
While the first workshop explored the general issues concerning the use of real-world data (RWD) and real-world evidence (RWE), many individual participants at the second and third workshops drilled down into these issues in an attempt to identify specific questions to consider before using RWD and RWE in a study design. During the second workshop, individual participants suggested sets of questions organized by topic based on the workshop’s three sessions. These questions, the discussions at the second workshop, and additional work by several individual workshop participants between the second and third workshops informed further refinement of the questions into several “decision aids.” The decision aids were discussed at the third workshop and were intended to prompt discussion among the participants and inform them and potentially other stakeholders about topics in study design. Several sessions at the third workshop focused on these decision aids and explored the “sticking points” that individual workshop participants had identified at the second workshop. The presentations and discussions in the second and third workshops are covered in Chapters 6 through 9 of these proceedings, divided by the topic areas of the decision aids.
REAL-WORLD DATA ELEMENTS
As discussed in Chapter 1, there is no consensus on a definition of RWD. However, Brande Yaist, senior director of global patient outcomes and RWE at Eli Lilly and Company, said there are common themes among definitions. In particular, RWD are data that are derived from a variety of real-world sources, such as electronic health records (EHRs) and claims data, pragmatic trials, registries, social media, and directly from patients (see Figure 6-1). There are also hybrid approaches, where RWD are used in combination with primary clinical trial data collection.
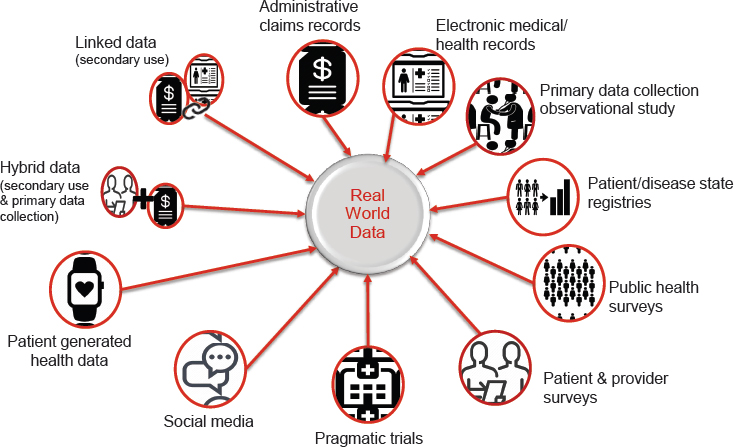
SOURCE: Yaist presentation, July 17, 2018.
With this wide definition of RWD, there is an almost infinite amount of data. Gregory Daniel, deputy director of the Duke-Margolis Center for Health Policy, asked when can we rely on these data? That is, when can RWD be used to assess characteristics of participants in a trial, such as eligibility, baseline health state, or key prognostic factors? When can RWD be relied on to assess patient outcomes? When can data that are generated by patients or by their devices be considered reliable? Perhaps most importantly, asked Daniel, how can the reliability of RWD be assessed before time and money are spent to conduct a study?
To answer these questions, workshop presenters and participants discussed the reliability of RWD, using illustrative examples to elucidate some of the main challenges, and referring to the draft decision aid (see Figure 6-3 later in this chapter).
ILLUSTRATIVE EXAMPLES
To explore the issues surrounding the use of RWD, speakers at the second and third workshops presented case studies as illustrative examples of the considerations that go into designing and conducting a real-world study.
NOACs Versus Warfarin
At the second workshop, Adrian Hernandez, vice dean for clinical research at the Duke University School of Medicine, presented a suite of trials that compared novel oral anticoagulants (NOACs) with warfarin. Oral anticoagulants like warfarin have long been used in patients for a number of indications, including reducing the risk of stroke and embolism in patients with atrial fibrillation. However, there are challenges involved with warfarin use, such as requirements for patient monitoring, said Hernandez, and many patients do not receive effective management (Go et al., 1999). The use of warfarin is suboptimal, even among high-risk patients, he said (Waldo et al., 2005). Researchers have been developing novel anticoagulants as an alternative to warfarin, and there were four pivotal trials used for approval of these drugs for the treatment of atrial fibrillation and risk reduction for stroke. Together, these trials enrolled more than 70,000 patients to compare NOACs with warfarin; each used slightly different methods and targeted different types of patients, but all involved some use of RWD. The trials presented were the following:
- Randomized Evaluation of Long-Term Anticoagulation Therapy (RE-LY) (Connolly et al., 2009);
- Rivaroxaban Once Daily Oral Direct Factor Xa Inhibition Compared with Vitamin K Antagonism for Prevention of Stroke and Embolism Trial in Atrial Fibrillation (ROCKET AF) (Patel et al., 2011);
- Apixaban for Reduction in Stroke and Other Thromboembolic Events in Atrial Fibrillation (ARISTOTLE) (Granger et al., 2011); and
- Effective Anticoagulation with Factor Xa Next Generation in Atrial Fibrillation-Thrombolysis in Myocardial Infarction 48 (ENGAGE AF-TIMI 48) (Giugliano et al., 2013).
The outcomes of these trials, said Hernandez, were largely consistent and showed that NOACs were non-inferior to warfarin. A 2014 meta-analysis showed that all four trials favored NOACs over warfarin for the risk of stroke and systemic embolic events, as well as secondary outcomes, such as ischemic stroke, hemorrhagic stroke, myocardial infarction (MI), and all-cause mortality (Ruff et al., 2014).
Hernandez outlined some of the major difficulties in conducting these studies. Three of the trials—which all enrolled thousands of patients—were double blinded. This led to, said Hernandez, enormous challenges for the investigators in terms of monitoring, ensuring standard of care, and adjudicating the outcomes (see Chapter 8 for more details on blinding).
Hernandez suggested that in order to assess the quality of these trials, one could use time in therapeutic range as a surrogate for quality. Warfarin has a narrow therapeutic window—for most indications, the international normalized ratio (INR) should be between 2 and 3. If the INR is lower, the risk of ischemic stroke is higher; if the INR is higher, the risk of intracranial hemorrhage is higher. For this reason, patients on warfarin must be monitored frequently to ensure that they are in the appropriate therapeutic window. In the ROCKET-AF study, a large majority of patients were in the therapeutic range (with an INR target of 2.5, inclusive from 2 to 3).
