
5
Replicability
Replication is one of the key ways scientists build confidence in the scientific merit of results. When the result from one study is found to be consistent by another study, it is more likely to represent a reliable claim to new knowledge. As Popper (2005, p. 23) wrote (using “reproducibility” in its generic sense):
We do not take even our own observations quite seriously, or accept them as scientific observations, until we have repeated and tested them. Only by such repetitions can we convince ourselves that we are not dealing with a mere isolated ‘coincidence,’ but with events which, on account of their regularity and reproducibility, are in principle inter-subjectively testable.
However, a successful replication does not guarantee that the original scientific results of a study were correct, nor does a single failed replication conclusively refute the original claims. A failure to replicate previous results can be due to any number of factors, including the discovery of an unknown effect, inherent variability in the system, inability to control complex variables, substandard research practices, and, quite simply, chance. The nature of the problem under study and the prior likelihoods of possible results in the study, the type of measurement instruments and research design selected, and the novelty of the area of study and therefore lack of established methods of inquiry can also contribute to non-replicability. Because of the complicated relationship between replicability and its variety of sources, the validity of scientific results should be considered in the context of an entire body of evidence, rather than an individual study or an individual replication. Moreover, replication may be a matter of degree, rather than a binary result of “success” or “failure.”1 We explain in Chapter 7 how research synthesis, especially meta-analysis, can be used to evaluate the evidence on a given question.
ASSESSING REPLICABILITY
How does one determine the extent to which a replication attempt has been successful? When researchers investigate the same scientific question using the same methods and similar tools, the results are not likely to be identical—unlike in computational reproducibility in which bitwise agreement between two results can be expected (see Chapter 4). We repeat our definition of replicability, with emphasis added: obtaining consistent results across studies aimed at answering the same scientific question, each of which has obtained its own data.
Determining consistency between two different results or inferences can be approached in a number of ways (Simonsohn, 2015; Verhagen and Wagenmakers, 2014). Even if one considers only quantitative criteria for determining whether two results qualify as consistent, there is variability across disciplines (Zwaan et al., 2018; Plant and Hanisch, 2018). The Royal Netherlands Academy of Arts and Sciences (2018, p. 20) concluded that “it is impossible to identify a single, universal approach to determining [replicability].” As noted in Chapter 2, different scientific disciplines are distinguished in part by the types of tools, methods, and techniques used to answer questions specific to the discipline, and these differences include how replicability is assessed.
___________________
1 See, for example, the cancer biology project in Table 5-1 in this chapter.
Acknowledging the different approaches to assessing replicability across scientific disciplines, however, we emphasize eight core characteristics and principles:
- Attempts at replication of previous results are conducted following the methods and using similar equipment and analyses as described in the original study or under sufficiently similar conditions (Cova et al., 2018).2 Yet regardless of how similar the replication study is, no second event can exactly repeat a previous event.
- The concept of replication between two results is inseparable from uncertainty, as is also the case for reproducibility (as discussed in Chapter 4).
- Any determination of replication (between two results) needs to take account of both proximity (i.e., the closeness of one result to the other, such as the closeness of the mean values) and uncertainty (i.e., variability in the measures of the results).
- To assess replicability, one must first specify exactly what attribute of a previous result is of interest. For example, is only the direction of a possible effect of interest? Is the magnitude of effect of interest? Is surpassing a specified threshold of magnitude of interest? With the attribute of interest specified, one can then ask whether two results fall within or outside the bounds of “proximity-uncertainty” that would qualify as replicated results.
- Depending on the selected criteria (e.g., measure, attribute), assessments of a set of attempted replications could appear quite divergent.3
- A judgment that “Result A is replicated by Result B” must be identical to the judgment that “Result B is replicated by Result A.” There must be a symmetry in the judgment of replication; otherwise, internal contradictions are inevitable.
- There could be advantages to inverting the question from, “Does Result A replicate Result B (given their proximity and uncertainty)?”
___________________
2Cova et al. (2018, fn. 3) discuss the challenge of defining sufficiently similar as well as the interpretation of the results:
In practice, it can be hard to determine whether the ‘sufficiently similar’ criterion has actually been fulfilled by the replication attempt, whether in its methods or in its results (Nakagawa and Parker 2015). It can therefore be challenging to interpret the results of replication studies, no matter which way these results turn out (Collins, 1975; Earp and Trafimow, 2015; Maxwell et al., 2015).
3 See Table 5-1, for an example of this in the reviews of a psychology replication study by Open Science Collaboration (2015) and Patil et al. (2016).
- While a number of different standards for replicability/non-replicability may be justifiable, depending on the attributes of interest, a standard of “repeated statistical significance” has many limitations because the level of statistical significance is an arbitrary threshold (Amrhein et al., 2019a; Boos and Stefanski, 2011; Goodman, 1992; Lazzeroni et al., 2016). For example, one study may yield a p-value of 0.049 (declared significant at the p ≤ 0.05 level) and a second study yields a p-value of 0.051 (declared nonsignificant by the same p-value threshold) and therefore the studies are said not to be replicated. However, if the second study had yielded a p-value of 0.03, the reviewer would say it had successfully replicated the first study, even though the result could diverge more sharply (by proximity and uncertainty) from the original study than in the first comparison. Rather than focus on an arbitrary threshold such as statistical significance, it would be more revealing to consider the distributions of observations and to examine how similar these distributions are. This examination would include summary measures, such as proportions, means, standard deviations (or uncertainties), and additional metrics tailored to the subject matter.
to “Are Results A and B sufficiently divergent (given their proximity and uncertainty) so as to qualify as a non-replication?” It may be advantageous, in assessing degrees of replicability, to define a relatively high threshold of similarity that qualifies as “replication,” a relatively low threshold of similarity that qualifies as “non-replication,” and the intermediate zone between the two thresholds that is considered “indeterminate.” If a second study has low power and wide uncertainties, it may be unable to produce any but indeterminate results.
The final point above is reinforced by a recent special edition of the American Statistician in which the use of a statistical significance threshold in reporting is strongly discouraged due to overuse and wide misinterpretation (Wasserstein et al., 2019). A figure from (Amrhein et al., 2019b) also demonstrates this point, as shown in Figure 5-1.
One concern voiced by some researchers about using a proximity-uncertainty attribute to assess replicability is that such an assessment favors studies with large uncertainties; the potential consequence is that many researchers would choose to perform low-power studies to increase the replicability chances (Cova et al., 2018). While two results with large uncertainties and within proximity, such that the uncertainties overlap with each other, may be consistent with replication, the large uncertainties indicate that not much confidence can be placed in that conclusion.
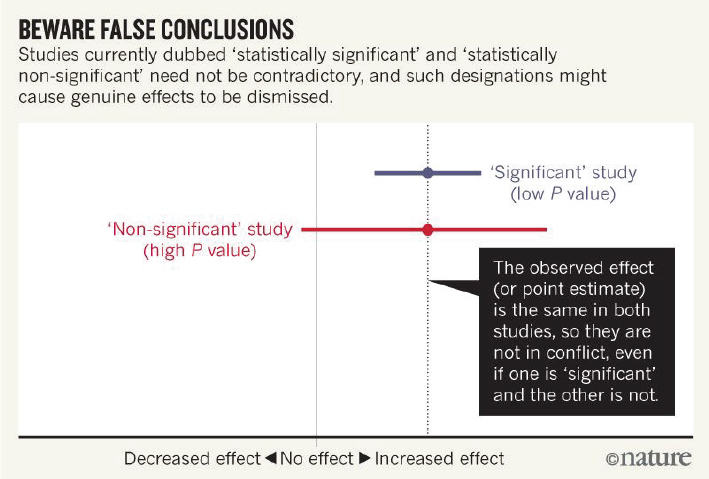
NOTES: The figure shows the issue with using statistical significance as an attribute of comparison (Point 8 on 74 of the main text); the two results would be considered to have replicated if using a proximity-uncertainty attribute (Points 3 and 4 on 73 of the main text).
