
4
Developing Smart Machines
![]()
Machines, ancient and modern, are tools to serve our needs. For eons they have carried out a huge variety of tasks, from manufacturing goods, to transporting people around, to helping us decipher the natural world, to simply entertaining us. Machines can fight, protect, heal, and even teach us. But what they have not been able to do until quite recently is to learn, make decisions, and act on their own.
Today, intelligent machines are everywhere. From the Netflix recommendation engine to Google Translate to Apple’s Siri voice-recognition system, artificial intelligence has become sufficiently accurate, reliable, and useful to find its way into numerous devices and applications. These technologies have taken off in parallel with a dramatic expansion of the amount and complexity of data, which provides fertile teaching ground from which machines can learn to make intelligent decisions on their own.
In the related area of robotics, engineers have made remarkable achievements by combining sophisticated software and artificial intelligence with equally sophisticated hardware to create machines that perform useful tasks in diverse real-world contexts. These robots now provide a variety of valuable services and perform activities that it would be impossible or dangerous for humans to attempt.
This chapter presents an introduction to key concepts in machine learning by Jaime Carbonell of Carnegie Mellon University; a history of artificial intelligence achievements by Eric Horvitz of Microsoft; and an exploration of robotics by Rodney Brooks of ReThink Robotics.
MAKING MACHINES LEARN
Most tasks performed by computers today are the result of traditional programming: Systems are developed to perform specific functions in response to specific inputs in order to fulfill a predetermined set of requirements. But in an increasing number of scenarios, we need computers not only to do the things they are programmed to do, but also to be able to take inputs and tell us something we didn’t already know or perform a task we didn’t specifically tell them to do—in short, to acquire the skill of learning.
Machine learning is a field that combines artificial intelligence, which is the ability of machines to make intelligent decisions, with data analysis, which allows machines to gain knowledge. There is a great deal of crossover between machine learning and artificial intelligence, and some see machine learning as a subfield within the broader scope of artificial intelligence. Essentially, machine learning is what lets computers discover patterns within data and then use those patterns to make useful, and ideally correct, predictions. Those predictions can then be used to make decisions or take actions that are appropriate for a given situation, the same way a human would.
Jaime Carbonell, a professor of computer science at Carnegie Mellon University and an expert in artificial intelligence and machine learning, presented an overview of the key challenges and approaches involved in machine learning.
How to School a Computer
Machine learning has virtually unlimited economic and consumer applications for fields as varied as medicine, robotics, finance, entertainment, and transportation. “Machine learning essentially is the engine that is driving modern artificial intelligence,” said Carbonell. “And the big impact is everywhere.” While a traditionally programmed self-driving car might be able to find its way around a city, it takes machine learning in order for a car’s driving system to notice another driver’s behavior, predict that he or she is about to cut in front of it, and slow down to allow that event to happen safely. By harvesting information from the environment, machines can adapt to our dynamic world to make smarter decisions.
Carbonell described the complex, multistage process of teaching a machine to learn. Central to machine learning is the process of feeding training data into a mathematical prediction model in order to test and refine the model to the point that the machine can use it to acquire and apply future knowledge. A key goal of this continuous learning process, Carbonell explained, is to minimize errors by continually assessing the difference between actual outcomes and predictions made by the machine-learning system. Minimal error is crucial to many machine learning and artificial intelligence applications—for example, when models are used to guide health care decisions or military activities or to design a system for manufacturing airplanes.
To further refine the learning algorithms, engineers must train the machine to appropriately handle and learn from outliers, rather than just typical data. In traditional statistics and engineering applications, researchers seek the most accurate reflection of a data set as whole and try to weed out or de-emphasize rare or extreme cases that do not reflect the norm. In machine learning, on the other hand, researchers cannot ignore rare cases; in fact, it is these outliers that give the machine some of its most important learning opportunities.
