
Randomization, by its nature, minimizes the effect of unmeasured confounders and other biases and allows straightforward inferences to be made from the gathered data. However, it is not always feasible and can be costly. When using observational data, what are ways to account for these biases and unmeasured confounders? What steps can be taken to ensure that the results from observational research are sound? In these sessions, participants explored these questions and heard from speakers who have developed methods to gain confidence in unrandomized observational comparisons. Throughout the presentations and discussions, workshop participants also heard an alternative perspective from some speakers who emphasized the continuing importance of randomization and discussed methods to make randomization easier in real-world settings.
ILLUSTRATIVE EXAMPLES
To explore the issues surrounding bias in observational comparisons, speakers at the second and third workshops presented case studies as illustrative examples of the considerations that go into designing and conducting observational data analyses.
Health Care Databases for Regulatory Decision Making
Data for effectiveness research in health care, said Sebastian Schneeweiss, professor of medicine and epidemiology at Harvard Medical School and Brigham & Women’s Hospital, can come from a number of different sources (see Figure 9-1). The first categorization, Schneeweiss said at the second workshop in this series, is between traditional randomized controlled trials (RCTs) and non-interventional studies. Within non-interventional studies, there are two major different sources of data, he said. One source is primary data that are generated for the purpose of conducting research on individuals and the investigator controls what, how, and when to measure; the other source is transactional data that are generated for other purposes, but used secondarily for research. Within transactional data, there are numerous cate-
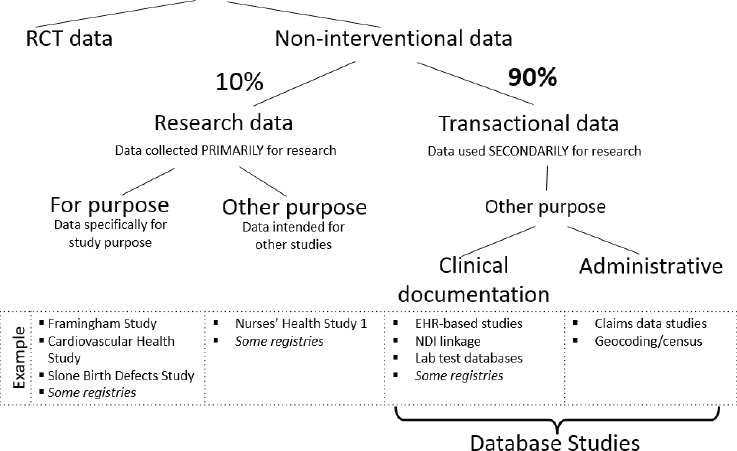
NOTE: EHR = electronic health record; NDI = National Death Index; RCT = randomized controlled trial.
SOURCES: Schneeweiss presentation, March 6, 2018; Franklin and Schneeweiss, 2017.
gories: electronic health records, laboratory results, and administrative data such as insurance claims. Schneeweiss said that in pharmacoepidemiology, approximately 90 percent of research is done with these types of transactional data.
Schneeweiss walked workshop participants through the process of using transactional data for research. First, he said, there is a dynamic database that records an ongoing stream of new health care records for all enrolled patients. These data are stabilized into a “snapshot” for research purposes. This ensures that the research will be replicable if the analysis is run again, said Schneeweiss. The study rules are then applied to all of the health encounters of individual patients (e.g., hospitalizations, diagnoses, procedures).
Real-world data (RWD) have four different potential uses in regulatory decision making, said Schneeweiss. RWD can be used as synthetic control arms for single-arm trials for primary approval. RWD can be collected and analyzed for secondary indications—such as a different outcome or different population—for a product that is already on the market. RWD can also be used as part of the initial approval process, when the indication has been
based on surrogate endpoints with the understanding that evidence of clinical endpoints will be generated before the product receives full approval. Finally, RWD can be used for safety assessment and monitoring, either in the immediate postmarket time frame, or if a safety concern has arisen later in the product’s lifetime.
