2014, 78 proposals have been submitted, 40 of which requested Lilly data only and 38 of which requested a combination of Lilly and other sponsors’ trial data. Ninety percent of the proposals requested data from oncology or neuroscience trials. Of the 78 proposals, he said that 50 were approved and given access to the requested data. The remainder are still being processed, were withdrawn, or were rejected by the independent review panel (IRP), Kulkarni explained. Of the 50 proposals approved, 12 have resulted in publications.
Commitment to Data Sharing
Lilly is committed to sharing clinical trial data, and Kulkarni said that data sharing “is part of the normal process of conducting clinical trials for Lilly.” In addition to listing trials on the Vivli platform, Lilly also participates in Project Data Sphere and the TransCelerate Placebo and Standard of Care Data Sharing initiative.7 The latter has allowed Lilly to use shared control arm data to inform trial design and, in some cases,
___________________
7 See https://transceleratebiopharmainc.com/initiatives/placebo-standard-of-care (accessed February 10, 2020).
“to replace some part of the placebo arm using data from TransCelerate,” Kulkarni said. Lilly also shares data through the disease research foundations working on lupus, Alzheimer’s disease, and Duchenne muscular dystrophy. Kulkarni supported the concept of a single data-sharing platform where researchers could access thousands of trials.
In closing, Kulkarni said that Lilly has invested significant time and resources making trial data available for sharing, but secondary use of the data is still very limited. He expressed concern that if shared data are not being accessed and used, interest by data generators in supporting the infrastructure for sharing could wane.
PLATFORM PERSPECTIVE
Sean Coady, Program Officer, Division of Cardiovascular Sciences, National Heart, Lung, and Blood Institute
Coady discussed data-sharing infrastructure sustainability challenges from the perspective of an individual NIH institute. A key aspect of sustainability is an institutional commitment to sharing, Coady said, and NHLBI leadership has been committed to wide sharing of data for more than 30 years. NHLBI’s first data-sharing policy was instituted in 1989 by then director Claude Lenfant, who committed to making deidentified data from contract-supported studies available. Although there was then a formal policy in place to enable sharing, few in the research community knew about it, Coady said.
In 1999, protocols to implement the data-sharing policy were developed, and the NHLBI Data Repository was established, Coady continued. The NIH-wide data-sharing policy was released in 2003, requiring grant applicants to include a data-sharing plan with their application.8 To provide a means for NIH grantees to share their data per the NIH requirement, in 2005 NHLBI expanded the scope of its data repository to include investigator-initiated (i.e., grant-supported) studies in addition to the contract-supported studies already included. In 2009, NHLBI created the Biologic Specimen and Data Repository Information Coordinating Center to facilitate integrated searching of both the data repository and the institute’s existing BioRepository.9 The current NHLBI director, Gary Gibbons, established the Trans-Omics for Precision Medicine program in 2014, facilitating the sharing of more than 150,000 whole genome
___________________
8 See https://grants.nih.gov/grants/guide/notice-files/not-od-03-032.html (accessed March 31, 2020).
9 See https://biolincc.nhlbi.nih.gov/home (accessed February 10, 2020).
SOURCE: As presented by Sean Coady, November 18, 2019.
sequences and other omics data.10 In 2019, the institute began development of BioData Catalyst, a cloud-based infrastructure for data and tools built on a data commons approach to sharing and data science.11
Challenges
Coady highlighted several concerns in the areas of platform usability, resource constraints, and outcome metrics, pointing out that his perspective on the challenges facing platforms is similar to those expressed by other workshop panelists.
Usability and Resource Constraints
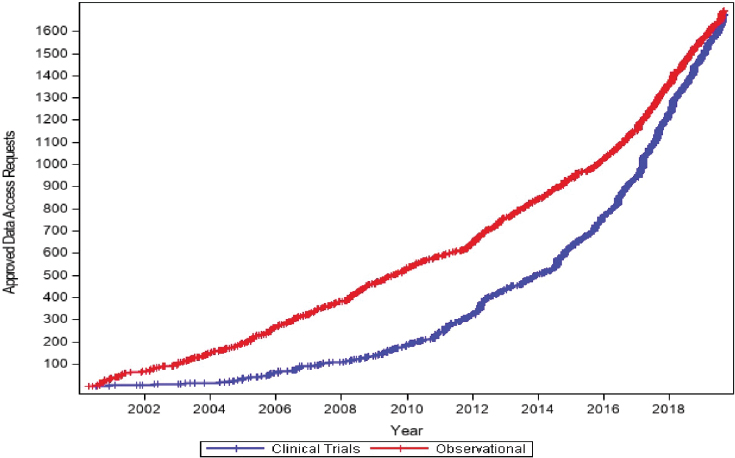
Coady showed a graph of the cumulative data access requests for both clinical trial and observational data in the NHLBI registry, which illustrates the increasing rate of demand, especially for clinical trial data (see Figure 6-2).
___________________
10 See https://www.nhlbiwgs.org (accessed February 10, 2020).
11 See https://www.nhlbidatastage.org (accessed February 10, 2020).
He elaborated on several of the challenges of accommodating this growing user base.
- Metadata standards. Coady described the NHLBI data repository as a “come as you are” repository of clinical trials and observational studies and said that the lack of standards for metadata impacts data discovery and usability, especially as the repository expands.
- Stewardship burden. NHLBI conducts a review of data that are submitted to the repository, Coady said. Reviewers confirm deidentification and usability factors (e.g., accurate coding, alignment of the metadata with the clinical data). He added the growing number of studies submitted to the repository further constrains resources.
- Implicit user support. When investigators access data in the NHLBI repository, it is understood that staff will attempt to answer any questions investigators might have. A concern, Coady said, is that the repository continues to grow, but resources do not grow simultaneously, making it increasingly more difficult to provide the support that is implicitly assumed.
