
3
Vision of the Future: What New Chemicals Could Be Made?
To date, most successful commercial products were carefully selected for their manufacturing via biological synthesis. As discussed in the preceding chapter, a large degree of chemical space is already known to be available for chemical manufacturing. The vision of the future put forth herein is one where biological synthesis and engineering and chemical synthesis and engineering are on par with one another for chemical manufacturing.
The recommendations and roadmap goals outlined throughout this report were all conceived in the context of this overarching vision and are designed with the understanding that, in order for the industrialization of biology to be realized, the use of biological and chemical routes must be thought of as equals. That is not to say that each would be used interchangeably, but that biological routes would be included the same way individual chemical reactions are considered when developing a synthetic route.
Determining whether both biological and chemical routes should be set on equal footing and understanding the potential diversity of chemical products that could be produced are critical to the industrialization of biology. The majority of this chapter is devoted to answering these questions.
The industrialization of biology offers prospects not only for new commercial production and process methods but also for the opening
of novel chemical space for the discovery of functional molecules (e.g., pharmaceuticals, materials, fuels). As discussed in Chapter 4, enzyme- or cell-based synthetic approaches can provide compounds ranging from drop-in replacements—made via processes with economic or environmental advantages over previous synthetic methods—to new structures with improved function or performance relative to their chemical precursors. Targets at either end of this spectrum are subject to very different factors with respect to technological and economic factors influencing their development (Figure 3-1). The Department of Energy’s report, Top Value Added Chemicals from Biomass, 76 provides an excellent discussion of potential targets for the biological production of chemicals.
Both commodity and specialty chemicals can be approached using biological methods but should take advantage of the unique properties of living systems. For commodity chemicals, targets need to add economic value to the starting carbon source (e.g., glucose or cellulose) and can include preexisting high-volume chemicals, biologically sourced
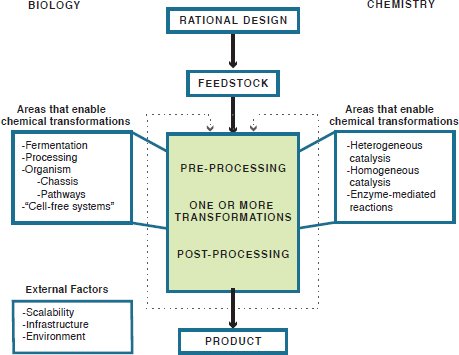
FIGURE 3-1 Chemical manufacturing flowchart, showing the report’s conceptual schema of the chemical manufacturing process and highlighting the techniques of both biology and chemistry that enable chemical transformations.
precursors that may be converted to the desired product through simple chemical transformations, or new structures. These types of targets can provide both economic and environmental benefits via the ability of cells to utilize biomass-derived carbon sources, grow in aqueous media, and carry out multistep transformation of substrate to product in a single reactor. Specialty or fine chemical targets yield more flexibility in approach and cost of manufacture based on their higher value. Indeed for many complex natural products, there may be no existing chemical method for their commercial manufacture. As such, a biological route can provide new access to the target or a semisynthetic intermediate. In addition to multistep cellular transformations, single enzyme-based transformations may also be important in this area because the utilization of enzymatic regio- and stereoselectivity can greatly streamline a chemical process.
The continued development of biotechnology related to chemical synthesis also enables new routes to discovery when combined with the more mature area of chemical synthesis, because it allows opportunities to mix orthogonal structural space. In this regard, living systems produce a wide range of compounds that often demonstrate relatively low structural overlap to those produced via synthetic methods (Figure 3-2). Much of this divergence in structure arises naturally from differences in building block availability and assembly. In general, synthetic compounds are ultimately derived from petrochemical sources with substitution patterns controlled by the selectivity of chemical reagents but can take advantage of a broader coverage of elemental composition, functional groups, and reaction space. In contrast, large classes of biological metabolites often share a biosynthetic logic in their assembly but can utilize the selectivity of enzymes to produce highly complex structures. As such, the development of methods for combining biological and synthetic chemistry could
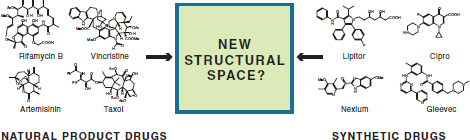
FIGURE 3-2 Low-structural-overlap compounds produced by living systems and synthetic methods. Some of the current targets of chemical manufacturing are identified.
allow the expansion of the accessible structural space for screening new compounds for functional properties.