Schneeweiss provided several examples of results from database studies that came to the same causal conclusion as RCTs (Connolly et al., 2009; Fergusson et al., 2008; Fralick et al., 2017; Giles et al., 2016; Kim et al., 2017; Neal et al., 2017; Patorno et al., 2018; Schneeweiss et al., 2008; Seeger et al., 2015; Zinman et al., 2015). Schneeweiss pointed out that in these examples, a new-user, active-comparator design was chosen; determining why these database studies and RCTs came to the same conclusion would be key to indicating when database studies could be appropriate and reliable in future research. More importantly, said Schneeweiss, “How confident can we be that a new database study will generate results that are comparable to those from an RCT?” Confidence in non-experimental database studies, said Schneeweiss, depends on two factors. The first is whether the study examines beneficial effects or harmful effects, and second, whether it looks for the intended treatment effect or discovers unintended effects (see Figure 9-2). Depending on the answers to these questions, said Schneeweiss, the a priori confidence level in RWD will be higher or lower. For example, confidence in RWD is higher when the study finds an unintended (and unknown) effect, in part because the provider is “blinded” to the effect so the confounding is less strong, he said.
There are three reasons, said Schneeweiss, why researchers prefer RCTs to observational studies. First, and most obvious, is that RCTs use random treatment assignment. Second, there is controlled outcome measurement. Third, the implementation of RCTs is clear and easy to understand. Schneeweiss emphasized that “sweat and tears” go into the design of an RCT, but the actual analysis is quite straightforward compared to the complex analytics used in database studies. Despite these advantages of RCTs, Schneeweiss offered his perspective on when a researcher might feel comfortable conducting a database study instead:
- First, an active comparator is preferred. Using a database to study the difference between two active treatments is far easier than comparing a treatment to patients who did not receive treatment because “there is usually a reason why they did not get treated.”
- The second requirement for a valid database study is that outcomes and exposures need to be measurable and observable in the data.
- Finally, the key confounding variables need to also be measurable and observable in the system.
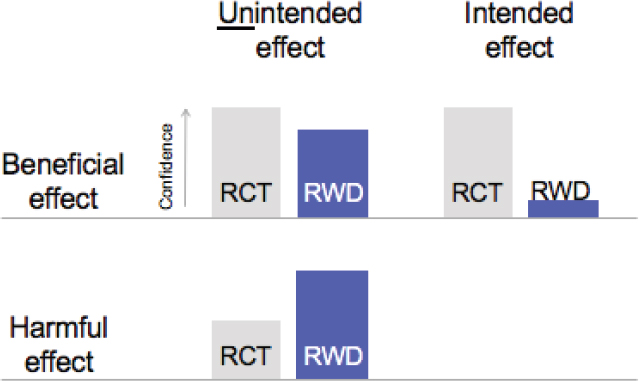
NOTE: RCT = randomized controlled trial; RWD = real-world data.
SOURCE: Schneeweiss presentation, March 6, 2018.
There are research questions that need to be answered by RCTs, and research questions that can be answered through RWD analyses, said Schneeweiss. There is an unknown area of overlap between the two. “If you can identify that group of questions that are relevant for decision makers and that we feel confident we can answer without randomization” and without putting patients at risk, RWD analysis could be used with high confidence, he said.
Schneeweiss presented a possible pathway for deciding to conduct RWD analysis. At each step along the pathway, if the answer to a question is “no,” an RCT would be more appropriate. Schneeweiss described the checkpoints along the pathway:
- Is the setting adequate for an RWD analysis?
- Is data quality fit for purpose?
- Is the data analysis plan based on epidemiologic study design principles?
- Was balance in confounding factors among treatment groups achieved?
