
3
Case Studies of Models Used
to Inform Health Policy
The workshop’s second panel featured three case studies presented by long-time modelers which were offered to illustrate some of the ways in which models can be used to inform health policy. In each case, said session moderator Pamela Russo, a senior program officer at the Robert Wood Johnson Foundation, the models are nonlinear, dynamic, and interactive, and they cross multiple disciplines. (Box 3-1 contains highlights from these presentations.) David Mendez, an associate professor in the Department of Health Management and Policy at the University of Michigan School of Public Health, discussed tobacco models. Pasky Pascual, an environmental scientist, lawyer, and former director of the Council for Regulatory Environmental Modeling at the Environmental Protection Agency (EPA), described EPA’s use of models to set clear air standards. Bobby Milstein, a director at ReThink Health, illustrated how communities have used models to engage in regional health reform efforts. An open discussion moderated by Russo followed the three presentations.
COMPUTATIONAL MODELS IN TOBACCO POLICY1
As the previous speakers had already noted, there are several good reasons to model, said David Mendez in the introduction to his presen-
___________________
1This section is based on the presentation by David Mendez, an associate professor in the Department of Health Management and Policy at the University of Michigan School of Public Health, and the statements are not endorsed or verified by the Institute of Medicine.
tation on the use of models in tobacco control efforts. One reason is to understand a problem fully, and in that context models can provide a coherent framework with which to analyze a situation and integrate different datasets in a way that mental models cannot. Models, he explained, can be used to monitor, forecast, and evaluate the consequences of policies using “What if?” scenarios that are explored in in silico experiments, and they can identify gaps in knowledge which can guide data collection. In the tobacco control area, models can be used to address such questions as
- If current conditions continue, what is the likely trajectory of smoking prevalence?
- If all the tobacco control measures known to be effective were fully implemented, what is the likely trajectory of smoking prevalence?
- What would be the population health impact of removing menthol cigarettes from the market?
- What would be the consequences of increasing the minimum purchasing age for tobacco products?
- What would be the impact of reducing nicotine in combustible tobacco products to nonaddictive levels?
- What is the estimated impact of tobacco control policies on avoided mortality?
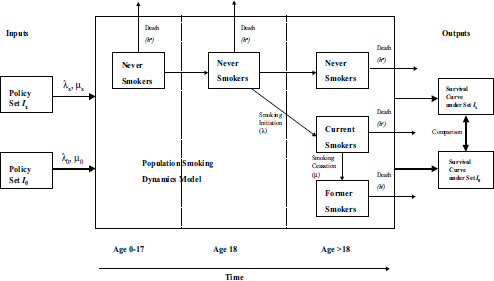
One of the issues that Mendez has been exploring using the Michigan Model of Smoking Prevalence and Health Effects is the effect that tobacco control policies have on the smoking status of individuals. The model identifies individuals by gender, age, when they started smoking, and trajectory, and it tracks these individuals from birth to death. Mendez and his colleagues use these simulations to examine the probability of initiation and cessation and the way those two events interact under different policy scenarios. While the model is constructed to capture the initiation and cessations probabilities at the individual level, it actually follows groups of individuals, which is why this type of model is called an aggregate model (see Figure 3-1). One of the assumptions built into the model is that groups comprising individuals with certain characteristics behave in a homogeneous way, Mendez said.
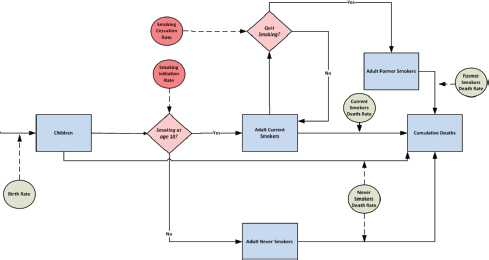
SOURCE: Mendez presentation, April 9, 2015.
Mendez used a bathtub analogy to explain how this model works. Water flowing into the bathtub represents individuals who initiate smoking, and the rate at which water flows out of the tap is analogous to the probability of initiation. Similarly, water flowing out of the bathtub represents individuals who quit smoking plus the number of people who die from all causes. The level of water in the bathtub represents smoking prevalence, and this is what he and his colleagues are interested in and what the model tracks over time.