Natural products and their derivatives remain an important resource for the discovery of new bioactive compounds. They represent a significant portion of new chemical entities while also playing an important role in the identification of druggable targets and pathways for development of synthetic compounds.77 Their success as pharmaceutical agents is likely derived from their natural evolution toward structures optimized to bind macromolecular biological targets, which requires a high structural complexity that can be oftentimes difficult to replicate in a synthetic compound. As such, it is estimated that it is several orders of magnitude more likely that a natural product will bind a cellular target compared to a synthetic compound. However, the use of natural products as lead compounds is quite challenging, because they are difficult to synthesize and structurally optimize for appropriate pharmacokinetic behavior. As such, natural products routinely remain underutilized in the drug discovery pipeline, and advances in biotechnology on many different fronts could greatly alter this landscape.
It is widely accepted that natural products contain an enormous structural diversity. As previously discussed, this structural diversity typically accesses structural space outside of chemically synthesized compound libraries, yet poises natural products for macromolecular target binding. Thus, the inclusion of new natural product structures and their pharmacophores is important for expanding the available space for discovery. However, there are several roadblocks to achieving this goal: most natural products are produced at extremely low yield in their native host; the majority of genes encoding the production of natural products are silent, that is, displaying no detectable phenotype; and most environmental isolates are not culturable under laboratory conditions. Thus, new methods of moving from gene sequence to product are important and could potentially be provided both by the ability to synthesize and express large sets of genes in model hosts and by rapid approaches to domesticate environmental hosts.
While the complexity of natural product structures serves as an advantage in their use as lead compounds, it rapidly becomes a disadvantage given that most lead compounds need to be optimized for proper potency, cross-reactivity, and pharmacokinetic behavior. Semisynthetic approaches, or the direct chemical modification of a natural product or biosynthetic intermediate, are limited in their ability to achieve a broad range of structural transformations of the natural product given their functional group density and lability to harsh chemical reaction conditions. Thus, enzymatic or biosynthetic modifications can provide a new route into structural diversification of natural products for tuning their performance as drugs. In this regard, the identification and characterization of tailoring enzymes that may oxidize, cross-link, or ligate on new groups to core structures are useful. In addition, methods to feed in different building blocks to the biosynthetic machinery can generate much-needed variations in the core structure. Advances in manipulating core structure and tailoring can further help to create diversity by introducing orthogonal chemical handles (e.g., halogens) or new linkage locations (e.g., amines) for downstream enzymatic or chemical reactions.
Tapping New Structural Diversity
Beyond the exploration of natural products classes with known genetic signatures, such as polyketides, nonribosomal peptides, and isoprenoids, there are many structural cores that have yet to be identified or genetically annotated. Among these are nitrogen-rich compounds of varied structure, including alkaloids, which are needed to augment our pool of compounds, as the more well-characterized classes of natural products tend to be oxygen rich (e.g., polyketides and isoprenoids). Modified peptides, both ribosomally and nonribosomally encoded, also represent interesting families for further characterization. Improvements in gene prediction, chromosome modification, host domestication, and small-molecule analysis can aid in this endeavor.
For the development of advanced molecules, the relatively new interface between synthetic chemistry and biology needs to be further enlarged because synergy between these two areas can greatly accelerate the discovery process. For example, microbial fermentation can generate previously untapped monomers for polymer production, but the synthesis and characterization of the resulting materials is equally essential for identifying new properties or functions. Conversely, the analysis of
synthetic bottlenecks in the production of complex targets could allow us to focus on engineering specific enzyme families with the highest potential to enable pharmaceutical research and production. Research directions in this area could include but are not limited to engineering enzymes or pathways for the biological production of complex building blocks, stereo- and regioselective transformation of synthetic building blocks, reactions involving key elements or functional groups, and catalysis of new C-C bond-making reactions. In addition, computational tools to combine biological and synthetic reaction space to analyze the efficiency of different hybrid preparation routes are also necessary to identify specific paths forward for further development.
Engineering the Production of Complex Building Blocks
Building blocks with a high density of stereocenters or functional groups can often be derived from biological sources. Some examples include isoprenoids, sugars, and other classes of metabolites, which are used as synthetic starting materials but also can affect the price and availability of the final product. One example was previously presented for the production of artemisinin from a microbially derived semisynthetic intermediate. In this case, both the intermediate and the target compounds are natural products and synthetic chemistry is used to scale up a biologically difficult reaction that ultimately opens access to a low-cost antimalarial drug.