For example, machine learning often deals with unbalanced data sets in which the ultimate focus of decision making is precisely the outlier cases. In medicine, very few patients will actually have the rare disease researchers are interested in. In airplane safety, very few flights will result in accidents, yet these present the greatest learning opportunities Therefore, in machine learning, such instances are not mere statistical noise, but central lessons for the system to learn from: If you ignore the outliers, Carbonell said, “you could miss everything that is interesting.”
Broadly speaking, machine learning engineers select mathematical models, analyze historical data sets to generate and refine their models, and then apply the models to make predictions about new data. Through this process computers can be developed that use mathematics the way humans use mental models when they encounter a new situation, recognize a pattern, and adapt their behavior to it. In computers, this is known as transfer learning. Along with related theories such as deep neural networks and proactive learning, transfer learning is seen as an important driver for future machine learning advances.
Tapping Big Data
Recent years have seen a surge of progress in machine learning thanks in large part to the rapid growth of big data, the enormous data sets now being generated by thousands of information-sensing devices in both the scientific world and the everyday world. Big data is now integral to every branch of science: “Not everything in the disciplines is big data or data sciences, but data sciences has a part of every single one,” said Carbonell. “Data science, which you can loosely define as big data plus machine learning plus domain knowledge, is the big win in this area—their combination is the big win.” Because big data sets are large scale, highly complex, and multidimensional, they are extremely difficult to work with. Many layers of computing technologies, such as cloud storage, privacy and security controls, data merging and cleaning algorithms, and other tools and methods are required in order for a big data set to reach a state where analysis can occur.
Only once big data is in this state can it be incorporated into machine learning. Carbonell explained that big data has propelled numerous recent advances in machine learning; on the flip side, it is precisely because we are in an era of big data that we need
machine learning systems more than ever. Machine learning has become crucial to the ability to sift through, analyze, and understand today’s highly complex data.
Creating the Multilingual Computer
Much of Carbonell’s work has focused on imbuing machines with the ability to process natural human language. Reflecting on the history and current state of this field, Carbonell noted that rather than being a linear progression of ideas and methods, the dominant theories in machine-based language translation systems today are the product of a collective development of numerous different theories that have evolved and converged over the years.
In particular, Carbonell identified two key moments in the development of machine translation. The first took place in the mid-2000s, when rule-based language translation systems (which retrieve information from dictionaries and grammar rule sets) were replaced by statistical translation systems (which use statistical models based on the analysis of parallel texts). This transition enabled the invention of Google Translate and similar services, which represented a significant breakthrough, albeit still with relatively high rates of error compared to human expert translations.
A second advance was structural learning. Using structural learning, a system can translate whole language structures, as opposed to individual words or phrases. One of its advantages is that words and sentences can be reordered, even across large chunks of text, creating a smoother, more natural output as opposed to a clunky, word-by-word translation. It is a far more complicated, but more promising, area of research, and Carbonell said ongoing work in this area has already greatly reduced machine translation error rates. And, the combination of structural learning and deep neural networks promises further improvements.
One particularly complex problem facing machine translation today, according to Carbonell, is dealing with rare languages. Uncommon languages create two main hurdles for current machine translation techniques: First, there is generally not a lot of existing data a computer can use to learn the language, and, second, in some cases rare languages have substantially different structures, such as more complex morphology, than more common languages. Yet incorporating rare languages into machine translation is worthwhile, because it could help to preserve rare languages, such as Alaska’s Iñupiaq or Greenland’s Kalaallisut, and also to make the Internet and the outside world more accessible to speakers of such languages.
Another key challenge is decoding word ambiguity. Carbonell illustrated this challenge by presenting different uses of the seemingly straightforward English word “line.” Line can refer to a power line, a subway line, an actor’s line in a play, online, or many other meanings, and machine translation systems must use context to decide which
meaning is correct. Big data and innovative algorithms are crucial to developing models that can better handle such challenges.