Friends of Cancer Research Pilot Project
At the third workshop, Jeff Allen, president and chief executive officer of Friends of Cancer Research, talked about a pilot project that investigated the performance of real-world endpoints among patients with advanced non-small cell lung cancer (aNSCLC) who were treated with immune checkpoint inhibitors. The goal of the project, said Allen, was to explore potential endpoints that may be fit for regulatory purposes as well as to assess the long-term benefits of a product. The project used a retrospective observational analysis design with patient-level data. The data were derived from EHRs and claims databases from six data partners. The study was conducted in a distributed manner, said Allen, which meant that each partner maintained and analyzed its own data; the partners collaborated to develop common data elements and methodological approaches so that the analyses would be as similar as possible. Allen described the three research objectives:
- Characterize the demographic and clinical characteristics of aNSCLC patients treated with immune checkpoint inhibitors.
- Assess ability to generate real-world endpoints in aNSCLC patients treated with immune checkpoint inhibitors, and segmented by clinical and demographic characteristics.
- Assess performance of real-world endpoints as surrogate endpoints for overall survival.
Investigators defined and assessed five endpoints of interest for this population, all of which could be gleaned from the RWD sources. Allen noted that it was remarkably challenging to define and standardize these endpoints among different data sources to ensure that the study was comparing “apples to apples.” Allen also noted that these endpoints were not necessarily indicative of the full potential of the partners’ datasets, but rather represented the common denominator among them all. The endpoints defined were
- Overall survival (OS): The length of time from the date that treatment was initiated to the date of death;
- Time to next treatment: The length of time between initiation of treatment and initiation of the next systemic treatment;
- Time to treatment discontinuation: The length of time between initiation and discontinuation of treatment;
- Progression-free survival: The length of time between initiation of treatment and a progression event (as evidenced in the patient’s chart) or death; and
- Time to progression: The length of time between initiation of treatment and a progression event, but excludes death as an event.
Allen noted that the intention of this study was not to compare different drugs or readjudicate clinical trials, but rather to look at what evidence could be extracted from diverse data sources and what the strength of that evidence would be. For the first research objective of characterizing the patients, Allen said they found “really great consistency [among] the different characteristics.” While the patient demographics and characteristics were not identical across the six databases, they were relatively consistent in terms of age, histology, sex, and treatment.
On the next objective—assessing the ability to generate real-world endpoints—there were some challenges, said Allen. Even a simple endpoint such as death of the patient can be challenging to collect, due to the limited availability of accurate and timely death records. Despite these challenges, said Allen, there was relative consistency among the datasets on many of the endpoints (see Table 6-1). When segmented by patient demographics, there was again relative consistency, despite some outliers. This consistency among datasets suggests that these types of data could be used to assess patient populations when randomized controlled trials (RCTs) are not feasible or desirable.
The third research objective was to evaluate the correlations between these real-world endpoints and overall survival (see Table 6-2). These correlations, while not “overwhelmingly strong,” were consistent, said Allen. This suggests that these real-world endpoints—readily accessible in EHRs—could potentially serve as surrogate endpoints for overall survival.
Finally, the investigators wanted to examine how closely the overall survival rate from the real-world datasets would align with what had been observed in clinical trials for these drugs. Using data for patients on any of three different immune checkpoint inhibitors, the investigators compared the real-world overall survival rates with the ranges that had been observed in pivotal clinical trials for each drug. The overall survival rates from the databases were generally in line with the rates from the clinical trials, said Allen (see Figure 6-2). This came as a bit of a surprise, he said, because
TABLE 6-1 Real-World Endpoints in Six Datasets
| Data Set | rwOS | rwTTD | rwTTNT |
|---|---|---|---|
| Data Set A | 13.50 [12.80, 14.50]a | 7.03 [6.27, 9.97] | 22.50 [NA] |
| Data Set B | 15.78 [12.20, 24.59]; 8.58 [7.56, 10.26]b |
3.25 [2.76, 3.75] | |
| Data Set C | 8.67 [6.83, 10.02] | 4.70 [3.68, 5.52] | 11.60 [8.80, 16.10] |
| Data Set D | 9.15 [8.82, 9.51] | 3.21 [3.21, 3.44] | 14.03 [12.89, 15.15] |
| Data Set E | 12.69 [11.70, 13.87] | 3.63 [3.40, 3.87] | 12.07 [11.24, 13.48] |
| Data Set F | 12.30 [9.61, 16.94] | 4.60 [3.71, 6.32] | 12.50 [9.29, NA] |
a Overall survival was calculated as days between I/O initiation and disenrollment.
b Sites with social security or state death data, censored at estimated earliest date such data should be available if no death was observed.
NOTE: NA = not applicable; rwOS = real-world overall survival; rwTTD = real-world time to treatment discontinuation; rwTTNT = real-world time to next treatment.
SOURCE: Allen presentation, July 17, 2018.
TABLE 6-2 Correlation Between Real-World Overall Survival and Real-World Extracted Endpoints
| Data Set | rwOS Versus rwTTNT | rwOS Versus rwTTD | ||
|---|---|---|---|---|
| N | Correlation [95% CI] | N | Correlation [95% CI] | |
| Data Set A | 83 | 0.36 | 254 | 0.63 |
| Data Set B | 225 | 0.62 [0.54, 0.69] | ||
| Data Set C | 96 | 0.70 [0.58, 0.79] | 295 | 0.89 [0.86, 0.91] |
| Data Set D | 1,203 | 0.61 [0.57, 0.64] | 4,337 | 0.80 [0.79, 0.81] |
| Data Set E | 358 | 0.62 [0.54, 0.68] | 1,456 | 0.77 [0.75, 0.79] |
| Data Set F | 39 | 0.46 [0.33, 0.81] | 142 | 0.80 [0.66, 0.85] |
NOTE: CI = confidence interval; rwOS = real-world overall survival; rwTTD = real-world time to treatment discontinuation; rwTTNT = real-world time to next treatment.
SOURCE: Allen presentation, July 17, 2018.
NOTE: CI = confidence interval; rwOS = real-world overall survival; rwTTD = real-world time to treatment discontinuation; rwTTNT = real-world time to next treatment.
SOURCE: Allen presentation, July 17, 2018.
there had long been speculation that the survival rates of the homogeneous clinical trial populations might be lower once the treatment was applied to a more diverse real-world population.