Zostavax Vaccine Effectiveness and Duration of Effectiveness Project
Hector Izurieta, epidemiologist at the Office of Biostatistics and Epidemiology at the U.S. Food and Drug Administration’s (FDA’s) Center for
Biologics Evaluation and Research, described a real-world study on the effectiveness and duration of effectiveness of the herpes zoster—commonly known as shingles—vaccine, Zostavax (Izurieta et al., 2017). The study used data on Medicare Part D beneficiaries and compared outcomes of those who had been vaccinated with those who had not received the vaccine. Outcomes included herpes zoster and ophthalmic zoster (a subtype of shingles in which the characteristic rash presents at the forehead and around the eyes) medical office visits, postherpetic neuralgia, and herpes zoster hospitalization. The researchers, said Izurieta, used Cox regression models to estimate the risks of herpes zoster and postherpetic neuralgia in the vaccinated and unvaccinated populations, adjusted for the main known characteristics, and measured the risk at different time intervals because vaccine protection varies over time.
After this basic overview of the study, Izurieta went through the draft decision aid (see Figure 9-5 later in this chapter) and discussed each question included in the decision aid.
What Are the Clinical and Epidemiologic Justifications for the Comparator Selected (and the Margin, If Applicable)?
Despite previous clinical trials, questions regarding the effectiveness of the vaccine and the duration of effectiveness lingered, said Izurieta. This study demonstrated effectiveness, and was also among the first studies to examine postherpetic neuralgia and hospitalization for herpes zoster, he said.
Where Has the Study Been Registered Prior to Initiation (e.g., ClinicalTrials.gov)? If It Is a Regulatory Study, or a Study Initiated by a Regulatory Agency, Which Regulatory Agencies Have Examined the Protocol?
The study was not registered prior to implementation. As regulators, said Izurieta, the researchers worked within the team to prepare the protocol and analyze the data according to the prespecified protocol; they considered this to be appropriate for the time.
How Can Reporting Be Structured to Enable Replication by a Regulator or Another Research Team?
To facilitate replication, said Izurieta, the researchers published appendixes and supplementary material that included all of the covariates used, all of the codes used, and all of the analyses and subanalyses for the groups.
Does There Appear to Be Appropriate Balance Between the Treatment Cohorts After Matching/Weighting? After Matching or Weighting for Balance, Do the Analytic Cohorts Appear to Represent Clinically Meaningful Groups for Study (e.g., Has Utility or Generalizability Been Sacrificed)?
To achieve balance, Izurieta and his colleagues adopted an approach developed by Rubin and Thomas (2000) that combines propensity scores and Mahalanobis metric matching. This approach, said Izurieta, allowed adjustment for heterogeneity between variables and controls, using a broad list of covariates that are plausibly related to herpes zoster, while generating cohorts that are closely matched on a subset of key covariates. The researchers used propensity scoring to adjust for covariates, including demographic factors, socioeconomic conditions, health care usage characteristics, and frailty characteristics. Mahalanobis distance was used to match essential covariates, including age, gender, race, and low-income subsidy. The database that was used, said Izurieta, included about 1 million people who had been vaccinated, and about 7 million who had not been vaccinated. This disproportion allowed the researchers to use nearly all of the vaccinated individuals and to be very selective about choosing non-vaccinated individuals for one-to-one matching, said Izurieta. For each vaccine recipient, a control population was found whose propensity scores fell within an acceptable range. Among these beneficiaries, one vaccine recipient was matched to one control with the minimum Mahalanobis distance from the vaccine recipient. Researchers used standardized mean difference statistics and falsification outcomes in order to assess cohort balance.
Before matching, the two populations were different with respect to key covariates. For example, the unvaccinated population was slightly older, was more racially diverse, and was more likely to receive low-income subsidies. These differences resulted in variations in the propensity score distribution between groups, said Izurieta (see Figure 9-3). After using the two-step matching process with propensity scores and Mahalanobis distance, the propensity score distributions were “wonderfully consistent” for all covariates (see Figure 9-4).
Are There Specific Unmeasured Confounders Thought to Be Sufficiently Influential That They Might Alter the Statistical Inference from the Study? Is There a Supplemental Way to Measure These Confounders? If Not, Can Sensitivity Analyses Be Designed to Examine Their Potential Influence?
