
6
Stewardship and Governance in
the Learning Health System
INTRODUCTION
The growth and development of the digital infrastructure for health will depend on the effectiveness of its stewardship and governance mechanisms. This chapter focuses on a broad range of issues central to establishing a governance entity, such as the format and scope of authority of such an entity, and presents a case study from a similar effort in the United Kingdom. Remaining pieces focus on the types of governance issues raised when considering a learning health system, including leveraging ongoing efforts to accelerate development and approaches to mitigating potentially conflicting interests among stakeholders.
Drawing from her experiences—including leading the establishment of the Rhode Island Health Information Exchange—Laura Adams of the Rhode Island Quality Institute identifies and addresses fundamental questions posed in contemplating the governance of the digital health infrastructure. Focusing on the source and scope of authority, the mission, purpose, and primary goals, and the theoretical foundations for a governance structure, she lays out many options for consideration. Ms. Adams suggests that all potential models of governance structure and stakeholder participation should be considered, and that the scope of the governing bodies’ authority should be succinctly communicated in a statement of purpose. She notes that this statement should draw on guiding principles such as transparency and commitment to the common good, and that consideration of guiding theories—such as complexity theory—could aid in providing an ethical and legal framework. Pointing to some of the
unique governance challenges posed by a learning health system, including changing privacy considerations and accommodating new sources of data, Ms. Adams suggests drawing on past successes and experiences while incorporating the widest array of viewpoints possible.
Theresa Mullin from the Food and Drug Administration describes ongoing efforts to implement a systematic strategy for data standards development and adoption. This process will address heterogeneity in new drug applications, improve regulatory efficiency, and contribute toward the agency’s public health mandate by facilitating exploration of safety and efficacy issues. Dr. Mullin suggests that, through the standardization of clinical data in electronic health records, this effort presents an opportunity to facilitate information exchange and analysis for learning, reducing costs, and reducing burdens on providers for adverse event reporting. Dr. Mullin also highlights some of the overarching governance principles driving this effort: an open, transparent, and inclusive process; and a requirement that the resulting requirements be practical, user-oriented, sensitive to costs, and sustainable.
Meeting patient expectations for privacy and security is central in developing a learning health system, explains Shawn Murphy from Partners HealthCare. He details how current limitations to privacy through de-identification could be overcome by a comprehensive security and privacy approach that does a better job of addressing patients’ chief concerns around health information protection—avoiding embarrassment and economic risk. Citing an example of research program–based restrictions on physician access to data—whose risk to patient privacy is negligible given their otherwise broad access to patient information—Dr. Murphy suggests that the certified trustworthiness of the recipient should be a component of access control. He goes on to note that this, coupled with appropriate de-identification and secure data storage, provides a balanced approach to security that better matches the expectations of the patient while facilitating access for approved data users.
Guidance for approaches to governing the digital health infrastructure can be drawn from examples of similar efforts. Harry Cayton of the National Information Governance Board (NIGB) for Health and Social Care in the United Kingdom describes the approach they have taken in dealing with information governance issues facing the National Health Service. Mr. Cayton details the role played by the NIGB as an independent statutory committee to advise the government on the use of patient-identifiable data for clinical audit and research. He describes their philosophy that information governance (or stewardship) is the responsibility of every organization involved and provides a list of principles developed by the committee to guide their work. Stating that the purpose of the NIGB is to deal with the “wicked questions” that arise around use of health information,
Mr. Cayton affirms that there is no right or wrong answer, only the best answer at the time. In conclusion he suggests that all governance systems need the same things: mechanisms for agreeing on and applying consistent principles, checks for the practicality of guidance given, consistent procedures, and credibility with stakeholders.
GOVERNANCE COORDINATION, NEEDS, AND OPTIONS
Laura Adams, M.S., R.N.
Rhode Island Quality Institute
Establishing a governance structure for the learning health system calls for an open exploration that allows for emergence of structures perhaps not yet conceived, but advanced by consideration of several key factors to make it an effective and responsive function. Some important elements to be considered in establishing such a structure include the source and scope of authority; mission, purpose, and primary goals; operating procedures; the framework for evaluation and continual improvement; and the funding mechanism. For the purposes of this paper, only the following elements will be explored: source and scope of authority; mission, purpose, and primary goals; and special considerations such as a proposed theoretical foundation.