When building such a model, one of the first tasks is to build confidence that the predictions that the model makes fit with the observed data (see Figures 3-2 and 3-3). “We have some theory about how the elements interact and how people start smoking and quit smoking,” Mendez said, “and we want to make sure that this is a good representation of what is happening in the real world.” When he and his colleagues used data from the National Health Interview Survey to test the model, they found that the fit between the model’s predictions and the data was very good (Mendez and Warner, 2004). They then developed some projections of what would happen with varying initiation rates (see Figure 3-4).
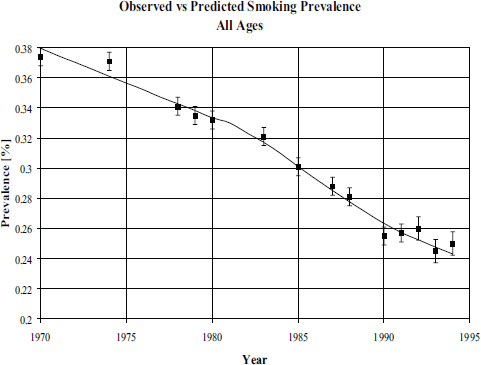
SOURCES: Mendez et al., 1998; Mendez presentation, April 9, 2015.
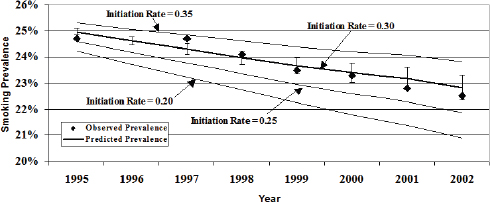
SOURCE: Mendez and Warner, 2004.
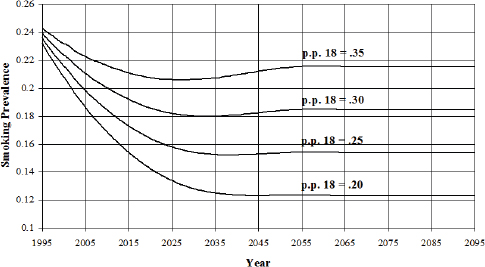
SOURCES: Mendez et al.,1998; Mendez presentation, April 9, 2015.
To understand the health effects of smoking, Mendez and his colleagues used data from the Cancer Prevention Study II to develop relative risks for former and current smokers, both female and male. The model predicts the relative risk of death from the time of smoking initiation and the length of time an individual smoked. He explained that the model
contains compartments that keep track of individuals by age and by when they stop smoking (see Figure 3-5) and that it explores the effects of policies that affect the initiation and cessation rates on mortality and morbidity over time on a population level.
Mendez listed some of the ways in which he and his colleagues have used this model. These included assessing smoking prevalence targets, evaluating the effect of offering smoking cessation programs in managed care organizations, evaluating the impact of menthol cigarettes on a population’s health, evaluating the effectiveness of radon remediation when smoking rates are declining, and evaluating the effect of tobacco control policies on global smoking trends. In the study that evaluated the effect of offering smoking cessation programs in managed care organizations (MCOs), the question of interest was whether offering such programs were cost-beneficial for the MCOs. The answer was that they were not because of the large turnover in managed care organizations. Mendez said that this study was interesting because the presumption was that there would be a clear benefit, but the analysis showed that while the gains for society are substantial, there is no benefit that accrues to a managed health care organization.
For the radon remediation project, the goal was to examine the effectiveness of EPA guidance about remediating homes with high levels of radon. “The problem here is that there was no clear distinction between smokers and nonsmokers when this policy was put in place,” Mendez
SOURCE: Mendez presentation, April 9, 2015.
said, noting that the data show that health risks associated with radon exposure are much higher for smokers than for nonsmokers. The model’s analysis showed that with declining smoking rates, the effectiveness of the EPA recommendation is questionable (Lantz et al., 2013; Mendez et al., 2011).