Harnessing the Wisdom of Crowds
Engineering a machine learning system and giving it data to learn from is not sufficient to create a truly intelligent machine. Carbonell pointed out that learning in machines, like learning in people, takes time and tinkering.
He explained that active learning is crucial to this process in which the computer identifies questions or missing data and actively seeks answers or data to fill in the gaps. It is a continuous cycle between a computer and a human that allows the machine to refine its knowledge and understand nuance. In the case of machine translation, for example, the computer attempts a translation, identifies a missing piece of information, and then asks a human to supply it. The machine then incorporates that data, and all the other data gleaned from active learning, into its models to create better and better translations over time.
Instead of one expert supplying data, Carbonell said this function can also be performed by a crowd of nonexperts, which can be a less expensive approach to training a machine using active learning. When working on a translation, for example, the computer would catch an obvious error and solicit suggestions from the crowd. The crowd, offering subtly different translations, cumulatively helps to reduce ambiguities and improve the translation model. The process ultimately results in translations that are better than any single nonexpert in the crowd could create alone. Although machine translation might not be as good as a professional human translator, the large and nuanced body of information created by the crowd helps the machine produce language that is recognizably human. Machine learning is successful, Carbonell noted, because “there’s no data like more data.” More data bring more learning. Although Carbonell acknowledged challenges to working with a crowd of nonexperts to refine machine translation models, these can be overcome and are worth the excellent training the translation systems receive.
In Carbonell’s view, future machine learning research will benefit from both the large increase in available data and the rise of crowdsourcing. Crowdsourcing can work especially well with a crowd of experts. In computational biology, for example, harnessing the collective ideas of multiple biologists has helped to parse complex and variable protein structures or interactions between proteins, tasks that are exceedingly difficult for one person or machine to perform alone but that can provide important insights for the development of new drugs or vaccines.
With the advent of the era of big data, today is an exciting time for machine learning. By taking advantage of new, vast data sets and new modeling techniques, machine
learning researchers are making important strides toward intelligent machines that can bring enormous benefits to medicine, education, energy, finance, and society as a whole.
ACHIEVEMENTS IN ARTIFICIAL INTELLIGENCE
The goal of artificial intelligence (AI) is to create computers capable of making decisions that produce a realistic outcome that is as good as or better than the outcome when decisions are made by humans. There are numerous applications of these technologies, and they are largely used to augment or support human activities by going beyond human decision-making capability in some way. In some cases, artificial intelligence enables decision making in situations that are beyond the reach of humans owing, for example, to danger or physical constraints. In other cases, it is used to inform decisions that require more data than any human could access or process alone.
The idea that machines could be built to think like humans is as old as computers themselves. Eric Horvitz, managing director of Microsoft Research’s main Redmond laboratory and an expert in artificial intelligence, presented an overview of the history and primary achievements of artificial intelligence research and development.
Creating the Theoretical Foundation
Although the term “artificial intelligence” was not coined until the 1950s, an important predecessor field, known variously as operations research or decision science, blossomed in the 1940s and laid much of the groundwork for the birth of artificial intelligence. Operations researchers studied analytical methods to create models that aid in decision making. Building on this context, John McCarthy, one of the co-founders of artificial intelligence, coined the term in a 1956 proposal to pursue work related to forming abstractions, self-improvement, manipulating words, and developing a theory of complex intelligences. Notably, these are still active areas for artificial intelligence research today.
Horvitz described the development of artificial intelligence in the years since as a multisector, cooperative process spanning decades. “This has been a very shared, collaborative process across industry and academia with great funding from the agencies,” he said. After branching away from operations research in the late 1950s, artificial intelligence researchers became particularly interested in logic, searching, and finding acceptable but not necessarily optimal, results (known as “satisficing”) to make decisions. Although this divergence narrowed the focus of artificial intelligence somewhat, it also led to significant innovation.