In terms of the broad organization of governance, several forms can be considered. It could be a centralized organization, a distributed system with no identified “center,” a hybrid model, or one with few similarities to existing structures. Similarly, it could be established as a governmental agency, a private entity, a public–private partnership, or even a loose association. The scope of the governance structure could be national, international, or a combination of geopolitical considerations. It could be a formal organization, a virtual group, or reflect elements of both. Finally, the members of the governing body could be limited to the “usual suspects,” or include patients and consumers as well.
The source (or sources) of authority for the governance structure, as well as the scope of this authority, will also be primary considerations. There are several models that can be drawn on as the source of authority. First, it could receive a direct official mandate by governmental statute or regulation. Alternatively, the governing structure could be created by a trusted neutral entity where authority is conferred by those being governed or by a private entity that receives official designation or mandate and is regulated by a government agency.
Ethical and Legal Foundations
Once these broad considerations are determined, the scope of the governing body’s authority should be succinctly enunciated in a statement of purpose that encompasses the various purposes and goals. An example of such as statement is:
To foster data utility for the common good, cultivating a bond of trust with the public and between data-sharing entities to accelerate collaborative progress toward the creation of a learning healthcare system.
The mission statement draws on the guiding principles for governance that consist of durable statements that represent a set of values and guide decision making. Such principles will include, for example, transparency of the governance functions and activities, a reflection of its commitment to the common good, and overarching respect for, and an intent to, protect privacy. As we have learned from similar efforts, these guiding principles can conflict. It is, indeed, one of the primary purposes of the organization to balance these competing concerns during the governing process.
In such cases, it can be useful to apply a particular guiding theory in developing governance processes and to help resolve such conflicts. One such theory is complexity theory, which posits that simple rules guide complex behavior and accommodate continuous evolution in complex adaptive systems. Surprisingly, these simple rules, once identified and applied consistently, can produce desired outcomes in very complex systems. Another aspect of complexity theory includes the acceptance of paradox and tension as natural and even desirable if managed properly. An example of such is the coexistence of a principle of widespread access to data alongside a commitment to privacy protection. The theories of complex adaptive systems offers guidance in understanding the need to become comfortable with tension and paradox and advance new approaches that acknowledge the existence and value of tension and paradox. Another example of managing paradox and tension is “giving direction without giving directives,” and maintaining authority without having control (Zimmerman et al., 1998).
An emerging governance structure for the learning health system must also specify structures and relationships with other relevant entities. The legal and ethical framework guiding the activities of the governing body needs to be determined. In addition, the question arises as to whether there is to be a single governing body or several and, if the latter, how the different bodies will relate to each other and coordinate their activities. Other important questions include: What is the relationship of the governance structure with other existing governing bodies at the local, national, and international level? What are the inclusion criteria and selection processes for determining who will have a formal role in governance?
Ensuring Privacy and Promoting Trust
Once the legal and ethical framework is determined, the real work of governance begins. Some of the pressing governance challenges for the learning healthcare system include the changing locus of research and the changing nature of privacy considerations. Critical data sources are moving beyond the traditional clinical settings of large healthcare networks and academic medical centers. New sources of data—ranging from those collected in ambulatory clinical environments to the ever-growing sources of patient-supplied data—are becoming increasingly central to research. The changing landscape of trust as it relates to such issues as privacy also presents challenges. Consequently, governance activities will need to regard the nature, foundations, and manifestations of trust. Current privacy concerns could diminish over time (as a result of new methods of protection), but they could also grow and severely impact achievement of the goals of a learning health system.
