
7
Integrating the Social and Behavioral Sciences (SBS) into the Design of a Human–Machine Ecosystem
With the next generation of artificial intelligence (AI), technologies and tools used to help filter and analyze data would not only be inserted into the current work of the intelligence analyst as they are now but also would transform the very way intelligence analysis is conducted. As a recent report on AI notes, “the field of AI [research] is shifting toward building intelligent systems that can collaborate effectively with people, and that are more generally human-aware,1 including creative ways to develop interactive and scalable ways for people to teach robots” (2015 Study Panel of the One Hundred Year Study of Artificial Intelligence, 2016, p. 9). Future technology could support the design of a human–machine ecosystem for intelligence analysis: an ecosystem composed of human analysts and autonomous AI agents, supported by other technologies that could work in true collaboration. This ecosystem could transform intelligence analysis by
- proactively addressing core analytic challenges more comprehensively than humans alone could, by, for example, systematically monitoring large volumes of data and mining large archives of potentially relevant background material;
- reaching across controlled-access networks within the Intelligence Community (IC) efficiently and securely; and
- identifying patterns and associations in data more rapidly than
___________________
1 Systems that are human-aware “specifically model, and are specifically designed for, the characteristics of the people with whom they are meant to interact” (p. 17).
humans alone could do, and in real time, uncovering connections that previously would not have been detectable.
The design and implementation of a successful human–machine ecosystem will depend on research from the SBS. Given the increasing sophistication of AI applications and the many possible modes of human–technology partnering, there are many unanswered questions about how best to integrate humans with AI agents in analytic tasks. Existing SBS research will be relevant, but the complexity of a human–machine ecosystem will pose new kinds of challenges for the human analyst, challenges that will require new research if the IC is to take advantage of this fundamental technological opportunity.
This chapter explores key questions about human–machine interactions that need to be addressed if the development of new AI collaborators is to produce trusted teammates, not simply assistive devices. The committee’s objective was not to propose a plan for developing a human–machine ecosystem, but to describe the SBS research the IC will need if it is to create, use, and maintain one. We begin with an overview of what would be different if such an ecosystem were developed for the IC: a look at the nature of the agents and technologies that would orchestrate the work and at how intelligence analysis would be transformed. We then turn to what is needed to exploit this opportunity. We examine primary insights from SBS fields that can guide designers, engineers, and computer scientists, at all stages from design to implementation, in creating technologies that will interact optimally with human analysts and support high-functioning systems of human and machines.
We also consider what new research will be needed to bring this opportunity to fruition. For simplicity, the discussion is divided into four domains: (1) human capacities, (2) human–machine interaction, (3) human–technology teaming, and (4) human–system integration. Although this list appears to suggest a hierarchy of work from studies of human capacity to system integration, an optimal research program will require the synergistic interplay of research in each of these domains as knowledge accumulates. Continuous research in each domain will form components of a larger research program that supports the development of an operational human–machine ecosystem to support intelligence analysis.
We note that the set of research topics that could potentially advance the development of a human–machine ecosystem is vast. We identified many other lines of inquiry that might be pursued, and this chapter offers a foundation for what would likely need to be an ongoing program of research. The chapter ends with conclusions about how the IC might move forward to pursue this opportunity, including ideas for planning and conducting the research that is needed, as well as key ethical considerations.
A NEW FORM OF ANALYTIC WORK
The development of a human–machine ecosystem for intelligence analysis would not alter the essential sensemaking challenge described in Chapter 4, but the nature of the activities an analyst might carry out in collaboration with AI agents would be very different. The primary benefits of such a system would lie in its capacity to marry capabilities that are uniquely human—those that presumably no machine could ever replace—with the computing power that outperforms human capacity for some tasks. By doing so, the human–machine ecosystem could, for example, filter and analyze vast quantities of data at an exponentially faster rate than would be possible for any team of humans; reveal questions, connections, and patterns that humans would likely or certainly miss; process a range of inputs—from text in multiple languages to geospatial data—that would require diverse expertise far beyond what a team of individual humans could offer; and tirelessly perform certain functions 24 hours a day.2
Many of the potential benefits relate to the availability of vast and constantly growing quantities and types of data. As discussed in Chapter 5, there are many computational approaches with potential application to issues of interest to the intelligence analyst, all of which require considerable computing power. Some types of data will need to be collected and integrated over long periods, while other streams of information will need to be monitored continuously for new data of value. Automated data collection, monitoring, and analysis supported by new AI techniques would offer means of exploiting large datasets. However, not all analytic work can be automated or turned over to AI. The human analyst will still play a critical role in information processing and decision making, exercising the complex capacity to make judgments in the face of the high levels of uncertainty and risk associated with intelligence analysis.
The key characteristic of a human–machine ecosystem would be the integration of contributions of multiple agents and technologies. There are many ways to describe such agents and technologies, but we distinguish here between those that have agency (humans and autonomous systems or AI) and those that simply provide services or information (e.g., cameras, sensing devices, algorithms for automatic data collection or interpretation). A simple depiction of a human–machine ecosystem in Figure 7-1 shows that people are an integral part of operations. The figure portrays three analytic teams that correspond to the three analytic lenses depicted in Figure 4-1 in Chapter 4. These teams, as well as individual agents, are working in collaboration with and connected to other teams through AI systems.
___________________
2 Several of the white papers received by the committee (see Chapter 1) provided valuable suggestions about what improved human–machine interactions might offer (see Dien et al., 2017; Phillips et al., 2017; Sagan and McCormick, 2017).
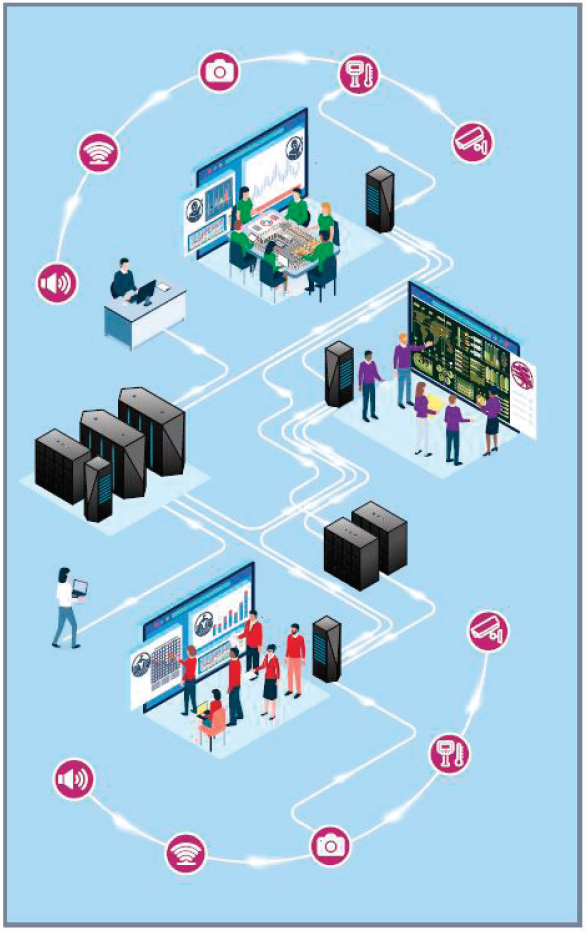
NOTE: This figure is a simple illustration of a human–machine ecosystem in which analysts work in collaboration with and are connected through AI systems. It shows three teams from the hypothetical illustration of analytic work in Chapter 4. The figure also reflects the fact that analysts will be able to work individually while remaining connected to the ecosystem. A variety of sensors (shown surrounding the ecosystem) provide information to the human and AI agents for a number of different purposes, from monitoring and analyzing data pertinent to intelligence analysis to collecting and processing data from interactions between analysts and AI to improve performance.
An agent has been defined as “anything that can be viewed as perceiving its environment through sensors and acting upon that environment through effectors” (Russell and Norvig, 2010, p. 34). Human agents are capable of perceiving through their senses; thinking with their brains; and acting with their hands, mouths, and other parts of the body. Machines that are designed as intelligent agents are able to perceive their environment through sensors (e.g., cameras, infrared rangefinders) and use actuators, motors, and embedded algorithms to make decisions and perform actions. Many intelligent machines (e.g., vacuums, robots for assembly lines, game systems) have been developed to accomplish finite, rule-based tasks.
Most machines perform automated functions, which means they are designed to complete a task or set of tasks in a predictable fashion and with predictable outcomes, usually with a human operator performing any tasks necessary before or after the automated sequence. A machine has autonomy when it can use knowledge it has accumulated from experience, together with sensory input and its built-in knowledge, to perform an action; that is, it has the flexibility to identify a course of action in response to a unique circumstance (National Research Council, 2014; Russell and Norvig, 2010). In a human–machine ecosystem, some machines would need to have that capability. Autonomous systems suitable for intelligence analysis may not be available now, but they are coming. We use the term “semiautonomous agents” for such machines to stress the essential involvement of humans in critical decisions.
These semiautonomous agents would receive inputs from their environment through sensors and supporting technologies, as well as from other agents; select action(s) in pursuit of goals; and then influence their environment either by passing information along or by engaging in physical actions. For example, a useful semiautonomous agent might be a robot capable of physically moving material from one place to another, or an agent capable of alerting an analyst of an event requiring attention through vibrations on a device such as a smartphone. Ideally, these agents would learn from feedback and from their own experiences so they could adapt future actions to improve performance within the ecosystem. There is a long history of research and AI development improving the capability of machines to learn (McCorduck, 2004).
Semiautonomous machines could work with human agents, augmenting working memory, for example, or indicating potentially useful information during an analytic task. They could also work independently, performing complex monitoring functions or data analysis that were beyond human capabilities, or taking on tasks normally performed by humans when the workload became excessive. Either way, they would need to be able to interact regularly with other semiautonomous and human agents, as well as other types of machines.
Other machines in the ecosystem would not have the capacity for adaptive operations; they would be designed to provide necessary and predictable information or services, automatically or on request, to support the work of human and semiautonomous agents. We refer to these types of machines either as sensors (devices useful for monitoring the state of the human and semiautonomous agents, as well as the environment within the ecosystem) or as tools or supporting technologies (devices that will be helpful in acquiring or processing data or executing analyses across many forms of information3).
The IC already uses many kinds of tools to track a broad range of security threats. This capacity will only expand as it becomes possible to implement more and improved automated analyses or data processing tools to monitor broad areas of interest. Semiautonomous AI agents could foreseeably be of particular benefit in meeting the challenge of identifying significant intersections in a vast range of data and analytic output and, as discussed in Chapter 5, their connections to sociopolitical developments and emerging threats. They would require the capacity to integrate critical information—such as data and findings culled from images, communications, environmental measurements, and other collected intelligence—into the workflow of human agents to help them uncover significant connections. (Box 7-1 illustrates the possible effect on information available to analysts.)
In a human–machine ecosystem, analysts would work collaboratively with these semiautonomous AI agents to conduct the analytic activities of sensemaking. Table 7-1 illustrates some of the specific ways in which analytic activities carried out by a human–machine ecosystem would differ from those carried out in the traditional manner.
RESEARCH DOMAINS
If AI technology becomes powerful and autonomous enough to support an ecosystem for intelligence analysis, that system will be useful only to the extent that human analysts benefit from and are able to take advantage of the assistance it offers. SBS research is essential to ensuring that developers of such an ecosystem for the IC understand the strengths and limitations of human agents. Numerous disciplines—such as cognitive science, communications, human factors, human–systems integration, neuroscience, and psychology—contribute to this understanding of human characteristics and their interactions with machines. Most of the questions of interest
___________________
3 Information of relevance to intelligence analysis includes varied types of data, such as those from satellite surveillance and open-source communications and the tracking of critical supply chains, environmental measurements, and indicators of disease contagion.
TABLE 7-1 Comparison of Analytic Activities Conducted Traditionally and in a Human–Machine Ecosystem
| Analytic Activity of an Individual Analyst | Traditional Human Process | Process in a Human–Machine Ecosystem (HME) |
|---|---|---|
| Maintain Inventory of Important Questions |
|
|
| Stay Abreast of Current Information |
|
|
| Analyze Assembled Information |
|
|
| Communicate Intelligence and Analysis to Others |
|
|
| Analytic Activity of an Individual Analyst | Traditional Human Process | Process in a Human–Machine Ecosystem (HME) |
|---|---|---|
| Sustain and Build Expertise in Analytic Area (when time permits) |
|
|
NOTE: Descriptions of analysts’ activities are based on discussion in Chapter 4.
will require interdisciplinary work that brings researchers together both from across the SBS disciplines and with those in AI fields and computer science. The discussion here divides the needed research into four domains: (1) human capacities, (2) human–machine interaction, (3) human–technology teaming, and (4) human–system integration. Although it is not possible to discuss all the relevant research questions comprehensively within the scope of this study, we offer in each domain some of the critical areas that should be investigated. As noted above, the optimal research program will require the synergistic interplay of research in each of these domains as knowledge accumulates.
Human Capacities
While human agents bring sophisticated and contextualized reasoning to the process of analysis and inference, they are also limited in significant ways in their ability to process information. Understanding those limits, particularly in the context of intelligence analysis, is an important step in designing the technologies to augment them. The limitations to humans’ capacity for perception, attention, and cognition are at the root of many errors, both in everyday life and in expert settings such as medicine (Krupinski, 1996; Nodine and Kundel, 1987; Waite et al., 2016), and there is every reason to believe that the same is true for intelligence analysis. While existing research provides insights into these limitations, the complexity of an environment of human–machine teams for intelligence analysis would require more detailed understanding, derived from many research areas, of how these limitations should be factored into a system’s design. In this section, we illustrate the possibilities with a discussion of two such areas: we explore findings from vision sciences that shed light on human limits in attention and memory, and review the literature on workload to consider what is known about how individuals manage interruptions and multiple tasks.
Fundamental Capacity Limits
Humans have finite capabilities. At a perceptual level, many of these limits are fairly self-evident, and centuries of research and development have been devoted to extending human capacity. For example, human acuity is limited to resolving details of about 1 minute of arc (a unit of measure for angles), so microscopes and telescopes were invented to bring small or distant objects into view. Other devices (e.g., infrared night-vision glasses) were created to detect and render visible electromagnetic radiation outside the range of wavelengths of 400–700 nanometers, which humans cannot see. Microphones and amplifiers allow humans to detect otherwise
inaudible sounds, while other devices extend their chemical senses of taste and smell. And the seismograph that detects a remote earthquake or underground nuclear blast can be thought of as an enhancement of humans’ sense of touch.
Attention limits are less fully understood than perceptual limits, and accordingly, less progress has been made in developing the technologies to support them. In fact, research has shown that humans are imperfectly aware of their own attention limits. Many people can recognize that they will fail to see something if it is too small to resolve or if the lights are out, but it may be less obvious to them that they can fail to notice a fairly dramatic change between two visible instances of the same thing (e.g., missing that someone previously had a beard [Simons and Levin, 1998] or failing to perceive an object right in front of them [Cohen et al., 2016; Simons and Chabris, 1999]).
Figure 7-2 can be used to illustrate the complex relationship between attention and what is seen. In this figure, all the colors and lines seemingly can be seen at a glance, yet the presence of particular structures, such as one with four disks instead of three, or one with a blue, a yellow, and a red disk, is not immediately apparent. What makes attentional limits less intuitive than perceptual limits is that some version of “everything” can be seen clearly in this image. In this figure, the presence of a single purple
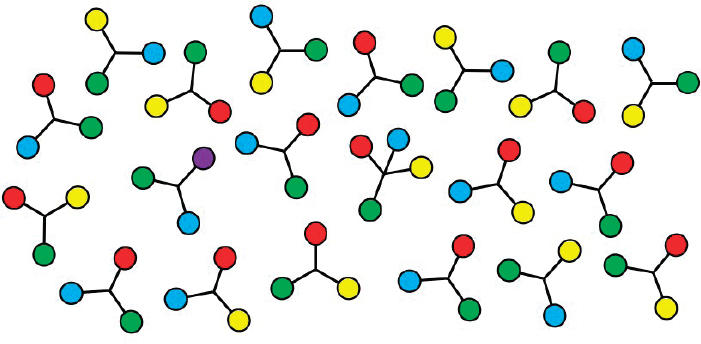
NOTE: This figure illustrates that some visual search tasks are easier than others. Finding the purple target is relatively easy because there is only one, and it is distinct. Finding a three-disk structure that includes blue, yellow, and red disks requires more effort, even though it is easy to confirm the correct colors once one has identified the right item. When the target is defined by a combination of colors, attentional scrutiny is required.