SOURCE: Amrhein et al. (2019b, p. 306).
CONCLUSION 5-1: Different types of scientific studies lead to different or multiple criteria for determining a successful replication. The choice of criteria can affect the apparent rate of non-replication, and that choice calls for judgment and explanation.
CONCLUSION 5-2: A number of parametric and nonparametric methods may be suitable for assessing replication across studies. However, a restrictive and unreliable approach would accept replication only when the results in both studies have attained “statistical significance,” that is, when the p-values in both studies have exceeded a selected threshold. Rather, in determining replication, it is important to consider the distributions of observations and to examine how similar these distributions are. This examination would include summary measures, such as proportions, means, standard deviations (uncertainties), and additional metrics tailored to the subject matter.
THE EXTENT OF NON-REPLICABILITY
The committee was asked to assess what is known and, if necessary, identify areas that may need more information to ascertain the extent
of non-replicability in scientific and engineering research. The committee examined current efforts to assess the extent of non-replicability within several fields, reviewed literature on the topic, and heard from expert panels during its public meetings. We also drew on the previous work of committee members and other experts in the field of replicability of research.
Some efforts to assess the extent of non-replicability in scientific research directly measure rates of replication, while others examine indirect measures to infer the extent of non-replication. Approaches to assessing non-replicability rates include
- direct and indirect assessments of replicability;
- perspectives of researchers who have studied replicability;
- surveys of researchers; and
- retraction trends.
This section discusses each of these lines of evidence.
Assessments of Replicability
The most direct method to assess replicability is to perform a study following the original methods of a previous study and to compare the new results to the original ones. Some high-profile replication efforts in recent years include studies by Amgen, which showed low replication rates in biomedical research (Begley and Ellis, 2012), and work by the Center for Open Science on psychology (Open Science Collaboration, 2015), cancer research (Nosek and Errington, 2017), and social science (Camerer et al., 2018). In these examples, a set of studies was selected and a single replication attempt was made to confirm results of each previous study, or one-to-one comparisons were made. In other replication studies, teams of researchers performed multiple replication attempts on a single original result, or many-to-one comparisons (see e.g., Klein et al., 2014; Hagger et al., 2016; and Cova et al., 2018 in Table 5-1).
Other measures of replicability include assessments that can provide indicators of bias, errors, and outliers, including, for example, computational data checks of reported numbers and comparison of reported values against a database of previously reported values. Such assessments can identify data that are outliers to previous measurements and may signal the need for additional investigation to understand the discrepancy.4Table 5-1 summarizes the direct and indirect replication studies assembled by the committee. Other sources of non-replicabilty are discussed later in this chapter in the Sources of Non-Replicability section.
___________________
4 There is risk of missing a new discovery by rejecting data outliers without further investigation.
Many direct replication studies are not reported as such. Replication—especially of surprising results or those that could have a major impact—occurs in science often without being labelled as a replication. Many scientific fields conduct reviews of articles on a specific topic—especially on new topics or topics likely to have a major impact—to assess the available data and determine which measurements and results are rigorous (see Chapter 7). Therefore, replicability studies included as part of the scientific literature but not cited as such add to the difficulty in assessing the extent of replication and non-replication.
One example of this phenomenon relates to research on hydrogen storage capacity. The U.S. Department of Energy (DOE) issued a target storage capacity in the mid-1990s. One group using carbon nanotubes reported surprisingly high values that met DOE’s target (Hynek et al., 1997); other researchers who attempted to replicate these results could not do so. At the same time, other researchers were also reporting high values of hydrogen capacity in other experiments. In 2003, an article reviewed previous studies of hydrogen storage values and reported new research results, which were later replicated (Broom and Hirscher, 2016). None of these studies was explicitly called an attempt at replication.
Based on the content of the collected studies in Table 5-1, one can observe that the
- majority of the studies are in the social and behavioral sciences (including economics) or in biomedical fields, and
- methods of assessing replicability are inconsistent and the replicability percentages depend strongly on the methods used.
The replication studies such as those shown in Table 5-1 are not necessarily indicative of the actual rate of non-replicability across science for a number of reasons: the studies to be replicated were not randomly chosen, the replications had methodological shortcomings, many replication studies are not reported as such, and the reported replication studies found widely varying rates of non-replication (Gilbert et al., 2016). At the same time, replication studies often provide more and better-quality evidence than most original studies alone, and they highlight such methodological features as high precision or statistical power, preregistration, and multi-site collaboration (Nosek, 2016). Some would argue that focusing on replication of a single study as a way to improve the efficiency of science is ill-placed. Rather, reviews of cumulative evidence on a subject, to gauge both the overall effect size and generalizability, may be more useful (Goodman, 2018; and see Chapter 7).
Apart from specific efforts to replicate others’ studies, investigators will typically confirm their own results, as in a laboratory experiment, prior to
TABLE 5-1 Examples of Replication Studies
| Field and Author(s) | Description | Results | Type of Assessment |
|---|---|---|---|
| Experimental Philosophy (Cova et al., 2018) | A group of 20 research teams performed replication studies of 40 experimental philosophy studies published between 2003 and 2015 | 70% of the 40 studies were replicated by comparing the original effect size to the confidence interval (CI) of the replication.a | Direct |
| Behavioral Science, Personality Traits Linked to Life Outcomes (Soto, 2019) | Performed replications of 78 previously published associations between the Big Five personality traits and consequential life outcomesb | 87% of the replication attempts were statistically significant in the expected direction, and effects were typically 77% as strong as the corresponding original effects. | Direct |
| Behavioral Science, Ego-Depletion Effect (Hagger et al., 2016) | Multiple laboratories (23 in total) conducted replications of a standardized ego-depletion protocol based on a sequential-task paradigm by Sripada et al. (2014) | Meta-analysis of the studies revealed that the size of the ego-depletion effect was small with 95% CI that encompassed zero (d = 0.04, 95% CI [−0.07, 0.15]). | |
| General Biology, Preclinical Animal Studies (Prinz et al., 2011) | Attempt by researchers from Bayer HealthCare to validate data on potential drug targets obtained in 67 projects by copying models exactly or by adapting them to internal needs | Published data were completely in line with the results of the validation studies in 20%-25% of cases. | Direct |
| Oncology, Preclinical Studies (Begley and Ellis, 2012) | Attempt by Amgen team to reproduce the results of 53 “landmark” studies | Scientific results were confirmed in 11% of the studies. | Direct |
| Genetics, Preclinical Studies (Ioannidis, 2009) | Replication of data analyses provided in 18 articles on microarray-based gene expression studies | Of the 18 studies, 2 analyses (11%) were replicated; 6 were partially replicated or showed some discrepancies in results; and 10 could not be replicated. | Direct |
| Experimental Psychology (Klein et al., 2014) | Replication of 13 psychological phenomena across 36 independent samples | 77% of phenomena were replicated consistently. | Direct |
| Field and Author(s) | Description | Results | Type of Assessment |
|---|---|---|---|
| Experimental Psychology, Many Labs 2 (Klein et al., 2018) | Replication of 28 classic and contemporary published studies | 54% of replications produced a statistically significant effect in the same direction as the original study, 75% yielded effect sizes smaller than the original ones, and 25% yielded larger effect sizes than the original ones. | Direct |
| Experimental Psychology (Open Science Collaboration, 2015) | Attempt to independently replicate selected results from 100 studies in psychology | 36% of the replication studies produced significant results, compared to 97% of the original studies. The mean effect sizes were halved. | Direct |