Governance must understand that context plays an important role as it relates to a number of issues, including privacy. One iconic image from the aftermath of Hurricane Katrina is the photo of the driveway of a physician in Mississippi strewn with the medical records of his patients drying in the sun after his office had flooded. Records from many other physicians and hospitals were destroyed. In light of this reality, the local health information exchange (HIE) had relatively few problems with consent issues as they related to electronic health records, as people saw the value in moving away from paper records. The situation was different in Rhode Island, where from the beginning of the process of development of a statewide HIE, there was no contextual crisis, but a deep commitment to consumer engagement and addressing privacy concerns. The process included nearly 18 months of intense work and broad engagement of the community in order to produce the state’s privacy framework, which included the passage of legislation mandating the voluntary nature of participation, consumers’ rights to have the data in the HIE, State governmental oversight of the HIE, restrictions on the uses of the data, and stiff penalties for those convicted of misuse. The primary motivation in this endeavor was to respect and regard the differing viewpoints while using consumer control as the paramount guiding principle. The result was a community-supported consent model, as well as a significant degree of community trust and ongoing inclusion in the development of other aspects of the HIE.
Conclusion
These examples illustrate some of the elements that need to be incorporated into the governance structure of the learning health system. This is a
complex system, and governance will confront many challenges in establishing sustainable procedures to oversee the implementation of a large-scale health information system. By drawing on the successes and experience of existing programs, a new governance structure can be established that has the requisite authority and framework to build partnerships among various data sources, ensure data integrity, address privacy issues, and establish policies for proper data use, auditing, and enforcement. By incorporating the widest possible array of viewpoints from competing stakeholders, the system can engender trust, foster adherence to common data models and standards, and garner financial support—all necessary for a sustainable governance function.
CONSISTENCY AND RELIABILITY IN REPORTING FOR REGULATORS
Theresa Mullin, Ph.D.
Food and Drug Administration
The information systems being developed to support health care have the potential to address critical questions related to public health, health policy, and healthcare delivery. These questions include
- How quickly and how well can we detect and interpret new safety signals?
- How do we maximize the value of what is learned in clinical trials?
- How do we ensure that key healthcare system participants have appropriate access to the information needed to make the best-informed decisions?
Policy makers and researchers can use data collected from the emerging digital health infrastructure to address these questions, as well as many more. Development and widespread adoption of information standards is essential for the use of health data for knowledge generation and expedited application of new knowledge in clinical care.
Building a learning health system requires governance and stewardship at many levels, particularly in the area of standards development for the format and content of patient data. Stewardship is necessary to ensure that the locus of these efforts is driven by the needs of healthcare decision makers rather than technical advances. Governance is necessary to ensure that relevant stakeholders, including potential end users of the data, are included in the standards development process. Together, stewardship and governance processes must ensure that electronic health data are reliable, available, and research-ready.
Within a narrower scope, the Food and Drug Administration (FDA) is engaging relevant stakeholders in the development of data standards for clinical trials data. These standards will facilitate a more transparent and reliable review process for new products as well as advance the agency’s public health mission by providing a platform for consistent, science-based regulatory decisions. Although premarket clinical research yields only a fraction of the volume of clinical data generated by care delivery, stakeholders such as the FDA, sponsors, and standard-setting bodies have an active interest in developing data standards for clinical and preclinical data. Advances from these efforts may be useful leverage to jump-start the development of the digital infrastructure for the broader learning health system.
Background
FDA is responsible for the review of new drug applications (NDAs). Since 1938, every new drug has been the subject of an approved NDA before it could be sold in the United States. Since 1962, an NDA has included all animal and human data and analyses of those data intended to support claims of efficacy and safety. The data gathered during the animal studies and human clinical trials of an investigational NDA become part of the NDA. Under law, no pertinent data may be omitted.
The NDA submission should provide enough information to permit FDA reviewers to make the following judgments:
- The drug has been shown to be effective for its proposed use or uses.
- Safety has been assessed by all reasonably applicable methods.
- The drug is safe for its intended use; that is, the benefits of the drug outweigh the risks for the doses being proposed for approval.
- The drug’s proposed labeling (package insert) provides adequate directions for use and whether other postmarket risk management is required.
- The methods used in manufacturing the drug and the controls used to maintain the drug’s quality are adequate to preserve the drug’s identity, strength, quality, and purity.