To evaluate the potential impact of tobacco control policies on global smoking trends, Mendez and his colleagues used data from World Health Organization databases and explored what would happen with the world prevalence of smoking if current conditions continued compared to an environment in which a comprehensive package of well-known effective tobacco control strategies was implemented. “The World Health Organization has found this information useful as it attempts to communicate the possibilities of tobacco control worldwide,” Mendez said.
For the United States, Mendez and University of Michigan colleague Kenneth Warner used this model to analyze the possibility of meeting the Healthy People 2010 goal of achieving a smoking prevalence rate of 13 percent. This analysis showed that this goal was unreachable since even if the initiation rate for smoking went to zero, the cessation rate would have to increase by more than threefold to achieve a 13 percent prevalence in 2010. If the initiation rate dropped to 15 percent by 2010, cessation rates would need to increase more than fourfold to reach the target. “The targets were made without thinking about the mechanisms that drive prevalence,” Mendez said. “Our projections were that prevalence would be between 18 and 19 percent, and that is where we were in 2010, at 19.3 percent.” He commented that the problem with setting unrealistic goals is that the community will get discouraged. “It is not that we fail with tobacco control policies,” he said, “but because the goals were so outrageous, the public health community feels like a failure by not achieving them.”
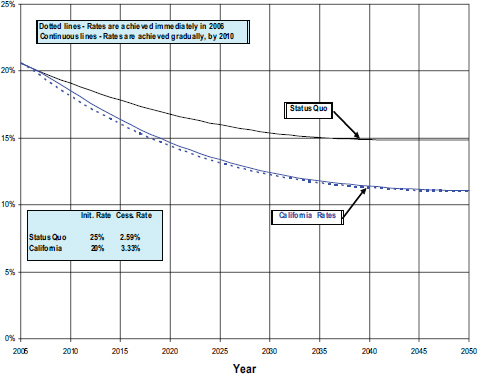
Rather than just pointing out the error of setting unrealistic goals, Mendez and Warner used their model to set a goal for 2020 that would be feasible. To do this, they chose the policies that California had enacted and that have driven the prevalence of smoking in that state to 14.7 percent (Mendez and Warner, 2008). Under the optimistic conditions that assume the nation can achieve California’s initiation and cessation rate, the model found the nation would still not achieve California’s current prevalence level until after the year 2020 (see Figure 3-6).
In a project commissioned by the Tobacco Product Scientific Advisory Committee of the Food and Drug Administration (FDA), Mendez modeled likely outcomes from removing menthol cigarettes from the market. The results projected that an estimated 328,000 premature deaths would be avoided over a 40-year period if menthol cigarettes did not exist and that there would be 9 million fewer new smokers over that same period. Based at least in part on this study, the advisory committee determined
SOURCES: Mendez and Warner, 2008; Mendez presentation, April 9, 2015
that removing menthol cigarettes from the market would benefit public health.
In his final comments, Mendez highlighted two modeling efforts conducted by other investigators. The SimSmoke model, developed largely by David Levy at the Georgetown University Medical Center, simulates the dynamics of smoking rates and smoking-attributed deaths in a state or nation and also the effects of policies on those outcomes. This model shows that the effects vary with the way a policy is implemented and by demographics, and it points out the dynamic, nonlinear, and interactive effects of smoking policies (Levy and Friend, 2002; Levy et al., 2013). The Cancer Intervention and Surveillance Modeling Network, funded by the National Cancer Institute, is a network of modelers looking to improve understanding of cancer control interventions. Using data from the National Health Interview Survey, this group can reproduce the history of smoking for any cohort in the U.S. population, and it has evaluated the impact on lung cancer and overall mortality of smoking control policies enacted since 1964. By the network’s estimates, some 8 million pre-
mature deaths have been avoided and mean lifespan has been extended by 20 years (Holford et al., 2014).