Allen concluded with what he sees as the main takeaways from this pilot project. First, he said, there is a high level of shared patient characteristics among the datasets, despite the fact that the datasets have variable sample sizes and data capture processes. This similarity among sources
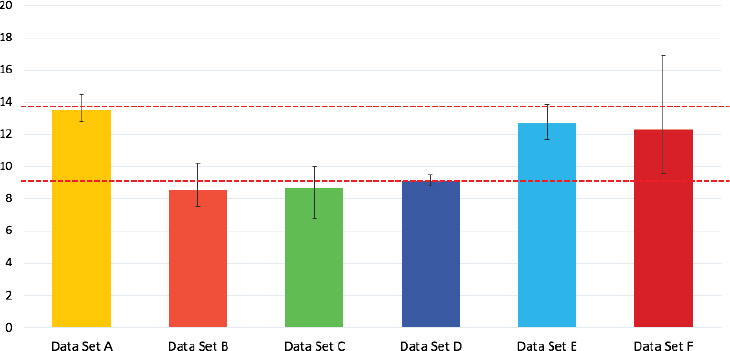
NOTE: Each bar represents a combination of information based on three different products in the class from each data partner. The y-axis shows the median overall survival in months of advanced non-small cell lung cancer (aNSCLC) patients treated with a checkpoint inhibitor. The red dashed lines represent the observed range in overall survival levels in the pivotal randomized controlled trials for the same products.
SOURCES: Allen presentation, July 17, 2018; concept/data from Huang et al., 2018.
demonstrates the feasibility of identifying aNSCLC patients from diverse RWD sources. Second, the study demonstrated that several real-world endpoints correlate well with OS. However, more research is needed to determine whether the endpoints could be reliable surrogates for OS, and whether these endpoints could support decision making by regulators and payers. Finally, the overall survival rates assessed from EHR and claims data were quite consistent with the rates observed in clinical trials, he said, suggesting a need for additional research on the association between data from real-world sources and data from clinical trials.
DISCUSSION: CHARACTERIZING REAL-WORLD DATA AND REAL-WORLD EVIDENCE
Following the presentation of the illustrative examples, the workshop participants discussed some of the general issues and overarching considerations with using RWD, in particular how one could characterize the utility of RWD before a study is performed. Several participants highlighted challenges in defining the population, exposure, and outcomes; concerns about
data collection by providers; considerations of whether and when expert adjudication might be necessary; and safety issues that could be addressed.
Defining the Population, Exposure, and Outcomes
One of the pivotal parts of assessing the quality and relevance of data is determining if the source has information about the right population, the right exposure, and the right outcomes, said Yaist and Aylin Altan, senior vice president of research at OptumLabs, during the third workshop. However, defining these elements is not as straightforward as it might seem. During the second workshop, Jesse Berlin, vice president and global head, Epidemiology, Johnson & Johnson, gave an example of trying to determine—based on RWD—which patients have diabetes. He said there are multiple codes, drugs, and other data points that could indicate that a patient has diabetes, but there is no obvious way to determine this with 100 percent certainty. He noted that a colleague had developed a predictive model that would classify the probability of patients being diabetic (which could mean that a patient would be a 0.8 diabetic, he noted). Gregory Simon concurred with the idea of a probabilistic model, noting that while we commonly use dichotomous classifications for medical conditions, many medical phenomena are “fuzzy.” The line between an MI and not an MI, or between depression and not depression, is not “completely crisp,” he said. A probabilistic approach would help to better capture the fuzziness of medical conditions, but could also be challenging for researchers and regulators to understand.
Exposure, said Berlin, can also be difficult to determine using RWD. For example, exposure to a drug is usually indicated through a prescription for the drug in the EHR, or a record of payment for the drug in the claims data. However, neither of these data points can prove that the patient is taking the drug as prescribed. Hernandez added that when using RWD to capture population, exposure, and outcome, it is possible to use sensitivity and specificity analyses to assess the robustness of the evidence. In other words, even though there is variability in the data, this variability can be accounted for in the analysis.
Hui Cao said that although it can be challenging to assess RWD sources for population, exposure, and outcomes, they are fairly straightforward in some situations. For example, for certain diseases (e.g., diabetes), established algorithms can identify the population with the disease. These algorithms can be employed before a study is conducted in order to understand how well the population can be identified and with what level of confidence, she said. For exposure, there is generally high confidence about accurately capturing drugs given by injection or intravenously because of the administration method. However, capturing oral medications or inhaled products can
be trickier, she said. In terms of outcomes, the data for certain events, such as hospitalization for MI, are fairly accurate. For other outcomes, such as laboratory measures or continuous variables, the data may be less reliable.
Robert Temple, deputy director for clinical science at the U.S. Food and Drug Administration’s (FDA’s) Center for Drug Evaluation and Research (CDER), added that while much of the discussion had been on assessing the quality of data for RWE studies, RWD can also be used to facilitate clinical trials. For example, RWD can be used to identify patients who may be appropriate subjects for a trial. For this use of RWD, the quality of the data does not matter as much, he said, because the participants will undergo further evaluation for enrollment.
Data Collection by Providers
One concern with RWD collection, said Simon, is whether providers can accurately assess the condition or event of interest. In RCTs, data are collected by providers specifically trained in the trial protocol, whereas in RWD, providers in real-world settings assess patients and must accurately and completely record necessary information. This accurate data collection is “foundational” to the idea of RWD, he said. If the assessment requires special training, technology, or tools, Simon suggested it would be better suited to an RCT. Hernandez emphasized the importance of examining the incentives (or disincentives) to accurate data collection that affect the providers. For example, said Simon, when Medicare changed its payment structure in a way that incentivized the diagnosis of “major depressive disorder” instead of “depression not otherwise specified,” the “ratio of these two diagnoses in most large health systems flipped overnight.” The epidemiology of depressive disorders did not change, said Simon, but rather the incentives that governed their recording.
Relatedly, said Hernandez, different EHR systems vary considerably, and these variations can impact how providers record information. For example, a colleague of Hernandez “teaches his Fellows to never code for diabetes in their EHR system, because it pulls up a laundry list of choices that you have to make which don’t quite fit.” As a consequence, RWD from this particular EHR system are not likely to have accurate data about diabetes, which could result in systematic bias, he said.
One workshop participant noted that while retrospective studies depend on how the provider put data into the system in the past, prospective pragmatic trials have the opportunity to improve this initial data collection. For example, researchers in the Salford Lung Studies (see Chapter 3) embedded prompts in the EHR to improve data collection, said Simon.