In the mid-1980s, the field went through another transformation focused on how to handle uncertainty. Unknowns are inherent in any system, and dealing with these
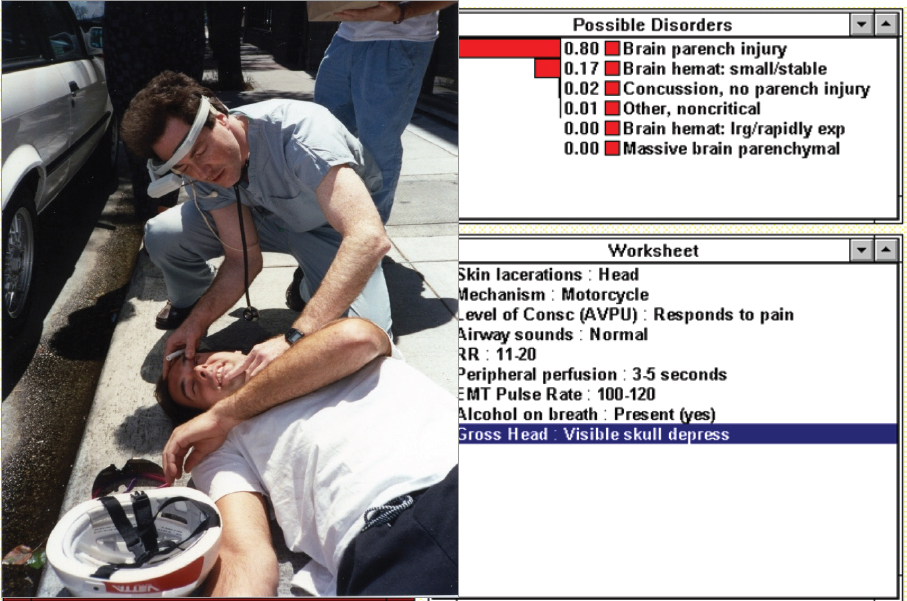
creates pressures in artificial intelligence, such as how to make decisions in high-stakes scenarios or within realistic constraints, how to learn in an environment where data keep increasing, and how to interact with real people in the real world. Opting to reduce their emphasis on resolving uncertainty altogether, researchers in this period became more focused on using artificial intelligence to solve specific problems. In one DARPA-funded study, for example, paramedics used artificial intelligence–enabled devices to receive real-time advice while treating a patient in crisis (see Figure 4.1). One important outcome of this early research was what are known as “approximations.” When a patient is gasping for breath, there is not enough time to run through every possible reason why this is happening and create a subsequent care plan; using approximations allows a system to compute decisions and determine each outcome quickly and coherently.
These theoretical and methodological advances were driven largely by government funding, Horvitz explained. Over time, numerous federal agencies have been interested in pursuing artificial intelligence for a variety of applications, from health to space exploration. Agencies including the National Science Foundation (NSF), the Office of Naval Research (ONR), the National Library of Medicine (NLM), and the National Aeronautics and Space Administration (NASA) greatly advanced the field in its early days, in Horvitz’s view, through targeted funding of early artificial intelligence and machine learning research.
Impacts and Achievements of Research on Intelligent Machines
This early, government-funded artificial intelligence research had an enormous impact, not just on technology but also directly on the U.S. economy. In the 1990s, pairing artificial intelligence research with the growth of the Internet enabled the creation of e-commerce, a crucial driver of today’s economy. For example, about 20 years ago researchers started working on what is now known as “collaborative filtering.” This artificial intelligence fuels the recommender engines on websites like Netflix and Amazon—the “you might also like” suggestions that propel a significant proportion of e-commerce activity. Researchers with the inclination—and funding, largely from government sources—played an instrumental role in developing and refining collaborative filtering, enabling the eventual commercial applications that we depend on today.