SOURCE: Redrawn from Wolfe (2003).
disk is immediately obvious because there is only one (although even in this case, one might not notice the purple disk until it became relevant). What is not obvious is that one needs to direct attention to a specific question to be sure of its specific features (its colors or orientation)—that is, attention is generally limited to one or maybe a few objects or locations at any moment. For the rest of what is presently in view, the visual system is generating something like a statistical statement. In this case, the statistical statement might be, “There are red, green, blue, and yellow circles, mostly in triangular structures (with one exception).” This estimate is surprisingly rough. For instance, only attentional scrutiny would identify whether there is a vertical line in the figure.
Interestingly, however, the perceptual experience is not so rough. Instead, people experience a “grand illusion” (Noë et al., 2000) that they are seeing a coherent visual world filled with meaningful, recognized objects. One way of conceptualizing this phenomenon is to say that people “see” their “unconscious inference” (Helmholtz, 1924) about the state of the world. This mismatch between the perceptual experience and what is actually held in attention is what leads people to miss something in plain sight.
Attention and memory are closely intertwined elements of cognitive performance, and there are related capacity limits in these domains. Failures of attention could be thought of as failures of memory as opposed to failures of attention. That is, the observer might have seen and recognized something, but then have simply failed to remember it for long enough to report it. Note that from a practical point of view, it matters little whether these errors are described as “blindness” or “amnesia” since versions of these errors (e.g., failure to see a tumor in a medical scan or a missile site in a satellite image) would have the same adverse consequences either way.
Limits to retention in long-term memory are familiar, but limits to short-term or working memory can feel more surprising (Cowan, 2001). There is considerable debate among researchers about whether the latter capacity should be understood as a continuous “resource” or a set of discrete “slots” (Suchow et al., 2014), but there is agreement that the capacity is small. Researchers have found a variety of ways to demonstrate the significant limits to what humans can successfully hold in short-term memory (e.g., see Pylyshyn and Storm, 1988; Vogel and Machizawa, 2004).
These findings could have implications for the design of a human–machine ecosystem, but additional foundational research is needed on the nature of the limits on attention and memory and their significance in IC contexts. Meanwhile, researchers pursuing the design of a human–machine ecosystem can use what is already known in developing technologies, systems, or processes that may augment these human capacities.
Managing Workload
The literature on workload demands, task switching, and interruptions and their effects on human performance is highly relevant to the design of communication protocols and priorities in a human–machine ecosystem. In this environment, the types of workload demands on individual analysts would be different than in the current analytic workflow. Many agents would likely be operating in the work environment, with other agents asynchronously providing new information to be assessed and possibly interrupting the task of another agent.
A promising research avenue is to seek ways to better characterize how and when the products of semiautonomous agents and supporting technologies can best be conveyed to human analysts. A large network of semiautonomous AI agents could generate notifications or push information to human analysts on a random, and sometimes rapid, schedule. From the point of view of the human, however, this capability could have costs as well as benefits. If the semiautonomous agents were to uncover evidence of unusually high-priority risks, this information likely should be pushed to the responsible human analysts as quickly as possible. Otherwise, in lower-risk situations, it would be important to schedule information transfer so as not to stress the human analyst and to increase the information’s usability. Human analysts may also initiate searches for relevant data or inputs from other agents. Research questions of interest include how best to interrupt analysts to transfer information and how analysts would manage switching between tasks in a human–machine ecosystem.
Interruptions. The current literature on interruptions and work fragmentation suggests that people who are interrupted can sometimes compensate by working harder when they return to the interrupted task, though there may be costs in terms of stress and frustration (Bawden and Robinson, 2008; Mark et al., 2008). In other cases, interruptions simply degrade human performance. Interruption is a frequent occurrence for information workers in many work environments (for a review, see Mark et al. [2005]), but are all interruptions the same, and what are their costs? Do people spontaneously interrupt their work patterns, and if so, why? Can external cues help keep things on track (Smith et al., 2003)? These questions require new research.
Work fragmentation, with correspondingly short work episodes, may damage performance, especially on complex problems. Even when an interruption delivers task-relevant information, switching between tasks takes time (Braver et al., 2003; Monsell, 2003; Pashler, 2000). If the current task involves several complicated steps, an interruption may require going back several steps to reinstate context (Altman et al., 2014). Recursive
interruptions, in which an interruption to handle a second task is in turn interrupted by a third, can pose high demands for recovery. On the other hand, some research has shown that multitasking can sometimes improve efficiency (Grier et al., 2008).
Researchers have coded the activities of individuals in their natural work environments and explored the costs of interruption and task switching (Mark et al., 2005, 2016). Such studies indicate that cycling between multiple tasks is common, and that interruptions are most detrimental if the interrupted task is complex, if the interruption does not occur at a natural breakpoint, and if the interruption requires a switch to a different work unit. Individuals who recover well following an interruption often note the current state of information within the interrupted task for later use or analysis (Mark et al., 2005). These observations have implications for the design of protocols for interaction between humans and machines.
Switching between tasks. A classic literature has examined when and how humans divide attention between tasks. Sometimes, tasks can be carried out concurrently without loss; more often, however, performance must be traded off between tasks (Sperling and Dosher, 1986; Sperling and Melcher, 1978; Wickens, 2008, 2010), and in overload situations, operators often carry out tasks and subtasks sequentially (Wickens et al., 2015). Some of the loss in performance caused by switching between tasks can be reduced with training or practice (Monsell, 2003; Strobach et al., 2012). Research in this area has focused on workload and task switching in laboratory tasks involving rapid stimulus classifications, such as alternating color or orientation judgments, where the switching to another task is triggered by the stimulus (Bailey and Konstan, 2006; Pashler, 2000). In voluntary task switching, also studied in laboratory settings (Arrington and Logan, 2004, 2005), operators who are instructed to switch between two tasks at their own rate generally prefer to avoid switch costs. However, research on factors that might be especially important for a human–machine ecosystem, such as the difficulty or priority of a task that might affect task choice, is sparse (Gutzwiller, 2014).
Task threading (a combination of concurrent and sequential task execution), task switching, and interruption have also been studied in human factors research, often using tasks related to flight deck or other complex operations scenarios. Such studies have consisted of observing how individual human agents (e.g., a pilot) facing a computer screen (e.g., on a flight deck) manage their duty cycle with two to four tasks, each with different incentives and time demands. Models predicting the pattern of switching between tasks include preferences for easy, interesting, or high-priority tasks (Gutzwiller et al., 2014; Wickens et al., 2015). These studies also have identified connections between task switching and the human agent’s
need for breaks (Helton and Russell, 2015). Other measured aspects of individual cognitive capacities or functions, such as working memory or perceptual abilities, and their interactions with task complexity or stress may be correlated with an individual’s ability to perform in these complex environments (Kane and Engle, 2003; Kane et al., 2007; Oberlander et al., 2007; Unsworth and Engle, 2007).
When work cycles between tasks in relatively rapid episodes, the workload demands can be visible in various physiological measures, such as pupil diameter or other measures of workload or related stress, such as heart rate (Adamczyk and Bailey, 2004; Bailey and Konstan, 2006; Haapalainen et al., 2010; Iqbal et al., 2004, 2005). (See the discussion of applications of neuroscience later in this chapter.)
Human–Machine Interaction
Research dating back decades has explored human–machine interaction, focusing primarily on the respective strengths and weaknesses of humans and machines and means of assigning tasks accordingly (see, e.g., Endsley, 1987; Kaber et al., 2005; National Research Council, 1951; Parasuraman, 2000; Parasuraman et al., 2000). More recent frameworks for human–machine interaction are helping system designers think about the possibilities for collaboration between humans and machines (Chen and Barnes, 2014). As shown in Figure 7-3, for example, Cummings (2014) drew on Rasmussen’s (1983) taxonomy of skills, rules, and knowledge-based behaviors to illustrate the synergy between computers and humans in relation to type of task and degree of uncertainty. Figure 7-3 shows that skills-based and rules-based tasks lend themselves to automation or execution by machines and that knowledge-based and expertise-based tasks are best performed by humans. However, the figure also indicates that the degree
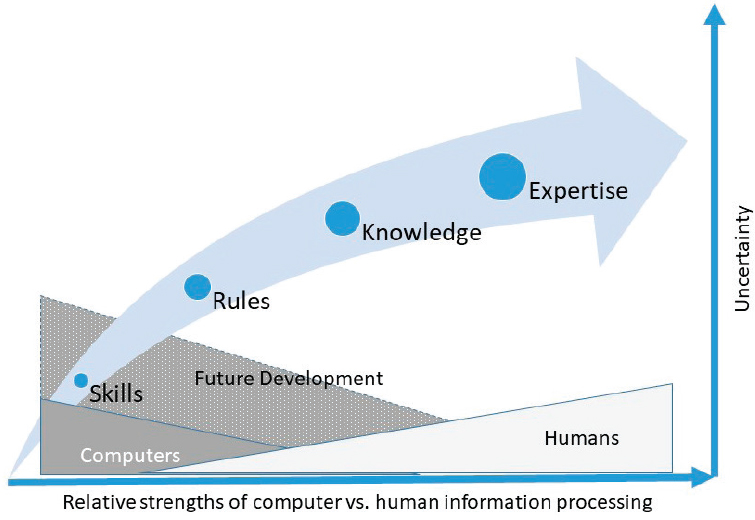
NOTE: Skills-based tasks are defined as sensory–motor actions that can become highly automatic through training and practice. Rules-based tasks are actions guided by a set of procedures. Knowledge-based tasks are actions aided by mental models developed over time through repeated experience. Expertise-based tasks are actions predicated on previous knowledge-based tasks and dependent on significant experience in the presence of uncertainty.
SOURCE: Adapted from Cummings (2014).
of uncertainty inherent in the task at hand will help determine whether it can be fully automated, should be fully under human control, or can best be executed by human–machine interaction.
For repetitive or routine tasks, where the uncertainty is low and sensor reliability is high, machines have advantages over humans. For higher-level cognitive tasks, humans still outperform machines when judgment and intuition are key. However, current and projected advances in the reasoning capabilities of AI and machine learning show promise for enabling machines to take on more knowledge-based and even expertise-based tasks (Cummings, 2014; 2015 Study Panel of the One Hundred Year Study of Artificial Intelligence, 2016). With these advances, machines will be able to work alongside humans as teammates, changing the roles that both play and requiring a new understanding of how human–machine interactions can be most effective.
For intelligence analysis in the age of data overload, human analysts are likely to need assistance from machines in a number of ways. Examples include (1) providing decision support (e.g., helping to store critical information, search datasets, scan multiple images, monitor real-time data streams for anomalies, or recover situational awareness when switching between tasks); (2) generating data visualizations from large datasets in ways that help analysts discover patterns and critical information; and (3) augmenting forecasting capabilities to improve the IC’s ability to anticipate events. This section explores some of the questions that need to be considered and research needed to improve human–machine interaction for intelligence analysis, including research on applications of neuroscience, a field that is advancing rapidly and providing tools and methods.
Decision Support
A wide range of research has investigated technologies that support decision making, much of it focused on medical decision support. Greenes (2014) provides an overview of the topic’s scope within the medical field, which ranges from deep learning algorithms that support classification of images (e.g., Amir and Lehmann, 2016; Fraioli et al., 2010) to efforts to leverage big data methods so that genomic data on patients can be applied to support precision medical care (e.g., Hoffman et al., 2016). AI systems have also been developed to advise human decision makers. Examples of these applications include moving ships and cranes around a container port (Bierwirth and Meisel, 2015), moving energy around the grid (Ferruzzi et al., 2016), and maintaining supply chains (O’Rourke, 2014). At the level of individual consumers there are such applications as rules for conversing with one’s car (Strayer et al., 2016) and even options for presenting online reviews that could shape one’s choice of a restaurant (Zhang et al.,
2017). Efforts in the security realm include automating airport screening (Hättenschwiler et al., 2018).
For all of these applications, implementation requires making choices about the specific nature of the human–machine interactions involved, and the same will be true for applications of AI to intelligence analysis. Many different rules for transferring information between human and AI agents are possible. For example, does the AI offer its information before, during, or after the human’s initial decision? Different rules will produce different outcomes. Moreover, the nature of the task influences rule decisions and outcomes. For instance, if the task is to detect or predict something rare, even a good AI system is likely to produce many more false-positive than true-positive findings. As discussed further below, the interaction rule on how these findings are presented and used can affect the human user’s attitude toward and trust in the AI (Hoff and Bashir, 2015). Should the AI agent present only that information most likely to be useful, posing the risk of failing to draw attention to seemingly less important but actually critical pieces of information, or should the AI agent be programmed to deliver many possibilities to the human analyst, who would then have to separate out the useful material? Can the AI agent be programmed to base its behavior on the prior decision making of the human analyst? For instance, if the human agent were labeling all the information being provided by the AI agent as uninteresting, might the AI agent become more permissive in an effort to make the outputs of the task more comprehensive to increase its chances of providing useful information? There are no straightforward answers to such questions, and seeking those answers and developing ultimate rules for specific contexts will be a rich area for future research.
The remainder of this section reviews some of what is known about perception errors, rare events, biases, and trust to highlight the range of issues that need to be considered in developing the rules of interaction between humans and machines.
Perception errors. An error in perception might involve detecting something that is not present (a false-positive error) or failing to detect something that is present (a false-negative or miss error). Most existing research has focused on the latter class of errors. A useful taxonomy of such errors comes from work in medical image perception (Nodine and Kundel, 1987, p. 1):
- Sampling errors (also called “search” errors [Krupinski, 1996]) occur when experts fail to look in the right location or sample the right information. These are cases in which, in a world of too much information, the information that turned out to be relevant was simply never examined.
- Recognition errors are those in which the target was seen or the information reviewed, but no stimulus attracted any particular attention, and no action was taken. In these cases, the relevant information was examined but not regarded as important.
- Decision errors are those in which the observer recognizes that the stimulus or information might be important, but makes the wrong decision about what to do with that information.
Decisions depend on criteria (Macmillan and Creelman, 2005), either formally set by some standard or internally judged by the observer. A false-negative (or miss) error is made when the observer perceives a target and takes a conservative position by incorrectly concluding that it is not a target, whereas a false-positive error is made when the observer takes a more liberal position by incorrectly concluding that something is a target when it is not. The placement of a decision criterion is of particular importance for detection of rare events (see below). At an airport security checkpoint, for example, the same bag might pass through on one day but be sent for secondary inspection on another if the alert level were raised. The bag has not changed, but the decision criterion has. Signal detection theory (Green and Swets, 1966) makes it clear that shifting decision criteria simply changes the mix of errors made by observers and does not eliminate the possibility of errors.
Rare events. Many of the targets that intelligence analysts try to detect are rare events. It would be desirable, for example, to detect the warning signs of a terrorist’s intentions or of a coup d’état. But, the likelihood that any individual will become a terrorist is very, very small, and coups d’état are also quite rare. Detecting events that are naturally rare is more complicated then detecting more common ones. Research has shown that the nature of human cognition predisposes a person to miss rare events. Humans are, at least in a rough sense, Bayesian decision makers (Maloney and Zhang, 2010): they take the prior probabilities of an event or stimulus into account when making decisions. Missing the signs of a rare event can therefore be considered a form of decision error because humans are typically biased against deciding that they are detecting a rare event (after all, it is rare).
Laboratory studies of rare events in the contexts of screening mammography (Evans et al., 2013) and baggage screening (Mitroff and Biggs, 2014; Wolfe et al., 2013) have shown that low-prevalence targets are more frequently missed (Wolfe et al., 2005) and that using more conservative decision criteria is an important factor in these cases. This research also has shown that observers more readily abandon the search for a rare than for a more common target (Cain et al., 2013; Tuddenham, 1962; Wolfe and Van Wert, 2010). Other research has demonstrated that observers are less
vigilant in monitoring the world for rare events (Colquhoun and Baddeley, 1967; Mackworth, 1970; Thomson et al., 2015).
Rare events take different forms, falling on a continuum from predictable to unpredictable. The occurrence of breast cancer in a breast cancer screening program is an example of a predictable rare event: breast cancer will occur, but it will be rare (about 3 to 5 cases in 1,000 women screened in a North American population [Lee et al., 2016]). At the other end of the continuum are so-called “black swan” events.4 Obviously, truly unpredictable events will by definition, be impossible to predict. Early detection of predictable rare events, from cancer to coups d’état, is a more tractable but still difficult problem.