While much of the attention around data is often on assessing data quality once they are collected, said one workshop participant, the start-
ing point should be ensuring that data are collected in a standardized and accurate way, both for research purposes and clinical purposes. EHRs, the workshop participant said, are designed primarily for patient care; the primary goal should be for the EHR to capture data that are meaningful and useful for patient care, including facilitating, rather than complicating, patient care by providers. Elise Berliner, director, Technology Assessment Program, Center for Outcomes and Evidence, Agency for Healthcare Research and Quality, concurred, noting that some of the challenges in data analysis are also challenges to patient care—for example, patients seeking care outside their usual health network, or missing or fragmented health data. Fundamentally, said Berliner, the health care system is about patients and their providers. She asked, “How do we work together with the other stakeholders to make the data infrastructure better and more reliable?” Simon noted that although different stakeholders use different terms, the data needs of all stakeholders are essentially the same: knowing whether the care that a patient received worked and whether it was safe.
Expert Adjudication
Expert adjudication, said Daniel, can sometimes be necessary to confirm that the recorded data are reliable or reasonably complete. Simon said adjudication is not for issues such as missing data or technical problems, but rather for validating that the source clinician correctly assessed the patient and accurately recorded the data. Unfortunately, he said, “We cannot put ourselves in a time machine and go back . . . and interview that patient ourselves.” Adjudication generally means using low-quality text notes in order to validate the data against the record, said Simon. Hernandez said that not all clinical data need to be adjudicated, because ultimately they may not matter if they are correct. For example, if errors in assessment or recording are random and not systematic, this random error should not affect the results. Joanne Waldstreicher noted that there is empirical literature about expert adjudication and when it makes a difference.
Safety Issues
In clinical trials, said Simon, adverse safety events can be detected because trial participants’ baseline health status is measured before the trial begins, so any adverse events that occur after the exposure may be attributable to the intervention. For example, a participant’s blood pressure will be measured at the beginning of a trial and then measured again after exposure to the intervention. However, in a real-world setting, “things are measured when they’re measured,” said Simon. In this scenario, it may be more difficult to differentiate between comorbidities (i.e., a health condition
that was preexisting) and adverse events (i.e., a health condition that was due to the intervention). This may make it more difficult to assess safety issues using RWD, said Simon.
Another safety issue raised by Simon was the issue of misclassification of data. Normally, random misclassification of data biases a study toward the null (i.e., random error may result in a finding of no effect). In a study examining effectiveness, the result of this bias would be a finding that the intervention had no effect on outcomes, he said. However, random misclassification may also result in missing safety events, which could “lead to conclusions that would damage the public’s health or be unsafe.”
DECISION AID
The general issues discussed by individual workshop participants in the first and second workshops were used to identify topics that could benefit from further exploration in the third workshop. Draft “decision aids” were developed by some individual workshop series participants on discrete aspects of study design to organize the topics that could benefit from further exploration and to facilitate deeper discussions at the workshop. A decision aid (like that presented at the workshop; see Figure 6-3), said session moderator Pall Jonsson of the National Institute for Health and Care Excellence in the United Kingdom, is “intended to lay out key questions for stakeholders to consider early on” in order to “make thoughtful choices around the development and design” of rigorous studies that use RWD. Many workshop participants reflected on the concepts highlighted in the decision aid over the course of their discussions, and some workshop participants offered direct feedback on the decision aid itself (see Box 6-1).
“FIT FOR PURPOSE” AND RELEVANCE OF DATA
At the third workshop, a panel of speakers representing different RWE stakeholders shared their perspectives and experiences using RWD. The speakers were asked to discuss how a decision aid such as the one in Figure 6-3 could help guide the use of RWD. When considering using RWD to answer a research question, said Daniel, the essential question is the following: Is the accuracy of the data good enough to reasonably and consistently identify the right population, the exposure or the intervention, and the right outcome? That is, are the data relevant and fit for purpose for the research question at hand? Several speakers discussed the processes they use to assess the relevance of RWD.
Researchers Using RWD Primarily from External Sources
Yaist said that when considering the use of RWD, it is imperative to start with the research question and the context of the decision. Only with this information in hand can one determine what data elements might answer the question and provide the information necessary to meet a certain need. Once the context of the decision is clarified, said Yaist, one can begin to identify possible data sources, and to evaluate these sources for relevance. Yaist said the first step is to see if there are already validated ways to get information; for example, major adverse cardiac events in claims data have been extensively studied. Next, the researcher would look to see where the needed data elements could be found—are there existing data sources, either from clinical care or from patients? Or do the data need to be collected? (See Figure 6-4 for this decision tree.) Once data sources are identified, the researcher would look at a number of factors to assess the relevance of the data for the research question:
- Availability of key data elements (e.g., exposure, outcome, and covariate variables);
- Representativeness of population;
- Sufficient number of subjects;
- Availability of complete exposure window;
- Longitudinality of data; and
- Availability of elements for patient linking.
Organizations with Existing Databases of Real-World Data
Altan presented a similar approach as Yaist for assessing the relevance of an existing source of RWD. OptumLabs is an aggregator of data that stores de-identified data for use by 30 partners that can access these data. The data at OptumLabs originate from a wide variety of sources, including data derived from EHRs, administrative claims, laboratory results, consumer data, and socioeconomic status (see Figure 6-5).
Altan outlined a simplified version of the decision process that she uses when an organization approaches OptumLabs with a research question that potentially can be answered with existing RWD (see Figure 6-6). The first step, said Altan, is asking if the required sample and variables exist. That is, are there data on the right population, the exposure and outcome under study, and covariates or confounders of interest? If there are data, is there a sufficient sample size to power the study? Can the available data be used for any special needs, for example, repeated measurements or measurements of exposure around a specific event?