A different type of advancement in this area can be illustrated in the commercial synthesis of oseltamivir (Tamiflu), a synthetic antiviral compound prescribed for avian flu that is made from shikimic acid. This biosynthetic intermediate is produced by microbes and plants but at such low levels that its availability controls that of Tamiflu. As a result, a strain of E. coli was engineered to highly overproduce shikimic acid and has greatly increased access to Tamiflu.78 In contrast to the example of artemisinin, Tamiflu is not itself a natural product but simply takes advantage of the existing stereocenters in a biological metabolite to reduce the cost of the target compound. Without using the innate stereochemistry of shikimic acid, the synthesis of Tamiflu would likely require several steps resulting in higher prices and decreased availability.
Beyond traditional natural products, biological systems are also uniquely poised for the generation of other types of structures with challenges of regioselectivity and stereoselectivity. One example is represented by polysaccharides, which can be important modifiers of bioactive agents. Their chemical synthesis requires extensive and laborious protection and deprotection routines to achieve regioselective assembly but can potentially be put together instead from their unprotected parental sugars using glycosyl transferase enzymes.
The ability to take these routes and use computational analysis or software to identify these points of overlap rather than relying on human insight could greatly accelerate similar projects. By extension, large-scale analysis of various synthetic routes could also help to identify classes of molecules or patterns of substitution that could be produced using biological systems as useful synthetic building blocks.
Engineering the Stereo- and Regioselective Transformation of Synthetic Building Blocks
Enzymes excel at selective transformations and have been used as reagents for individual transformations of synthetic intermediates when chemical reagents are difficult to optimize for a particular reaction. In many cases, the adoption of an enzymatic step could streamline the synthetic route, which may utilize a number of additional steps in order to avoid a particularly challenging problem in asymmetric catalysis. In this case, families of enzymes, such as ketoreductases, esterases, peptidases, and transaminases, have been well developed for these applications.79 One important advance was achieved for sitagliptin (Januvia, Merck), where a partnership between enzyme engineering and chemical synthesis led to the insertion of a transaminase-catalyzed step, thereby reducing the step count in its preparation.80 Currently, we are limited to a select group of enzyme families that are known to be naturally accommodating to wide ranges of substrates, which correspondingly limits the scope of transformations that are targeted for this approach. Thus, the identification and implementation of new target enzyme families and transformations could greatly accelerate advances in this area.
Catalysis with Key Functional Groups and for New C-C Bond-Making Chemistry
Compared to the chemical reaction scope, cells typically use a smaller set of functional groups and lower diversity of C-C bond-forming reactions, because enzymes can use substrate and product selectivity to form the correct bond amidst many different possibilities. In comparison, synthetic catalysts tend to use functional group orthogonality and/or protecting groups to achieve selective bond formation. Thus, an interesting area of development could incorporate enzymes to install rarer elements or synthetic functional groups for function or as synthetic handles for downstream chemical catalysis. In addition, new enzyme classes could also be evolved to catalyze C-C bond coupling reactions from synthetic building blocks. Some examples of useful functional groups could be fluorine to tune bioactivity and pharmacokinetic properties81 as well as orthogonal synthetic handles such as other halides (X = Cl, Br, I), nitriles, boronic
acids/esters, or alkynes for cross-coupling reactions such as those developed by Heck, Stille, Negishi, and Suzuki; Sonogashira; and BuchwaldHartwig. One example where synthesis has inspired the development of new reaction chemistry involves the engineering of cytochrome P450s for the insertion of C or N rather than O to form cyclopropane or aziridine rings.82 In addition, the exploration of biodiversity leads to the discovery of new families of enzymes that could be useful for synthetic applications, such as those catalyzing Pictet-Spengler83 or Diels-Alder84 reactions.