Other key achievements in artificial intelligence that can be traced to early government-funded research include computer-aided perception, language, and movement tracking. Horvitz described how research funded by DARPA and other agencies followed a clear path to today’s face recognition technology, now used in myriad applications including military intelligence and national security, crime-fighting, and consumer uses. Today’s artificial intelligence systems can process and match data based on images of faces as well as auxiliary information such as location, events, and even clothing.
As techniques for perceiving visual cues and understanding language became more refined, these developments also paved the way for teaching machines how to track and understand human movement. Research in this area led directly to consumer products like the Xbox Kinect and Nintendo’s Wii, which track and respond to the body’s movements. To artificial intelligence researchers, Horvitz said, these products seem shockingly inexpensive considering the enormous amount of hard work and innovation that led to their invention.
Another key innovation rooted in artificial intelligence research is stacked representation, also known as neural networks. Although this modeling approach emerged in the late 1980s, there were not enough data available at the time for neural networks to make accurate predictions. With the rise of big data and today’s data-intensive scientific methods, together with conceptual advances in how to structure the networks, neural networks have reemerged as a useful way to improve accuracy in artificial intelligence models. They have been applied, for example, to reduce the error rate in speech recognition systems. These advances enabled many innovations, such as the Skype real-time translation service, which, Horvitz said, “would stun our colleagues 10 or 15 years ago.”
Since Horvitz’s early experience with the DARPA-funded project to provide artificial intelligence support for paramedics, the field has advanced numerous applications in health care, including increasing hospitals’ ability to predict readmissions and allowing doctors to perform surgery remotely, a technique known as telesurgery (see Figure 4.2).
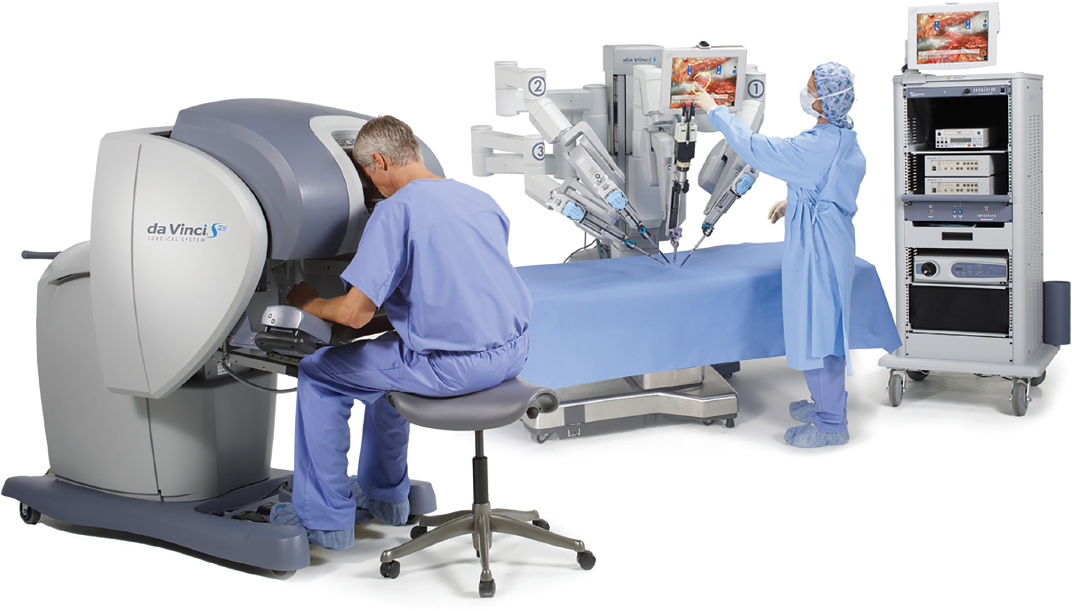
Successful telesurgery research, funded by DARPA, enabled researcher Phil Green at SRI to create Intuitive Surgical, a company of substantial value specializing in methods that enable minimally invasive surgery through robotics and artificial intelligence. “It’s stunning what the DARPA investment could do,” reflected Horvitz.