While the cohort was well matched on many important covariates, said Izurieta, the problem of unmeasured confounders still existed. For example, vaccine recipients might seek health care more readily than non-vaccinated individuals. To address this issue, the researchers conducted a secondary
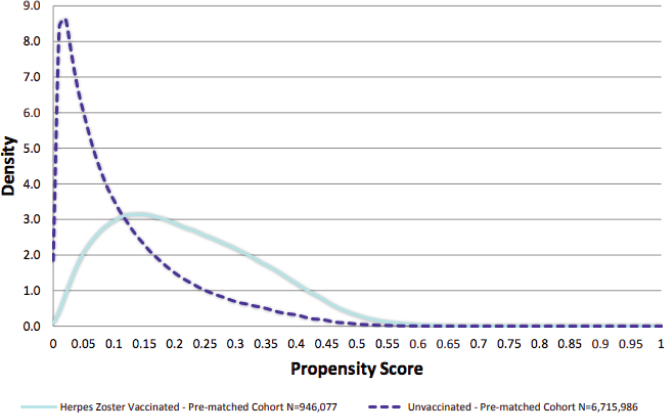
SOURCE: Izurieta presentation, July 17, 2018.
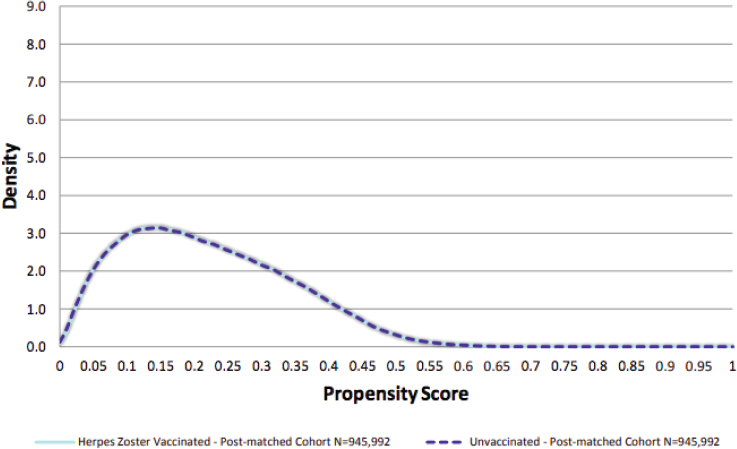
SOURCE: Izurieta presentation, July 17, 2018.
analysis that compared the herpes zoster vaccine recipients with a cohort of people who received the pneumococcal vaccine (but not the herpes zoster vaccine). The researchers used 13 negative endpoints (e.g., thrombosis, hip fracture, hemorrhoids) in order to check the balance of these cohorts, and found no substantial difference between the two groups (Tseng et al., 2011).
After the herpes zoster vaccine study was published, said Izurieta, the researchers initiated a second project to use a Medicare survey to check the match of the herpes zoster study cohorts and to augment the cohort data using multiple imputation, something that had not been done previously. The Medicare Current Beneficiary Survey is distributed to a random sample of beneficiaries every year, and asks questions regarding health usage, vaccine history, education level, and frailty. The researchers compared approximately 900 herpes zoster vaccine recipients with about 900 non-vaccinated individuals from the survey respondents, and used multiple imputation to reanalyze the vaccine effectiveness after linking the data to the survey.
DISCUSSION: OBSERVATIONAL STUDIES AND RANDOMIZATION
Perspective from Some Workshop Participants: Continued Importance of Randomization
Supplementing knowledge through observational comparisons is useful, said Robert Califf. However, while he agreed with the basic principles for RWD analyses laid out by Schneeweiss during the second workshop, Califf asserted that “where possible, you should randomize.” David Madigan, professor of statistics, and dean, Faculty of Arts and Sciences, Columbia University, agreed in part with Califf. However, he said, there are many disease areas and interventions for which evidence is needed, but there is never going to be a randomized trial. In these situations, evidence from observational studies is better than no evidence. Madigan said, “Randomization is an incredibly important tool that can provide very high-quality answers to important questions, but there are situations where we cannot randomize.” Observational database studies are one way to answer these questions (e.g., for rare diseases), and so there is a need to “keep improving the way we do these studies,” he added.