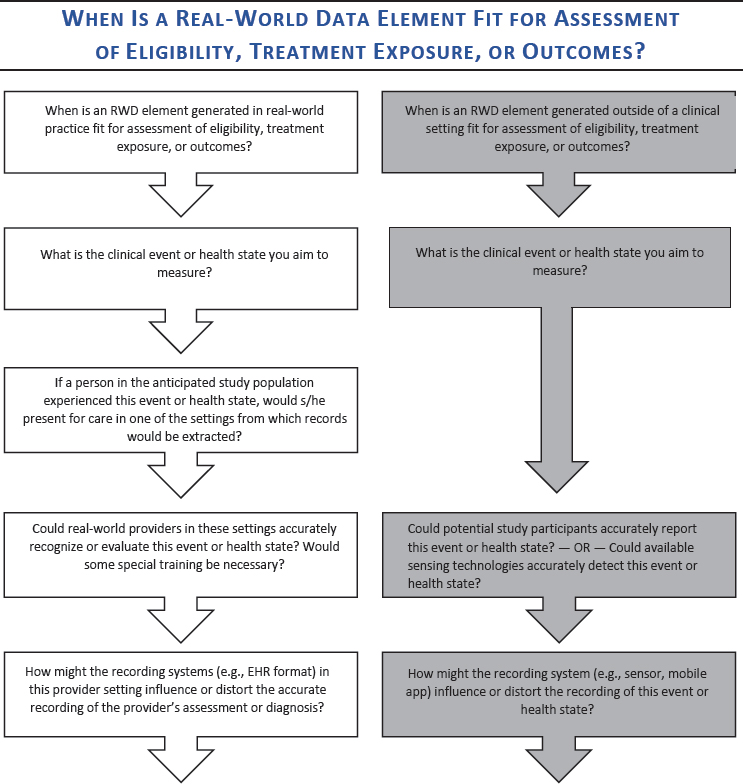
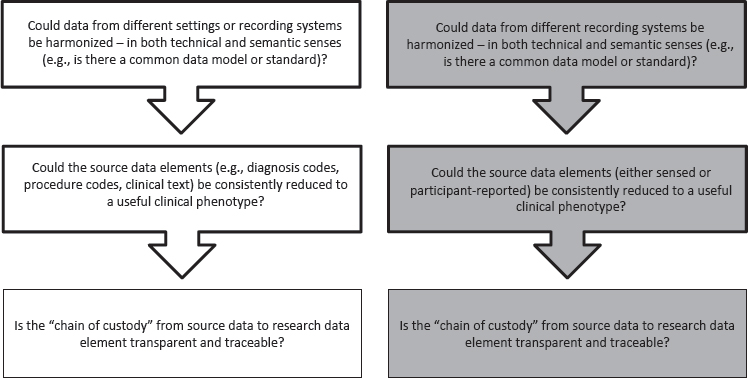
NOTES: This decision aid reflects questions about development and design for studies using RWD, and served to assist conversation and frame workshop discussions. The boxes with white backgrounds (on the left) show questions relevant to data generated within a health care system, such as electronic health record (EHR) or claims data. The boxes with the gray background (on the right) show questions relevant to data generated directly by patients and that would not necessarily be seen by a provider. This decision aid was drafted by some individual workshop participants based on the discussions of individual workshop participants at the first and second workshops in the real-world evidence series. The questions raised are those of the individual participants and do not necessarily represent the views of all workshop participants; the planning committee; or the National Academies of Sciences, Engineering, and Medicine, and the figure should not be construed as reflecting any group consensus.
SOURCE: Jonsson presentation [Session 2], July 17, 2018.
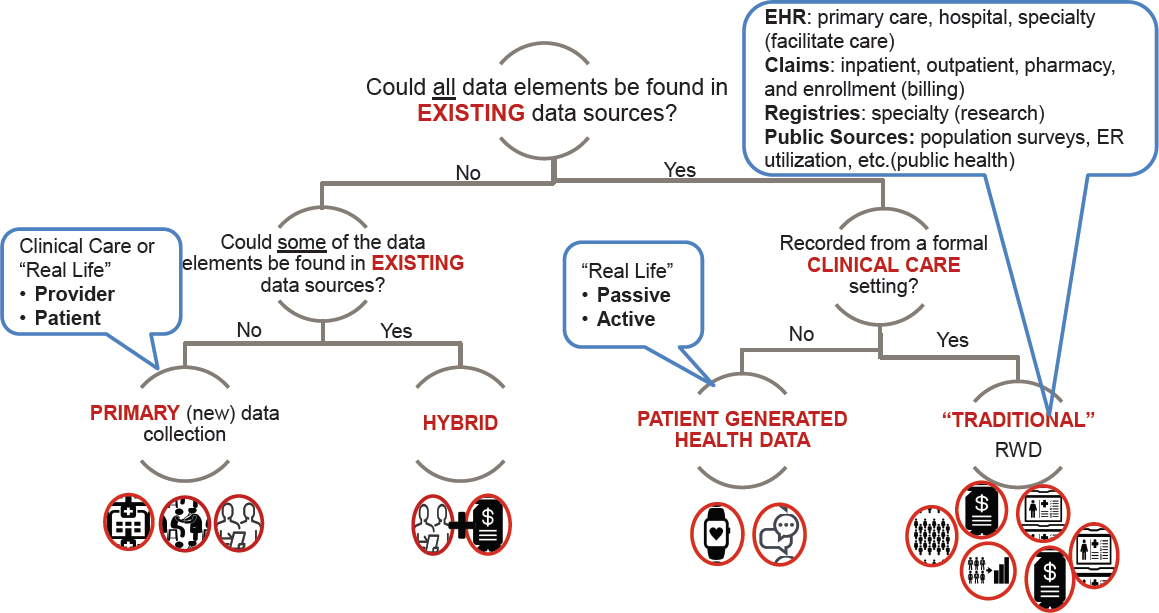
NOTE: EHR = electronic health record; ER = emergency room; RWD = real-world data.
SOURCE: Yaist presentation, July 17, 2018.
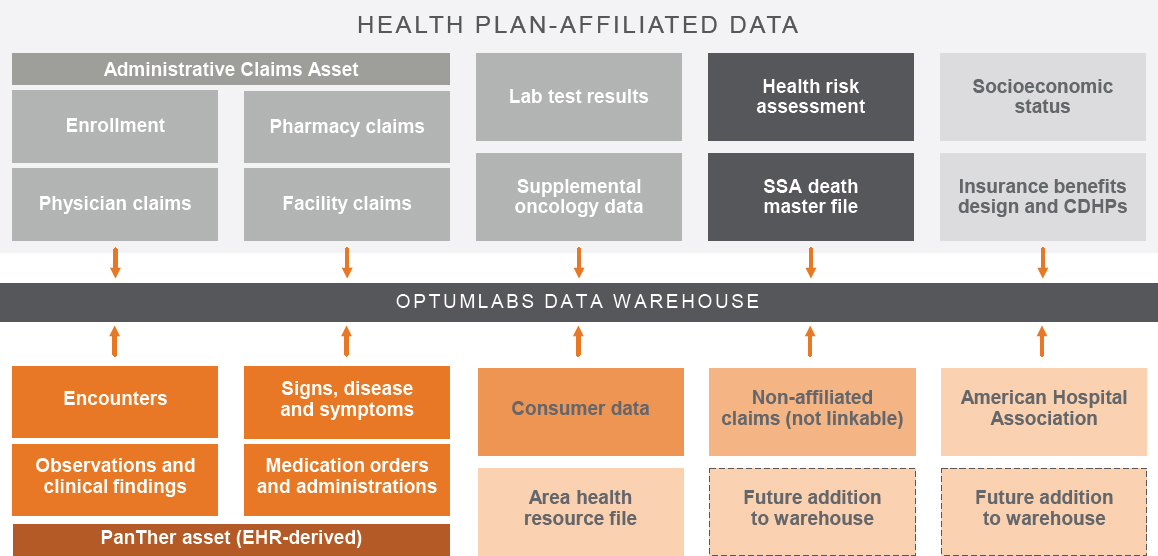
NOTE: CDHP = consumer directed health plan; EHR = electronic health record; SSA = Social Security Administration.