Technology would appear to offer a solution to the problem of detecting rare events since a computer does not get bored. An algorithm’s decision criteria can be set and will not drift to a more conservative value in the face of such events (Horsch et al., 2008). Yet even without a shift in the decision criteria, some false alarms will still occur. The extent of false alarms is one aspect of human–machine interaction that plays into human trust of technology, discussed further below.
Biases. Cognitive biases are thought processes that produce errors in decisions, as when an individual holds on to beliefs or ways of knowing in spite of contrary information (Gilovich and Griffin, 2002). Humans use information from prior experiences to understand current ones; they can often find connections and use related experience successfully in new applications. However, this ability to retrieve useful information from memory quickly is also subject to a number of biases. Individuals can, for example, be predisposed to search for information that is aligned with knowledge they already possess or that confirms a working hypothesis. While having hypotheses can be useful for sorting information, a person can become anchored to a particular working hypothesis and as a result, filter out discrepant information that may in fact be useful (Tversky and Kahneman, 1974; Yudkowsky, 2011).
Teams of people are just as susceptible to bias as individuals are. Consider the information-pooling bias—the tendency for a team to share and discuss information all members share over information known only to one team member (Stasser et al., 2000). In intelligence analysis, the capacity to consider other information that may be vital to the analysis is essential. Researchers have identified a number of simple cognitive prompts to guide
___________________
4 A black swan event is a metaphor for something that was not predicted but happened nonetheless. For example, the Fukushima nuclear reactor accident in Japan has been called a black swan event since officials believed they had prepared for all extreme threats to the reactor (Achenbach, 2011).
people to think more strategically about their decisions (e.g., Heath et al., 1998; Klein, 2007; Wittenbaum et al., 2004). Further research is needed to determine whether such prompts could work for the tasks of intelligence analysis and whether interactions with machines can be optimized to ensure that additional information critical to the problem at hand is reviewed and shared among analysts as appropriate.
Like humans, moreover, machines and AI systems are subject to errors and decision biases. In an increasingly digitized world, data mining algorithms are used to make sense of emerging streams of behavioral and other data (Portmess and Tower, 2014). Machine learning algorithms are used to identify inaccurate information automatically at the source (e.g., fraud alerts on credit cards) (Mittelstadt et al., 2016), and personalization and filtering algorithms are used to facilitate access to particular information for users (Newell and Marabelli, 2015). The issue, however, is that developers and users of such algorithms may, intentionally or inadvertently, insert bias into the algorithms’ operational parameters (Caliskan et al., 2017; Nakamura, 2013). Algorithms will reflect the gender, racial, socioeconomic, and other biases that are reflected in training data. For example, domestic U.S. criminal justice applications of machine learning and AI, such as facial recognition algorithms used in policing, have been found to be biased against African Americans (Garvie et al., 2016; Klare et al., 2012). (See Box 7-2 and Appendix D for more detail, and see Osoba and Welser [2017] and National Academies of Sciences, Engineering, and Medicine [2017a, 2018a] for further discussion of AI errors, bias, and associated risks.) This issue will continue to grow in importance as algorithms become more complex, and as they engage in semiautonomous interactions with other algorithms and are used to augment and/or replace analyses and decisions once the purview of humans.
Although research is under way to examine bias in training datasets and algorithms, one issue yet to be addressed is cultural bias, an issue of significance for the IC. Because data for training datasets are frequently collected in countries where relevant research is taking place, these algorithms are often biased to be more successful with certain cultures and geographic regions than others (Chen and Gomes, 2018). Analysts using computational models to assist in understanding and predicting the intent, behavior, and actions of adversaries may derive skewed results because of unrecognized cultural bias in the computational design process. Understanding of cultural nuances will be important in extending algorithmic applications to semantic and narrative analyses of use to the IC. For example, non-English data must be carefully defined and categorized for use in computational models to avoid mirror imaging and biasing the model toward one’s own cultural norms.5
___________________
5 Mirror imaging denotes analysts’ assumption that people being studied think and act like the analysts themselves, including their gender, race, culture, and so on (Witlin, 2008).
Designers can take steps to address and mitigate machine-based biases before algorithms and technologies are put into use by incorporating SBS insights on complex cultural, political, and social phenomena into their designs.
Trust. Lack of trust on the part of human agents will limit the potential of a human–machine ecosystem. On the other hand, excessive trust can lead to complacency and failure to intervene when the performance of technology declines (Cummings et al., 2008) or it is used for circumstances beyond its design (Parasuraman and Riley, 1997; Lee and Moray, 1994; Hoffman et al., 2013). Machine-based biases and errors will likely affect a human’s ability to trust machines completely, as demonstrated by the rare event example in Box 7-3.
The problem of low-prevalence events could adversely affect operations in a human–machine ecosystem. For example, an ecosystem’s detection of
two novel, otherwise undetected factors linking activities and information of the sort described earlier in Box 7-1 could be very useful. But if these two factors were embedded in a list of 100 spurious connections between activities, analysts might disregard the information. Given the vast number of possible interactions that might be uncovered by a human–machine ecosystem, the development of collaborative technologies capable of providing advice with high positive predictive value (i.e., number of correct conclusions/all conclusions) will be a daunting technical challenge.
Another challenge concerns the need to understand the reasoning behind the machine’s connections or conclusions. This issue has been termed “explainable AI” and is being examined by a number of research programs.6 In intelligence analysis or other types of decision making, it is not enough just to flag a connection or an anomaly; it would be useful if the machines could explain how they reached their findings.
The challenge for SBS research, then, is to understand how humans can make the best use of imperfect information from AI agents and supporting
___________________
6 See more information on Defense Advanced Research Projects Agency’s AI program at https://www.darpa.mil/program/explainable-artificial-intelligence [January 2019].
technologies. If the human–machine interactions are designed well, a feedback protocol will be in place to support both humans and machines in assessing any results critically, to allow more flexibility than human agents simply accepting or rejecting machine outputs.
Static and Dynamic Data Visualization
A human–machine ecosystem for intelligence analysis will use semiautonomous AI agents and supporting technologies to process massive digital datasets as an aid in discovering relevant patterns, including many that change over time. Because human analysts will continue to play critical roles in analysis and decision making, it will be important to consider human characteristics in the design and selection of ways to perceive the data. Sophisticated data visualizations7 are increasingly available in the public domain. Innovative new ways to present analyses of data are also likely to benefit the IC.
There are many approaches to data visualization. Textbooks and manuals have been written on the subject, many inspired by informal analysis of effectiveness, visual interest, and aesthetics (Tufte, 2003, 2006; Tufte and Graves-Morris, 2014; Tufte and Robins, 1997; Tufte et al., 1998). Visualization methods have been developed for statistical and computer applications (see, e.g., Rahlf, 2017). Indeed, the history of cartographic and visualization methods is long (Fayyad et al., 2002; Friendly and Denis, 2001; Fry, 2007; Keller et al., 1994; Steele and Iliinsky, 2010).
The volume and complexity of data available in the age of digital human behavior pose new challenges in analysis and visualization. Analyzing trends in time-varying multivariate data—that is, coding multiple variables at different times—creates special challenges for visualization and understanding, especially as large-scale time-varying simulations (Lee and Shen, 2009) are incorporated into analysis. As the volume of data potentially relevant both to research and to situations of interest to intelligence analysts increases, so do the challenges of how best to analyze and display these data for human interpretation and comprehension. Effectively conveying information to the human analyst may help support understanding, and therefore trust in the outputs of AI agents.
Researchers in the field of modern data visualization study how best to visualize data to support human perception and reasoning. An early literature on interpretation of simple graphs (e.g., Boy et al., 2014; Dujmović et al., 2010; Halford et al., 2005; Kosslyn, 1989; Wainer, 1992) focused on the distributions of single variables, differences in means, or interactive effects of variables. The aim of emerging work on data visualization is to support analysis and communication of more complex information. For example, researchers have proposed a rank ordering of different graphical formats to indicate how well they convey information about correlations
___________________
7 The term “data visualization” refers to the representation of information or data analysis in the form of a chart, diagram, picture, etc.
among variables (Harrison et al., 2014; Kay and Heer, 2016). Other recent advances include the following:
- Research has been conducted on the relative effectiveness of different visual features, including the relative discriminability of different CIE colors8 at different spatial scales (Stone et al., 2014); the effectiveness of coding by position, orientation, size, and color/luminance to reveal central tendencies, outliers, trends, and clusters in data (Healey, 1996; Szafir et al., 2016a); and how display size can influence the effectiveness of visualization (Shupp et al., 2009; Yost and North, 2006).
- Research has also been carried out on novel ways of visualizing word usage in text. Configurable color fields, such as clusters of color patterns, can help reveal patterns of word usage in documents, allowing comparison of those patterns across documents even when the relevant patterns may not be known a priori (Szafir et al., 2016b). In addition, complex word co-occurrence patterns based on frequently occurring words or word combinations can be used to derive the “topics” appearing in different bodies of text (Alexander et al., 2014; Dou et al., 2011). Keywords have been used to query financial transaction histories (Chang et al., 2007).
- Visualization of networks as graphs of connected points (nodes) or as points in multidimensional spaces in which distance conveys similarity has supported research on social networks. Study of the dynamics of social networks that change over time can potentially be aided by time animation displays or corresponding computer simulations of potential cascades of outcomes.
In practice, intelligence analysts will likely focus on the problems to be solved, not what can be accomplished with a specific visualization tool. Thus the most useful design focus will be on making the interactions with data tools natural, obvious, and transparent, permitting the analyst to move easily between different visualization applications (Shapiro, 2010; Steele and Iliinsky, 2010). Other predictable challenges may involve the fusion of multiple sources of data and treatment of missing data (Buja et al., 2008), both ongoing topics of study.
___________________
8 The CIE color model is a color space model created by the International Commission on Illumination, known as the Commission Internationale de l’Elcairage (CIE).
A combination of research in the vision sciences, the behavioral sciences, and human factors has the potential to advance understanding of how people extract meaning from a data visualization, resulting in more effective techniques and design principles. Research on visual perception and attention can be mined to improve the functionality of data visualization. Relevant topics include studies of the perception of basic visual properties (e.g., color, shape), visual search, and working memory.
Forecasting Models and Tools
A well-designed human–machine ecosystem has the potential to transform predictive forecasting—a domain that has long been central to the IC. Forecasting (the so-called “Holy Grail” of intelligence analysis) is the reliable anticipation of future events. Large-scale data sources and the
increasing complexity of intelligence problems will challenge the design of future forecasting systems. In addition, designers will have to determine how best to integrate information processed by semiautonomous AI agents and automated detection systems with human judgment. At present, forecasting methods with a 75–80 percent success rate are considered rather good, yet this success rate is often built on easy-to-moderate cases. Human analysts or algorithmic models may also score well on easy calls, but not so well on situations that are more difficult to predict. The IC needs forecasting methods that succeed with challenging problems. Recent SBS research has made significant progress toward (1) understanding how humans make predictions and improving the probability estimates of human forecasts and (2) incorporating human behavior into forecasting models. The next generation of forecasting research can build on this work to improve precision for those difficult problems with which the analyst most needs help.
Human forecasters. Human judgments and decisions, including the ability of humans to assess and manipulate probabilities, have been studied for decades, notably since the World War II era (Luce, 2005; Luce and Raiffa, 2012). Forecasting the future is a complex effort, though people do it often as they consider decisions in their personal lives (e.g., the likelihood of needing major medical treatment in the next year); in business (e.g., what kinds of dresses will sell); or in economic predictions (e.g., the economic consequences of a shift in monetary policy). The centrality of forecasting to intelligence analysis was recently highlighted by an Intelligence Advanced Research Projects Activity (IARPA) research initiative on geopolitical forecasting, which sponsored competitive forecasting tournaments.9 These tournaments were focused on such questions as: How likely is it that unrest in region R will explode into violence, and on what time scale? Will country C develop enriched nuclear stockpiles of a critical size? Will a regional outbreak of infectious disease D be transmitted to the United States? Will the capacity to generate clean fresh water be outpaced by population growth in arid region Z?
The initial 4-year round of IARPA funding covered five academic research groups that participated in these tournaments, producing a wealth of research on potential approaches to improving geopolitical forecasting (Tetlock, 2017). The research groups focused directly on understanding the probability estimates made by humans and how best to aggregate them. The research topics included quantitative evaluation of probability estimation, the technical issues underlying the transformation and/or aggregation of probability estimates from several individuals, the characteristics of
___________________
9 For more information on IARPA’s Aggregative Contingent Estimation program, see https://www.iarpa.gov/index.php/research-programs/ace [November 2018].
individual forecasters who are very successful, and whether selection or training could improve the accuracy of forecasts. This research program yielded valuable information for the IC, predicting yes-or-no answers to geopolitical questions relevant to its work. For example: Will Italy’s Silvio Berlusconi resign, lose reelection/confidence vote, or otherwise vacate office before October 1, 2011 (Satopää et al., 2014a)?10
The IARPA tournaments led to a number of key conclusions, resulting especially from the prominent work of one of the research groups—the Good Judgment Project (Mellers et al., 2014). This group may have outperformed others precisely because it focused on the training and selection of individuals and teams, as well as the use of technical models of probability estimation and aggregation.11 The training directed individuals to recognize potential biases of human probability estimates and reasoning (Fischhoff et al., 1978; Fong et al., 1986; Slovic et al., 1980). The group showed that certain interventions—such as providing individual training, increasing the interchange within teams, and the selection of “superforecasters” (the top few percent of performers)—all can improve the performance of both individuals and teams12 (Mellers et al., 2014).
One question for the next generation of research is how AI might be integrated into forecasting teams (see discussion of human–technology teaming below). To contribute effectively to team forecasts, AI and the automated models from which it would draw information would have to do a better job of incorporating human behavior into their predictions.
Incorporating human behavior into forecasting models. Research on human behavior, whether cognitive or social, has become increasingly relevant to forecasting. Many forecasting tools used in everyday life are based on physical models (e.g., forecasting of storm paths from weather models). Many of these physical models help predict impacts on humans but do not incorporate impacts of human behavior on the system. However, some tools have incorporated human behavior in their models. For example, a model used to predict the future geospatial distribution of valley fever—
___________________
10 Each human forecaster participating in a tournament would provide a probability estimate—e.g., 0.70 for a yes-no event—with the event being coded as 1 or 0 for whether it was predicted to occur or not. Brier (1950) scoring was used to assess the calibration of the forecasted probability (e.g., BS = ERj = 1(fi – oi)2, where R is the number of outcomes—2 as the problems were binary, fi is the forecasted probability, and oi is the outcome).
11 Other IARPA-funded groups focused on methods for aggregating and transforming probability estimates to correct for biases near the endpoints (i.e., underestimation near 1 and overestimation near 0) that may emerge from asymmetric noise distributions [Turner et al., 2014; Erev et al., 1994; Baron et al., 2014]).
12 The team performance was measured by the median probability estimate of an interacting group of individuals.
which tends to expand north and east from its area of greatest incidence in the southwestern United States when air and soils become warmer—incorporates both the impacts of human behavior on soil disturbance and climate factors (Gorris et al., 2018).
Two relevant examples were highlighted in the workshops held for this study (NASEM, 2018d; see Chapter 1). One of these examples, parallel to the valley fever case, shows how physical models of Zika virus vectors based on seasonal wetness, temperature, and mosquito proliferation identify baseline risk, but can be made more accurate when such human factors as risk behaviors, the mobility of infected individuals, or the potential impacts of available sociopolitical responses are also modeled (Monaghan et al., 2016). Other inputs might include indicators derived from data mining of social messaging (Twitter, Facebook, etc.), used to provide online estimates of outbreak severity. In the second example, indicators of human behavior are introduced into analytic estimates of human water insecurity in regions of water scarcity and population increase identified by the United Nations, many in the Middle East. Researchers from the Massachusetts Institute of Technology (MIT) forecasted regional water poverty by estimating the likelihood of large-scale water infrastructure projects based on such observable human indicators as local decision making, permits, and funding (Siddiqi et al., 2016). This example illustrates the benefits of specifying the most useful human indicators to include in a forecasting model.
Both of these examples start with models based in physical or biological mechanisms that become more sophisticated in one of three ways: (1) by incorporating further model modules to account for important aspects of human behavior (e.g., population mobility, exposure epidemiology, physical consequences of policy initiatives); (2) by measuring key inputs based on associated aspects of human behavior (e.g., disease contagion or measures of social unrest harvested from social media); or (3) by incorporating new questions or new indicators based on deconstruction of a problem (e.g., physical precursors of water projects, analysis of the availability of precursor supplies in an economic supply chain).