One way to incorporate randomization into RWD, said Califf, would be a system in which patients can consent to participating in randomized studies in the course of clinical practice. Califf said this type of randomization could be used in a situation in which two reasonable clinicians would make a different choice for no specific reason. For example, if a patient has hypertension and there is substantial uncertainty about which drug is more effective, the patient could be randomized to receive one or the other. The data resulting from this randomization, he said, could be used to fill
a chasm in evidence to answer questions considered most important by patients and clinicians, including which of several approved treatments is best for which patient.
Capturing the Uncertainty of Observational Trials
Every scientific study has some amount of uncertainty, said Madigan. While language such as “rely on” or “trust” is often used to describe a study, he said, this is the wrong mindset: The focus instead should be on characterizing and conveying the uncertainty in the study results. When a study is aimed at estimating the effect size of an intervention in some population, there are varying levels of accuracy depending on the study design. A well-conducted RCT can be quite accurate; an observational study that is not randomized, said Madigan, tends to be less accurate in general. However, the observational study may be “accurate enough” for the decisions that need to be made. Researchers have a duty to better capture and characterize all of the types of uncertainty in a study, he said.
Madigan described a statistical approach that he said can help illuminate the level of uncertainty in an observational study. Propensity scoring (which Izurieta used), he said, is a commonly used approach that attempts to estimate the probability that an individual would have an exposure (e.g., be treated with a drug, be a smoker). In an RCT, researchers know the exact likelihood that someone will be exposed (i.e., 50 percent if it is a 50–50 randomized trial), but in the real world, the likelihood of being exposed is due to a large number of factors such as socioeconomic status, access to health care, age, etc. Propensity scoring attempts to account for these factors by adjusting the likelihood of an exposure accordingly. Paul Rosenbaum (Rosenbaum, 2010) has extended this idea further, said Madigan, by attempting to account not just for known factors that affect probability of exposure, but also for the unknown factors that are not included in the propensity score. Rosenbaum accounts for these unknown factors by calculating how large a difference there would need to be in the probability that two people have an exposure in order for the results to not be statistically significant. An example of this approach, said Madigan, can be found using a 1954 matched-pair study on smoking (Hammond and Horn, 1954). This study matched each person who smoked heavily with one person who did not smoke and compared the outcomes. After adjusting for known covariates, there was a statistically significant large effect of smoking on lung cancer. Cornfield et al. (1959) calculated that in order for this effect to not be statistically significant, there would need to be an unknown factor that made it nine times more likely for a person to smoke. Madigan said “it is pretty hard to conceive of” an unknown factor that would increase a person’s risk of smoking nine-fold. This “gamma
analysis,” as Rosenbaum calls it, can give researchers confidence in findings from observational studies, even if the effect estimate is not as accurate as from an RCT. David Martin, associate director for Real-World Evidence Analytics at FDA’s Center for Drug Evaluation and Research (CDER), gave a regulator’s perspective on this approach, and said that this type of analysis could help move the conversation forward in a way that addresses concerns on both sides. On one side, it helps to mitigate the concerns of people who dismiss observational studies as being fraught with unmeasured confounding, and on the other, it forces observational researchers to truly examine, consider, and account for the effect of all potential variables.
Multiple Unreported Analyses
One issue with observational studies, said Califf, is the possibility of researchers conducting multiple, unreported analyses and then choosing only the most favorable ones to report. When there are an unlimited number of chances to obtain a certain result, the reported outcome is likely not a valid representation of the truth, he said. Although results in the published literature may point to a certain finding, Califf said, “We have no idea how many things were looked at that were never published.” Observational data can now be analyzed with the push of a button because of automated programs; this ease of analysis increases the chances that the published results are a highly selective sample of all of the results compared with clinical trials. He added that there is a need for principles and systems to address this issue for observational studies. Schneeweiss agreed that many database studies are done “in the dark” and said that practices such as preregistration of database studies could help address the issue. Schneeweiss said that preregistration is particularly appropriate for confirmatory studies, and Martin agreed, noting that research that is performed to evaluate or confirm hypotheses needs transparency. Martin suggested that other countermeasures to multiple unreported analyses could be in-house replication by FDA, or support from FDA for complex data analysis.