| Experimental Psychology (Patil et al., 2016) | Using reported data from the Open Science Collaboration (2015) replication study in psychology, reanalyzed the results | 77% of the studies replicated by comparing the original effect size to an estimated 95% CI of the replication. | Direct |
| Experimental Psychology (Camerer et al., 2018) | Attempt to replicate 21 systematically selected experimental studies in the social sciences published in Nature and Science in 2010-2015 | Found a significant effect in the same direction as the original study for 62% (13 of 21) studies, and the effect size of the replications was on average about 50% of the original effect size. | Direct |
| Empirical Economics (Dewald et al., 1986) | 2-year study that collected programs and data from authors and attempted to replicate their published results on empirical economic research | Two of nine replications were successful, three “near” successful, and four unsuccessful; findings suggest that inadvertent errors in published empirical articles are a commonplace rather than a rare occurrence. | Direct |
| Economics (Duvendack et al., 2015) | Progress report on the number of journals with data sharing requirements and an assessment of 167 studies | 10 journals explicitly note they publish replications; of 167 published replication studies, approximately 66% were unable to confirm the original results; 12% disconfirmed at least one major result of the original study, while confirming others. | N/A |
| Field and Author(s) | Description | Results | Type of Assessment |
|---|---|---|---|
| Economics (Camerer et al., 2016) | An effort to replicate 18 studies published in the American Economic Review and the Quarterly Journal of Economics from 2011-2014 | Significant effect in the same direction as the original study found for 11 replications (61%); on average, the replicated effect size was 66% of the original. | Direct |
| Chemistry (Park et al., 2017; Sholl, 2017) | Collaboration with National Institute of Standards and Technology (NIST) to check new data against NIST database, 13,000 measurements | 27% of papers reporting properties of adsorption had data that were outliers; 20% of papers reporting carbon dioxide isotherms as outliers. | Indirect |
| Chemistry (Plant, 2018) | Collaboration with NIST, Thermodynamics Research Center (TRC) databases, prepublication check of solubility, viscosity, critical temperature, and vapor pressure | 33% experiments had data problems, such as uncertainties too small, reported values outside of TRC database distributions. | Indirect |
| Biology Reproducibility Project: Cancer Biology | Large-scale replication project to replicate key results in 29 cancer papers published in Nature, Science, Cell, and other high-impact journals | The first five articles have been published; two replicated important parts of the original papers, one did not replicate, and two were uninterpretable. | Direct |
| Psychology, Statistical Checks (Nuijten et al., 2016) | Statcheck tool used to test statistical values within psychology articles from 1985-2013 | 49.6% of the articles with null hypothesis statistical test (NHST) results contained at least one inconsistency (8,273 of the 16,695 articles), and 12.9% (2,150) of the articles with NHST results contained at least one gross inconsistency. | Indirect |
| Engineering, Computational Fluid Dynamics (Mesnard and Barba, 2017) | Full replication studies of previously published results on bluff-body aerodynamics, using four different computational methods | Replication of the main result was achieved in three out of four of the computational efforts. | Direct |
| Field and Author(s) | Description | Results | Type of Assessment |
|---|---|---|---|
| Psychology, Many Labs 3 (Ebersole et al., 2016a) | Attempt to replicate 10 psychology studies in one online session | 3 of 10 studies replicated at p < 0.05. | Direct |
| Psychology (Luttrell et al., 2017) | Argued that one of the failed replications in Ebersole et al. was due to changes in the procedure. They randomly assigned participants to a version closer to the original or to Ebersole et al.’s version. | The original study replicated when the original procedures were followed more closely, but not when the Ebersole et al. procedures were used. | Direct |
| Psychology (Wagenmakers et al., 2016) | 17 different labs attempted to replicate one study on facial feedback by Strack et al. (1988). | None of the studies replicated the result at p < 0.05. | Direct |
| Psychology (Noah et al., 2018) | Pointed out that all of the studies in the Wagenmakers et al. (2016) replication project changed the procedure by videotaping participants. Conducted a replication in which participants were randomly assigned to be videotaped or not. | The original study was replicated when the original procedure was followed (p = 0.01); the original study was not replicated when the video camera was present (p = 0.85). | Direct |
| Psychology (Alogna et al., 2014) | 31 labs attempted to replicate a study by Schooler and Engstler-Schooler (1990). | Replicated the original study. The effect size was much larger when the original study was replicated more faithfully (the first set of replications inadvertently introduced a change in the procedure). | Direct |
NOTES: Some of the studies in this table also appear in Table 4-1 as they evaluated both reproducibility and replicability. N/A = not applicable.
aFrom Cova et al. (2018, p. 14): “For studies reporting statistically significant results, we treated as successful replications for which the replication 95 percent CI [confidence interval] was not lower than the original effect size. For studies reporting null results, we treated as successful replications for which original effect sizes fell inside the bounds of the 95 percent CI.”
bFrom Soto (2019, p. 7, fn. 1): “Previous large-scale replication projects have typically treated the individual study as the primary unit of analysis. Because personality-outcome studies often examine multiple trait-outcome associations, we selected the individual association as the most appropriate unit of analysis for estimating replicability in this literature.”
publication. More generally, independent investigators may replicate prior results of others before conducting, or in the course of conducting, a study to extend the original work. These types of replications are not usually published as separate replication studies.
Perspectives of Researchers Who Have Studied Replicability
Several experts who have studied replicability within and across fields of science and engineering provided their perspectives to the committee. Brian Nosek, cofounder and director of the Center for Open Science, said there was “not enough information to provide an estimate with any certainty across fields and even within individual fields.” In a recent paper discussing scientific progress and problems, Richard Shiffrin, professor of psychology and brain sciences at Indiana University, and colleagues argued that there are “no feasible methods to produce a quantitative metric, either across science or within the field” to measure the progress of science (Shiffrin et al., 2018, p. 2632). Skip Lupia, now serving as head of the Directorate for Social, Behavioral, and Economic Sciences at the National Science Foundation, said that there is not sufficient information to be able to definitively answer the extent of non-reproducibility and non-replicability, but there is evidence of p-hacking and publication bias (see below), which are problems. Steven Goodman, the codirector of the Meta-Research Innovation Center at Stanford University (METRICS), suggested that the focus ought not be on the rate of non-replication of individual studies, but rather on cumulative evidence provided by all studies and convergence to the truth. He suggested the proper question is “How efficient is the scientific enterprise in generating reliable knowledge, what affects that reliability, and how can we improve it?”
Surveys
Surveys of scientists about issues of replicability or on scientific methods are indirect measures of non-replicability. For example, Nature published the results of a survey in 2016 in an article titled “1,500 Scientists Lift the Lid on Reproducibility (Baker, 2016)”5; this article reported that a large percentage of researchers who responded to an online survey believe that replicability is a problem. This article has been widely cited by researchers studying subjects ranging from cardiovascular disease to crystal structures (Warner et al., 2018; Ziletti et al., 2018). Surveys and studies have also assessed the prevalence of specific problematic research practices, such as a 2018 survey about questionable research practices in ecology and evolution
___________________
5Nature uses the word “reproducibility” to refer to what we call “replicability.”
(Fraser et al., 2018). However, many of these surveys rely on poorly defined sampling frames to identify populations of scientists and do not use probability sampling techniques. The fact that nonprobability samples “rely mostly on people . . . whose selection probabilities are unknown [makes it] difficult to estimate how representative they are of the [target] population” (Dillman, Smyth, and Christian, 2014, pp. 70, 92). In fact, we know that people with a particular interest in or concern about a topic, such as replicability and reproducibility, are more likely to respond to surveys on the topic (Brehm, 1993). As a result, we caution against using surveys based on nonprobability samples as the basis of any conclusion about the extent of non-replicability in science.