Data analytics and statistical models are tools that underpin the majority of forecasting. Traditionally, empirical models have been built from intentional observational studies, using statistically designed data collections. The data revolution and the explosion of data science have opened up new data sources not traditionally used in empirical models (Keller et al., 2016, 2017; NASEM, 2017b). Today, access to administrative data (i.e., data collected to administer a program, business, or institution) and opportunity data (e.g., embedded sensors, social media, Internet entries) are routinely being accessed to support analyses, even within the IC and U.S. Department of Defense (DoD) contexts (NASEM, 2017b). New quantitative paradigms are being developed to manage the diversity of data and the
challenges associated with repurposing massive amounts of non–statistically designed data sources for analysis (National Research Council, 2013). The IC has a growing program in open-source intelligence making use of such nontraditional data sources (Williams and Blum, 2018).
The IC has a long history of implementing and understanding engineering and physical systems modeling. The challenges highlighted in this report will require the IC to build corresponding competency in social systems modeling to support forecasting and sensemaking. The transition from physical/engineering-based modeling to social systems modeling is not straightforward (NASEM, 2016), however, for the following reasons:
- Physical systems often evolve according to well-known rules, so that uncertainties in predictions based on such models can be narrowed down to uncertainties in model parameters, initial conditions, and residual errors. By contrast, social systems often evolve according to rules that are not well understood, making the difference between such models and real life highly uncertain at times; quantifying this uncertainty can be challenging.
- A substantial amount of direct data is available for many physical systems with which to calibrate these models and estimate uncertainties in model-based predictions. Data for many social system models, on the other hand, are not readily available, and it may not be possible to produce those data directly (e.g., inducing strong emotions such as hatred in a human subject is unethical). Data may therefore need to be repurposed for use in supporting models of social systems.
- Engineered systems are often designed to operate so that their various subprocesses behave linearly, with minimal interaction, and operate within their designed specifications. Complex interactions and feedbacks are often the focus for many social systems, and the humans that are central to social systems do not have design specifications.
- Behavior mechanisms in physical systems can be modeled relatively easily because their effects are well known and independent (e.g., behavior of materials for yielding, fatigue, fracture, and creep. In contrast, mechanisms in human systems often interact (e.g., sadness, depression, addiction), making modeling more difficult.
- Extrapolation is difficult for physical and social systems. However, extrapolation is frequently required in many social system settings since the complexities of these systems often put them on a trajectory that is unlike previous experience.
___________________
13 More information on IARPA’s Hybrid Forecasting Competition can be found at https://www.iarpa.gov/index.php/research-programs/hfc?id=661 [November 2018].
14 Also, strong claims have been made about the calibrating force of the proper scoring method, such as the Brier score (Brier, 1950; Mellers et al., 2015; Tetlock et al., 2014), and it is not clear whether training and calibration of human forecasters would be equally effective in multinomial or expanded probability assessment problems, or indeed how best to aggregate estimates from multiple sources.
Applications of Neuroscience
Projected progress in neuroscience could be particularly relevant to the development of human–machine ecosystems, optimizing human–machine interactions. Developing work on the neurobiological relationships that underlie emotion, motivation, and cognition and influence cognitive processes (e.g., decision making) and their determinants is yielding possibilities for identifying and tracking physiological responses that signal mental and emotional states and improving task performance. Related work on interfaces between the human brain and computer technology, while further from implementation, show promise for significantly increasing the efficiency of technology-supported work.
Monitoring physiological responses. As an example of the application of neuroscience, neurotechnologies such as functional neural imaging (functional magnetic resonance imaging [fMRI]15 and functional near-infrared spectroscopy [fNIRS]16) provide tools with which to identify neural correlates of various dimensions of analytic thinking, such as inductive reasoning, pattern detection, cognitive flexibility, cognitive bias, open-mindedness, and even creativity. Mapping based on experimental results could produce a catalog of neural correlates of analytic thinking—that is, regions or networks of the brain that are active during a particular dimension of analytic thinking. Such mapping could provide a basis for vetting various human–machine interactions anticipated in a human–machine ecosystem.
Another important contribution of neuroscience is in the development of strategies and sensors designed to measure and potentially mitigate mental and physical fatigue in the workplace (see also the discussion of supports for the analytic workforce in Chapter 8). Recent advances have been made in developing tools for monitoring the physiological state of human agents and enhancing the interactions between humans and machines. Further developments in this area are likely to provide tools that can be used both in SBS research to study strategies for improving operations in a human–machine ecosystem and within the ecosystem itself as a way of monitoring the state of the environment and providing feedback to agents.
___________________
15 fMRI is used to measure changes in blood flow across the brain as an indication of changes in neural activity. Used in hospitals and imaging facilities, it measures changes in neural activity with high spatial resolution, but the size of the device does not allow for deployment in field settings.
16 fNIRS is used to measure changes in blood flow and changes in oxygenation of blood in discrete regions of the brain as an indication of neural activity. It measures changes in neural activity with moderate spatial resolution, and the size and portability of the device allow for deployment in field settings.
A wide range of portable, noninvasive biological sensors now available can monitor such physiological parameters as respiration and heart rate and a number of other biological signals.17 Many of these parameters are highly sensitive to stress, and can serve as important markers of specific aspects of stress, performance, and fatigue in human agents. Output from a number of these sensors has been used in developing explicit measures of cognitive workload (Liu et al., 2018). Biological markers, for example, including emerging skin-sensor measures of metabolic and neuroendocrine status (Rohrbaugh, 2017), could be valuable in identifying workload effects and provide important tools for use in studies of strategies for mitigating fatigue.
Although direct contact between a human agent and the sensor is necessary for some of these measures, work on the development of remote sensors that do not have that limitation is under way. Such sensors could be used to monitor physiological parameters as diverse as heart rate and heart rate variability, respiration, electrodermal activity, and other responses in people who are moving and are at a distance from the sensor.18
The development and deployment of these technologies will pose a wide range of ethical, legal, and social challenges (discussed further below). The use of biological sensors without the consent of those whose responses were being measured would pose clear questions, for example, but their use could also foster various forms of dependence among those who consented. Individuals who relied on data from the sensors to monitor their states and regulate their activities might become overreliant on the technology and less skillful at monitoring their own physiological responses (Bhardwaj, 2013; Lu, 2016; Noah et al., 2018). And widespread use of biosensors would contribute to concerns about a state in which too many actions are under surveillance (Shell, 2018; Rosenbalt et al., 2014; Moore and Piwek, 2017), as well as raise questions about the “quantified self”—the idea that all understanding of human behaviors is reduced to the data being tracked (Swan, 2013).
Interfaces between the human brain and computers. Research in neurotechnology and human–machine interactions has also explored interfaces between the human brain and computers; current applications of this work tend to be limited to the laboratory and are not yet practical for general use (Nicolas-Alonso and Gomez-Gil, 2012). A human operator using a
___________________
17 Other physiological parameters that can be monitored include heart rate variability; cardiovascular performance derived from impedance cardiography; sympathetic and parasympathetic activity indexed by pupillometry; localized cerebral blood flow revealed by near-infrared spectroscopy; and electrodermal, electroencephalographic, electromyographic, and neuroendocrine responses.
18 Other responses include photoplethysmographic, pupillometric, oculometric (eye-tracking), and pneumographic (respiratory) responses (Rohrbaugh, 2017).
keyboard and perhaps a mouse to enter and receive information through visual displays and possibly auditory communications represents a rather cumbersome and inefficient mode of interaction. The ability of the computer to interpret the thoughts of an operator would have significant implications for intelligence analysis, especially in combination with AI. Indeed, developments in brain–computer interfaces are rapidly emerging, making “thoughts” available as input to software applications. Instead of using typing or voice to issue data, an operator can deliver commands or information to a computer program simply by thinking. Current applications of this technology include devices that monitor the attention an individual devotes to a task and those that detect a selection that currently would be indicated by a mouse click. Emerging applications interface with virtual reality to convey feedback of reactions to the system through thoughts. Eventually, the brain–computer communication could be two-way, allowing a computer to induce perception in the brain of an operator.
DoD and the broader scientific community are increasingly interested in enhancing such interfaces. In support of President Obama’s BRAIN (Brain Research through Advancing Innovative Neurotechnologies) initiative, DoD sponsored the Systems-Based Neurotechnology for Emerging Therapies (SUBNETS) program.19 This program entailed a multi-institutional effort (the University of California-San Francisco, Massachusetts General Hospital, Lawrence Livermore National Laboratory, and Medtronics) to develop and deploy brain–computer interfaces (including invasive procedures) to advance health. More recently, DARPA sponsored the Towards a High-Resolution, Implantable Neural Interface project in support of the 2016 Neural Engineering System Design program.20 Although many of these efforts involve invasive methods, noninvasive approaches are increasingly viable and currently in development. One such system is envisioned as a wearable interactive smart system that can provide environmental and contextual information via multimodal sensory channels (visual, auditory, haptic); read the physiological, affective, and cognitive state of the operator; and assist in focusing attention on relevant items and facilitate decision making. Although this capability may be somewhat fanciful, and perhaps unrealistic with current technology and neurobiological understanding, ongoing interdisciplinary efforts are moving in this direction.
___________________
19 See https://www.darpa.mil/program/systems-based-neurotechnology-for-emerging-therapies [July 2018].
20 See https://www.darpa.mil/news-events/2017-07-10 [July 2018].
Human–Technology Teaming
Intelligence analysts generally work in analytic teams and collaborate regularly with their colleagues (see Chapter 4), and a key objective for a human–machine ecosystem is for analysts to work productively with technological teammates. A variety of research sheds light on the nature of teams in the workplace, some in the security context (see Box 7-4), and points to research directions for better understanding of human–machine teaming. This section reviews the science of teamwork and then explores its applications to teams involving autonomous or semiautonomous AI systems.
The Science of Teamwork
A rich literature describes research on teamwork and the factors that make human teams effective (Salas et al., 2008). The science of teams and teamwork gained impetus in July 1988 when the USS Vincennes accidentally took down an Iranian Airbus, killing 290 passengers. This incident was attributed in part to poor team decision making under stress. The Department of the Navy established a research program—TADMUS (Tactical Decision Making Under Stress)21—to identify research in human factors and training that could be useful in preventing such incidents. This program focused significant attention on team training (Cannon-Bowers and Salas, 1998). DoD subsequently supported significant research on
___________________
21 See http://all.net/journal/deception/www-tadmus.spawar.navy.mil/www-tadmus.spawar.navy.mil/TADMUS_Program_Background.html [June 2018].
the science of teams (Goodwin et al., 2018). In 2016, for example, the Army Research Office funded a Multi-University Research Initiative on the network science of teams, and in 2018, the Army Research Laboratory announced its Strengthening Teamwork for Robust Operations in Novel Groups (STRONG) program, focused on human–agent teaming.
The research base in this area has grown as recognition of the importance of understanding and improving teamwork has spread to other sectors, including medicine, energy, and academia. Foundational work established the nature of a team: a special type of group whose members have different but interdependent roles on the team (Salas et al., 1992). The study of teams within academia has come to be known as team science, which focuses on examining such questions as which team features influence scientific productivity (e.g., number of publications) and scientific impact (e.g., number of citations) (for a review, see Hall et al. [2018]). A 2015 National Academies report, Enhancing the Effectiveness of Team Science (National Research Council, 2015) addresses collaboration among teams of scientists, which often operate across disciplines. The interdisciplinary field of computer-supported cooperative work (Grudin, 1994) has developed to address the integration of computing technologies into teams, and most recently, advances in AI have led to work on the teaming of humans and autonomous agents or robots (McNeese et al., 2017).
Individuals almost always are members of multiple teams concurrently (O’Leary et al., 2011). In some cases, this multiteam membership enriches the performance of all teams because individuals serve as conduits of best practices across teams (Lungeanu et al., 2018). Research also has examined teams of teams, treating them as multiteam systems (DeChurch et al., 2012). This research has focused on the dilemma that the overarching goals of the system (e.g., investing resources to share intelligence relevant to other teams) are often not well aligned with the local goals of each team (e.g., investing resources in collecting and acting on intelligence within a particular team), which makes for inherent tension. This research has led to conceptualizing multiteam systems as ecosystems of networked groups (Poole and Contractor, 2012).
Research has also yielded practical guidance on how best to assemble human teams, how to train and lead teams, and how such outside influences as stress influence teamwork (Cannon-Bowers and Salas, 1998; Contractor, 2013). Significant research has also been carried out in the area of team cognition (Salas and Fiore, 2004). This work indicates that teammates who share knowledge about the task and the team (what has been referred to as shared mental models) are better able to coordinate implicitly (Entin and Serfaty, 1999; Fiore et al., 2001). For large or spatially distributed teams, individual team members likely can hold only partial understandings of the tasks and teammates at any given time. In such situations, cognition at the
team level has been observed to be fluid and heavily dependent on team interaction (Cooke et al., 2013). Considerable research also has focused on conceptualizing the effectiveness of a team in terms of its transactive memory (Wegner, 1987). That is, effective teams comprise individuals who each possess expertise in some of the areas required for the team to be effective, are aware of the expertise possessed by each of their team members, are able to retrieve that expertise as needed, and help expand those members’ expertise by proactively providing them with information relevant to their areas of expertise.
Clarity about roles and the nature of communication and interaction are very important to team effectiveness because of the different contributions each member brings. These aspects of team functioning can be improved at minimal cost through attention to team composition, leadership, and training and the use of collaborative technologies (Salas et al., 2008). Training of team leaders is a particularly useful intervention for improving team functioning. Although groups can be trained to perform more effectively as teams, this poses a challenge for ad hoc teams that are formed to meet a particular need and may never function together again as a team. Trained leaders can address this challenge by training other team members, thereby improving overall team performance. This point is illustrated by a study of training strategy for effective code blue resuscitation (Hinski, 2017). The strategy used in this study was modeled after one developed by DoD in the context of an unmanned aerial system: the interactions among team member roles that are essential for an effective resuscitation were identified, and this model was studied by the leaders of the code blue exercises for as little as 5 minutes. Once on the code blue team, these leaders were taught to request information that did not come in a timely manner. Results later indicated that the trained leaders helped train the other team members, thereby improving team performance relative to that of teams with untrained leaders.
Teamwork and Autonomous Systems
Advances in AI and robotics have yielded computing technologies capable of collaboration on the level of a full-fledged teammate. SBS researchers are now exploring new types of human–machine interactions, including those among teams that include a mix of humans, autonomous AI, decision aids, wearable technologies, and robots. This research is examining optimal ways such teams can be assembled, developed, and led to be most effective. Building on a large body of knowledge about human teams, this work is considering the similarities and differences in teamwork characteristics and dynamics when teammates include technological agents. Human factors research has historically focused on human–machine interaction in rela-
tion to machines with automated functions but limited autonomy; today, however, machines have become increasingly intelligent and, in many ways, autonomous (Parasuraman et al., 2000). These machines do not require as much supervision, control, or oversight from humans relative to their less autonomous counterparts, and they function in many ways like human teammates. Thus they can take on those parts of a task that humans cannot or do not want to do, although in many circumstances, humans would need to maintain supervisory control even as their direct active control of machines decreased (Chen and Barnes, 2014).
Research in human factors has started to explore how this human–technology teaming relationship works in greater detail. Questions to be addressed include the following:
- How does the presence of an AI agent affect human team members?
- How should tasks be allocated to humans or machines?
- How are human trust, skill development, and situation awareness affected by AI systems?
- What form of interaction or communication is best suited to such heterogeneous teams?
- How much do the AI or robot team members need to know about their human counterparts? Can biometrics be used to sense human states?
Human factors research on such questions often requires multidisciplinary collaboration with the AI and robotics community. There is a body of research on human interaction with robots that possess autonomy. Most of this work has been at the dyadic level—between one human and a robot, and researchers are just starting to explore how the presence of a robot on the team affects human-to-human interaction (Jung et al., 2017). More research and theoretical advances are needed with respect to teaming contexts that include multiple humans and robots (Robert, 2018).
One outstanding question about the protocols for interaction within a human–machine ecosystem is the appropriate balance of control between the semiautonomous AI agents and the analysts (Chen and Barnes, 2014). Current findings from applied research and human factors analyses—albeit based on contexts other than intelligence analysis, such as aircraft navigation or production facilities—consistently reveal the need to retain one or more active human agents at the stage at which a system comes to a decision or chooses an action. This work indicates that, whereas using computer systems to perform analyses on input data at high rates may be necessary to support limited human capacities, overreliance on automated analyses (e.g., flight deck reliance on autopilot) is associated with an increased likelihood of failures (Parasuraman and Riley, 1997) and lack
of situational awareness (Endsley and Kiris, 1995; Hancock et al., 2013; Parasuraman and Hancock, 2008; Wickens et al., 2016). Whether the same potential for error seen in these other operational environments applies to the more fluid environment of intelligence analysis, or in the same way, remains to be assessed (Holzer and Moses, 2015).