Richard Platt told workshop participants about how Sentinel deals with multiple unreported analyses. Before a study is implemented, he said there is extensive discussion between FDA scientists and the researchers at Sentinel, and all of the specifications are decided in advance. Multiple analyses may still be done, he said, but each one is specified in advance and is shown in the report, so it is a transparent process. For regulatory decisions, said Martin, this type of prespecification is a necessary best practice. Another workshop participant added that there are technological approaches used to help ensure that there is a prespecified protocol and that the first analysis is reported as such (rather than running multiple analyses and picking the “best” one to report).
Gregory Simon noted that there are two potential solutions to the problems with multiple unreported analyses. The first would be to allow only a certain number of prespecified analyses. The second would be to allow analyses to be unlimited, but require that all analyses be reported and compared. Schneeweiss disagreed with this second approach, saying that “you just get a mess of data and you have no idea how to interpret it.”
Several other individual speakers emphasized the importance of prespecification of the analytic plan; Mark van der Laan, professor of biostatistics and statistics at the University of California, Berkeley, called the problem of multiple unplanned analyses “the biggest problem in observational studies.”
Reproducibility
Several individual participants noted problems related to non-reproducibility of database studies. One issue, said Madigan, is that researchers write custom code for a particular study rather than using validated tools. If the code is not available to other researchers, the study cannot be reproduced. Another issue, he said, is that authors are not always transparent about their design and analytic choices. For example, he cited a paper that said the study was “adjusted for age.” However, no further details were given about how this was done, and Madigan had to contact the authors to understand that they had grouped the participants into 5-year ranges. If the participants were grouped by different age ranges, the data generated a different answer, Madigan said, adding, “The level of irreproducibility we are living with right now is unacceptable.”
RWD analyses, said Schneeweiss, require multiple difficult choices about study design, dealing with non-standardized observations, and complex analytic methods. Because of this complexity, he emphasized that it is essential that researchers present studies with transparency and promote replicability. Decision makers—particularly regulators—need to be able to determine exactly how and when decisions were made in order to assess the quality of the research and replicate the analysis. “Transparent, structured reporting of complex methodology clarifies study validity for decision makers,” Schneeweiss observed.
DECISION AID
The general issues discussed by individual workshop participants in the first and second workshops were used to develop a decision aid for the third workshop (see Figure 9-5). As with the other decision aids, the intention was to outline some questions to consider to make thoughtful choices in real-world evidence (RWE) study design. Participants at the third workshop
reflected on these questions and offered feedback on the decision aid specifically (see Box 9-1) and throughout the course of their discussions.
PRESENTATIONS: OBSERVATIONAL STUDIES AND BIAS
Replicating RCTs to Gain Confidence
One way to increase confidence in observational studies, said Jessica Franklin, assistant professor of medicine at Harvard Medical School, is to replicate results from RCTs using RWE. If RCT results can be consistently replicated across a range of clinical questions, this “gives us confidence going forward into new clinical questions,” she said. Franklin and Schneeweiss are working on a project that will replicate a number of RCTs using RWD sources. Thirty RCTs have been selected, and the researchers are setting up the protocol for conducting the replications, she said. The process for determining which RCTs are appropriate for replicating with RWD, she said, is similar to the process that Schneeweiss outlined for determining whether a question can be appropriately answered with RWD. First, the setting and data quality must be assessed for the specific research question. Next, a statistical analysis plan is drafted, and initial analyses are conducted to test feasibility and validity. If the study passes these initial steps, the study is registered, and the analyses are specified before being conducted. Once results are reported, additional analyses can be conducted if necessary or appropriate. This process could serve as a model for how to use RWE to inform policy, said Franklin.
Marc Berger added that replicating RCTs can be used to identify fit-for-purpose datasets. If a dataset and an RCT generate substantially similar results, other analyses that use the same dataset “should be more credible,” he said.