High-quality researcher surveys are expensive and pose significant challenges, including constructing exhaustive sampling frames, reaching adequate response rates, and minimizing other nonresponse biases that might differentially affect respondents at different career stages or in different professional environments or fields of study (Corley et al., 2011; Peters et al., 2008; Scheufele et al., 2009). As a result, the attempts to date to gather input on topics related to replicability and reproducibility from larger numbers of scientists (Baker, 2016; Boulbes et al., 2018) have relied on convenience samples and other methodological choices that limit the conclusions that can be made about attitudes among the larger scientific community or even for specific subfields based on the data from such surveys. More methodologically sound surveys following guidelines on adoption of open science practices and other replicability-related issues are beginning to emerge.6 See Appendix E for a discussion of conducting reliable surveys of scientists.
Retraction Trends
Retractions of published articles may be related to their non-replicability. As noted in a recent study on retraction trends (Brainard, 2018, p. 392), “Overall, nearly 40% of retraction notices did not mention fraud or other kinds of misconduct. Instead, the papers were retracted because of errors, problems with reproducibility [or replicability], and other issues.” Overall, about one-half of all retractions appear to involve fabrication, falsification, or plagiarism. Journal article retractions in biomedicine increased from 50-60 per year in the mid-2000s, to 600-700 per year by the mid-2010s (National Library of Medicine, 2018), and this increase attracted much commentary and analysis (see, e.g., Grieneisen and Zhang, 2012). A recent comprehensive review of an extensive database of 18,000 retracted papers
___________________
6 See https://cega.berkeley.edu/resource/the-state-of-social-science-betsy-levy-paluck-bitssannual-meeting-2018.
dating back to the 1970s found that while the number of retractions has grown, the rate of increase has slowed; approximately 4 of every 10,000 papers are now retracted (Brainard, 2018). Overall, the number of journals that report retractions has grown from 44 journals in 1997 to 488 journals in 2016; however, the average number of retractions per journal has remained essentially flat since 1997.
These data suggest that more journals are attending to the problem of articles that need to be retracted rather than a growing problem in any one discipline of science. Fewer than 2 percent of authors in the database account for more than one-quarter of the retracted articles, and the retractions of these frequent offenders are usually based on fraud rather than errors that lead to non-replicability. The Institute of Electrical and Electronics Engineers alone has retracted more than 7,000 abstracts from conferences that took place between 2009 and 2011, most of which had authors based in China (McCook, 2018).
The body of evidence on the extent of non-replicabilty gathered by the committee is not a comprehensive assessment across all fields of science nor even within any given field of study. Such a comprehensive effort would be daunting due to the vast amount of research published each year and the diversity of scientific and engineering fields. Among studies of replication that are available, there is no uniform approach across scientific fields to gauge replication between two studies. The experts who contributed their perspectives to the committee all question the feasibility of such a science-wide assessment of non-replicability.
While the evidence base assessed by the committee may not be sufficient to permit a firm quantitative answer on the scope of non-replicability, it does support several findings and a conclusion.
FINDING 5-1: There is an uneven level of awareness of issues related to replicability across fields and even within fields of science and engineering.
FINDING 5-2: Efforts to replicate studies aimed at discerning the effect of an intervention in a study population may find a similar direction of effect, but a different (often smaller) size of effect.
FINDING 5-3: Studies that directly measure replicability take substantial time and resources.
FINDING 5-4: Comparing results across replication studies may be compromised because different replication studies may test different study attributes and rely on different standards and measures for a successful replication.
FINDING 5-5: Replication studies in the natural and clinical sciences (general biology, genetics, oncology, chemistry) and social sciences (including economics and psychology) report frequencies of replication ranging from fewer than one out of five studies to more than three out of four studies.
CONCLUSION 5-3: Because many scientists routinely conduct replication tests as part of a follow-on work and do not report replication results separately, the evidence base of non-replicability across all science and engineering research is incomplete.
SOURCES OF NON-REPLICABILITY
Non-replicability can arise from a number of sources. In some cases, non-replicability arises from the inherent characteristics of the systems under study. In others, decisions made by a researcher or researchers in study execution that reasonably differ from the original study such as judgment calls on data cleaning or selection of parameter values within a model may also result in non-replication. Other sources of non-replicability arise from conscious or unconscious bias in reporting, mistakes and errors (including misuse of statistical methods), and problems in study design, execution, or interpretation in either the original study or the replication attempt. In many instances, non-replication between two results could be due to a combination of multiple sources, but it is not generally possible to identify the source without careful examination of the two studies. Below, we review these sources of non-replicability and discuss how researchers’ choices can affect each. Unless otherwise noted, the discussion below focuses on the non-replicability between two results (i.e., a one-to-one comparison) when assessed using proximity and uncertainty of both results.
Non-Replicability That Is Potentially Helpful to Science
Non-replicability is a normal part of the scientific process and can be due to the intrinsic variation and complexity of nature, the scope of current scientific knowledge, and the limits of current technologies. Highly surprising and unexpected results are often not replicated by other researchers. In other instances, a second researcher or research team may purposefully make decisions that lead to differences in parts of the study. As long as these differences are reported with the final results, these may be reasonable actions to take yet result in non-replication. In scientific reporting, uncertainties within the study (such as the uncertainty within measurements, the potential interactions between parameters, and the variability of the
system under study) are estimated, assessed, characterized, and accounted for through uncertainty and probability analysis. When uncertainties are unknown and not accounted for, this can also lead to non-replicability. In these instances, non-replicability of results is a normal consequence of studying complex systems with imperfect knowledge and tools. When non-replication of results due to sources such as those listed above are investigated and resolved, it can lead to new insights, better uncertainty characterization, and increased knowledge about the systems under study and the methods used to study them. See Box 5-1 for examples of how investigations of non-replication have been helpful to increasing knowledge.
The susceptibility of any line of scientific inquiry to sources of non-replicability depends on many factors, including factors inherent to the system under study, such as the
- complexity of the system under study;
- understanding of the number and relations among variables within the system under study;
- ability to control the variables;
- levels of noise within the system (or signal to noise ratios);
- mismatch of scale of the phenomena and the scale at which it can be measured;
- stability across time and space of the underlying principles;
- fidelity of the available measures to the underlying system under study (e.g., direct or indirect measurements); and
- prior probability (pre-experimental plausibility) of the scientific hypothesis.
Studies that pursue lines of inquiry that are able to better estimate and analyze the uncertainties associated with the variables in the system and control the methods that will be used to conduct the experiment are more replicable. On the other end of the spectrum, studies that are more prone to non-replication often involve indirect measurement of very complex systems (e.g., human behavior) and require statistical analysis to draw conclusions. To illustrate how these characteristics can lead to results that are more or less likely to replicate, consider the attributes of complexity and controllability. The complexity and controllability of a system contribute to the underlying variance of the distribution of expected results and thus the likelihood of non-replication.7
___________________
7 Complexity and controllability in an experimental system affect its susceptibility to non-replicability independently from the way prior odds, power, or p-values associated with hypothesis testing affect the likelihood that an experimental result represents the true state of the world.
The systems that scientists study vary in their complexity. Although all systems have some degree of intrinsic or random variability, some systems are less well understood, and their intrinsic variability is more difficult to assess or estimate. Complex systems tend to have numerous interacting components (e.g., cell biology, disease outbreaks, friction coefficient between two unknown surfaces, urban environments, complex organizations and populations, and human health). Interrelations and interactions among multiple components cannot always be predicted and neither can the resulting effects on the experimental outcomes, so an initial estimate of uncertainty may be an educated guess.