Polymers are organic macromolecules made of repeating monomer units that are valued for their tunable functional and structural properties. Indeed, polymers are used for a broad range of applications, from use as plastics, rubbers, fibers, and paints to controlled drug release and electronic displays. They are derived from biological sources, such as natural rubber, silk, and cellulose, as well as synthetic origins, such as polyethylene, polystyrene, nylon, silicone, and polyvinyl chloride. Polymer properties are controlled by many variables, including monomer structure, bonding between monomers, tacticity, average molecular weight, polydispersity, and branching for homopolymers. Co-polymers made up of more than one monomer type expand this range even further to include attributes such as monomer arrangement (periodic, statistical, or random) or co-block characteristics. These structural features influence intra- and interchain microstructure that in turn control bulk material properties that are important for function, such as melting temperature, crystallinity, glass transition, tensile strength and elasticity, transport behavior, and electronic response.
The relationship between chemical and materials properties has been well explored but remains challenging to predict from a new monomer given the breadth of different polymers that can be accessed. At this time, many of the commodity polymers are constructed from building blocks that can be prepared from readily available petrochemical sources. However, living systems provide a vast array of bifunctional compounds that can be used as monomers, the majority of which have yet to be tapped for polymer synthesis. This section covers opportunities in metabolic engineering for existing and new monomers and polymers.
One approach is the direct replacement of existing monomers derived from petrochemical sources with the same structure made by microbial fermentation. A key advantage in this strategy is that a drop-in replacement already has a current market demand. However, two major chal-
lenges are that it can be difficult to either ferment the monomer at a competitive price with the existing competitor given their low cost and the capital investment associated with building plants for a new process or to displace significant volume of the petrochemically derived monomer because of their high usage. An example of a microbially sourced monomer currently on the market is ethylene (or “bioethylene”). Ethylene represents one of the highest-volume monomers in use today (~140 million tons per year) because it is found in approximately half of all plastics as a homopolymer (e.g., high- and low-density polyethylene) and co-polymer (e.g., polystyrene, polyvinyl chloride, and polyethylene terephthalate).85 Bioethylene is produced by microbial fermentation of sugar to ethanol followed by chemical dehydration and is produced at a large scale (~200 kilotons [kt] in 2013).85 For comparison, if all the ethanol produced by microbial fermentation for transportation fuels were converted to bioethylene, then this volume could reach approximately 25 percent of the annual ethylene feedstock currently needed.85 While it can be produced at a similar cost as petrochemical ethylene, the price depends greatly on the cost of sugar, which is currently a highly volatile feedstock. Other examples of monomers in the development pipeline at this time are butadiene (from dehydration of 1,4-butanediol, Genomatica),86 acrylic acid (from dehydration of 3-hydroxypropionic acid, Cargill, OPXBIO; or lactate, Myriant),87 and isoprene (Dupont and Goodyear). All three of these monomers are targeted toward large-volume markets. Other similar targets can be identified by examining the commodity chemicals market and could be prioritized by their biosynthetic complexity as well as the range of polymer products, because niche markets could potentially be easier to move toward biosourced monomers.
Another approach is the development of new monomers to produce novel polymers. Although the market for these new monomers is more difficult to characterize, they do not need to directly compete with an existing product made through a mature process. This approach also allows polymer chemists to explore greater chemical space to improve the material properties of polymers or to discover entirely new functions. In general, many commercial polymers have been developed from readily available petrochemical feedstocks and optimized for their intended application by controlling various parameters as discussed above. As such, compounds falling into the same chemical class as known monomer feedstocks, but with different substitution patterns, could be funneled into the same polymerization pipeline but impart altered properties to homo- and co-polymers.
One example is Bio-PDO®: Before the advent of Bio-PDO, 1,3-propanediol (PDO) was considered a specialty monomer but still fell into a chemical class with known polymeric products generated from structurally similar but more readily available diols, such as ethylene glycol or propylene glycol. However, the new microbial process for its production enabled greater access to this monomer and led to the development of new polymers that have earned significant market share.
A second example that highlights the interplay between chemistry and biology is polylactic acid (or polylactide, PLA) made from the microbially sourced lactic acid monomer, developed by NatureWorks.88 Similar polyesters, called polyhydroxyalkanoates (PHAs), are made by microbes for carbon storage from a variety of 3-hydroxyacids and are thus biodegradable.89 As such, a significant research effort was made to develop plant- or microbe-based processes for its industrial production of PHA and PLA because a biosourced and biodegradable polyester could have interesting applications. The underlying biology of these systems involved in controlling important parameters including chain length and polydispersity is quite complex and remains insufficiently understood for rapid engineering. As a result, the polymer properties of bioengineered PHAs were difficult to tune compared to synthetic polyesters made from mature chemical processes. NatureWorks developed instead a process based on the chemical polymerization of lactate, which is also a 3-hydroxyacid even though it is not typically a physiological monomer for PHA biosynthesis. Using this approach, their overall process could rely on a robust fermentation process for the monomer, because many organisms are known to ferment glucose to lactate at near quantitative yield, and a well-characterized chemical polymerization to PLA, which allows for control over its material properties while maintaining the biodegradability of the polymer.