Predictive Analytics and Machine Learning
Javier Jimenez, vice president and global head for Real-World Evidence and Clinical Outcomes at Sanofi, suggested that new tools such as machine learning and predictive modeling may be useful for analyzing RWD. In addition to other uses, machine learning and predictive modeling present an opportunity to evaluate unmeasured confounders through proxies from other information that has been collected, he said. Jimenez presented a study on insulin in which predictive analytics were used to build models that evaluated the probability of an outcome for different populations, based on information in the Optum Database. The predictive models were based on individual variables as well as the interactions of all the variables, said Jimenez. The models were applied to the overall population in order to understand the

NOTE: This decision aid was drafted by some individual workshop participants based on the discussions of individual workshop participants at the first and second workshops in the real-world evidence series. The questions raised are those of the individual participants and do not necessarily represent the views of all workshop participants; the planning committee; or the National Academies of Sciences, Engineering, and Medicine, and the figure should not be construed as reflecting any group consensus.
SOURCE: Simon presentation, July 18, 2018.
expected outcome if all patients were to use the particular insulin product. The results of this model, he said, were consistent with the results from a real-life study. In addition, the analysis revealed a particular subgroup that benefited more from the product. This model, said Jimenez, could be used to predict the probability of a specific outcome for a patient, using all of the available information.
van der Laan outlined another modern approach for conducting observational studies using computer systems to learn from data, known as “targeted machine learning.” This approach, he said, is always based on a roadmap of causal inference, with defined steps that are followed for every analysis:
- The first step is understanding the question of interest from a causal perspective—that is, what are the outcomes, interventions, and other variables of interest—and developing a causal model describing the causal relations among the variables. The causal model allows a researcher to define the counterfactual data that would have been seen under a particular intervention on the intervention variables and defines the causal question of interest.
- Second, the researcher must determine what observed data are available and link them to the underlying counterfactual data that define the causal question of interest.
- Third, researchers determine whether causation can be established from the available data. To answer this, researchers use mathematical techniques to establish identification of the answer to the
-
causal question from the observed data distribution under a specified set of causal assumptions. These underlying assumptions generally cannot be tested. Any such identification result defines an estimand.
- Next, the researcher must commit to an estimand that “best” approximates the desired causal quantity and develop an a priori specified estimator and method of inference. It is essential that this be a priori specified in order for the research to be reproducible and transparent.
- The final step is sensitivity analysis to establish how confidence intervals and p-values change under different levels of assumed discrepancy of the estimand and the desired causal quantity, due to unmeasured confounding or other violations of the non-testable assumptions.
van der Laan described an approach called “targeted learning,” which combines causal modeling, state-of-the-art machine learning, and deep statistical learning to get more precise answers for causal questions of interest, while providing formal statistical inference in terms of confidence intervals and p-values. Targeted learning is a technique to minimize estimation bias and to maximize precision in observational studies.
Regulatory Perspective on Observational Studies for Drugs
Nicole Gormley, clinical team leader within the Division of Hematology Products at CDER, said although the 21st Century Cures Act has put new focus on RWD and RWE to expand and expedite drug development, the “evidentiary criteria and standard really doesn’t change.” To approve a drug label, FDA needs a “demonstration of substantial evidence of efficacy with adequate demonstration of safety to enable the safe and effective use of the product,” Gormley said. RWE can serve as primary or supportive evidence when FDA evaluates a product for approval, and there are specific aspects that regulators would consider to evaluate evidence, she said:
- First, data should be relevant for the proposed indication for the product; that is, the data should represent the population of interest and the setting in which the product would be used. For example, in an RCT, there are strict inclusion and exclusion criteria that define the patient population. In RWD, by contrast, the patient’s inclusion in a treatment group is due to multiple factors, which can introduce bias.
- Second, a critical factor is that the outcomes being measured are clear and well assessed. In some disease settings, outcomes are relatively easy to assess (e.g., survival rates). Other endpoints may be
-
more difficult to assess, particularly in the real world. For example, an outcome of “attaining transfusion independence” is easy to assess in theory through the absence or presence of transfusions. However, in practice, some patients may be receiving transfusions at other centers that are not captured in the data, or data may be missing for other reasons.