Systems under study also vary in their controllability. If the variables within a system can be known, characterized, and controlled, research on such a system tends to produce more replicable results. For example, in social sciences, a person’s response to a stimulus (e.g., a person’s behavior when placed in a specific situation) depends on a large number of variables—including social context, biological and psychological traits, verbal and nonverbal cues from researchers—all of which are difficult or impossible to control completely. In contrast, a physical object’s response to a physical stimulus (e.g., a liquid’s response to a rise in temperature) depends almost entirely on variables that can either be controlled or adjusted for, such as temperature, air pressure, and elevation. Because of these differences, one expects that studies that are conducted in the relatively more controllable systems will replicate with greater frequency than those that are in less controllable systems. Scientists seek to control the variables relevant to the system under study and the nature of the inquiry, but when these variables are more difficult to control, the likelihood of non-replicability will be higher. Figure 5-2 illustrates the combinations of complexity and controllability.
Many scientific fields have studies that span these quadrants, as demonstrated by the following examples from engineering, physics, and psychology. Veronique Kiermer, PLOS executive editor, in her briefing to the committee noted: “There is a clear correlation between the complexity of the design, the complexity of measurement tools, and the signal to noise ratio that we are trying to measure.” (See also Goodman et al., 2016, on the complexity of statistical and inferential methods.)
Engineering. Aluminum-lithium alloys were developed by engineers because of their strength-to-weight ratio, primarily for use in aerospace engineering. The process of developing these alloys spans the four quadrants. Early generation of binary alloys was a simple system that showed high replicability (Quadrant A). Second-generation alloys had higher amounts of lithium and resulted in lower replicability that appeared as failures in manufacturing operations because the interactions of the elements were not understood (Quadrant C). The third-generation alloys contained less
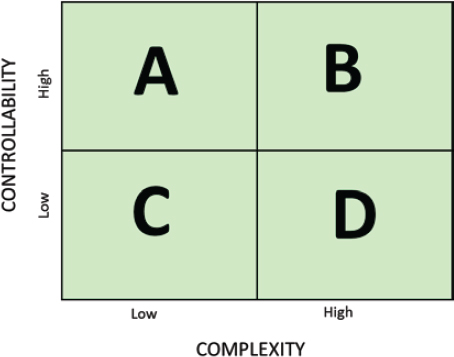
NOTE: See text for examples from the fields of engineering, physics, and psychology that illustrate various combinations of complexity and controllability that affect susceptibility to non-replication.
lithium and higher relative amounts of other alloying elements, which made it a more complex system but better controlled (Quadrant B), with improved replicability. The development of any alloy is subject to a highly controlled environment. Unknown aspects of the system, such as interactions among the components, cannot be controlled initially and can lead to failures. Once these are understood, conditions can be modified (e.g., heat treatment) to bring about higher replicability.
Physics. In physics, measurements of the electronic band gap of semiconducting and conducting materials using scanning tunneling microscopy is a highly controlled, simple system (Quadrant A). The searches for the Higgs boson and gravitational waves were separate efforts, and each required the development of large, complex experimental apparatus and careful characterization of the measurement and data analysis systems (Quadrant B). Some systems, such as radiation portal monitors, require setting thresholds for alarms without knowledge of when or if a threat will ever pass through them; the variety of potential signatures is high and there is little controllability of the system during operation (Quadrant C). Finally, a simple system with little controllability is that of precisely predicting the path of a feather dropped from a given height (Quadrant D).
Psychology. In psychology, Quadrant A includes studies of basic sensory and perceptual processes that are common to all human beings, such
as the purkinje shift (i.e., a change in sensitivity of the human eye under different levels of illumination). Quadrant D includes studies of complex social behaviors that are influenced by culture and context; for example, a study of the effects of a father’s absence on children’s ability to delay gratification revealed stronger effects among younger children (Mischel, 1961).
Inherent sources of non-replicability arise in every field of science, but they can vary widely depending on the specific system undergoing study. When the sources are knowable, or arise from experimental design choices, researchers need to identify and assess these sources of uncertainty insofar as they can be estimated. Researchers need also to report on steps that were intended to reduce uncertainties inherent in the study or differ from the original study (i.e., data cleaning decisions that resulted in a different final dataset). The committee agrees with those who argue that the testing of assumptions and the characterization of the components of a study are as important to report as are the ultimate results of the study (Plant and Hanisch, 2018) including studies using statistical inference and reporting p-values (Boos and Stefanski, 2011). Every scientific inquiry encounters an irreducible level of uncertainty, whether this is due to random processes in the system under study, limits to researchers understanding or ability to control that system, or limitations of the ability to measure. If researchers do not adequately consider and report these uncertainties and limitations, this can contribute to non-replicability.
RECOMMENDATION 5-1: Researchers should, as applicable to the specific study, provide an accurate and appropriate characterization of relevant uncertainties when they report or publish their research. Researchers should thoughtfully communicate all recognized uncertainties and estimate or acknowledge other potential sources of uncertainty that bear on their results, including stochastic uncertainties and uncertainties in measurement, computation, knowledge, modeling, and methods of analysis.
Unhelpful Sources of Non-Replicability
Non-replicability can also be the result of human error or poor researcher choices. Shortcomings in the design, conduct, and communication of a study may all contribute to non-replicability.
These defects may arise at any point along the process of conducting research, from design and conduct to analysis and reporting, and errors may be made because the researcher was ignorant of best practices, was sloppy in carrying out research, made a simple error, or had unconscious bias toward a specific outcome. Whether arising from lack of knowledge, perverse incentives, sloppiness, or bias, these sources of non-replicability
warrant continued attention because they reduce the efficiency with which science progresses and time spent resolving non-replicablity issues that are caused by these sources do not add to scientific understanding. That is, they are unhelpful in making scientific progress. We consider here a selected set of such avoidable sources of non-replication:
- publication bias
- misaligned incentives
- inappropriate statistical inference
- poor study design
- errors
- incomplete reporting of a study
We will discuss each source in turn.
Publication Bias
Both researchers and journals want to publish new, innovative, ground-breaking research. The publication preference for statistically significant, positive results produces a biased literature through the exclusion of statistically nonsignificant results (i.e., those that do not show an effect that is sufficiently unlikely if the null hypothesis is true). As noted in Chapter 2, there is great pressure to publish in high-impact journals and for researchers to make new discoveries. Furthermore, it may be difficult for researchers to publish even robust nonsignificant results, except in circumstances where the results contradict what has come to be an accepted positive effect. Replication studies and studies with valuable data but inconclusive results may be similarly difficult to publish. This publication bias results in a published literature that does not reflect the full range of evidence about a research topic.
One powerful example is a set of clinical studies performed on the effectiveness of tamoxifen, a drug used to treat breast cancer. In a systematic review (see Chapter 7) of the drug’s effectiveness, 23 clinical trials were reviewed; the statistical significance of 22 of the 23 studies did not reach the criterion of p < 0.05, yet the cumulative review of the set of studies showed a large effect (a reduction of 16% [±3] in the odds of death among women of all ages assigned to tamoxifen treatment [Peto et al., 1988, p. 1684]).
Another approach to quantifying the extent of non-replicability is to model the false discovery rate—that is, the number of research results that are expected to be “false.” Ioannidis (2005) developed a simulation model to do so for studies that rely on statistical hypothesis testing, incorporating the pre-study (i.e., prior) odds, the statistical tests of significance, investigator bias, and other factors. Ioannidis concluded, and used as the title of his paper,
that “most published research findings are false.” Some researchers have criticized Ioannidis’s assumptions and mathematical argument (Goodman and Greenland, 2007); others have pointed out that the takeaway message is that any initial results that are statistically significant need further confirmation and validation.