The IC is increasingly aware that its work is evolving from being carried out by analysts in fixed stable teams (or teams of teams) to what is described as teamwork on the fly, or “teaming” (Edmondson, 2012), whereby analysts dive in and out of teams as they are needed. These transient team memberships can improve performance, but require rapid identification of the human and AI agents with the requisite skills and resources. Traditionally, decisions about team composition have been made by humans. Recently, however, there have been preliminary attempts to use AI agents not only to participate on teams but also to assemble them (Tannenbaum et al., 2012). Some recent studies have investigated the use of AI agents to assemble “dream” or “flash” teams and even organizations on the fly (Gomez-Zara et al., 2018; Valentine et al., 2017).
___________________
22 For more information on recommender systems and flash teams, see Contractor (2013) and Tannenbaum et al. (2012).
Human–Systems Integration
In many industrial contexts, custom-developed technologies can go unused because in practice, they are either not useful for the task for which they are intended or are not usable by the intended user (Parasuraman and Riley, 1997). Technologies can even end up being disruptive to the task or have unintended consequences when they affect another part of the system in an unexpected way. Careful design and integration of system components is essential to realizing the vision of a human–machine ecosystem and to ensuring that the resulting system is an effective tool for analysis. The design of a human–machine ecosystem can leverage recent advances in social network theories23 and methods (see Chapter 5), as well as in the field of human–systems integration, to address processes and outcomes within the ecosystem.
Researchers in the field of human–systems integration draw on a robust body of work from multiple SBS and other literatures (psychology, human factors, management, occupational health and safety, human–computer interaction) to develop well-integrated sociotechnical systems (dynamic systems in which people, tasks, technology, and the environment interact throughout the stages of the work being carried out). The goal of a human–systems integration approach is to develop a resilient and adaptive system and avoid unintended consequences (National Research Council, 2007), ensuring that operational solutions, like the human–machine ecosystem, address both the needs and the capabilities and limitations of human analysts. This kind of integration cannot be added on after a human–machine
___________________
23 There is growing recognition in the research community that ecosystems can be characterized as multidimensional social networks of nodes representing both humans and nonhuman elements, such as AI agents. Networks of this sort are multirelational because they represent a wide variety of social (e.g., who knows or trusts whom) and cognitive (e.g., who thinks what others know) ties (Contractor et al., 2011).
ecosystem for the IC is developed. It needs to be a part of the process from the beginning of the ecosystem’s development so that the resulting design allows for seamless coordination among analysts and available tools and technologies.
For each of the stages of design and integration, the full range of human dimensions would be considered in light of the larger system. New technology will create a need for new training, and possibly different selection methods and different task processes (see further discussion of the analytic workforce in Chapter 8). A human–systems integration approach has the potential to improve system performance while making unexpected negative outcomes less likely. Notably, many other industries and government agencies have required the use of this approach, often after a disaster occurs that can be partially attributed to poor integration of human behavior within a sociotechnical system (e.g., Three Mile Island, the Piper Alpha, the Challenger explosion). Such an approach is not costly relative to the potential costs of failing to undertake it: poor system performance, unintended consequences, or disaster.
CONCLUSIONS
The IC has for decades sought to exploit rapid technological changes in computer networking, data storage, supercomputing, and AI that could support intelligence analysis. Looking just at AI projects, the Central Intelligence Agency (CIA) reports that nearly 140 such efforts are under way.24 Historically, as reported to the committee, the IC generally has added new technologies and tools on to a long-standing analytic process. The capabilities of AI are changing, and will continue to change, the way many industries do business. The committee believes that if the IC is to take advantage of advancing AI capabilities and adjust to evolving security threats, it will have to transform how it conducts intelligence analysis. This transformation will require not only understanding what capabilities are offered by new technologies but also understanding how analysts will function in collaboration with machines to make decisions.
CONCLUSION 7-1: To develop a human–machine ecosystem that functions effectively for intelligence analysis, it will be necessary to integrate findings from social and behavioral sciences research into the design and development of artificial intelligence and other technologies involved. A research program for this purpose would extend theory and findings from current research on human–machine interactions to new types of interactions involving multiple agents in a complex teaming environment.
The research described in this chapter will go a long way toward supporting the design of an effective human–machine ecosystem for intelligence analysis. If the IC pursues this objective, it will have to consider a number of issues. SBS research can provide answers to foundational questions necessary to support engineers and computer scientists in the design and development of such an ecosystem, including those related to the uses of technologies, measures, concepts of operation, and human–machine interaction and teaming. The use of such a system in the IC context would be unprecedented, and its responsible use will also require careful attention to a number of ethical questions. Since ethical considerations are so critical to such a system’s development and ultimate implementation, we conclude this chapter with a discussion of some of these considerations.
___________________
24 Presentation by Dawn Meyeriecks, CIA’s Deputy Director for Science and Technology, at INSA-AFCEA Intelligence Summit in September 2017 (https://www.defenseone.com/technology/2017/09/cia-technology-director-artificial-intelligence/140801 [September 2018]). Projects, many involving collaboration with external software developers, range from algorithms that automatically tag objects in video to prediction models based on big data.
A Research Program to Support Design and Development
The development of a human–machine ecosystem for intelligence analysis will need to be carefully tailored to the unique needs of the IC, and the research described in this chapter will need to be applied to the complex tasks, processes, and contexts of intelligence analysis. The success of an SBS research program in accomplishing this will rest on collaboration between the IC and the broad SBS community.
The research needed to support the design and development of human–technology analytic teams crosses many disciplines. A successful research program will foster interdisciplinary work and, to the extent possible, remain open and unclassified. It will be important for a range of researchers with a broad set of expertise to contribute to the research efforts, share results with each other, and discuss improvements to the system’s design and development. SBS researchers will also need to be able to collaborate with computer scientists and cognitive and human systems engineers to help translate research findings to practice.
The research needed will include basic, applied, and translational work and will need to be aimed at solving operational problems with strong connections to intelligence analysis. Researchers and members of the IC will need to collaborate to understand the needs the ecosystem should meet, the different functions the various team members (human and AI) should be able to perform, the kinds of interactions that will be possible, the forms of output, and many more features. The research program will also need to be an iterative one, in which findings from evaluations of results and assessments of evolving needs are continually fed into ongoing design work.
One mechanism for such a research program—particularly a program that requires the testing of hypotheses, tools, technologies, and designs in a realistic environment—is a testbed. Testbeds provide a way to test interactions at scale safely, accelerate the translation of findings from research and development to operations, and engage a wide range of researchers economically. They allow for early testing of concepts and the integration of humans and systems ahead of a finished human–machine ecosystem. However, they must be well managed to achieve such objectives. The most successful testbeds have been designed to address specific problems, and multiple testbeds might therefore be an option for carrying out all the research necessary to support the development and use of a human–machine ecosystem for intelligence analysis. For the types of human–machine interactions that need to be investigated, such a testbed could be virtual so that researchers from multiple institutions could be involved.
CONCLUSION 7-2: A social and behavioral sciences research agenda to support the development of technologies and systems for effective
human–machine teams for intelligence analysis should include, but not be limited to, the following goals:
- Apply methodologies from the vision sciences, the behavioral sciences, and human factors to advances in data visualization to improve understanding of how people extract meaning from visualizations and the functionality of tools designed to present information from large datasets.
- Use techniques from social network analysis to better understand how information can be transmitted effectively, as well as filtered among distributed teams of humans and machines, and how the need to use artificial intelligence (AI) to search and filter information can be balanced with the need to restrict access to certain information.
- Develop new modes of forecasting that incorporate human judgment with automated analyses by AI agents.
- Apply neuroscience-inspired strategies and tools to research on workload effects in a complex environment of networked human and AI agents.
- Examine the implications of ongoing system monitoring of work behaviors in terms of privacy issues, as well as potential interruptions to the intrinsic work habits of human analysts.
- Extend insights from the science of human teamwork to determine how to assemble and divide tasks among teams of humans and AI agents and measure performance in such teams.
- Identify guidelines for communication protocols for use in coordinating the sharing of information among multiple human and AI agents in ways that accommodate the needs and capabilities of human analysts and minimize disadvantages associated with interruption and multitasking in humans.
Ethical Considerations
For some, talk of machines and collaboration with AI agents can be somewhat chilling. Reasonable concerns include the prospect that, in restricted environments, there will be more opportunities for inadvertent disclosures of confidential information; that biases inherent in algorithms will negatively affect decision making; that machine-generated output may increase false positives and subsequent false alarms; and that too much trust may be placed in machines to find the emergent patterns and signals, perhaps usurping what should be functions of human analysts or occupying them with new oversight and management tasks that compete with their analytic work.
Such concerns can be addressed by systematic planning informed by research and attention to ethical considerations. As advanced as AI has become in the past few decades, it still cannot outperform humans in many regards. For cognitive tasks (e.g., chess), researchers are finding that a collaborative approach with humans and AI is far more effective than the best humans or AI agents on their own.
These important ethical issues need to be considered during the research and design phase, before a human–machine ecosystem is ready for implementation (see the discussion of standards for such research phases in Box 7-5). The primary ethical issues arise from the fact that the ecosystem would rely on semiautonomous AI agents, which, rather than being programmed to do a specific task, would be capable of performing multiple tasks of varying sophistication in an adaptive fashion. These agents would be goal-directed, respond to their environments in real time, and operate continuously (Brozek and Jakubiec, 2017), characteristics that would make them ethically distinct from more traditional machines, whose actions can be predicted based on their intended uses. AI agents in this system would
need to adapt appropriately to challenges that designers might not have anticipated in advance.
Ethicists have examined the emerging problem of how AI agents with autonomy can be designed so they act safely and in accordance with the social and ethical requirements associated with their roles (e.g., Bostrom and Yudowsky, 2011; Campolo et al., 2017). Ethicists working in this area have not yet reached consensus about how this can be accomplished. The field of AI ethics is an emerging field that is, like AI itself, evolving rapidly and in a nonlinear fashion. Some ethicists argue that the problem is best addressed by involving experts in SBS fields, engineering, and ethics in the research and design of any autonomous agent. Some have suggested that to deploy such agents ethically, it is necessary to incorporate as part of their functionality the capacity to reason ethically and respond and adapt to changing ethical norms. Ethicists are still actively debating the fundamental question of whether AI systems themselves have moral status (Bostrom and Yudowsky, 2011; Brozek and Jakubiec, 2017; IEEE Standards Association, 2016). Some of the key questions are reviewed below.
Why Is It Important to Have Ethical AI?
Semiautonomous AI agents within a human–machine ecosystem will undoubtedly affect their environment in ways both predictable and unpredictable. Issues of human safety, justice, fairness, and the like will arise for AI agents that perform cognitive tasks once possible only for humans. Thus it is reasonable to consider that the agents must also take on the social responsibilities associated with the cognitive tasks they perform. For example, if an AI agent is entrusted with making decisions, it must be subject to the expectations that its decisions are fair as well as accurate (Bostrom and Yudowsky, 2011).
Semiautonomous agents in an IC context will need to operate according to the ethical requirements of their roles and the environment. The ethical requirements for an analyst are complex and may include responsibilities that require access to sensitive information and obligations to follow procedures for high-stakes decisions. It will also be necessary to consider the norms and values of the user community, in this case the client for intelligence—the policy maker or other decision maker who will use the analysis in taking actions (Benigni et al., 2017; IEEE Standards Association, 2016).
What Limits, If Any, Should Be Placed on AI Agency?
What kinds of tasks, decisions, or actions should be reserved only for people, on ethical and moral grounds? The potential need for such limits has received attention in the case of autonomous intelligent weapons (National
Research Council and National Academy of Engineering, 2014). While no consensus has yet emerged on criteria for the appropriate agency of AI agents in other types of computing systems, such as the ecosystem envisioned here, such questions are increasingly ubiquitous (National Research Council and National Academy of Engineering, 2014; van de Voort et al., 2015). Criteria specific to the IC context will be needed. For example, a semiautonomous AI agent might be permitted access to intelligence sources, but should it be permitted access to data from sensors monitoring human agents, or should that access be limited? For what purposes should an AI agent be permitted to forward information to another agent or party within the IC, to delete information it has determined is no longer valuable, or to initiate a new line of analysis? Answering these questions will require understanding of the norms and values of the analytical workplace and the moral benefits and limits of a human–machine ecosystem.
Including semiautonomous AI agents as team members in intelligence analysis raises further issues of accountability and control. When a team fails to identify a threat because of a failing on the part of the AI agent, who should be held responsible? If team members determine that the AI agent has begun producing unpredictable and potentially unreliable results or otherwise malfunctioning, who is responsible for determining whether that agent should be audited, taken offline, or trusted? These and other organizational and management questions will need careful consideration (Bohn et al., 2004; Bostrom and Yudowsky, 2011).
To What Degree Should Humans Rely on Autonomous Agents?
Designers and users of a human–machine ecosystem will also need to consider trade-offs associated with technological dependence on the system. The more computerized and automated the environment, the more individuals will rely on technical systems (Bohn et al., 2004). But this reliance may create problems when automated systems fail, leaving analysts unable to perform important tasks usually left to the system’s AI agents. Ethical deployment of AI in a human–machine ecosystem will require attention to failsafe provisions and backup protocols.
Implementation of a human–machine ecosystem would also raise more familiar, but nonetheless important, issues of privacy and surveillance in the context of ubiquitous workplace and employee monitoring. The IC workforce is used to more workplace monitoring than is typical in most other professions. However, the use of technologies whose value rests in part on worker surveillance—for example, learning from analysts’ inputs to increase the effectiveness of analyses or monitoring for signs of mental fatigue and stress to adjust interactions so as not to overload analysts’ cognitive capacities—raises ethical concerns about privacy (Bohn et al.,
2004). It is important that such monitoring not be used for discriminatory purposes, that sensitive and confidential information be protected, and that the use of such systems not lower employee morale.
The development of appropriate limitations on the use of surveillance devices in the context of intelligence analysis will require further study. Answering questions about when and how sensor systems will be used will require careful ethical accounting to determine whether and when infringements on privacy are justified and on what grounds (Ajunwa et al., 2017).
Finally, some ethical challenges raised by human–machine ecosystems transcend the IC. Many employment sectors are already beginning to confront the challenge automation poses for workforces. The challenge of mitigating the consequences of any job loss and equipping workers with new skills in increasingly automated environments will not be unique to the IC.
CONCLUSION 7-3: The design, development, and implementation of a system of human–technology teams, which would include autonomous agents, for use in intelligence analysis raise important ethical questions regarding access to certain types of data; authority to modify, store, or transmit data; and accountability and protections when systems fail. The Intelligence Community (IC) could best ensure that such systems function in an ethical manner and prepare to address unforeseeable new ethical issues by
- from the start, incorporating into the design and development process collaborative research, involving both members of the IC and the social and behavioral sciences community, on the application of ethical principles developed in other human–technology contexts to the IC context;
- ensuring that all research supported by the IC adheres to the standards for ethical conduct of research; and
- establishing a structure for ongoing review of ethical issues that may arise as the technology develops and new circumstances arise.
REFERENCES
2015 Study Panel of the One Hundred Year Study of Artificial Intelligence. (2016). Artificial Intelligence and Life in 2030. Palo Alto, CA: Stanford University. Available: https://ai100.stanford.edu/sites/default/files/ai100report10032016fnl_singles.pdf [December 2018].
Achenbach, J. (2011). Japan’s “black swan”: Scientists ponder the unparalleled dangers of unlikely disasters. The Washington Post, March 17. Available: https://www.washingtonpost.com/national/japans-black-swan-scientists-ponder-the-unparalleled-dangers-of-unlikely-disasters/2011/03/17/ABj2wTn_story.html?utm_term=.c22f85fce8b7 [December 2018].
Adamczyk, P.D., and Bailey, B.P. (2004). If not now, when?: The effects of interruption at different moments within task execution. In CHI ‘04 Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp. 271–278). New York: Association for Computing Machinery. doi:10.1145/985692.985727.
Ajunwa, I., Crawford, K., and Schultz, J. (2017). Limitless worker surveillance. California Law Review, 105(32017), 735–776.
Alexander, E., Kohlmann, J., Valenza, R., Witmore, M., and Gleicher, M. (2014). Serendip: Topic Model-Driven Visual Exploration of Text Corpora. Paris, France: Institute of Electrical and Electronics Engineers. Available: https://graphics.cs.wisc.edu/Papers/2014/AKVWG14/Preprint.pdf [December 2018].