SOURCE: Altan presentation, July 17, 2018.

SOURCE: Altan presentation, July 17, 2018.
The second step, said Altan, is determining the quality and provenance of the data. Similar to the process outlined by Yaist, this requires considering the research question, the audience, and the proposed purpose for the data, and determining what quality standard would be required. For example, a stakeholder looking to use RWD for regulatory purposes requires the highest quality data, whereas a stakeholder seeking data for marketing research does not. Altan also looks for completeness of the data, the availability of linkages among data and whether they have been well assessed, and whether the provenance of the data can be established. Part of the data quality assessment process, said Altan, is examining whether the impact of any quality issues can be understood.
Finally, any sources of bias and their impact should be assessed, she said. Common sources of bias may include missing data, a lack of representativeness of the sample, and the “present patient bias,” where the data only reflect patients who presented for care, but not those who did not seek care. In addition, there may be other biases such as differing policies or care practices. For example, a patient’s insurance policy will affect what his or her claims data look like, said Altan. Two patients, one who has insurance with a capitated model and one who has pay-for-service coverage, are going to have very different claims data, even if their care was similar. These types of bias need to be understood and addressed in order for data to be relevant and useful.
Altan gave an example of how this process would work for a variety of data needs and research questions. One common issue, said Altan,
is missing data and leakage. To illustrate, Altan showed a table of data about hospitalizations for myocardial infarction and what medications were administered during the hospitalization. Some sources reported a very low percentage of patients receiving aspirin, which indicates to Altan that “something is wrong.” These differences might reflect differences among the sources, for example, different EHR platforms or differences in the types of data that each source shares. Regardless of the source of the difference, a discrepancy like this indicates there are missing data in the dataset, and that the calculated average for aspirin use may not be accurate. Robert Ball, deputy director of the Office of Surveillance and Epidemiology at FDA’s CDER, noted that even as RWD sources and the tools for using them improve, it is likely that there will continue to be issues with missing data. One way to address this issue, he said, might be through statistical approaches.
FDA Sufficiency Analyses
Ball shared details of his experience with “sufficiency analyses” in Sentinel, as required by the FDA Amendments Act of 2007, which have the same basic focus as the processes described by the other speakers. Sufficiency analyses, said Ball, ask the questions, “Are the data there for exposures, outcomes, and confounders? Are the methods and tools available? Can it be done with sufficient precision to answer the question of interest?” FDA has conducted these analyses for the use of RWD to study around 100 drug-adverse event outcomes, he said, using Sentinel’s System of Active Risk Identification and Analysis (ARIA). ARIA contains data in a common data model, which includes the “most granular elements that are needed to make the assessments,” clarified Ball. The curation and quality control of the data occur within each data partner, but the use of a centralized approach and centralized software help to ensure that it is an efficient and standardized process. Ball noted that because of the distributed model of Sentinel, it is important to have access to the people who know the data and the data systems. If a problem arises—such as missing or incomplete data—their knowledge of the data is critical.
PATIENT-GENERATED DATA
Luca Foschini, co-founder and chief data scientist of Evidation Health (Evidation), spoke about the current state and the future potential of patient-generated health data (PGHD). Foschini noted that currently, most RWD still comes from health system data, which is episodic and limited. PGHD, on the other hand, can be continuously collected, helping to illuminate patient experience between clinical visits. A key challenge with these
data, especially when passively collected from wearables and sensors, is that they generate huge volumes of data. For example, he said, a patient who has undergone a knee arthroscopy has perhaps dozens of data points in the claims data over the course of 1 year—the procedures undergone, the drugs taken, and the physical therapy conducted. On the other hand, the same knee arthroscopy can be measured by a device that logs steps to track patterns of physical activity, potentially generating hundreds of thousands of data points over the course of 1 year. At scale, these types of devices are being used to collect RWD for millions of patients, accumulating trillions of data points, he said. Processing this volume of data requires infrastructure designed to intake, clean, and normalize continuous data. In addition to its volume, the complex nature of the data requires analytical approaches such as artificial intelligence and machine learning, he said.
PGHD can come from a wide variety of sources, said Foschini, such as devices attached to a person’s wrist or shoe, implantables, and smart devices in the home or car (Gambhir et al., 2018). In addition, there are PGHD available from social media sources, as well as data that patients report themselves such as surveys or diaries. Foschini said that because there are so many potential sources of PGHD, “the hope of having a common data model for [all the disparate kinds of] PGHD is doomed”; researchers should not wait for a common data model before beginning to use these sources, he said.
Foschini discussed the value of PGHD, and how it can be used to answer research questions. He gave examples using several types of PGHD and their value for research. Evidation conducted analysis for a study that used wearable activity trackers to study patients with multiple sclerosis. One finding of the study was that it took people with multiple sclerosis a significantly longer time to fall asleep at night (see Table 6-3). This outcome, said Foschini, had never before been measurable.
TABLE 6-3 Patient-Generated Health Data for a Study of Multiple Sclerosis (MS)
| Activity Trackers Only | MS Trackers | Matched Control Trackers |
|---|---|---|
| N | 498 | 1,400 |
| Percent of Days with Tracked Steps* | 73% | 77% |
| Mean Daily Stepcount* | 6,379 | 7,188 |
| Mean Nightly Sleep Duration (Hours) | 6.3 | 6.5 |
| Max Time to Fall Asleep (Minutes)* | 18.58 | 13.91 |
NOTE: * p < 0.001 corrected for false discovery rate.