Promising Prospects for the Future
Today, artificial intelligence work continues to advance through collaborations among industry labs and federal agencies. For example, work by Microsoft and Google, building on advances funded by DARPA, has led directly to technologies we now use daily, including grammar checking and personal assistants like Siri and Cortana. In transportation and infrastructure, artificial intelligence work has been applied to improve wind maps for aviation and urban traffic modeling, among many other things.
Future artificial intelligence research, Horvitz predicted, will likely include enhancing vehicle safety, improving self-driving cars, and improving the ability of computers to answer deeper questions. Human–machine collaboration, in which a problem is divided into two parts, one given to a computer and one to a human to work on together, also holds great promise. For example, a surgical approach in which a machine and a human work together could bring huge benefits to patients and medical staff.
Horvitz identified augmented cognition, where machine learning complements human cognition in areas such as memory, attention, or judgment, as another exciting
research area. Integrative artificial intelligence, or the creation of systems that can interact with the complexity of real-world settings, also holds great promise. Integrative artificial intelligence, said Horvitz, could be the key to transforming computers, which currently have deep but very narrow intelligence, into broader, more humanlike thinking machines.
It is clear from Horvitz’s many examples that government-funded artificial intelligence research has reaped many benefits for the technology sector, the economy as a whole, and our everyday technologies. Continued research will no doubt bring future rewards in this promising and fast-evolving field, Horvitz said.
ROBOTICS: FROM VISION TO REALITY
Robotics is another area in which engineers have made remarkable gains in developing machines that can operate independently and make smart decisions. Today’s robotics achievements reflect a strong government–industry–consumer pipeline that has had important impacts on science, industrial manufacturing, and our everyday lives.
Rodney Brooks has long been at the forefront of this field. Among the earliest pioneers of robotics, Brooks has seen his work go to Mars and into people’s kitchens. His work at Stanford University in the 1970s, funded by NASA, focused on creating simple mobile robots. At the time, creating robots also required that one either invent or implement needed components such as stereo vision, map building, and planning. At the time, creating a robot able to move 20 feet by itself over the course of 6 hours was considered a huge victory. As today’s Martian rovers and vacuuming robot Roombas make clear, we have come a long way.
SLAM Dunk
According to Brooks, one of the most crucial innovations that propelled robotics into the field as it is known today is SLAM (Simultaneous Localization And Mapping). SLAM is an essential skill for robots: it is what gives them the ability to enter an unfamiliar environment, map it, and understand their own place within that map. Remarkably, two papers presented at the same conference in 1985, one by Brooks and his team at MIT and one from a laboratory in France, trying to solve the same problem independently, led to SLAM’s creation.1 After the conference, the two teams’ work was disseminated across the robotics research community.
___________________
1 R.A. Brooks, 1985, Visual map making for a mobile robot, pp. 824-829 in 1985 IEEE International Conference on Robotics and Automation, Proceedings, doi:10.1109/ROBOT.1985.1087348; R. Chatila and J.-P. Laumond, 1985, Position referencing and consistent world modeling for mobile robots, pp. 138-145 in 1985 IEEE International Conference on Robotics and Automation, Proceedings, doi:10.1109/ROBOT.1985.1087373.
SLAM turned out to be key to solving many thorny robotics issues, and by 1991 the academic research community had collectively made significant improvements on initial SLAM approaches. This process, said Brooks, illustrated how the community inspires itself and propels research forward, from one federally funded idea to another. It also showed how making a hardware prototype, however imperfect, freely available for others to tinker on moved robotics from a nebulous theoretical area to a series of well-defined research problems that scientists could then collectively solve. Initially the bulk of this work was led by federally funded labs at Stanford, MIT, and the University of Pennsylvania; by the mid-1990s, many more researchers were working on further improvements.