DEFENDING PUBLIC HEALTH MODELS IN THE COURTROOM
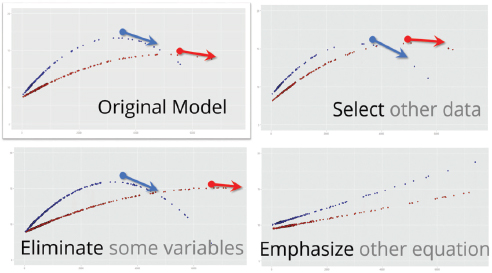
Pasky Pascual started his presentation by talking briefly about a modeling technique that he has used, called hierarchical Bayesian modeling, to investigate the relationship between charged particles and oxygen in two streams just north of Washington, DC. The results that the model produces, he said, depend heavily on the data used to initialize the model, the variables chosen for inclusion in the model, and on the specific equations in the model that are emphasized (see Figure 3-7). “If these models remained on my laptop, they continue to be an interesting intellectual exercise,” Pascual said, “but the moment I use any of these models to make a decision that affects other peoples’ lives in a significant way, that is a problem.”
Models are everywhere, Pascual said, and any major regulation that is issued by EPA is ultimately based on a model. With his colleagues Elizabeth Fisher from Oxford University and Wendy Wagner at the University of Texas School of Law, Pascual has written two papers discussing the use and abuse of scientific and social-scientific models in environmental policy (Fisher et al., 2010; Wagner et al., 2010). Litigants will
SOURCE: Pascual presentation, April 9, 2015.
challenge models by mischaracterizing them as belonging to two different extremes, Pascual said. At one extreme, models are portrayed as being truth engines, which means that as soon as the model makes an error, it becomes invalid. At the other extreme, models are seen as being completely malleable and therefore should be considered arbitrary and capricious under the law.
The reality is that models fall somewhere between these two extremes, Pascual said. “There are indeed uncertainties that prevent us from making perfect predictions, but there are evaluation methods that help us distinguish between models that are truthful and those that are merely ‘truthy,’” he said, borrowing that last word from the lexicon of Stephen Colbert. In reality, every modeling approach has its own intellectual foundation and its own assumptions, which Pascual and his colleagues refer to as a model’s epistemic frame (Pascual et al., 2013). For example, in 1962 FDA, in responding to the thalidomide crisis, stated by way of regulation that the best scientific evidence for evaluating drug risks comes from randomized clinical trials. Implicit in that decision, Pascual said, was that FDA prescribed one particular statistical method for drawing inferences. Over the years a number of panels, including those organized by the Institute of Medicine, have been recommending that FDA take a more agnostic view of modeling, and, in fact, Congress mandated in the 2007 FDA Reauthorization Act that the agency take a more universal view of modeling. Pascual and his colleagues used the FDA Reauthorization Act to make the case that models used for regulatory decision making need to be transparent in terms of both the methods used and the epistemic framework of those methods.
In an upcoming paper, Pascual and his collaborators discuss how model transparency leads to both legal accountability and defensibility in the context of the Clean Air Act. He said that while the Clean Air Act is complex, there are four important features regarding the implementation of air quality standards that are important to know for this discussion: The standards have to protect public health, be based on the latest science, be reviewed by a science panel, and be subject to judicial review. That last feature means that if a stakeholder with established standing disagrees with the model that EPA used to make its regulatory decision, the stakeholder can force the agency to defend the model in court.
In the early years of EPA’s regulation of ambient air quality standards, there were 16 court cases challenging the agency’s decisions, and the court’s approach to evaluating the science was, as Pascual characterized it, “very ad hoc.” The court’s approach was reminiscent of Justice Potter Stewart’s comment on pornography in that the court seemed to say that it could not define what good science is but that it would know it when it saw it. “If you read the cases, they are rather incoherent and not very
cohesive,” Pascual said. In 2008, though, EPA laid out its causal epistemic framework and challenged the court to judge its decisions against this framework. In the past courts said that controlled human exposure trials, like randomized clinical trials, engender the highest level of confidence about the causal relationship between ozone exposure and health effects. However, as Hammond pointed out earlier in the workshop, randomizing different groups and exposing them to different concentrations of toxics would not be ethical. The agency’s models computationally control for other covariants that might interfere with this causal relationship. In essence, this approach to science says that given a particular level of a pollutant, the models, based on data from human and animal exposure, suggest that a particular health effect will result. If the data come from controlled human studies or from observational studies that rule out chance, the agency determines that a causal relationship exists. If the data come from observational studies with possible confounders plus animal toxicity studies, the agency considers that it is likely that a causal relationship exists between exposure to a pollutant and an adverse health effect.