Taking this bioinspired approach, there already exist many classes of bifunctional small-molecule metabolites that fall into categories of known monomers or monomer precursors that can be processed within a few downstream chemical steps (e.g., dehydration, oxidation, and reduction). For example, different combinations of carboxylic acid, ester, ketone, aldehyde, amine, alcohol, olefin, and epoxide functional groups could be directly incorporated into polymers such as polyesters, polyamides, nylons, polyolefins, synthetic rubbers, polyethers, and others. Because small structural changes in monomer structure, such as stereochemistry, substitution patterns, or spacing between functional groups, can greatly affect polymer performance, these monomers could be explored for their behavior in homo- and co-polymers. The biosynthesis of some of these monomers could then be directly engineered from existing pathways or could also be greatly diversified by engineering pathways to accommodate greater structural diversity.
An interesting area for the development of high-performance polymers could be templating or engineering the assembly of monomer units using polymerase enzymes to regulate important features that may be difficult to control using chemical catalysts, such as sequence, tacticity, block size, or branching. While the enzymatic selectivity filter for some of these properties may not yet be sufficiently understood for engineering purposes, the ability to precisely tune these properties could transform the scope of polymer behavior that can be achieved.
Protein polymers offer a key example of how precise control over sequence and chain length can impart key material properties. There are many examples of polypeptide-based materials, such as silks, wool, or collagen, which are genetically encoded and synthesized via the ribosome. Using the 20 canonical proteinogenic amino acids as well as others, an enormous amount of structural and functional space of the resulting polyamides can be examined. Currently, there already exists a large body of work on peptide-based materials and their self-assembly into materials with unusual properties.90 In addition to side-chain diversity, it may also be possible to examine features such as tacticity by altering interchanging L- and D-stereochemistry around the alpha carbon or branching from side-chain functional groups by post-translational attachment of different structures. Another area of research is the use of the templating afforded by the ribosome to make different classes of polymers, such as polyesters.91 A key challenge in this area for industrial-scale production is the development of robust methods for engineering the export of the target polypetides to allow for their scalable collection as individual polymers or as fibers.
In addition to genetically templated macromolecules, such as polypetides, polymerases can also catalyze the assembly of alkanes (fatty acid synthases), polyketide-based structures (polyketide synthases), mixed peptide and ketide structures (hybrid nonribosomal peptide and polyketide synthases), polyesters (PHA synthases), oligosaccharides (glycosyl transferases), and others. All of these structures can be produced using a broad range of monomers, which can either be selectively or non-selectively chosen by the particular enzyme. Developing a better understanding of how these systems control polymer structure and monomer selection could allow us to selectively generate either new monomers or polymers with high functionality.
Polymers for Templating the Formation of Inorganic Materials
In addition to the production of purely organic materials, biological systems can also use the self-assembly of these biopolymers to template
the formation of inorganic and composite organic and inorganic materials made of calcium, silicon, iron, manganese, and copper. Some naturally occurring examples include bone, nacre, diatom frustules, and magnetite nanocrystals. In these cases, the nanostructure of these materials is highly controlled in terms of chemistry (e.g., composition and mineral structure) as well as structure (e.g., size and shape).91b, 92 This approach has inspired the development of methods to evolve polymers, such as peptides, to template and control the shapes of different minerals. A major challenge in this area again is the consideration of cost in the scalable production of materials through this route, which could be correspondingly improved by the development of methods for extracellular delivery of the templating agents.
BUSINESS MODELS FOR FUTURE INDUSTRIAL BIOTECHNOLOGY
The term “vertically integrated development” is used to describe a future in which biomanufacturing process research and development is performed by vertically integrated corporations that develop the entire bioprocess from end to end: from feedstock sourcing to organism engineering to manufacturing and sales. In this future, successful industrial biotechnology companies are comparable to Intel: they encompass everything from design to manufacturing.