FDA currently receives and reviews approximately 140 original NDAs (Figure 6-1) and over 3,700 NDA supplements per year. There are no regulatory or statutory standards for the format of data submissions in NDAs. While an increasing proportion of submissions are being submitted in electronic format, some applications still contain paper documents. For wholly electronic submissions, the submissions and associated raw clini-
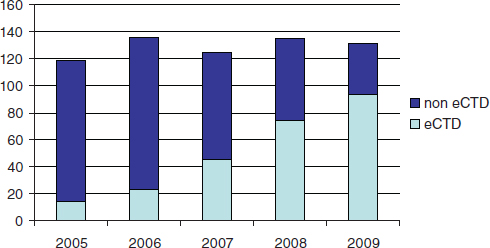
FIGURE 6-1 Number of FDA new drug applications from 2005 to 2009, indicating the proportion formatted according to the electronic Common Technical Document format.
cal data are large (the average size of an electronically submitted NDA is 10 gigabytes). Without a standardized structure, the application can be difficult to navigate. Fortunately, an increasing proportion of NDAs are being submitted electronically, and an increasing portion of the electronic submissions are being formatted according to the electronic Common Techical Document format.
The bigger struggle with electronic submissions is the format and content of the clinical and preclinical data included to support claims of efficacy and safety. Few submissions attempt to implement standards for the content of the subject-level data. The lack of standardized clinical data creates an impediment to rapid acquisition, analysis, and understanding of new drug performance. Furthermore, nonstandardized clinical data are difficult to integrate for analysis across datasets since each dataset requires formatting prior to integration. As a result, even a relatively straightforward review question can require extremely demanding data manipulations. This also increases the variability of reviews, and limits reviewers’ ability to quickly address late-emerging issues.
Efforts to Address Data Challenges
To improve review efficiency and facilitate in-depth exploration of safety and efficacy questions, FDA is implementing a more systematic strategy for data standards development and adoption. FDA will need to address specific disease indications to identify the data elements and clinical
terminology required for FDA reviewers to assess clinical benefits versus risks. A critical part of this effort involves FDA engagement with standards development organizations, other federal department and agencies, academic researchers, regulated industry, vendors, and others who will bring their data needs to the process.
Although this process is motivated by the FDA’s own public health mission, addressing the agency’s need for more standardized clinical data may provide leverage to support the development of other learning systems. Clinical data form a critical part of the content for records in the care setting, and the clinical data standards developed to meet FDA regulatory requirements can serve and support a transition to more standardized clinical data in electronic health records (EHRs). This would not only facilitate data analysis and enable learning from data generated in the healthcare system, but might also reduce the cost of clinical research and reduce the burden on healthcare providers for adverse event reporting. In the case of clinical research, an electronic case report form (the data collection tool for a clinical trial) might be automatically populated from an EHR that uses a specific data standard. With adverse event reporting, a standardized individual case safety report (the reporting form for adverse events) could also be automatically populated from the EHR. Pilots of these types of applications are already under way.
To fully benefit from the development of data standards for clinical data, FDA has identified the need to pursue data standards development collaboratively. FDA is including internal and external stakeholders in the development of standards for content, format, and exchange of electronic clinical data. Simultaneously, FDA will be developing regulatory policy changes that will outline new requirements for regulated industry, undertaking changes within FDA to gain significant business process improvements, and making technical infrastructure investments to ensure the capacity to do the advanced computing and data manipulations that standardized data would allow. Effective, continuing communication and stakeholder engagement will be critical in all of these endeavors, since all affected parties must be aware, involved, provide feedback, and be invested. As a practical consideration, sustained resources will also be necessary to ensure success.
Conclusions
Several general governance principles have emerged from FDA’s experience to date, including
- The process must be open and inclusive of all stakeholders, respectful, transparent, and predictable.
- The standards, use policies, and formal requirements that result from the process must be practical, end-user oriented, cost-sensitive, and sustainable.
In summary, FDA’s recent and ongoing work to develop health data standards is primarily driven by the agency’s own public health mission and regulatory business needs. This work may also accelerate the readiness of clinical data standards for use in EHRs. Systems interoperability coupled with common data standards would facilitate data pooling to address questions across both premarket clinical research and postmarket clinical care. It would also enable more powerful and rapid application of data mining, semantic linking, meta-analysis, and other advanced methods intended to address continuing questions about the quality and effectiveness of therapeutic products. In a learning health system, a common language is the first requirement to facilitate widespread communication and knowledge sharing.