Altmann, E.M., Trafton, J.G., and Hambrick, D.Z. (2014). Momentary interruptions can derail the train of thought. Journal of Experimental Psychology, 143(1), 215–266.
Amir, G.J., and Lehmann, H.P. (2016). After detection: The improved accuracy of lung cancer assessment using radiologic computer-aided diagnosis. Academic Radiology, 23(2), 186–191.
Arrington, C.M., and Logan, G.D. (2004). The cost of a voluntary task switch. Psychological Science, 15(9), 610–615.
Arrington, C.M., and Logan, G.D. (2005). Voluntary task switching: Chasing the elusive homunculus. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31(4), 683–702.
Bailey, B.P., and Konstan, J.A. (2006). On the need for attention-aware systems: Measuring effects of interruption on task performance, error rate, and affective state. Computers in Human Behavior, 22(4), 685–708.
Baron, J., Mellers, B.A., Tetlock, P.E., Stone, E., and Ungar, L.H. (2014). Two reasons to make aggregated probability forecasts more extreme. Decision Analysis, 11(2), 133–145.
Bawden, D., and Robinson, L. (2008). The dark side of information: Overload, anxiety and other paradoxes and pathologies. Journal of Information Science, 35(2), 180–191.
Benigni, M.C., Joseph, K., and Carley, K.M. (2017). Online extremism and the communities that sustain it: Detecting the ISIS supporting community on Twitter. PLoS ONE, 12(12), e0181405. doi:10.1371/journal.pone.0181405.
Bhardwaj, S. (2013). Technology, and the up-skilling or deskilling conundrum. WMU Journal of Maritime Affairs, 12(2), 245–253.
Bierwirth, C., and Meisel, F. (2015). A follow-up survey of berth allocation and quay crane scheduling problems in container terminals. European Journal of Operational Research, 244(3), 675–689.
Bohn, J., Coroama, V., Langheinrich, M., Mattern, F., and Rohs, M. (2004). Living in a world of smart everyday objects—social, economic, and ethical implications. Journal of Human and Ecological Risk Assessment, 10(5), 763–786. Available: https://www.vs.inf.ethz.ch/publ/papers/hera.pdf [December 2018].
Bostrom, N., and Yudowsky, E. (2011). The ethics of artificial intelligence. In W. Ramsey, and K. Frankish (Eds.), Cambridge Handbook of Artificial Intelligence (pp. 316–334). Cambridge, UK: Cambridge University Press.
Boy, J., Rensink, R.A., Bertini, E., and Fekete, J-D. (2014). A principled way of assessing visualization literacy. IEEE Transactions on Visualization and Computer Graphics, 20(12), 1963–1972.
Braver, T.S., Reynolds, J.R., and Donaldson, D.I. (2003). Neural mechanisms of transient and sustained cognitive control during task switching. Neuron, 39(4), 713–726.
Brier, G.W. (1950). Verification of forecasts expressed in terms of probability. Monthey Weather Review, 78(1), 1–3.
Brozek, B., and Jakubiec, M. (2017). On the legal responsibility of autonomous machines. Artificial Intelligence Law, 25(3), 293–304.
Buja, A., Swayne, D.F., Littman, M.L., Dean, N., Hofmann, H., and Chen, L. (2008). Data visualization with multidimensional scaling. Journal of Computational and Graphical Statistics, 17(2), 444–472.
Cain, M.S., Adamo, S.H., and Mitroff, S.R. (2013). A taxonomy of errors in multiple-target visual search. Visual Cognition, 21(7), 899–921. doi:10.1080/13506285.2013.843627.
Caliskan, A., Bryson, J.J., and Narayanan, A. (2017). Semantics derived automatically from language corpa contain human-like biases. Science, 356(6334), 183–186.
Campolo, A., Sanfillippo, M., Whittaker, M., and Crawford, K. (2017). AI Now 2017 Report. New York: New York University. Available: https://assets.ctfassets.net/8wprhhvnpfc0/1A9c3ZTCZa2KEYM64Wsc2a/8636557c5fb14f2b74b2be64c3ce0c78/_AI_Now_Institute_2017_Report_.pdf [October 2018].
Cannon-Bowers, J.A., and Salas, E. (Eds.). (1998). Making Decisions Under Stress: Implications for Individual and Team Training. Washington, DC: American Psychological Association.
Chadwick, G.L. (2018). Final Rule Material: New and Revised Definitions. Available: https://about.citiprogram.org/wp-content/uploads/2018/07/Final-Rule-Material-New-and-Revised-Definitions.pdf [October 2018].
Chang, R., Ghoniem, M., Kosara, R., Ribarsky, W., Yang, J., Suma, E., Ziemkiewicz, C., Kern, D., and Sudjianto, A. (2007). WireVis: Visualization of categorical, time-varying data from financial transactions. In VAST ‘07 Proceedings of the 2007 IEEE Symposium on Visual Analytics Science and Technology (pp. 155–162). Washington, DC: IEEE Computer Society. doi:10.1109/VAST.2007.4389009.
Chen, J.Y.C., and Barnes, M.J. (2014). Human–agent teaming for multirobot control: A review of human factors issues. IEEE Transactions on Human-Machine Systems, 44(1), 13–29.
Chen, D., and Gomes, C.P. (2018). Bias Reduction via End-to-End Shift Learning: Application to Citizen Science. arXiv preprint arXiv:1811.00458v2.
Cohen, M.A., Dennett, D.C., and Kanwisher, N. (2016). What is the bandwidth of perceptual experience? Trends in Cognitive Science, 20(5), 324–335.
Colquhoun, W.P., and Baddeley, A.D. (1967). Influence of signal probability during pretraining on vigilance decrement. Journal of Experimental Psychology, 73(1), 153–155.
Contractor, N. (2013). Some assembly required: Leveraging Web science to understand and enable team assembly. Philosophical Transactions of the Royal Society: Mathematical, Physical and Engineering Sciences, 371(1987), 20120385. doi:10.1098/rsta.2012.0385.
Contractor, N., Monge, P.R., and Leonardi, P. (2011). Multidimensional networks and the dynamics of sociomateriality: Bringing technology inside the network. International Journal of Communication, 5, 682–720. Available: https://ijoc.org/index.php/ijoc/article/view/1131/550 [December 2018].
Cooke, N.J., Gorman, J.C., Myers, C.W., and Duran, J.L. (2013). Interactive team cognition. Cognitive Science, 37(2), 255–285. doi:10.1111/cogs.12009.
Cowan, N. (2001). The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behavioral Brain Science, 24(1), 87–114; discussion 114–185.
Cummings, M. (2014). Man versus machine or man + machine? IEEE Intelligent Systems, 62–69. Available: https://hal.pratt.duke.edu/sites/hal.pratt.duke.edu/files/u10/IS-29-05Expert%20Opinion%5B1%5D_0.pdf [December 2018].
Cummings, M.L., Pina, P., and Crandall, J.W. (2008). A Metric Taxonomy for Human Supervisory Control of Unmanned Vehicles. San Diego, CA: Association for Unmanned Vehicle Systems International. Available: https://pdfs.semanticscholar.org/d696/e4deea76c6165ad36e0bcde113b3c5f6d309.pdf [December 2018].
DeChurch, L.A., Marks, M.A., and Zaccaro, S.J. (Eds.). (2012). Multiteam Systems: An Organization Form for Dynamic and Complex Environments. New York: Routledge.
Defense Science Board. (2012). The Role of Autonomy in DoD Systems. Washington, DC: U.S. Department of Defense.
Dien, J., Kogut, P., Gwizdka, J., Hatfield, B., Gentili, R.J., Oh, H., Lo, L-C., and Jaquess, K.J. (2017). Cognitive Augmentation for Coping with Open-Source Intelligence (OSINT) Overload [White Paper]. Available: http://sites.nationalacademies.org/cs/groups/dbassesite/documents/webpage/dbasse_177283.pdf [November 2018].
Dou, W., Wang, X., Chang, R., and Ribarsky, W. (2011). ParallelTopics: A probabilistic approach to exploring document collections. In Proceedings of the IEEE Conference on Visual Analytics Science and Technology (pp. 231–240). Washington, DC: IEEE Computer Society. doi:10.1109/VAST.2011.6102461.
Dujmovi , V., Gudmundsson, J., Morin, P., and Wolle, T. (2010). Notes on large angle crossing graphs. Proceedings of the Sixteenth Symposium on Computing: The Australasian Theory, 109, 19–24.
Edmondson, A.C. (2012). Teaming: How Organizations Learn, Innovate, and Compete in the Knowledge Economy. San Francisco, CA: John Wiley & Sons.
Endsley, M. (1987). The application of human factors to the development of expert systems for advanced cockpits. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 31(12), 1388–1392. doi:10.1177/154193128703101219.
Endsley, M.R., and Kiris, E.O. (1995). The out-of-the-loop performance problem and level of control in automation. Human Factors, 37(2), 381–394.
Entin, E.E., and Serfaty, D. (1999). Adaptive team coordination. Human Factors, 41(2), 312–325. doi:10.1518/001872099779591196.
Erev, I., Wallsten, T.S., and Budescu, D.V. (1994). Simultaneous over- and underconfidence: The role of error in judgment processes. Psychological Review, 101(3), 519–527. doi:10.1037/0033-295X.101.3.519.
Evans, K.K., Birdwell, R.L., and Wolfe, J.M. (2013). If you don’t find it often, you often don’t find it: Why some cancers are missed in breast cancer screening. PLoS ONE, 8(5), e64366. doi:10.1371/journal.pone.0064366.
Fayyad, U.M., Wierse, A., and Grinstein, G.G. (2002). Information Visualization in Data Mining and Knowledge Discovery. San Francisco, CA: Morgan Kaufmann Publishers.
Ferruzzi, G., Cervone, G., Delle Monache, L., Graditi, G., and Jacobone, F. (2016). Optimal bidding in a Day-Ahead energy market for Micro Grid under uncertainty in renewable energy production. Energy, 106, 194–202. doi:10.1016/j.energy.2016.02.166.
Fetchenhauser, D., and Dunning, D. (2009). Do people trust too much or too little? Journal of Economic Psychology, 30(3), 263–276. doi:10.1016/j.joep.2008.04.006.
Fiore, S.M., Salas, E., and Cannon-Bowers, J.A. (2001). Group dynamics and shared mental model development. In M. London (Ed.), Applied in Psychology: How People Evaluate Others in Organizations (pp. 309–336). Mahwah, NJ: Lawrence Erlbaum Associates.
Fischhoff, B., Slovic, P., and Lichtenstein, S. (1978). Fault trees: Sensitivity of estimated failure probabilities to problem representation. Journal of Experimental Psychology: Human Perception and Performance, 4(2), 330–344. Available: https://www.gwern.net/docs/predictions/1978-fischhoff.pdf [December 2018].
Fong, G.T., Krantz, D.H., and Nisbett, R.E. (1986). The effects of statistical training on thinking about everyday problems. Cognitive Psychology, 18(3), 253–292.
Fraioli, F., Serra, G., and Passariello, R. (2010). CAD (computed-aided detection) and CADx (computer aided diagnosis) systems in identifying and characterising lung nodules on chest CT: Overview of research, developments and new prospects. La Radiologia Medica, 115(3), 385–402. doi:10.1007/s11547-010-0507-2.
Friendly, M., and Denis, D.J. (2001). Milestones in the History of Thematic Cartography, Statistical Graphics, and Data Visualization. Available: http://www.datavis.ca/milestones [July 2018].
Fry, B. (2007). Visualizing Data: Exploring and Explaining Data with the Processing Environment (1st ed.). Sebastopol, CA: O’Reilly Media, Inc.
Garvie, C., Bedoya, A., and Frankle, J. (2016). The Perpetual Line-Up: Unregulated Police Face Recognition in America. Georgetown Law Center on Privacy and Technology. Available: https://www.perpetuallineup.org [January 2019].
Gilovich, T., and Griffin, D.W. (2002). Heuristics and biases: Then and now. In D.G.T. Gilovich, and D. Kahneman (Eds.), Heuristics and Biases: The Psychology of Intuitive Judgment (pp. 1–18). Cambridge, UK: Cambridge University Press.
Gomez-Zara, D.A., Paras, M., Twyman, M., Ng, J., Dechurch, L., and Contractor, N. (2018). Who would you like to work with? In CHI 2018 Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems. New York: Association for Computing Machinery.
Goodrich, M.A., and Schultz, A.C. (2007). Human–robot interaction: A survey. Human–Computer Interaction, 1(3), 203–275.
Goodwin, G.F., Blacksmith, N., and Coats, M.R. (2018). The science of teams in the military: Contributions from over 60 years of research. American Psychologist, 73(4), 322–333.
Gorris, M.E., Cat, L.A., Zender, C.S., Treseder, K.K., and Randerson, J.T. (2018). Coccidioidomycosis dynamics in relation to climate in the southwestern United States. GeoHealth, 2(1), 6–24.
Green, D.M., and Swets, J.A. (1966). Signal Detection Theory and Psychophysics. New York: Wiley.
Greenes, R.A. (2014). A brief history of clinical decision support: Technical, social, cultural, economic, and governmental perspectives. In Clinical Decision Support (2nd ed.) (pp. 49–109). Oxford, UK: Elsevier. doi:10.1016/B978-0-12-398476-0.00002-6.
Grier, R., Wickens, C., Kaber, D., Strayer, D., Boehm-Davis, D., Trafton, J.G., and St. John, M. (2008). The red-line of workload: Theory, research, and design. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 52(18), 1204–1208. Los Angeles, CA: SAGE Publications.
Grudin, J. (1994). Computer-supported cooperative work: History and focus. Journal Computer, 27(5), 19–26.
Gutzwiller, R. (2014). Applied Multi-Task Management. Ph.D. Thesis. Colorado State University.
Gutzwiller, R.S., Wickens, C.D., and Clegg, B.A. (2014). Workload overload modeling: An experiment with MATB II to inform a computational model of task management. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 58(1), 849–853.
Haapalainen, E., Kim, S., Forlizzi, J.F., and Dey, A.K. (2010). Psycho-physiological measures for assessing cognitive load. In UbiComp ‘10 Proceedings of the 12th ACM International Conference on Ubiquitous Computing (pp. 301–310). New York: Association for Computing Machinery. doi:10.1145/1864349.1864395.
Halford, G.S., Baker, R., McCredden, J.E., and Bain, J.D. (2005). How many variables can humans process? Psychological Science, 16(1), 70–76.
Hall, K.L., Vogel, A.L., Huang, G.C., Serrano, K.J., Rice, E.L., Tsakraklides, S., and Fiore, S.M. (2018). The science of team science: A review of the empirical evidence and research gaps on collaboration in science. The American Psychologist, 73(4), 532–548. doi:10.1037/amp0000319.
Hancock, P.A., Jagacinski, R. J., Parasuraman, R., Wickens, C.D., Wilson, G.F., and Kaber, D.B. (2013). Human-automation interaction research: Past, present, and future. Ergonomics in Design, 21(2), 9–14.
Harrison, L., Yang, F., Franconeri, S., and Chang, R. (2014). Ranking visualizations of correlation using Weber’s law. IEEE Transactions on Visualization and Computer Graphics, 20(12), 1943–1952.
Hättenschwiler, N., Sterchi, Y., Mendes, M., and Schwaninger, A. (2018). Automation in airport security X-ray screening of cabin baggage: Examining benefits and possible implementations of automated explosives detection. Applied Ergonomics, 72, 58–68. doi:10.1016/j.apergo.2018.05.003.
Healey, C.G. (1996). Choosing effective colours for data visualization. In VIS ‘96 Proceedings of the 7th Conference on Visualization ‘96 (pp. 263–271). Los Alamitos, CA: IEEE Computer Society Press. Available: http://www.diliaranasirova.com/assets/PSYC579/pdfs/02.1-Healey.pdf [December 2018].
Heath, C., Larrick, R.P., and Klayman, J. (1998). Cognitive repairs: How organizational practices can compensate for individual shortcomings. Review of Organizational Behavior, 20, 1–37.
Helmholtz, H.V. (1924). Treatise on Physiological Optics (Translation from 3rd German ed.). J.P.C. Southall, (Ed.). Rochester, NY: The Optical Society of America.
Helton, W.S., and Russell, P.N. (2015). Rest is best: The role of rest and task interruptions on vigilance. Cognition, 134, 165–173. doi:10.1016/j.cognition.2014.10.001.