Outcome Metrics
Some of the outcome metrics used to evaluate an institution’s investment in a data-sharing platform are relatively simple to assess, such as the number of website visits or the number of data access requests fulfilled. Using the number of publications as a metric can be burdensome, Coady said, as there is often the need to search for them. Other metrics that would be useful to have, but are more difficult to track, include the use of shared NHLBI data for workforce training and the inclusion of shared data in follow-up grant applications.
Coady shared that the NHLBI repository has generated more than 1,100 publications over the past 20 years, about half of which were based on clinical trial data and about half on observational study data.12 Sixty-eight trials from the repository have led to one or more publications, and investigators who published tended to publish more than once, he said. He added that it took about 5 years before half of the data users published their first paper, which is something for newer registries to keep in mind when looking at metrics.
___________________
12 See https://biolincc.nhlbi.nih.gov/publications (accessed March 15, 2020).
DISCUSSION
Priorities
Coetzee prompted participants to identify additional priorities to address sustainability challenges (aside from funding). Coady reiterated that metadata standards would help to accelerate discovery and help to maintain longer-term usability. Kulkarni agreed and said that CDISC metadata standards are used by the pharmaceutical industry, and he suggested that academic researchers also consider using CDISC standards as a base, rather than creating new standards. He also reiterated his support for the concept of a single data-sharing platform to overcome the problem of not being able to combine datasets from different platforms. Humphreys agreed that the lack of standards is a priority item and suggested that there is a need for an internationally recognized body to convene stakeholders and drive the standard-setting process. Amy Nurnberger referred others to the Research Data Alliance, which has convened working groups to consider standards, including metadata standards, for specific fields, including health (although not specific to clinical trials).13
Concerns About Using Multiple Platforms
Matthew Sydes observed that Lilly is contributing data to three of the five data-sharing platforms that were discussed, and Wellcome Trust oversees the IRP for two of the five. He asked if different Lilly trials are deposited in different repositories, and which platform a researcher interested in Lilly datasets should use to begin with. From a sustainability perspective, he questioned whether all of these platforms are needed. Humphreys clarified that Lilly transitioned from CSDR to Vivli and is not contributing to both simultaneously. She confirmed that the same Wellcome IRP provides services to CSDR and Vivli, using the same criteria for both. She explained that she serves as the point of contact between the two platforms and ensures that, if researchers submit the same or similar proposal to both, the IRP does not consider it twice. She noted that many of the clinical trials that Wellcome funds are conducted at centers that use their own data access committees, and she said it could be argued that they are not independent. She suggested that a single IRP for multiple platforms could provide consistency across platforms. Kulkarni acknowledged that Lilly is willing to support multiple data transparency activities (including, as mentioned, TransCelerate and Project Data
___________________
13 See https://www.rd-alliance.org (accessed February 10, 2020).
Sphere), but that it is resource intensive, and a single platform would be more sustainable and usable.
Preservation of Data Beyond Platform Life Span
David Sampson from the American Society of Clinical Oncology raised a concern about data preservation if a platform is not sustainable. He noted that there are archives that can preserve the content of journals that cease publication. Kulkarni said that, although he could not comment on the platforms, Lilly and other pharmaceutical companies preserve data per regulatory requirements, and after preservation is no longer mandated, companies archive data so that they can be retrieved if needed (although he noted there might be time and cost involved to retrieve). Data are assets to companies, he said, and they are well preserved. Coady said the NHLBI platform uses accession numbers with versioning so that when older editions of studies are archived, they can be referenced through the accession number. Coetzee observed that, while industry preserves data as an asset, this factor is not a motivation for all data generators. He suggested there might be a need for standardization of preservation, or important datasets could be “lost to history.”
Data-Sharing Cost Estimates
Given the different estimates of the costs of data sharing that have been discussed, Jeffrey M. Drazen asked how NIH might calculate allowable data-sharing costs. Humphreys agreed that the numbers discussed are just estimates and are very heterogeneous. She speculated that many of Wellcome’s grant applicants do not include an estimated cost for a data outputs plan in their applications because they do not know what that cost would be. Wellcome deliberately does not specify allowable amounts to enable applicants to be flexible in how they propose what is needed for their specific project, she said. Coady said that investigators initiating large clinical trials are encouraged to consider data-sharing costs as part of an overall data management process. Alex Sherman added that, years ago working with the Critical Path Institute, they calculated the costs of the activities needed to merge data from multiple trials in the same disease space to be $25,000 to $30,000.
Costs of Providing IPD to Participants
A workshop participant said that clinical trial participants generally have the right to their own patient-specific data from trials and asked how frequently such requests are made and what the costs of fulfilling the
requests are. They suggested that if thousands of participants in a large trial requested their individual data, the costs could be high. Kulkarni responded that the trial sponsor is never in direct contact with participants, and that it would be a trial investigator who receives and fulfills the request from the patient. Sherman said that clinical research organizations routinely deliver trial participant data to each site, and the cost of providing an individual’s clinical trial data would be essentially the same as that for other participants at the same site. The challenge in delivering a specific participant’s file is that the data provided are only identified by subject ID, he said, and only the site knows each identity.
Data Obsolescence
Drazen asked about the actual use of archived historical datasets, especially when clinical practice has changed over time (e.g., the treatment of heart attacks over the past several decades), and whether there is a time when a dataset is obsolete. Coady cited several older NHLBI clinical trials from which data are still being requested and used to consider various associations (e.g., the Studies of Left Ventricular Dysfunction from the 1990s). He said there are many uses for old data, especially with new statistical methods (e.g., risk factor identification, risk prediction).
This page intentionally left blank.