COMPLYING WITH PATIENT ExPECTATIONS FOR DATA DE-IDENTIFICATION
Shawn N. Murphy, M.D., Ph.D.
Partners HealthCare, Inc.
The use of patient data from electronic health record (EHR) systems can provide tremendous benefits to clinical research. However, the adequacies of measures to protect patient privacy while utilizing these records are constantly challenged. These challenges are rarely welcomed because they represent a seemingly endless set of technical constraints to be imposed upon our systems. But, could the answer to this situation not be a new technical solution but simply a more complete understanding of what the patients actually expect us to do to protect their privacy?
Patient Expectations
Overall, surveys have found that patients’ opinions of how their data should be protected are on a continuum from the use of their health data where it may be distributed freely to a completely closed approach where it may hardly be used at all (Willison et al., 2007). Patients give several reasons for keeping their EHR data private. Some express a wish to control the purposes for which the data are used, although most patient surveys reflect a desire only to be informed of its uses. Others hope to avoid embarrassment with the revelation of medical information to people they know or will know in the future. Finally, there is a potential economic im-
pact on the patient if insurance companies or employers obtain health data (Damschroder et al., 2007).
Meeting the patients’ expectations for precautions to be taken to avoid embarrassment and economic loss is not the job of software tools, but the entire system. If one tries to describe the system for protecting medical records, we find it described as a method to restrict and determine the people allowed to view the data. A de-identification process that is appropriate for those allowed to view the data can be part of this system, but ultimately it is about restricting those who view the data. Patients will expect the entire system to work, and any valid approach needs to take this into consideration.
Limitations of Current De-Identification Protocols
Proper consideration of the needs of end users can determine the level of de-identification necessary. It is unrealistic to expect data to be properly de-identified for all audiences. Some of the algorithms developed will provide de-identification to line-item patient data to a degree known as k-level anonymity (Fischetti and Salazar, 1999; Sweeney, 2002). The number k represents the number of people’s records that must be identical. If there are patient records that exceed this level of uniqueness, data values are removed from these patients’ records until the records are no longer unique. Although superficially such methods seem like an adequate solution to the de-identification problem, such methods have proven to be subject to “reverse engineering,” undoing the obfuscation (Dreiseitl et al., 2001). Furthermore (and somewhat obviously), they take out important attributes from the data (Ohno-Machado et al., 2001). De-identification methods are also quite actively used in “scrubbing” textual medical reports (Friedlin and McDonald, 2008; Uzuner et al., 2007). The patient names, dates, locations, and other potentially identifying information are removed by computer programs that search the text. These programs perform to various levels of accuracy, and involve trade-offs similar to those described above for structured data. The extent to which it can be assured that the data are de-identified and “unmatchable” to the original record is often dependent on removal of sentence structure, which is an important attribute of the data (Berman, 2003).
The failure of technology to offer a foolproof de-identification solution is not all that surprising. People are extremely resourceful and well accustomed to solving challenging problems. The bottom line is that the trust in who gets the data clearly needs to match the level of de-identification. If the receiver of the data is deemed to be unknown, then there is no amount of de-identification that can reliably protect the patient in all perpetuity unless the content is so simple and poor that it is rarely useful for clinical research.
A New Model for Protecting Health Data
It is possible to envision a better solution when one considers the two reasons patients are interested in preserving their privacy: embarrassment and economic risk. Patients expect the level of de-identification to comply with the risk, and the intentions of those who view the data to factor prominently into the risk. What we actually tend to see is that people who are extremely trustworthy with data and pose little risk of harm to the patient are restricted from data in illogical ways. For example, handling genomic data tends to be extremely restrictive. At Marshfield Clinic there is an enormous investment in a tissue bank of 20,000 consenting patients who get genotyped using the collected tissue. These genotypes are put together with de-identified data from their EHRs (McCarty and Wilke, 2010). The people who view the de-identified genomic data are not allowed to be the same people that have access to identified phenotypic data. This is due to the obvious potential that a person who can see both datasets could find a way to tie them both together. Since all the physicians at Marshfield Clinic must have access to the EHR, none of them are eligible to view these data. The result is that, although many are principal investigators of the studies, they cannot look at the data from their own study. In these cases, it seems highly unlikely that clinicians who are trusted with the lives of their patients, and see hundreds of patients’ private information, really represent a risk to a patient’s privacy.