Some initial robotics projects were funded by DARPA, NASA, and NSF for applications in defense, space, and science, respectively, but the consumer products industry also benefitted from this research. In fact, the self-driving Google car and other high-end cars with highly computerized functioning are direct descendants of SLAM and DARPA-funded research. Federal Grand Challenge and Urban Challenge grant programs were specifically launched to drive innovation and progress on functional autonomous vehicles; industry then took SLAM out of the labs and put it on real roads. “There’s a long history, from the late 1970s to now, of an idea that wasn’t about self-driving cars when it started—it was about navigation on other planets,” reflected Brooks.
Learning from Nature
Of course, robots do not only need to understand and map their environments; they also need to physically navigate them. Stuck on the problem of improving robots’ ability to navigate the rough and unpredictable terrain on other planets, Brooks turned to an approach known as behavior-based robotics. In behavior-based robotics, engineers use the natural movements of creatures such as insects, spiders, and birds to inspire new robot structures and ways of moving (see Figure 4.3). These approaches, for example, can improve a robot’s ability to right itself if knocked over or avoid getting stuck in crevasses. After some early success based on these new robotics models, Brooks was awarded NASA funding that enabled him to develop the Mars Rover.
The success of the Mars Rover encouraged Brooks to start his own private company to build robots, iRobot. In this capacity, he continued to develop robots for government applications; for example, DARPA funded work to create robots to search for and dispose of improvised explosive devices (IEDs) in Iraq and Afghanistan. The company also pursued consumer-oriented robots, including the Roomba, a robot vacuum that has sold 14 million units (and inspired countless YouTube videos of cats riding Roombas).
One story from iRobot’s early days illustrates the serendipity of innovation and just how difficult it is to predict when a research project might go from the theoretical to the practical. In the mid-1990s, the Japanese government provided iRobot some initial fund-

ing to begin developing robots to support operations in Japanese nuclear power plants. The project was later aborted after the Japanese government decided the robots would not be needed. Two decades later, when the 2011 Fukushima nuclear reactor meltdown rendered the plant too unsafe for people to enter, iRobot’s battle-hardened IED disposal robots were called upon to enter the plant and survey the damage.
Cultivating a Softer Side
Brooks highlighted the fact that research advances in humanoid robotics have also made it easier for robots to be deployed in factories among people. He explained that before recent improvements in user interfaces and robotic design, factories had to separate their human employees from the robots used in manufacturing processes. The robots, with their complicated user interfaces, awkward movements, and enormous size, were too dangerous for most people to work with. Today’s humanoid robots allow factory workers with no scientific or robotic expertise to easily and safely train and monitor their robotic partners (see Figure 4.4).
These industry robots, now ubiquitous in thousands of manufacturing facilities, can trace their lineage back to agencies like DARPA and NASA, which, despite not knowing exactly what the outcomes would be, led the way toward key robotics breakthroughs
by funding basic research in the field’s early days. Without this initial early government funding, robotic factories and self-driving cars would likely still be mere mirages on the far-off horizon.
Despite today’s remarkable technological capabilities, however, we still have a long way to go before we can use some of these technologies to their fullest potential. The adoption of driverless cars and trains, for example, will require not just better technology but also more trust and acceptance on the part of the public, Brooks explained. The 2009 crash of a self-driving Metro train in Washington, D.C., set social acceptance of autonomous vehicles back despite being a more efficient way to run subway lines. It is often the case, he said, that even when a new technology is ready for the consumer market, the consumers might not be ready for it.
Sharing their own perceptions of the field, several attendees noted that robotics research really took off once mobile robot-building platforms became inexpensive enough that every lab could afford one. Instead of a few teams working on research problems, suddenly there were dozens or hundreds of teams actively building off of each other’s innovations, and the field thrived. While government-funded research was clearly crucial for the field’s beginnings, Brooks noted, it is the ongoing synergy of research funding, academic labs, and industry products that continues to fuel innovation.