Hinski, S. (2017). Training the Code Team Leader as a Forcing Function to Improve Overall Team Performance During Simulated Code Blue Events. Ph.D. Thesis, Human Systems Engineering, Arizona State University. Available: https://repository.asu.edu/attachments/194035/content/Hinski_asu_0010E_17454.pdf [December 2018].
Hoff, K., and Bashir, M. (2015). Trust in automation: Integrating empirical evidence on factors that influence trust. Human Factors, 57(3), 407–434.
Hoffman, R.R., Johnson, M., Bradshaw, J.M., and Underbrink, A. (2013). Trust in automation. IEEE Intelligent Systems, 28(1), 84–88.
Hoffman, J.M., Dunnenberger, H.M., Hicks, J.K., Caudle, K.E., Carrillo, M.W., Freimuth, R.R., Williams, M.S., Klein, T.E., and Peterson, J.F. (2016). Developing knowledge resources to support precision medicine: Principles from the Clinical Pharmacogenetics Implementation Consortium (CPIC). Journal of the American Medical Informatics Association, 23(4), 796–801.
Holzer, J.R., and Moses, F.L. (2015). Autonomous systems in the intelligence community: Many possibilities and challenges. Studies in Intelligence, 59(1), Extracts. Available: https://www.cia.gov/library/center-for-the-study-of-intelligence/csi-publications/csi-studies/studies/vol-59-no-1/pdfs/Autonomous-Systems.pdf [December 2018].
Horsch, K., Giger, M.L., and Metz, C.E. (2008). Potential effect of different radiologist reporting methods on studies showing benefit of CAD. Academic Radiologist, 15(2), 139–152.
IEEE Standards Association. (2016). The IEEE Global Initiative for Ethical Considerations in Artificial Intelligence and Autonomous Systems. Ethically Aligned Design: A Vision for Prioritizing Wellbeing with Artificial Intelligence and Autonomous Systems, Version 1. IEEE. Available: http://standards.ieee.org/develop/indconn/ec/autonomous_systems.html [November 2018].
Iqbal, S.T., Zheng, X.S., and Bailey, B.P. (2004). Task-evoked pupillary response to mental workload in human–computer interaction. In CHI ‘04 Extended Abstracts on Human Factors in Computing Systems (pp. 1477–1480). New York: Association for Computing Machinery. doi:10.1145/985921.986094.
Iqbal, S.T., Adamczyk, P.D., Zheng, X.S., and Bailey, B.P. (2005). Towards an index of opportunity: Understanding changes in mental workload during task execution. In CHI ‘05 Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp. 311–320). New York: Association for Computing Machinery. doi:10.1145/1054972.1055016.
Jorritsma, W., Cnossen, F., and van Ooijen, P.M. (2015). Improving the radiologist–CAD interaction: Designing for appropriate trust. Clinical Radiologist, 70(2), 114–122.
Jung, M.F., Beane, M., Forlizzi, J., Murphy, R., and Vertesi, J. (2017). Robots in group context: Rethinking design, development and deployment. In Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems (pp. 1283–1288). New York: Association for Computing Machinery. doi:10.1145/3027063.3051136.
Kaber, D.B., Wright, M.C., Prinzel, L.J. III, and Clamann, M.P. (2005). Adaptive automation of human–machine system information-processing functions. Human Factors, 47(4), 730–741.
Kane, M.J., and Engle, R.W. (2003). Working-memory capacity and the control of attention: The contributions of goal neglect, response competition, and task set to Stroop interference. Journal of Experimental Psychology: General, 132(1), 47–70.
Kane, M.J., Conway, A.R.A., Hambrick, D.Z., and Engle, R.W. (2007). Variation in working memory capacity as variation in executive attention and control. In A.R.A. Conway, C. Jarrold, M.J. Kane, A. Miyake, and J.N. Towse (Eds.), Variation in Working Memory (pp. 21–48). New York: Oxford University Press.
Kay, M., and Heer, J. (2016). Beyond Weber’s law: A second look at ranking visualizations of correlation. IEEE Transactions on Visualization and Computer Graphics, 22(1), 469–478.
Keller, P.R., Keller, M.M., Markel, S., Mallinckrodt, A.J., and McKay, S. (1994). Visual cues: Practical data visualization. Computers in Physics, 8(3), 297–298.
Keller, S.A., Shipp, S., and Schroeder, A. (2016). Does big data change the privacy landscape? A review of the issues. Annual Review of Statistics and Its Application, 3, 161–180. doi:10.1146/annurev-statistics-041715-033453.
Keller, S.A., Korkmaz, G., Orr, M., Schroeder, A., and Shipp, S. (2017). The evolution of data quality: Understanding the transdisciplinary origins of data quality concepts and approaches. Annual Review of Statistics and Its Application, 4, 85–108. doi:10.1146/annurev-statistics-060116-054114.
Klare, B.F., Burge, M.J., Klontz, J.C., Vorder Bruegge, R.W., and Jain, A.K. (2012). Face recognition performance: Role of demographic information. IEEE Transactions on Information Forensics and Security, 7(6), 1789–1801. doi:10.1109/TIFS.2012.2214212.
Klein, G. (2007). Performing a project premortem. Harvard Business Review, 85, 18–19. Available: https://hbr.org/2007/09/performing-a-project-premortem [February 2019].
Kosslyn, S.M. (1989). Understanding charts and graphs. Applied Cognitive Psychology, 3(3), 185–225.
Krupinski, E.A. (1996). Visual scanning patterns of radiologists searching mammograms. Academic Radiology, 3(2), 137–144.
Lee, J., and Moray, N. (1994). Trust, self-confidence, and operators’ adaptation to automation. International Journal of Human–Computer Studies, 40(1), 153–184.
Lee, T-Y., and Shen, H-W. (2009). Visualization and exploration of temporal trend relationships in multivariate time-varying data. IEEE Transactions on Visualization and Computer Graphics, 15(6), 1359–1366. doi:10.1109/TVCG.2009.200.
Lee, C.S., Bhargavan-Chatfield, M., Burnside, E.S., Nagy, P., and Sickles, E.A. (2016). The National Mammography Database: Preliminary data. American Journal of Roentgenology, 206(4), 883–890.
Leese, M. (2014). The new profiling: Algorithms, black boxes, and the failure of anti-discriminatory safeguards in the European Union. Security Dialogue, 45(5), 494–511.
Liu, Y., Ayaz, H., and Shewokis, P. (2017). Multisubject “learning” for mental workload classification using concurrent EEG, fNIRS, and physiological measures. Frontiers in Human Neuroscience, 11, 389. doi:10.3389/fnhum.2017.00389.
Lu, J. (2016). Will medical technology deskill doctors? International Education Studies, 9(7), 130–134.
Luce, R.D. (2005). Individual Choice Behavior: A Theoretical Analysis. Mineola, NY: Dover Publications.
Luce, R.D., and Raiffa, H. (2012). Games and Decisions: Introduction and Critical Survey. New York: John Wiley & Sons.
Lungeanu, A., Carter, D.R., DeChurch, L.A., and Contractor, N.S. (2018). How team interlock ecosystems shape the assembly of scientific teams: A hypergraph approach. Communication Methods and Measures, 12(2–3), 174–198. doi:10.1080/19312458.2018.1430756.
Mackworth, J. (1970). Vigilance and Attention. Harmondsworth, UK: Penguin Books.
Macmillan, N.A., and Creelman, C.D. (2005). Detection Theory. Mahwah, NJ: Lawrence Erlbaum Associates.
Maloney, L.T., and Zhang, H. (2010). Decision-theoretic models of visual perception and action. Vision Research, 50(23), 2362–2374.
Mark, G., Gonzalez, V.M., and Harris, J. (2005). No task left behind? Examining the nature of fragmented work. In CHI ‘05 Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp. 321–330). New York: Association for Computing Machinery. doi:10.1145/1054972.1055017.
Mark, G., Gudith, D., and Klocke, U. (2008). The cost of interrupted work: More speed and stress. In CHI ‘08 Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp. 107–110). New York: Association for Computing Machinery. doi:10.1145/1357054.1357072.
Mark, G., Iqbal, S.T., Czerwinski, M., Johns, P., Sano, A., and Lutchyn, Y. (2016). Email duration, batching and self-interruption: Patterns of email use on productivity and stress. In CHI ‘16 Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems (pp. 1717–1728). New York: Association for Computing Machinery.
Mayer, R.C., Davis, J.H., and Schoorman, F.D. (1995). An integrative model of organizational trust. The Academy of Management Review, 20(3), 709–734.
McCorduck, P. (2004). Machines Who Think: A Personal Inquiry into the History and Prospects of Artificial Intelligence (2nd ed.). Natick, MA: A. K. Peters, Ltd.
McNeese, N.J., Demir, M, Cooke, N.J., and Myers, C. (2017). Teaming with a synthetic teammate: Insights into human–autonomy teaming. Human Factors, 60(2), 262–273. doi:10.1177/0018720817743223.
Mellers, B., Ungar, L., Baron, J., Ramos, J., Gurcay, B., Fincher, K., Scott, S.E., Moore, D., Atanasov, P., Swift, S.A., Murray, T., Stone, E., and Tetlock, P.E. (2014). Psychological strategies for winning a geopolitical forecasting tournament. Psychological Science, 25(5), 1106–1115. doi:10.1177/0956797614524255.
Mellers, B., Stone, E., Atanasov, P., Rohrbaugh, N., Metz, S.E., Ungar, L., Bishop, M.M., Horowitz, M., Merkle, E., and Tetlock, P. (2015). The psychology of intelligence analysis: Drivers of prediction accuracy in world politics. Journal of Experimental Psychology: Applied, 21(1), 1–14. Available: https://www.apa.org/pubs/journals/releases/xap-0000040.pdf [December 2018].
Mitroff, S.R., and Biggs, A.T. (2014). The ultra-rare-item effect: Visual search for exceedingly rare items is highly susceptible to error. Psychology Science, 25(1), 284–289.
Mittelstadt, B.D., Allo, P., Taddeo, M., Wachter, S., and Floridi, L. (2016). The ethics of algorithms: Mapping the debate. Big Data & Society, 1–21. doi:10.1177/2053951716679679.
Monaghan, A.J., Morin, C.W., Steinhoff, D.F., Wilhelmi, O., Hayden, M., Quattrochi, D.A., Reiskind, M., Lloyd, A.L., Smith, K., Schmidt, C.A., Scalf, P.E., and Ernst K. (2016). On the seasonal occurrence and abundance of the Zika virus vector mosquito Aedes aegypti in the contiguous United States. PLoS Currents, 8. doi:10.1371/currents. outbreaks.50dfc7f46798675fc63e7d7da563da76.
Monsell, S. (2003). Task switching. Trends in Cognitive Sciences, 7(3), 134–140.
Moore, P., and Piwek, L. (2017). Regulating wellbeing in the brave new quantified workplace. Employee Relations, 39(3), 308–316.
Nakamura, L. (2013). Cybertypes: Race, Ethnicity, and Identity on the Internet. New York: Routledge.
National Academies of Sciences, Engineering, and Medicine (NASEM). (2016). From Maps to Models: Augmenting the Nation’s Geospatial Intelligence Capabilities. Washington, DC: The National Academies Press. doi:10.17226/23650.
NASEM. (2017a). Challenges in Machine Generation of Analytic Products from Multi-Source Data: Proceedings of a Workshop. Washington, DC: The National Academies Press. doi:10.17226/24900.
NASEM. (2017b). Strengthening Data Science Methods for Department of Defense Personnel and Readiness Missions. Washington, DC: The National Academies Press. doi:10.17226/23670.
NASEM. (2018a). Artificial Intelligence and Machine Learning to Accelerate Translational Research: Proceedings of a Workshop—in Brief. Washington, DC: The National Academies Press. doi:10.17226/25197.
NASEM. (2018b). Learning Through Citizen Science: Enhancing Opportunities by Design. Washington, DC: The National Academies Press.
NASEM. (2018c). Learning from the Science of Cognition and Perception for Decision Making: Proceedings of a Workshop. Washington, DC: The National Academies Press. doi:10.17226/25118.
NASEM. (2018d). Emerging Trends and Methods in International Security: Proceedings of a Workshop. Washington, DC: The National Academies Press. doi:10.17226/25058.
National Research Council. (1951). Human Engineering for an Effective Air Navigation and Traffic Control System. Washington, DC: National Academy Press. Available: https://apps.dtic.mil/dtic/tr/fulltext/u2/b815893.pdf [February 2019].
National Research Council. (2007). Human–System Integration in the System Development Process: A New Look. Washington, DC: National Academies Press. doi:10.17226/11893.
National Research Council. (2013). Frontiers in Massive Data Analysis. Washington, DC: The National Academies Press. doi:10.17226/18374.
National Research Council. (2014). Complex Operational Decision Making in Networked Systems of Humans and Machines: A Multidisciplinary Approach. Washington, DC: The National Academies Press. doi:10.17226/18844.
National Research Council. (2015). Enhancing the Effectiveness of Team Science. Washington, DC: The National Academies Press. doi:10.17226/19007.
National Research Council and National Academy of Engineering. (2014). Emerging and Readily Available Technologies and National Security: A Framework for Addressing Ethical, Legal, and Societal Issues. Washington, DC: The National Academies Press. doi:10.17226/18512.
Newell, S., and Marabelli, M. (2015). Strategic opportunities (and challenges) of algorithmic decision-making: A call for action on the long-term societal effects of “datification”. The Journal of Strategic Information Systems, 24(1), 3–14.
Nicolas-Alonso, L.F., and Gomez-Gil, J. (2012). Brain computer interfaces: A review. Sensors, 12(2), 1211–1279. doi:10.3390/s120201211.
Nishikawa, R.M., Schmidt, R.A., Linver, M.N., Edwards, A.V., Papaioannou, J., and Stull, M.A. (2012). Clinically missed cancer: How effectively can radiologists use computer-aided detection? American Journal of Roentgenology, 198(3), 708–716. doi:10.2214/AJR.11.6423.
Noah, B., Keller, M.S., Mosadeghi, S., Stein, L., Johl, S., Delshad, S., Tashjian, V.C., Lew, D., Kwan, J.T., Jusufagic, A., and Spiegel, B.M.R. (2018). Impact of remote patient monitoring on clinical outcomes: An updated meta-analysis of randomized controlled trials. npj Digital Medicine, 1(1), 20172.
Nodine, C.F., and Kundel, H.L. (1987). Using eye movements to study visual search and to improve tumor detection. RadioGraphics, 7(6), 1241–1250. doi:10.1148/radiographics.7.6.3423330.
Noë, A., Pessoa, L., and Thompson, E. (2000). Beyond the grand illusion: What change blindness really teaches us about vision. Visual Cognition, 7(1), 93–106.
Oberlander, E.M., Oswald, F.L., Hambrick, D.Z., and Jones, L.A. (2007). Individual Difference Variables as Predictors of Error during Multitasking. No. NPRST-TN-07-9. Millington, TN: Navy Personnel Research Studies and Technology.
O’Leary, M.B., Mortensen, M., and Woolley, A.W. (2011). Multiple team membership: A theoretical model of its effects on productivity and learning for individuals and teams. Academy of Management Review, 36(3), 461–478.
O’Rourke, D. (2014). The science of sustainable supply chains. Science, 344(6188), 1124–1127.
Osoba, O., and Welser, IV, W. (2017). An Intelligence in Our Image: The Risks of Bias and Errors in Artificial Intelligence. Santa Monica, CA: RAND Corporation.
Parasuraman, R. (2000). Designing automation for human use: Empirical studies and quantitative models. Ergonomics, 43(7), 931–951.
Parasuraman, R., and Manzey, D.H. (2010). Complacency and bias in human use of automation: An attentional integration. Human Factors, 52(3), 381–410.
Parasuraman, R., and Hancock, P.A. (2008). Mitigating the adverse effects of workload, stress, and fatigue with adaptive automation. In P.A. Hancock, and J.L. Szalma (Eds.), Performance Under Stress (pp. 45–58). Burlington, VT: Ashgate.
Parasuraman, R., and Riley, V. (1997). Humans and automation: Use, misuse, disuse, abuse. Human Factors, 39(2), 230–253.
Parasuraman, R., Sheridan, T.B., and Wickens, C.D. (2000). A model for types and levels of human interaction with automation. IEEE Transactions on Systems, Man, and Cybernetics—Part A: Systems and Humans, 30(3), 286–297. doi:10.1109/3468.844354.
Pashler, H. (2000). Task switching and multitask performance. In S. Monsell, and J. Driver (Eds.), Attention and Performance XVIII: Control of Mental Processes (Ch. 12) (pp. 277–307). Cambridge, MA: MIT Press. Available: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.408.7509&rep=rep1&type=pdf [December 2018].