The judgment used to manage a case such as the above should factor in the proper match of de-identification to the trustworthiness of its recipients. The trustworthiness of the recipients should not be taken for granted, but determined by a defined process. Criminal history checks, letters of reference, and credentialing systems have been used in many scenarios in society to perform an objective trust assessment. Ultimately, the ability to match trust to a data recipient should be a critical factor in all reviews of data distribution proposals. The greater the level of de-identification and the less the risk of economic harm and embarrassment, the less trustworthy the recipient needs to be.
Although an individual may be deemed trustworthy, technical competencies will vary. This factors into a third determinant of data privacy, the physical and policy platform upon which the data are to reside. The data must be protected so that they do not go beyond the recipients for whom they were intended. This leads to the concern of physically protecting the data, which will be implemented with a combination of policy and technology. At the University of California at San Francisco, there is a protected area inside a network firewall where data are kept and analyses are performed. People are encouraged to keep the data within the protected area by having legal coverage provided by the institution should the data be
stolen from within the protected area. However, this approach requires a tremendous number of resources and limits the freedom of the individual to use “unsupported” software on privately funded platforms.
Other approaches, such as those used at Partners, put more responsibility upon the people who receive the data. A certain level of familiarity with security software and hardware platforms is assured by the necessity of taking a certified course. The data are then distributed behind a firewall in protected directories in an encrypted state, and the individuals manage their environments from this point. Protected network drives and computational resources are available for those who wish to use them—but it is not required—and private computational environments flourish behind the institutional firewall.
Conclusion
Data de-identification should not be considered a technical challenge, but rather a balance of three technical and human considerations: (1) techniques for de-identification, (2) the trustworthiness of the recipient, and (3) the physical security on which the data will reside. The first is indeed the way data can be changed to de-identify it, but the other two that should be balanced with this task are the trustworthiness of the data recipient and the physical security on which the data will reside. As an example, for a set of moderately sensitive de-identified text reports, it may only be possible to provide a 97% capability to truly scrub the identified data from the reports. In this case, the data will be authorized to be seen and shipped to the members of the community that are entrusted with this kind of identified data and have a reasonably secure location in which to place the data. Unlike the current scenario, the emphasis is not to keep the data within the entity, but to expose the data to trustworthy recipients in a physically secure environment. Intended use of the data is not factored in heavily to this algorithm, as it does not affect the risk to the patient.
The difference between this scenario and the current state is to consider every act of de-identification an achievement of balance between the level of data de-identification, the level of trustworthiness of the data recipients, and the level of security of the data location where it will reside. Although this will seem to make the process more complex, it is deemphasizing the institutional boundaries and uses of the data that can be equally complex and ambiguous. The principal merit of this recommendation is that it matches the expectations of the patient. They are entrusting us to “know their minds” and match the human expectations head on, rather than implement contrived polices that do not make them any more comfortable with the process. Answering patients’ expectations with flawed technical de-identification approaches and legalistic restrictions will result in poor
trust and a continuously changing set of technical and policy constraints from the community.
INFORMATION GOVERNANCE IN THE
NATIONAL HEALTH SERVICE (UK)
Harry Cayton
National Information Governance Board for Health and Social Care (UK)
Information governance exists in the space between people and data. The legal and ethical framework for the public and private use of personal health information for care, clinical audit, management, and research in England has developed over time. The legal framework is both statutory—as set out in Data Protection Legislation and in the Human Rights Act—and based on legal precedent through the Common Law of England.
Ethical interpretations within the law are overseen at the local level by Caldicott Guardians, by clinical and research ethics committees, and nationally by the National Information Governance Board (NIGB). Of course information governance applies as importantly to paper records as it does to electronic systems. However, the introduction of a national electronic record system has presented new challenges to the application of both legal and ethical practice and required new applications of existing principles to ensure that information technology assists clinicians to provide better care. This short paper therefore deals primarily with the particular information governance issues facing the National Health Service (NHS) in England as electronic systems for gathering, storing, transmitting, and using patient data are developed.