SOURCES: Foschini presentation, July 17, 2018; Evidation and Novartis, 2018.
The second example that Foschini presented was using both retrospective passively collected data with data prospectively collected from patients. In this study, Evidation had access to several million participants who had consented to share their data for this analysis, said Foschini. Participants also completed a survey asking if they had had any major medical procedure or surgery, and for more details about it if they had. Evidation then analyzed the types of surgery against the participants’ resting heart rate, among other variables, and was able to observe the effect of weight loss procedures on resting heart rate, which had not been possible to capture before in real-world settings (see Figure 6-7). This study, said Foschini, took less than 1 month to conduct. There is a real opportunity to use this model, in which participants are already sharing data, can be consented for a particular use of those data, and can be asked to provide additional information through survey questions, in order to quickly and easily collect fit-for-purpose RWD.
PGHD, said Foschini, can blur the line between RWD and data from clinical trials. For example, at the time of the workshop, Evidation was beginning a new study that ultimately enrolled 10,000 patients and collected prospective data on chronic pain through both devices and self-reported surveys. The data collected, said Foschini, will be an RWD source, but the study process is governed by a traditional clinical trial protocol. In fact, he worked with the Clinical Trials Transformation Initiative (CTTI) on its recently released guidance about how to use mobile devices for data
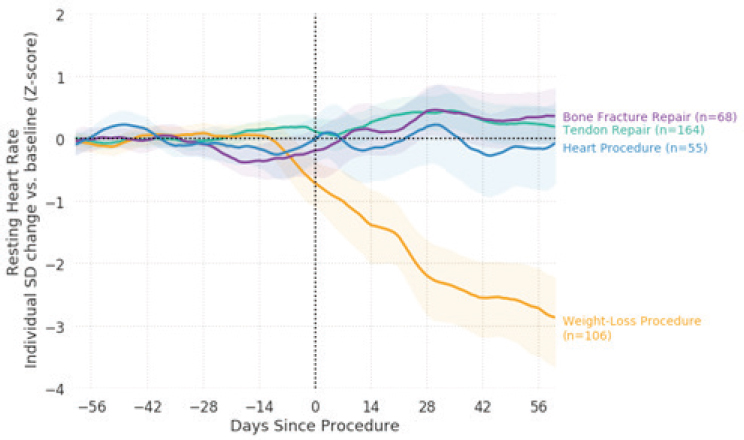
NOTE: SD = standard deviation.
SOURCE: Foschini presentation, July 17, 2018.
capture in clinical trials.1 Foschini said the findings and recommendations of the CTTI report, as well as from the Duke-Margolis Center for Health Policy work on characterizing RWD quality and relevancy,2 will be relevant for many sources and uses of PGHD. Other workshop participants discussed the potential of PGHD when linked with additional data sources (see Box 6-2).
“Traditional” RWD are collected in a clinical setting (e.g., EHRs or claims data), said Foschini. In many ways, the considerations about relevancy and quality of data are the same for PGHD and traditional RWD. Regardless of the source, data need to be available for key elements, need to be representative of the population, and need to be accurate and complete, he said. Some of the potential data issues with PGHD also exist in traditional RWD. For example, data collected in a clinical setting can have the “present patient” bias, in which only patients who present for care are represented in the data. A similar bias is possible in PGHD, said Foschini, because patients who are unwell may choose to wear (or not wear) the device, thus “censoring their outcome” in a way similar to patients who present for care.
___________________
1 See https://www.ctti-clinicaltrials.org/programs/mobile-clinical-trials (accessed January 4, 2019).
2 See https://healthpolicy.duke.edu/sites/default/files/atoms/files/characterizing_rwd.pdf (accessed January 4, 2019).
There are potential types of bias and confounders that are unique to PGHD, said Foschini, and those need to be addressed. For example, in traditional RWD, a provider inputs data into the EHR or claims system, and in general not much thought is given to how this user experiences the system. With PGHD, the end user is the patient or participant, and there may be biases based on the user experience, said Foschini.
Data from PGHD are potentially incredibly valuable and rich, said Simon, but they also may be quite chaotic. A challenge will be in monitoring and interpreting the data stream so that the data are useful rather than overwhelming.
DISCUSSION: REAL-WORLD DATA CONCERNS FOR FUTURE RESEARCH
During the second and third workshops, participants engaged in discussions that reflected on specific questions around the use of RWD (some of which were listed in the draft decision aid), as well as exploring related or new topics that emerged.
Real-World Data Compared with Data from Randomized Controlled Trials
While it is clearly important to ensure that RWD are accurate and reliable, said Robert Califf, it is also important to acknowledge that data from RCTs are not always accurate or reliable. RCTs are a relatively closed system, and the data they collect can be limited and skewed, he said. For example, treatments that are meant for long-term use in the real world cannot be fully assessed in short-term, controlled trials. For this reason, relying solely on RCTs and ignoring the data available in RWD could be “dangerous to the intended population,” he said, and called for validation of both RCT data and RWD.
A workshop participant said that clinical trial endpoints do not always align with real-world endpoints, nor are they always relevant to patients. Hernandez responded that while some clinical trial endpoints are extremely relevant—for example, survival or staying out of the hospital—he agreed that there are different preferences over the journey of a patient, and that they should be considered going forward. In mental health practice in particular, said Simon, validated endpoints are quite often not relevant to patients’ real-world experiences. For example, a patient does not care about a score on the Yale-Brown Obsessive Compulsive scale, favoring instead daily function and quality of life. In this area, said Simon, it is imperative to not treat these existing measures—which are often used for RCTs—as the gold standard against which to validate RWD. Daniel added that it is
important to make sure that endpoints are relevant to the ultimate decision maker, whether that is the patient, payer, or provider. Daniel said the endpoints that are studied in clinical trials may not necessarily need to be altered, but suggested instead focusing on developing an “evidence package” that includes trials, RWE, and other sources of information to get a well-rounded picture.
In considering the relevance and quality of a data source, said Yaist, one of the main considerations is whether the data are representative of the population of interest. Data that are to be used for a regulatory decision need to reflect the U.S. population, she said. Unfortunately, there are few data sources, including EHRs and claims, that truly reflect the population. When using these large data sources, she said, researchers need to “really think about systematic bias” that may be present. For example, researchers should consider the clinical context of the data source and how certain patients may be represented while others are not.