The term “horizontally stratified development” is used to describe a future in which there is a stratified industry for biomanufacturing process development in which different companies specialize in different steps along the supply or value chain. For example, one company may focus on feedstock sourcing, another on organism engineering, another on scale-up and manufacturing, and still another on marketing and sales. In this future, the industrial biotechnology industry is comparable to the PC industry of the 1990s in which different companies manufactured the hardware components, assembled the computers, wrote the operating system, and developed the software applications.93
The term “centralized production” is used to describe a future in which the biomanufacturing of chemicals occurs in a handful of very-large-capacity biorefineries that take advantage of economies of scale to eliminate inefficiency and produce chemicals with razor-thin cost margins and at volumes sufficient to meet world demand. In this future, chemical biomanufacturing looks similar to the oil and petrochemical industry in which there has been a persistent trend toward ever fewer and ever larger oil refineries over the past two decades.94, iii
_______________________
iii In 1994, the United States had 179 operable crude oil refineries capable of distilling just over 1.5 million barrels per day. In 2014, the United States was down to only 142 operable refineries but had a distillation capacity of nearly 1.8 million barrels per day.
The term “distributed production” is used to describe the local, small-scale manufacturing of chemicals. In this future, these specialized biorefineries might use geographically co-localized feedstocks and produce only enough product to meet local demand. In this future, chemical biomanufacturing looks similar to the home brewing or microbrewery industry of today.95
Examples of these definitions are presented for comparison in Box 3-1.
Although the envisioned future is presented here as discrete scenarios for simplicity, it should be noted that there exists a continuum of possibilities between these scenarios. For example, distributed production may result in biorefineries of sufficient size to supply a nation, a region, a city, a neighborhood, or just a single household. As a second example,
BOX 3-1
Vertically Integrated Development
Research and design for biomanufacturing is performed by corporations that develop the entire process end-to-end: from feedstock sourcing to organism engineering to manufacturing and sales.
Apple Inc. is a contemporary example of this, with design, operating system, sales, and service being provided by Apple Inc. itself.
Centralized Production
Biomanufacturing occurs in a handful of very large capacity facilities that take advantage of economies of scale to eliminate inefficiency and produce chemicals with thin margins and at volumes sufficient to meet world demand
The petroleum industry is a contemporary example of centralized production.
Horizontally Stratified Development
Research and design for biomanufacturing is performed by different companies that each specialize in a different step along the production process.
The PC industry is a contemporary example of this, with design, components, assembly, operating systems, software, sales, and service being provided by specialized companies.
Distributed Production
Biomanufacturing occurs in many local, small-scale facilities, potentially using geographically co-localized feedstocks and producing only enough product to meet local demand.
The home brewing or microbrewery industry is a contemporary example of distributed production.
the degree of stratification in the horizontally stratified industry may vary. Organism engineering may constitute a layer within the supply chain, or it may be further stratified into design firms, DNA synthesis and assembly firms, and organism testing and validation firms. Finally, even in a future where horizontally stratified development is the norm, it may still result in centralization within particular strata—akin to Microsoft’s dominance of operating systems on the PC in the 1990s.
Moreover, these discrete scenarios for the future are not mutually exclusive. It may be that some sectors of industrial biotechnology may lend themselves to centralized versus distributed production. For example, specialty ingredients—high-value chemicals that make up fast-moving consumer goods—will not require biorefineries at comparable scale to those needed for fuel production because the volumes needed to satisfy consumer demand are several orders of magnitude lower than for fuels. So the very nature of the specialty ingredients industry (hundreds of ingredients each at smaller volumes and higher price points) versus the commodity chemicals industry (dozens of chemicals at very large volumes with thin margins) may result in a hybrid chemical bioproduction model.
Furthermore, the degree of stratification or centralization of an industry can swing back and forth over time. As a particularly relevant case in point, DNA sequencing began as a highly distributed technology that was largely performed by individual researchers and labs. Then, driven in part by the Human Genome Project and the desire to push down the cost per base pair of sequencing DNA, there was a move to sequencing centers such as the Broad Institute of MIT and Harvard, the Sanger Centre, the Beijing Genome Institute, and the Department of Energy Joint Genome Institute. Today, while centralized sequencing centers continue, the falling costs of sequencing instruments are making genome sequencing at the individual laboratory scale possible once more.