NHS Connecting for Health
The NHS in England has been engaged in creating a health information and communication technology infrastructure since 2002. Initially known as the National Programme for IT and subsequently as NHS Connecting for Health, it has delivered growing interconnectedness of primary and secondary care records, a national personal demographics service using a unique identifier, nearly universal picture imaging and archiving system, a secure provider-to-provider network, a secure NHS e-mail system (NHSmail), e-prescribing and electronic transfer of prescriptions, electronic booking of appointments (Choose & Book), a summary care record, and a patient portal (HealthSpace). This ambitious program has been sometimes controversial and undoubtedly difficult—its benefits are not yet available across the NHS and its delivery is currently under review by the Coalition Government in the United Kingdom—but it has already achieved much.
The objectives of NHS Connecting for Health are
- Ready access to accurate, up-to-date patient information and a fast, reliable, and secure means of sending and receiving information.
- Streamlining clinical practice and smoother handovers of care, supporting multidisciplinary teamwork.
- Online decision support tools, easier access to best care pathways, and faster access to specialist opinions and diagnosis.
- Guidance on referral procedures and clear protocols for clinical investigations.
- More efficient referrals, alerts to conflicting medicines, and early detection of disease outbreaks.
- Reduced administration, paperwork, repetition, duplication, and bureaucracy.
Whatever is decided by the new government in relation to the implementation of the components of electronic health care, its commitment to “an information society” is explicit.
The National Information Governance Board for Health and Social Care
The NIGB is an independent statutory committee established by Act of Parliament in 2008. We advise the Secretary of State for Health on good practice in relation to information governance, specifically on the use of patient-identifiable data for clinical audit and research. The committee has 21 members, half nominated by national clinical and research bodies and half of them appointed from members of the public through advertisement and an independent public appointment system.
There are a number of ways you can define “information governance,” but the NIGB used
Information governance describes the structures, policies and practices which are used to ensure the confidentiality and security of records of patients and service users. Correctly developed and implemented it enables the appropriate and ethical use of information for the benefit of individuals and the public good. (Cayton, 2006)
The important word here is “enables.” Privacy is a great enabler and we need to construct our thinking around this. It’s also important to say that information governance in practice is the responsibility of each and every organization and data processor. The NIGB serves to advise, to support, and to develop standards and principles. Good information gover-
nance provides the framework of interoperability needed to be confident as professionals and as patients in sharing data with each other.
One of the most important things that the NIGB has done is establish a transparent set of principles. These are published, they are contestable, they are publicly viewable, and they set out the basis on which the NIGB approaches the problems (NIGB, 2008):
- People have personal interests and responsibilities.
- Informed consent and autonomy underpin health care.
- It is in people’s interests to have safe accessible care, a sound research base, cost-effective well-managed services.
- Professionals must work within legal and professional frameworks.
We have also published two commitments to patients and the public: the NHS Care Record Guarantee and, more recently, a parallel document, the Social Care Record Guarantee. These set a framework for patients and service users, setting out what we will do with their data and how we will keep it safe. These two guarantees allow both professionals and service users to feel confident about sharing data. The NHS Care Record Guarantee states “this guarantee is our commitment that we will use records about you in ways that respect your rights and promote your health and well-being” (NIGB, 2010). Public trust is an absolutely essential building block of what the NIGB does. We have transparency in all of our business—all of our papers and minutes are published on our website, and we have regular meetings with patient and professional organizations.
Wicked Questions
If there were not wicked questions, there would be no need for the NIGB. Sometimes our principles are in conflict—sometimes the public good, and the individual good are in conflict—that’s the point. These are the issues that the NIGB must resolve, whether it is a discussion about research or a discussion about how much a clinician respects a child’s wishes that their parents do not know something intimate and personal. For these questions, there is no right or wrong answer, just the best answer at the time. That means that in applying our principles we can change our view if we keep consistent with the principles, but the circumstances or the information changes.