One potential way to minimize bias from RWD, said Marc Berger, former vice president of Real World Data and Analytics at Pfizer, is to use multiple datasets. “You should never trust any one study,” said Berger. Using multiple datasets increases the likelihood that bias will be minimized, because each dataset may have different biases that cancel each other out (see Box 6-3).
Dynamic Data
Rima Izem, senior mathematical statistician at CDER, said one of the unique characteristics of RWD is that they are dynamic—the data change over time, which changes the answers that can be derived from the data. Many studies are predicated on the assumption that the data are static, and algorithms are validated based on the data at one point in time, she said. But with RWD, prospective data are always changing, and even retrospective data can change because data from other sources may be added to the dataset. Altan shared an example of the dynamism of RWD. Researchers were using data from claims and EHRs in a study, and during the course of the study, the provider of the EHR data had a change in their client base that caused data to be removed from the environment and changed the sample size.
Another way in which RWD can change over time, said Altan, is through changes to practice patterns for particular diseases. In a longitudinal study that may last multiple decades, the data about clinical care and clinical outcomes can change substantially as there are regulatory changes, formulary changes, or changes to standard of care. Simon added that coding can also change over time—for example, during a study on suicide prevention, the International Statistical Classification of Diseases and Related Health Problems (ICD) codes for self-harm changed dramatically between ICD-9 and ICD-10. As a result, the researchers had to adjust the outcome specifications during the trial, he said.
Berlin stressed that because of this dynamism of data, it may be necessary to reassess the tools used to analyze data—for example, the algorithms that are validated for a certain condition may need to be revalidated after changes have occurred. Most importantly, he said, the data tools and methods need to be transparent, so that all stakeholders can understand how the data have been collected, curated, and analyzed.
The Importance of Sharing
Deven McGraw, deputy director for health information privacy at the U.S. Department of Health and Human Services’ Office for Civil Rights at the time of the workshop and currently chief regulatory officer at Ciitizen, observed that nearly any use of RWE and RWD requires some amount of data sharing. Currently, the rules and regulations about data make it “perfectly permissible . . . for you to do nothing but sit on the data that you are collecting,” she said. There are perverse incentives that discourage sharing, she said, because when data are shared, there are rules and conditions that must be followed. The hurdles to sharing are even higher for data that are related to sensitive conditions such as mental health or substance abuse, she said. Clearly, patient privacy and security should be
protected. However, the current system tilts the scale so far in the direction of privacy that data are “buried in the backyard” and are not shared and used to their full potential. The regulatory environment, said McGraw, has unintentionally created disincentives for sharing, and it is time to “rethink our regulatory framework and take the thumb off of one side of the scale and try to put it on the other side of the scale.” However, allowing any and all kinds of sharing would not necessarily be beneficial, she said, and a framework of accepted principles could be essential for reducing risks and increasing benefits.
Transparency of Data Source and Curation
Berger said there is a lack of transparency around RWD and how they are curated. Transparency would allow researchers to check the original source document against the curated data in order to evaluate the quality of the curation, he said. Grazyna Lieberman, director of regulatory policy at Genentech, added that transparency enables assessment of the completeness of data collection, the accuracy of captured diagnoses, and the reliability of the processes to extract the data.
Another area in which there is a need for transparency, said Simon, is in how EHRs assign ICD codes. Simon said that in mental health, providers often do not type in a specific ICD code; rather, they type a text string that results in suggestions of ICD codes. The algorithms that map the text strings to the suggestions are proprietary, said Simon. Unfortunately, for RWD to be reliable, a researcher may need to know not just the ICD code, but also the text string that prompted the code. Transparency about the transformation from the source data to the analytic dataset is essential, he said, particularly in cases where the diagnosis is less straightforward (e.g., different types of depression versus myocardial infarction). One particular benefit of transparency is that it allows researchers to understand and modify code if the researcher wants a tighter or looser definition of a population, exposure, or outcome, said Simon.
There is a need for publicly available, validated, generally accepted algorithms for identifying core clinical phenomena, said Simon. The process of developing and validating these algorithms should be completely transparent, he said. Simon said this is a “higher level of transparency than we are accustomed to,” but it is critical because if a validated algorithm does not work, a researcher needs to be able to look at the building blocks of the algorithm to see where things went wrong. Without transparency, “the assertion that this is a valid phenotype or this is a valid specification will not go far; you need to show your work,” he said.
Context of the Decision
Yaist and Altan both emphasized the importance of considering the type of question that RWD are being used to answer. The research question clearly matters when determining the relevance of the data, but just as important is the context of the decision to be made. For example, said Yaist, if there is already an established safety and efficacy profile for a drug, that is a far different scenario than if RWD are being used to answer initial questions about safety and efficacy. The quality of the data that are needed for these two scenarios is very different, she said. Richard Platt added that there may be different standards for data quality when the data are being used to assess the superiority of a drug versus non-inferiority.
Participants discussed the fact that stakeholders all have a shared interest in the quality of the data, and they all have the same basic goal of improving health care. However, Simon noted, the specific data needs of stakeholders may vary considerably. For example, stakeholders trying to define and measure “myocardial infarction” may draw different boundaries around this outcome depending on whether they are clinicians, payers, or regulators. Some may want higher specificity, but some may need higher sensitivity, he said. There is a shared interest in the quality of the data, but the context of the decision to be made is critical.
Need for Systematic Processes
Ball said that FDA assesses a large volume of RWD studies, so “there has to be a very systematic and efficient process for quality assessment.” He said that while guiding questions such as the ones in the decision aid (see Figure 6-3) are useful and cover many of the key topics, FDA would need the questions to be systematized into an industrialized process.
Ball noted that the current system for assessing and using RWD is quite resource intensive. For example, he said, to validate algorithms used to identify cases of anaphylaxis, subject-matter experts currently manually review medical records to classify cases as to whether they are anaphylaxis. Then, another set of experts identifies the codes to combine in an algorithm and the algorithm is assessed as to how well it can identify the expert-classified cases of anaphylaxis. This process is “slow and inefficient” and costly. Alternatives that are in development include tools such as natural language processing and machine learning technologies, he said. Simon followed up on this point with the observation that creating an industrialized process for quality assessment would not only be more efficient and cost-effective, but would also help to create a culture of quality. This culture, said Altan, could involve data aggregators rethinking or better documenting the process of data collection, cleaning, and curating.
This page intentionally left blank.




