Analyzing the distribution of published results for a particular line of inquiry can offer insights into potential bias, which can relate to the rate of non-replicability. Several tools are being developed to compare a distribution of results to what that distribution would look like if all claimed effects were representative of the true distribution of effects. Figure 5-3 shows how publication bias can result in a skewed view of the body of evidence when only positive results that meet the statistical significance threshold are reported. When a new study fails to replicate the previously published results—for example, if a study finds no relationship between variables when such a relationship had been shown in previously published studies—it appears to be a case of non-replication. However, if the published literature is not an accurate reflection of the state of the evidence because only positive results are regularly published, the new study could actually have replicated previous but unpublished negative results.8
Several techniques are available to detect and potentially adjust for publication bias, all of which are based on the examination of a body of research as a whole (i.e., cumulative evidence), rather than individual replication studies (i.e., one-on-one comparison between studies). These techniques cannot determine which of the individual studies are affected by bias (i.e., which results are false positives) or identify the particular type of bias, but they arguably allow one to identify bodies of literature that are likely to be more or less accurate representations of the evidence. The techniques, discussed below, are funnel plots, a p-curve test of excess significance, and assessing unpublished literature.
Funnel Plots. One of the most common approaches to detecting publication bias involves constructing a funnel plot that displays each effect size against its precision (e.g., sample size of study). Asymmetry in the plotted values can reveal the absence of studies with small effect sizes, especially in studies with small sample sizes—a pattern that could suggest publication/selection bias for statistically significant effects (see Figure 5-3). There are criticisms of funnel plots, however; some argue that the shape of a funnel plot is largely determined by the choice of method (Tang and Liu, 2000),
___________________
8 Earlier in this chapter, we discuss an indirect method for assessing non-replicability in which a result is compared to previously published values; results that do not agreed with the published literature are identified as outliers. If the published literature is biased, this method would inappropriately reject valid results. This is another reason for investigating outliers before rejecting them.
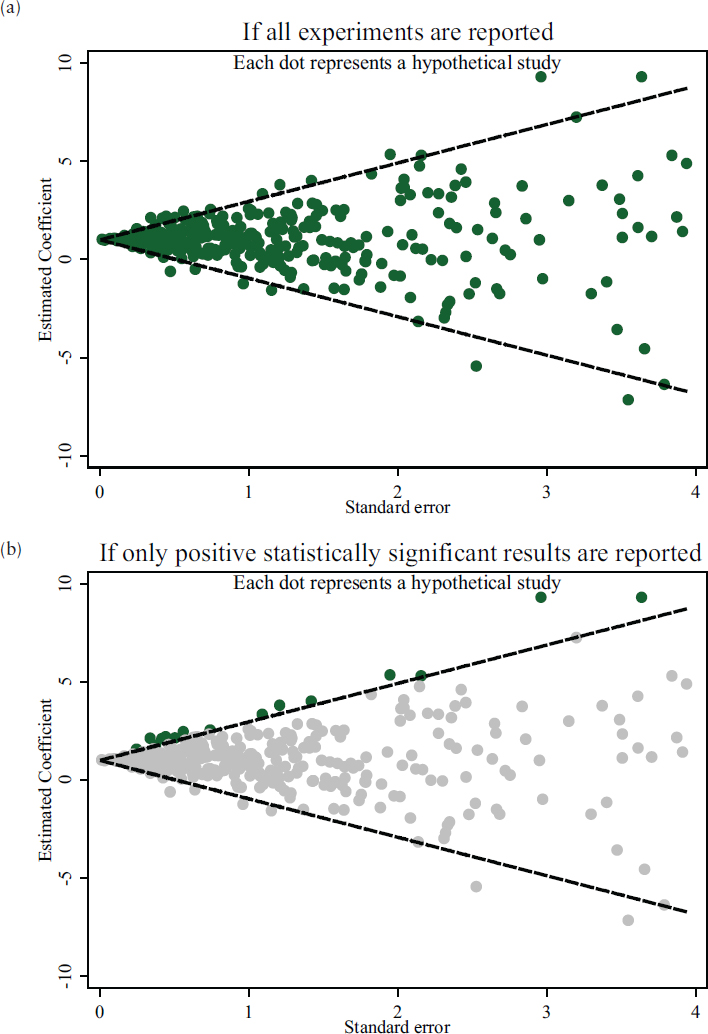
SOURCE: National Academies of Sciences, Engineering, and Medicine (2016c, p. 29).
and others maintain that funnel plot asymmetry may not accurately reflect publication bias (Lau et al., 2006).
P-Curve. One fairly new approach is to compare the distribution of results (e.g., p-values) to the expected distributions (see Simonsohn et al., 2014a, 2014b). P-curve analysis tests whether the distribution of statistically significant p-values shows a pronounced right-skew,9 as would be expected when the results are true effects (i.e., the null hypothesis is false), or whether the distribution is not as right-skewed (or is even flat, or, in the most extreme cases, left-skewed), as would be expected when the original results do not reflect the proportion of real effects (Gadbury and Allison, 2012; Nelson et al., 2018; Simonsohn et al., 2014a).
Test of Excess Significance. A closely related statistical idea for checking publication bias is the test of excess significance. This test evaluates whether the number of statistically significant results in a set of studies is improbably high given the size of the effect and the power to test it in the set of studies (Ioannidis and Trikalinos, 2007), which would imply that the set of results is biased and may include exaggerated results or false positives. When there is a true effect, one expects the proportion of statistically significant results to be equal to the statistical power of the studies. If a researcher designs her studies to have 80 percent power against a given effect, then, at most, 80 percent of her studies would produce statistically significant results if the effect is at least that large (fewer if the null hypothesis is sometimes true). Schimmack (2012) has demonstrated that the proportion of statistically significant results across a set of psychology studies often far exceeds the estimated statistical power of those studies; this pattern of results that is “too good to be true” suggests that results were either not obtained following the rules of statistical inference (i.e., conducting a single statistical test that was chosen a priori) or did not report all studies attempted (i.e., there is a “file drawer” of statistically nonsignificant studies that do not get published; or possibly the results were p-hacked or cherry picked (see Chapter 2).
In many fields, the proportion of published papers that report a positive (i.e., statistically significant) result is around 90 percent (Fanelli, 2012). This raises concerns when combined with the observation that most studies have far less than 90 percent statistical power (i.e., would only successfully detect an effect, assuming an effect exists, far less than 90% of the time) (Button et al., 2013; Fraley and Vazire, 2014; Szucs and Ioannidis, 2017; Yarkoni, 2009; Stanley et al., 2018). Some researchers believe that the
___________________
9 Distributions that have more p-values of low value than high are referred to as “right-skewed.” Similarly, “left-skewed” distributions have more p-values of high than low value.
publication of false positives is common and that reforms are needed to reduce this. Others believe that there has been an excessive focus on Type I errors (i.e., false positives) in hypothesis testing at the possible expense of an increase in Type II errors (i.e., false negatives, or failing to confirm true hypotheses) (Fiedler et al., 2012; Finkel et al., 2015; LeBel et al., 2017).
Assessing Unpublished Literature. One approach to countering publication bias is to search for and include unpublished papers and results when conducting a systematic review of the literature. Such comprehensive searches are not standard practice. For medical reviews, one estimate is that only 6 percent of reviews included unpublished work (Hartling et al., 2017), although another found that 50 percent of reviews did so (Ziai et al., 2017). In economics, there is a large and active group of researchers collecting and sharing “grey” literature, research results outside of peer reviewed publications (Vilhuber, 2018). In psychology, an estimated 75 percent of reviews included unpublished research (Rothstein, 2006). Unpublished but recorded studies (such as dissertation abstracts, conference programs, and research aggregation websites) may become easier for reviewers to access with computerized databases and with the availability of preprint servers. When a review includes unpublished studies, researchers can directly compare their results with those from the published literature, thereby estimating file-drawer effects.