A few concrete examples illustrate the type of questions the NIGB has dealt with. We advised the Chief Medical Officer, giving him formal legal cover so that he could collect personal data from patients about swine flu in a way that did not breach either the law or best practice. We have done work on care records for children and young people dealing with difficult
issues about confidentiality and security. We have produced a cartoon version of the Care Record Guarantee for children under 12 explaining to them what happens with their medical records. We have produced guidance on access to clinical information by social workers, and on how to correct or amend records (suppressing records that are wrong as a means of resolving disputes between clinicians and patients about what is in the record).
The Legal Use of Identifiable Data for Research
The NIGB advises the Secretary of State for Health to give researchers permission to use patient-identifiable data without consent. To gain permission, there are two tests applications must pass: (1) getting consent must be unduly onerous, and (2) the research has to be sufficiently important and in the public interest. Quite often we find that researchers can obtain consent and we are able to advise them how to do so. For example, one group wanted to do research looking at the quality of care of children who had recently died. They thought it would be too difficult to get consent from their parents. We were able to put them in touch with children’s hospices who had experience of dealing sensitively with parents and in obtaining consent in these circumstances.
Conclusion
The model of a governance and oversight committee such as the NIGB is only one way of supporting legal, ethical, and confidential data sharing. However we have learned a lot from it. Information governance exists in the space between people and technology. Technology is not the solution; people are the solution. Getting people to use the technology wisely, ethically, and effectively is essential for professional confidence and public trust. All governance systems need the same things: a mechanism for agreeing on and applying consistent principles, checks to ensure that the guidance that you give people is practicable, procedures for promoting consistency, and creditability with both the public and professionals.
REFERENCES
Berman, J. J. 2003. Concept-match medical data scrubbing. How pathology text can be used in research. Archives of Pathology and Laboratory Medicine 127(6):680-686.
Cayton, H. 2006. Information governance in the Department of Health and the NHS. http://www.nigb.nhs.uk/about/publications/igreview.pdf (accessed September 10, 2010).
Damschroder, L. J., J. L. Pritts, M. A. Neblo, R. J. Kalarickal, J. W. Creswell, and R. A. Hayward. 2007. Patients, privacy and trust: Patients’ willingness to allow researchers to access their medical records. Social Science and Medicine 64(1):223-235.
Dreiseitl, S., S. Vinterbo, and L. Ohno-Machado. 2001. Disambiguation data: Extracting information from anonymized sources. Proceedings of the AMIA Symposium 144-148.
Fischetti, M., and J. J. Salazar. 1999. Models and algorithms for the 2-dimensional cell suppression problem in statistical disclosure control. Mathematical Programming 84(2):283-312.
Friedlin, F. J., and C. J. McDonald. 2008. A software tool for removing patient identifying information from clinical documents. Journal of the American Medical Informatics Association 15(5):601-610.
McCarty, C. A., and R. A. Wilke. 2010. Biobanking and pharmacogenomics. Pharmacogenomics 11(5):637-641.
NIGB (National Information Governance Board) (UK). 2008. The principles of the National Information Governance Board. http://www.nigb.nhs.uk/about/meetings/principles.pdf (accessed September 10, 2010).
———. 2010. The NHS care record guarantee. http://www.nigb.nhs.uk/guarantee (accessed September 10, 2010).
Ohno-Machado, L., S. A. Vinterbo, and S. Dreiseitl. 2001. Effects of data anonymization by cell suppression on descriptive statistics and predictive modeling performance. Proceedings of the AMIA Symposium 503-507.
Sweeney, L. 2002. k-anonymity: A model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 10(5):557-570.
Uzuner, O., Y. Luo, and P. Szolovits. 2007. Evaluating the state-of-the-art in automatic de-identification. Journal of the American Medical Informatics Association 14(5):550-563.
Willison, D. J., L. Schwartz, J. Abelson, C. Charles, M. Swinton, D. Northrup, and L. Thabane. 2007. Alternatives to project-specific consent for access to personal information for health research: What is the opinion of the Canadian public? Journal of the American Medical Informatics Association 14(6):706-712.
Zimmerman, B., C. Lindberg, and P. E. Plsek. 1998. Edgeware: Insights from complexity science for health care leaders. Irving, TX: VHA Inc.


