Phillips, C., Wood, T., and Lewis, S. (2017). An Integrated Approach to Language Capabilities in Humans and Technology [White Paper]. Available: http://sites.nationalacademies.org/cs/groups/dbassesite/documents/webpage/dbasse_179909.pdf [December 2018].
Poole, M.S., and Contractor, N.S. (2012). Conceptualizing the multiteam system as an ecosystem of networked groups. In S.J. Zaccaro, M.A. Marks, and L.A. DeChurch (Eds.), Multiteam Systems: An Organizational Form for Dynamic and Complex Environments (pp. 193–224). New York: Routledge Academic.
Portmess, L., and Tower, S. (2014). Data barns, ambient intelligence and cloud computing: The tacit epistemology and linguistic representation of Big Data. Ethics and Information Technology, 17(1), 1–9.
Puma, S., Matton, N., Paubel, P.V., Raufaste, É., and El-Yagoubi, R. (2018). Using theta and alpha band power to assess cognitive workload in multitasking environments. International Journal of Psychophysiology, 123, 111–120. doi:10.1016/j.ijpsycho.2017.10.004.
Pylyshyn, Z., and Storm, R.W. (1988). Tracking multiple independent targets: Evidence for a parallel tracking mechanism. Spatial Vision, 3(3), 179–197.
Rahlf, T. (2017). Data Visualization with R: 100 Examples. Cham, Switzerland: Springer International. doi:10.1007/978-3-319-49751-8.
Rajivan, P., and Cooke, N.J. (2017). Impact of team collaboration on cybersecurity situational awareness. In P. Liu, S. Jajodia, and C. Wang (Eds.), Theory and Models for Cyber Situation Awareness (pp. 203–226). Cham, Switzerland: Springer International Publishing. doi:10.1007/978-3-319-61152-5.
Rajivan, P., and Cooke, N.J. (2018). Information pooling bias in collaborative security incident correlation analysis. Human Factors, 60(5), 626–639. doi:10.1177/0018720818769249.
Rasmussen, J. (1983). Skills, rules, and knowledge: Signals, signs, and symbols, and other distinctions in human performance models. IEEE Transactions on Systems, Man, and Cybernetics, 13(3), 257–266.
Robert, L.P. (2018). Motivational theory of human robot teamwork. International Robotics & Automation Journal, 4(4), 248–251.
Rohrbaugh, J.W. (2017). Ambulatory and non-contact recording methods. In J.T. Cacioppo, L.G. Tassinary, and G.G. Berntson (Eds.), Handbook of Psychophysiology (4th ed.) (pp. 300–338). New York: Cambridge University Press.
Rosenbalt, A., Kneese, T., and Boyd, D. (2014). Workplace Surveillance. Data & Society Research Institute. Available: https://datasociety.net/pubs/fow/WorkplaceSurveillance.pdf [December 2018].
Russell, S., and Norvig, P. (2010). Artificial Intelligence, A Modern Approach (3rd ed.). Upper Saddle River, NJ: Pearson Education, Inc.
Sagan, P., and McCormick, H.W. (2017). Multi-Disciplinary Studies of Probability Perception Contribute to Engineering & Exploiting Predictive Analytic Technologies [White Paper]. Available: http://sites.nationalacademies.org/cs/groups/dbassesite/documents/webpage/dbasse_176650.pdf [February 2019].
Salas, E., and Fiore, S.M. (Eds.) (2004). Team Cognition: Understanding the Factors That Drive Process and Performance. Washington DC: American Psychological Association.
Salas, E., Dickinson, T.L., Converse, S.A., and Tannenbaum, S.I. (1992). Toward an understanding of team performance and training. In R.W. Swezey and E. Salas (Eds.), Teams: Their Training and Performance (pp. 3–29). Norwood, NJ: Ablex.
Salas, E., Cooke, N.J., and Rosen, M.A. (2008). On teams, teamwork and team performance: Discoveries and developments. Human Factors: Golden Anniversary Special Issue, 50(3), 540–547. doi:10.1518/001872008X288457.
Satopää, V.A., Baron, J., Foster, D.P., Mellers, B.A., Tetlock, P.E., and Ungar, L.H. (2014a). Combining multiple probability predictions using a simple logit model. International Journal of Forecasting, 30(2), 344–356.
Satopää, V.A., Jensen, S.T., Mellers, B.A., Tetlock, P.E., and Ungar, L.H. (2014b). Probability aggregation in time-series: Dynamic hierarchical modeling of sparse expert beliefs. The Annals of Applied Statistics, 8(2), 1256–1280.
Shankar, S., Halpern, Y., Breck, E., Atwood, J., Wilson, J., and Sculley, D. (2017). No Classification without Representation: Assessing Geodiversity Issues in Open Data Sets for the Developing World. arXiv preprint arXiv:1711.08536. Available: https://ai.google/research/pubs/pub46553 [December 2018].
Shapiro, M. (2010). Once upon a stacked time series. In J. Steele and N. Iliinsky (Eds.), Beautiful Visualization: Looking at Data through the Eyes of Experts (pp. 15–36). Sebastopol, CA: O’Reilly Media.
Shell, E.R. (2018). The employer-surveillance state. The Atlantic, October 15.
Shupp, L., Andrews, C., Dickey-Kurdziolek, M., Yost, B., and North, C. (2009). Shaping the display of the future: The effects of display size and curvature on user performance and insights. Human–Computer Interaction, 24(1-2), 230–272.
Siddiqi, A., Ereiqat, F., and Anadon, L.D. (2016). Formulating expectations for future water availability through infrastructure development decisions in arid regions. Systems Engineering, 19(2), 101–110.
Siebert, J., Strobl, B., Etter, S., Vis, M., Ewen, T., and van Meerveld, H. (2017). Engaging the public in hydrological observations-first experiences from the CrowdWater project. EGU General Assembly Conference Abstracts, 19, 11592.
Simons, D.J., and Chabris, C.F. (1999). Gorillas in our midst: Sustained inattentional blindness for dynamic events. Perception, 28(9), 1059–1074.
Simons, D.J., and Levin, D.T. (1998). Failure to detect changes to people during a real-world interaction. Psychonomic Bulletin & Review, 5(4), 644–649.
Slovic, P., Fischhoff, B., and Lichtenstein, S. (1980). Facts and fears: Understanding perceived risk. In Societal Risk Assessment (pp. 181–216). Boston, MA: Springer.
Smith, G., Baudisch, P., Robertson, G., Czerwinski, M., Meyers, B., Robbins, D., and Andrews, D. (2003). GroupBar: The TaskBar Evolved. Available: http://rajatorrent.com.patrickbaudisch.com/publications/2003-Smith-OZCHI03-GroupBar.pdf [November 2018].
Sperling, G., and Dosher, B.A. (1986). Strategy and optimization in human information processing. In Basic Sensory Process I (pp. 2.1–2.65). Available: https://pdfs.semanticscholar.org/ba80/4c88813e27bcb225475054f947eb0ef3a934.pdf [December 2018].
Sperling, G., and Melchner, M.J. (1978). The attention operating characteristic: Examples from visual search. Science, 202(4365), 315–318.
Stasser, G., Vaughan, S., and Stewart, D. (2000). Pooling unshared information: The benefits of knowing how access to information is distributed among group members. Organizational Behavior and Human Decision Processes, 82(1), 102–116.
Steele, J., and Iliinsky, N. (2010). Beautiful Visualization: Looking at Data through the Eyes of Experts. Sebastopol, CA: O’Reilly Media.
Stone, M., Szafir, D.A., and Setlur, V. (2014). An Engineering Model for Color Difference as a Function of Size. Available: https://graphics.cs.wisc.edu/Papers/2014/SAS14/2014CIC_48_Stone_v3.pdf [December 2018].
Strayer, D.L., Cooper, J.M., Turrill, J., Coleman, J.R., and Hopman, R.J. (2016). Talking to your car can drive you to distraction. Cognitive Research: Principles and Implications, 1(16). doi:10.1186/s41235-016-0018-3.
Strobach, T., Liepelt, R., Schubert, T., and Kiesel, A. (2012). Task switching: Effects of practice on switch and mixing costs. Psychological Research, 76(1), 74–83.
Suchow, J.W., Fougnie, D., Brady, T.F., and Alvarez, G.A. (2014). Terms of the debate on the format and structure of visual memory. Attention, Perception & Psychophysics, 76(7), 2071–2079. doi:10.3758/s13414-014-0690-7.
Sullivan, B.L., Aycrigg, J.L., Barry, J.H., Bonney, R.E., Bruns, N., Cooper, C.B., Damoulas, T., Dohndt, A.A., Dietterich, T., Farnsworth, A., Fink, D., Fitzpatrick, J.W., Fredericks, T., Gerbracht, J., Gomes, C., Hochachka, W.M., Iliff, M.J., Lagoze, C., La Sorte, F.A., Merrifield, M., Morris, W., Phillips, T.B., Reynolds, M., Rodewald, A.D., Rosenberg, K.V., Trautmann, N.M., Wiggins, A., Winkler, D.W., Wong, W-K., Wood, C.L., Yu, J., and Kelling, S. (2014). The eBird enterprise: An integrated approach to development and application of citizen science. Biological Conservation, 169, 31–40. doi:10.1016/j. biocon.2013.11.003.
Swan, M. (2013). The quantified self: Fundamental disruption in big data science and biological discovery. Big Data, 1(2), 85–110.
Szafir, D.A., Haroz, S., Gleicher, M., and Franconeri, S. (2016a). Four types of ensemble coding in data visualizations. Journal of Vision, 16(5), 11. doi:10.1167/16.5.11.
Szafir, D.A., Stuffer, D., Sohail, Y., and Gleicher, M. (2016b). TextDNA: Visualizing Word Usage with Configurable Colorfields. Available: https://graphics.cs.wisc.edu/Papers/2016/ASSG16/TextDNA.pdf [December 2018].
Tannenbaum, S.I., Mathieu, J.E., Salas, E., and Cohen, D. (2012). Teams are changing: Are research and practice evolving fast enough? Industrial and Organizational Psychology, 5(1), 2–24. doi:10.1111/j.1754-9434.2011.01396.x.
Tetlock, P.E. (2017). Expert Political Judgment: How Good Is It? How Can We Know? Princeton, NJ: Princeton University Press.
Tetlock, P.E., Mellers, B.A., Rohrbaugh, N., and Chen, E. (2014). Forecasting tournaments: Tools for increasing transparency and improving the quality of debate. Current Directions in Psychological Science, 23(4), 290–295.
Thomson, D.R., Smilek, D., and Besner, D. (2015). Reducing the vigilance decrement: The effects of perceptual variability. Conscious Cognition, 33, 386–397. doi:10.1016/j. concog.2015.02.010.
Tuddenham, W.J. (1962). Visual search, image organization, and reader error in roentgen diagnosis: Studies of the psycho-physiology of roentgen image perception. Radiology, 78, 694–704. doi:10.1148/78.5.694.
Tufte, E.R. (2003). The Cognitive Style of PowerPoint. Cheshire, CT: Graphics Press.
Tufte, E.R. (2006). Beautiful Evidence (Vol. 1). Cheshire, CT: Graphics Press.
Tufte, E.R., and Graves-Morris, P. (2014). The Visual Display of Quantitative Information. Cheshire, CT: Graphics Press.
Tufte, E.R., and Robins D. (1997). Visual Explanations. Cheshire, CT: Graphics Press.
Tufte, E.R., McKay, S.R., Christian W., and Matey, J.R. (1998). Visual explanations: Images and quantities, evidence and narrative. Computers in Physics, 12, 146. doi:10.1063/1.168637.
Turner, B.M., Steyvers, M., Merkle, E.C., Budescu, D.V., and Wallsten, T.S. (2014). Forecast aggregation via recalibration. Machine Learning, 95(3), 261–289.
Tutt, A. (2016). An FDA for Algorithms. SSRN Scholarly Paper. Rochester, NY: Social Science Research Network. Available: http://papers.ssrn.com/abstract=2747994 [December 2018].
Tversky, A., and Kahneman, D. (1974). Judgment under uncertainty: Heuristics and biases. Science, 185(4157), 1124–1131.
Unsworth, N., and Engle, R.W. (2007). The nature of individual differences in working memory capacity: Active maintenance in primary memory and controlled search from secondary memory. Psychological Review, 114(1), 104–132. doi:10.1037/0033-295X.114.1.104.
Valentine, M.A., Retelny, D., To, A., Rahmati, N., Doshi, T., and Bernstein, M.S. (2017). Flash organizations: Crowdsourcing complex work by structuring crowds as organizations. In CHI ‘17 Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems (pp. 3523–3537). New York: Association for Computing Machinery. Available: https://hci.stanford.edu/publications/2017/flashorgs/flash-orgs-chi-2017.pdf [December 2018].
van de Voort, M., Pieters, W., and Consoli, L. (2015). Refining the ethics of computer-made decisions: A classification of moral mediation by ubiquitous machines. Ethics of Information Technology, 17(1), 41–56. doi:10.1007/s10676-015-9360-2.
Vogel, E.K., and Machizawa, M.G. (2004). Neural activity predicts individual differences in visual working memory capacity. Nature, 428(6984), 748–751.
Wainer, H. (1992). Understanding graphs and tables. Educational Researcher, 21(1), 14–23.
Wegner, D.M. (1987). Transactive memory: A contemporary analysis of the group mind. In B. Mullen and G.R. Goethals (Eds.), Theories of Group Behavior (pp. 185–208). New York: Springer-Verlag.
Wickens, C.D. (2008). Multiple resources and mental workload. Human Factors, 50(3), 449–455.
Wickens, C.D. (2010). Multiple resources and performance prediction. Theoretical Issues in Ergonomics Science, 3(2), 159–177. doi:10.1080/14639220210123806.
Wickens, C.D., Gutzwiller, R.S., and Santamaria, A. (2015). Discrete task switching in overload: A meta-analyses and a model. International Journal of Human–Computer Studies, 79, 79–84. doi:10.1016/j.ijhcs.2015.01.002.
Wickens, C.D., Gutzwiller, R.S., Vieane, A., Clegg, B.A., Sebok, A., and Janes, J. (2016). Time sharing between robotics and process control: Validating a model of attention switching. Human Factors, 58(2), 322–343.
Williams, H.J., and Blum, I. (2018). Defining Second Generation Open Source Intelligence (OSINT) for the Defense Enterprise. Santa Monica, CA: RAND Corporation. Available: https://www.rand.org/pubs/research_reports/RR1964.html [December 2018].
Witlin, L. (2008). Of note: Mirror-imaging and its dangers. SAIS Review of International Affairs 28(1), 89–90.
Wittenbaum, G.M, Hollingshead, A.B., and Botero, I.C. (2004). From cooperative to motivated information sharing in groups: Moving beyond the hidden profile paradigm. Communication Monographs, 71(3), 286–310. doi:10.1080/0363452042000299894.
Wolfe, J.M. (2003). Moving towards solutions to some enduring controversies in visual search. Trends in Cognitive Sciences, 7(2), 70–76.
Wolfe, J.M., and Van Wert, M. (2010). Varying target prevalence reveals two dissociable decision criteria in visual search. Current Biology, 20(2), 121–124. doi:10.1016/j. cub.2009.11.066.
Wolfe, J.M., Horowitz, T.S., and Kenner, N.M. (2005). Rare targets are often missed in visual search. Nature, 435(7041), 439–440.
Wolfe, J.M., Brunelli, D.N., Rubinstein, J., and Horowitz, T.S. (2013). Prevalence effects in newly trained airport checkpoint screeners: Trained observers miss rare targets, too. Journal of Vision, 13(3), 33. doi:10.1167/13.3.33.
Yost, B., and North C. (2006). The perceptual scalability of visualization. IEEE Transactions on Visualization and Computer Graphics, 12(5), 837–844.
Yudkowsky, E. (2011). Cognitive biases potentially affecting judgment of global risks. In N. Bostrom, and M. Cirkovic (Eds.), Global Catastrophic Risks (pp. 91–119). New York: Oxford University Press.
Zhang, H.Y., Ji, P., Wang, J.Q., and Chen, X.H. (2017). A novel decision support model for satisfactory restaurants utilizing social information: A case study of TripAdvisor.com. Tourism Management, 59, 281–297. doi:10.1016/j.tourman.2016.08.010.
This page intentionally left blank.
































