Misaligned Incentives
Academic incentives—such as tenure, grant money, and status—may influence scientists to compromise on good research practices (Freeman, 2018). Faculty hiring, promotion, and tenure decisions are often based in large part on the “productivity” of a researcher, such as the number of publications, number of citations, and amount of grant money received (Edwards and Roy, 2017). Some have suggested that these incentives can lead researchers to ignore standards of scientific conduct, rush to publish, and overemphasize positive results (Edwards and Roy, 2017). Formal models have shown how these incentives can lead to high rates of non-replicable results (Smaldino and McElreath, 2016). Many of these incentives may be well intentioned, but they could have the unintended consequence of reducing the quality of the science produced, and poorer quality science is less likely to be replicable.
Although it is difficult to assess how widespread the sources of non-replicability that are unhelpful to improving science are, factors such as publication bias toward results qualifying as “statistically significant” and misaligned incentives on academic scientists create conditions that favor publication of non-replicable results and inferences.
Inappropriate Statistical Inference
Confirmatory research is research that starts with a well-defined research question and a priori hypotheses before collecting data; confirmatory research can also be called hypothesis testing research. In contrast, researchers pursuing exploratory research collect data and then examine the data for potential variables of interest and relationships among variables, forming a posteriori hypotheses; as such, exploratory research can be considered hypothesis generating research. Exploratory and confirmatory analyses are often described as two different stages of the research process. Some have distinguished between the “context of discovery” and the “context of justification” (Reichenbach, 1938), while others have argued that the distinction is on a spectrum rather than categorical. Regardless of the precise line between exploratory and confirmatory research, researchers’ choices between the two affects how they and others interpret the results.
A fundamental principle of hypothesis testing is that the same data that were used to generate a hypothesis cannot be used to test that hypothesis (de Groot, 2014). In confirmatory research, the details of how a statistical hypothesis test will be conducted must be decided before looking at the data on which it is to be tested. When this principle is violated, significance testing, confidence intervals, and error control are compromised. Thus, it cannot be assured that false positives are controlled at a fixed rate. In short, when exploratory research is interpreted as if it were confirmatory research, there can be no legitimate statistically significant result.
Researchers often learn from their data, and some of the most important discoveries in the annals of science have come from unexpected results that did not fit any prior theory. For example, Arno Allan Penzias and Robert Woodrow Wilson found unexpected noise in data collected in the course of their work on microwave receivers for radio astronomy observations. After attempts to explain the noise failed, the “noise” was eventually determined to be cosmic microwave background radiation, and these results helped scientists to refine and confirm theories about the “big bang.” While exploratory research generates new hypotheses, confirmatory research is equally important because it tests the hypotheses generated and can give valid answers as to whether these hypotheses have any merit. Exploratory and confirmatory research are essential parts of science, but they need to be understood and communicated as two separate types of inquiry, with two different interpretations.
A well-conducted exploratory analysis can help illuminate possible hypotheses to be examined in subsequent confirmatory analyses. Even a stark result in an exploratory analysis has to be interpreted cautiously, pending further work to test the hypothesis using a new or expanded dataset. It is often unclear from publications whether the results came from an
exploratory or a confirmatory analysis. This lack of clarity can misrepresent the reliability and broad applicability of the reported results.
In Chapter 2, we discussed the meaning, overreliance, and frequent misunderstanding of statistical significance, including misinterpreting the meaning and overstating the utility of a particular threshold, such as p < 0.05. More generally, a number of flaws in design and reporting can reduce the reliability of a study’s results.
Misuse of statistical testing often involves post hoc analyses of data already collected, making it seem as though statistically significant results provide evidence against the null hypothesis, when in fact they may have a high probability of being false positives (John et al., 2012; Munafo et al., 2017). A study from the late-1980s gives a striking example of how such post hoc analysis can be misleading. The International Study of Infarct Survival was a large-scale, international, randomized trial that examined the potential benefit of aspirin for patients who had had a heart attack. After data collection and analysis were complete, the publishing journal asked the researchers to do additional analysis to see if certain subgroups of patients benefited more or less from aspirin. Richard Peto, one of the researchers, refused to do so because of the risk of finding invalid but seemingly significant associations. In the end, Peto relented and performed the analysis, but with a twist: he also included a post hoc analysis that divided the patients into the twelve astrological signs, and found that Geminis and Libras did not benefit from aspirin, while Capricorns benefited the most (Peto, 2011). This obviously spurious relationship illustrates the dangers of analyzing data with hypotheses and subgroups that were not prespecified.
Little information is available about the prevalence of such inappropriate statistical practices as p-hacking, cherry picking, and hypothesizing after results are known (HARKing), discussed below. While surveys of researchers raise the issue—often using convenience samples—methodological shortcomings mean that they are not necessarily a reliable source for a quantitative assessment.10
P-hacking and Cherry Picking. P-hacking is the practice of collecting, selecting, or analyzing data until a result of statistical significance is found. Different ways to p-hack include stopping data collection once p ≤ 0.05 is reached, analyzing many different relationships and only reporting those for which p ≤ 0.05, varying the exclusion and inclusion rules for data so that p ≤ 0.05, and analyzing different subgroups in order to get p ≤ 0.05. Researchers may p-hack without knowing or without understanding the consequences (Head et al., 2015). This is related to the practice of cherry picking, in which researchers may (unconsciously or deliberately) pick
___________________
10 For an example of one study of this issue, see Fraser et al. (2018).
through their data and results and selectively report those that meet criteria such as meeting a threshold of statistical significance or supporting a positive result, rather than reporting all of the results from their research.
HARKing. Confirmatory research begins with identifying a hypothesis based on observations, exploratory analysis, or building on previous research. Data are collected and analyzed to see if they support the hypothesis. HARKing applies to confirmatory research that incorrectly bases the hypothesis on the data collected and then uses that same data as evidence to support the hypothesis. It is unknown to what extent inappropriate HARKing occurs in various disciplines, but some have attempted to quantify the consequences of HARKing. For example, a 2015 article compared hypothesized effect sizes against non-hypothesized effect sizes and found that effects were significantly larger when the relationships had been hypothesized, a finding consistent with the presence of HARKing (Bosco et al., 2015).
Poor Study Design
Before conducting an experiment, a researcher must make a number of decisions about study design. These decisions—which vary depending on type of study—could include the research question, the hypotheses, the variables to be studied, avoiding potential sources of bias, and the methods for collecting, classifying, and analyzing data. Researchers’ decisions at various points along this path can contribute to non-replicability. Poor study design can include not recognizing or adjusting for known biases, not following best practices in terms of randomization, poorly designing materials and tools (ranging from physical equipment to questionnaires to biological reagents), confounding in data manipulation, using poor measures, or failing to characterize and account for known uncertainties.
Errors
In 2010, economists Carmen Reinhart and Kenneth Rogoff published an article that showed if a country’s debt exceeds 90 percent of the country’s gross domestic product, economic growth slows and declines slightly (0.1%). These results were widely publicized and used to support austerity measures around the world (Herndon et al., 2013). However, in 2013, with access to Reinhart and Rogoff’s original spreadsheet of data and analysis (which the authors had saved and made available for the replication effort), researchers reanalyzing the original studies found several errors in the analysis and data selection. One error was an incomplete set of countries used in the analysis that established the relationship between debt and economic growth. When data from Australia, Austria, Belgium, Canada,
and Denmark were correctly included, and other errors were corrected, the economic growth in the countries with debt above 90 percent of gross domestic product was actually +2.2 percent, rather than –0.1. In response, Reinhart and Rogoff acknowledged the errors, calling it “sobering that such an error slipped into one of our papers despite our best efforts to be consistently careful.” Reinhart and Rogoff said that while the error led to a “notable change” in the calculation of growth in one category, they did not believe it “affects in any significant way the central message of the paper.”11
The Reinhart and Rogoff error was fairly high profile and a quick Internet search would let any interested reader know that the original paper contained errors. Many errors could go undetected or are only acknowledged through a brief correction in the publishing journal. A 2015 study looked at a sample of more than 250,000 p-values reported in eight major psychology journals over a period of 28 years. The study found that many of the p-values reported in papers were inconsistent with a recalculation of the p-value and that in one out of eight papers, this inconsistency was large enough to affect the statistical conclusion (Nuijten et al., 2016).