- A third aspect of RWE that regulators would consider is the methods used to collect the data. Some methods give more confidence in the data collected, including well-designed protocols that minimize bias, account for confounders, and mitigate the impact of missing data.
- Finally, the statistical analyses applied to the data should be “robust and of significant rigor.” While RWE has the potential to expedite drug development and complement the evidence from RCTs, it is important to ensure that RWE is collected and analyzed in a way that minimizes bias and increases reliability.
Gormley emphasized that when stakeholders are considering using RWE for regulatory purposes, they should engage in dialogue with FDA early in the process.
Regulatory Perspective on Observational Studies for Devices
Premarket observational studies are more common in devices than in drugs, said Heng Li, mathematical statistician at FDA’s Center for Devices and Radiological Health (CDRH). This is due in part to a difference in the evidentiary standards for devices; for drugs, Li summarized that FDA requires “substantial evidence from well-controlled investigations.” For devices, however, FDA requires “reasonable assurance based on valid scientific evidence,” Li said. This evidence can come from well-controlled investigations as well as partially controlled studies, studies without matched controls, or well-documented case histories conducted by qualified experts. Premarket observational studies for devices generally use prospective enrollment for the treatment arm, and use an RWD source as a concurrent or historical control, said Li.
Statisticians at CDRH recently developed a streamlined procedure for designing premarket observational studies, said Li. This procedure uses propensity score methodology to balance baseline covariates, and uses an “outcome-free” design principle. This principle requires the propensity score development and assessment of covariate balance to be performed without knowledge of any outcome data. This procedure has two stages, he said:
- The first stage involves specifying a comprehensive list of baseline covariates, choosing an appropriate data source for the control group, identifying an independent statistician, and estimating the sample size.
- The second stage begins after the patients have been enrolled and all of the baseline covariate data have been collected, cleaned, and locked. In this stage, the independent statistician estimates the propensity score, performs matching or weighting, assesses baseline covariate balance, and finalizes the sample size and statistical analysis plan.
All of this work is done, said Li, without access to any outcome data. By blinding the statistician to the outcomes, a source of potential bias in the analysis is eliminated. This procedure has been implemented successfully in the premarket space for devices, he said.
DISCUSSION: THE FUTURE OF OBSERVATIONAL STUDIES
Context of the Decision
The choices in design and analysis of an observational study, said Gregory Daniel, depend on the context in which a decision is being made. Is it a chronic disease or is it a rare disease? What is already known about the safety and efficacy of a product? What is the expected treatment effect? What is the regulatory question at hand? For example, is it a brand new indication or an extension of the label? Gormley agreed, and said that evidence from observational studies needs to be examined on a “case-by-case basis.” The context is enormously important, she said; for example, the standard of evidence may be higher for a situation with the potential for serious, life-threatening illness.
Best Practices for Observational Studies
While the questions on the decision aid are useful, it is a “very hard task” to dictate exactly how to do design or analysis, said Franklin. For any given clinical question, she said, the methods are going to vary. It can be useful to give people examples of practices that have worked in the past or to point out some of the common mistakes in observational studies, she said. For example, she pointed to Schneeweiss’s presentation about which characteristics lead to a more valid observational study: an active comparator, a new user design, well-specified outcomes, and data sources with good longitudinal exposure measurement. In addition to these, propensity scores and sensitivity analyses can be useful, she said.
Berger agreed that there is a need for adoption of best practices in observational studies. In clinical trials, he said, there are rules and structures that enforce best practices for study design and conduct. For example, in RCTs, hypotheses must be registered, and if a hypothesis changes, this needs to be reported. Berger advocated for similar requirements and practices for observational studies: “We need to bring observational data up to the same level of scrutiny as we have for RCTs” before discussing when and whether RWD are fit for purpose.
Schneeweiss emphasized that the reliability of an observational study is driven by the underlying data. If the data are not fit for answering the question, the results will not be reliable. Unfortunately, he said, this is an ongoing process because “there is no one single dataset that will be fit” for all research questions.




