Errors can occur at any point in the research process: measurements can be recorded inaccurately, typographical errors can occur when inputting data, and calculations can contain mistakes. If these errors affect the final results and are not caught prior to publication, the research may be non-replicable. Unfortunately, these types of errors can be difficult to detect. In the case of computational errors, transparency in data and computation may make it more likely that the errors can be caught and corrected. For other errors, such as mistakes in measurement, errors might not be detected until and unless a failed replication that does not make the same mistake indicates that something was amiss in the original study. Errors may also be made by researchers despite their best intentions (see Box 5-2).
Incomplete Reporting of a Study
During the course of research, researchers make numerous choices about their studies. When a study is published, some of these choices are reported in the methods section. A methods section often covers what materials were used, how participants or samples were chosen, what data collection procedures were followed, and how data were analyzed. The failure to report some aspect of the study—or to do so in sufficient detail—may make it difficult for another researcher to replicate the result. For example, if a researcher only reports that she “adjusted for comorbidities” within the study population, this does not provide sufficient information about how
___________________
11 See https://archive.nytimes.com/www.nytimes.com/interactive/2013/04/17/business/17economixresponse.html.
exactly the comorbidities were adjusted, and it does not give enough guidance for future researchers to follow the protocol. Similarly, if a researcher does not give adequate information about the biological reagents used in an experiment, a second researcher may have difficulty replicating the experiment. Even if a researcher reports all of the critical information about the conduct of a study, other seemingly inconsequential details that have an effect on the outcome could remain unreported.
Just as reproducibility requires transparent sharing of data, code, and analysis, replicability requires transparent sharing of how an experiment was conducted and the choices that were made. This allows future researchers, if they wish, to attempt replication as close to the original conditions as possible.
Fraud and Misconduct
At the extreme, sources of non-replicability that do not advance scientific knowledge—and do much to harm science—include misconduct and fraud in scientific research. Instances of fraud are uncommon, but can be sensational. Despite fraud’s infrequent occurrence and regardless of how
highly publicized cases may be, the fact that it is uniformly bad for science means that it is worthy of attention within this study.
Researchers who knowingly use questionable research practices with the intent to deceive are committing misconduct or fraud. It can be difficult in practice to differentiate between honest mistakes and deliberate misconduct because the underlying action may be the same while the intent is not.
Reproducibility and replicability emerged as general concerns in science around the same time as research misconduct and detrimental research practices were receiving renewed attention. Interest in both reproducibility and replicability as well as misconduct was spurred by some of the same trends and a small number of widely publicized cases in which discovery of fabricated or falsified data was delayed, and the practices of journals, research institutions, and individual labs were implicated in enabling such delays (National Academies of Sciences, Engineering, and Medicine, 2017; Levelt Committee et al., 2012).
In the case of Anil Potti at Duke University, a researcher using genomic analysis on cancer patients was later found to have falsified data. This experience prompted the study and the report, Evolution of Translational Omics: Lessons Learned and the Way Forward (Institute of Medicine, 2012), which in turn led to new guidelines for omics research at the National Cancer Institute. Around the same time, in a case that came to light in the Netherlands, social psychologist Diederick Stapel had gone from manipulating to fabricating data over the course of a career with dozens of fraudulent publications. Similarly, highly publicized concerns about misconduct by Cornell University professor Brian Wansink highlight how consistent failure to adhere to best practices for collecting, analyzing, and reporting data—intentional or not—can blur the line between helpful and unhelpful sources of non-replicability. In this case, a Cornell faculty committee ascribed to Wansink: “academic misconduct in his research and scholarship, including misreporting of research data, problematic statistical techniques, failure to properly document and preserve research results, and inappropriate authorship.”12
A subsequent report, Fostering Integrity in Research (National Academies of Sciences, Engineering, and Medicine, 2017), emerged in this context, and several of its central themes are relevant to questions posed in this report.
According to the definition adopted by the U.S. federal government in 2000, research misconduct is fabrication of data, falsification of data, or plagiarism “in proposing, performing, or reviewing research, or in reporting research results” (Office of Science and Technology Policy, 2000, p. 76262). The federal policy requires that research institutions report all
___________________
12 See http://statements.cornell.edu/2018/20180920-statement-provost-michael-kotlikoff.cfm.
allegations of misconduct in research projects supported by federal funding that have advanced from the inquiry stage to a full investigation, and to report on the results of those investigations.
Other detrimental research practices (see National Academies of Sciences, Engineering, and Medicine, 2017) include failing to follow sponsor requirements or disciplinary standards for retaining data, authorship misrepresentation other than plagiarism, refusing to share data or methods, and misleading statistical analysis that falls short of falsification. In addition to the behaviors of individual researchers, detrimental research practices also include actions taken by organizations, such as failure on the part of research institutions to maintain adequate policies, procedures, or capacity to foster research integrity and assess research misconduct allegations, and abusive or irresponsible publication practices by journal editors and peer review.
Just as information on rates of non-reproducibility and non-replicability in research is limited, knowledge about research misconduct and detrimental research practices is scarce. Reports of research misconduct allegations and findings are released by the National Science Foundation Office of Inspector General and the Department of Health and Human Services Office of Research Integrity (see National Science Foundation, 2018d). As discussed above, new analyses of retraction trends have shed some light on the frequency of occurrence of fraud and misconduct. Allegations and findings of misconduct increased from the mid-2000s to the mid-2010s but may have leveled off in the past few years.
Analysis of retractions of scientific articles in journals may also shed some light on the problem (Steen et al., 2013). One analysis of biomedical articles found that misconduct was responsible for more than two-thirds of retractions (Fang et al., 2012). As mentioned earlier, a wider analysis of all retractions of scientific papers found about one-half attributable to misconduct or fraud (Brainard, 2018). Others have found some differences according to discipline (Grieneisen and Zhang, 2012).
One theme of Fostering Integrity in Research is that research misconduct and detrimental research practices are a continuum of behaviors (National Academies of Sciences, Engineering, and Medicine, 2017). While current policies and institutions aimed at preventing and dealing with research misconduct are certainly necessary, detrimental research practices likely arise from some of the same causes and may cost the research enterprise more than misconduct does in terms of resources wasted on the fabricated or falsified work, resources wasted on following up this work, harm to public health due to treatments based on acceptance of incorrect clinical results, reputational harm to collaborators and institutions, and others.
No branch of science is immune to research misconduct, and the committee did not find any basis to differentiate the relative level of occurrence
in various branches of science. Some but not all researcher misconduct has been uncovered through reproducibility and replication attempts, which are the self-correcting mechanisms of science. From the available evidence, documented cases of researcher misconduct are relatively rare, as suggested by a rate of retractions in scientific papers of approximately 4 in 10,000 (Brainard, 2018).
CONCLUSION 5-4: The occurrence of non-replicability is due to multiple sources, some of which impede and others of which promote progress in science. The overall extent of non-replicability is an inadequate indicator of the health of science.


