In concluding his talk, Pascual offered a quote from the statistician David Box, who said, “Every model is wrong, but some are useful.” No model is perfect, Pascual said, but by making a model transparent and providing a framework for evaluating a model’s performance, an expert scientific panel should be able to evaluate the validity of a model to a degree that the model will hold up in court. In the end, Pascual said, modeling is nothing more than a formalized method of questioning.
MODELING REGIONAL HEALTH REFORM USING THE RETHINK HEALTH DYNAMICS MODEL
Health data show that there are regional patterns that transcend the specifics of any disease or physical exposure, said Bobby Milstein, and this is true for the way that health care is delivered and how much it costs and with regard to the social, economic, and environmental conditions that leave people vulnerable to risk and disease. The challenge of addressing health reform at a regional level is what drove Milstein and his colleagues at ReThink Health to develop a model that can be used by those working to address health reform at the regional level to ask questions about the likely health and economic consequences of their efforts under realistic regional conditions that account for local trends related to a wide range of factors. These factors include insurance expansion, demography, aging, inequities, health status, the quality and cost of health care, the demand-supply for health care resources, provider payments, among others. Nobody can keep all of these dynamic factors in mind simultaneously when making choices about what actions to take,
Milstein said. In short, the model is meant to be used by people who are immersed in systems they do not fully understand and help them make better informed decisions.
ReThink Health started its efforts in Pueblo, Colorado, when Milstein and his colleagues met with leaders who were addressing a regional health reform agenda. Together they framed an approach to look at a number of policies and actions that these leaders thought were within their capabilities to influence in the region. From that start, ReThink Health’s efforts expanded to five additional sites in the first year and then three more over the next 3 years for a total of nine sites. The model is also being incorporated into an increasing number of academic curricula as future leaders are beginning to think about how the health care system works and about some of the conditions under which it might be able to change. Recently, for example, the National Association of Schools of Public Policy, Affairs, and Administration, a network of almost 300 academic institutions across the country, held its first student simulation competition on health policy. On one day, some 200 students at 93 schools sat down to think about how the health system might work and what their roles as policy makers would be.
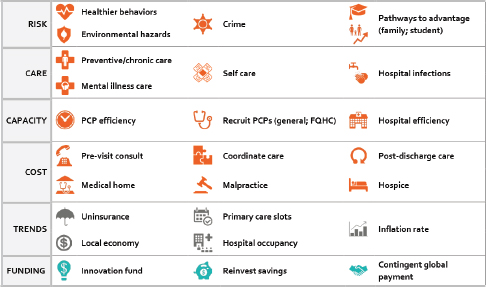
Users of this model, Milstein said, confront a stewardship challenge as they attempt to craft strategies that will steer their health system in a new direction, not just in the short term, but in an enduring way over time. The model’s logic incorporates three questions that policy makers ask in the real world, Milstein said: What shall we do, how will we pay for it, and how proud would we be of the consequences? The model provides an intentionally diverse menu of intervention options, with several dozen initiatives that policy makers could choose to change with regard to upstream and downstream initiatives and also financing within a regional health system (see Figure 3-8). For example, planners can focus on actions to cut health care costs, improve quality, or expand capacity as well as wider efforts to enable healthier behaviors, reduce environmental hazards, improve public safety, and expand socioeconomic opportunities that strongly shape health and well-being while also affecting the demand for expensive downstream health care. Every item on this menu, he explained, has been documented to make a difference in and of itself, yet there are open questions about how they might be combined to make a greater difference and how much ought to be invested in different contexts. These items can be tested alone or in combination, and Milstein presented two quick scenarios to illustrate the types of insights that users have begun to obtain with this model.
One scenario explores a suite of strategies designed to move the health system’s overdependence on tertiary care through hospitals and specialists to one that relies more on primary care combined with a greater role
NOTE: FQHC = Federally Qualified Health Center; PCP = Primary Care Physician.
SOURCE: Milstein presentation, April 9, 2015.
for self-care and medical homes. This approach begins with an assumption, which can be easily varied, that start-up funds are available from a temporary innovation fund set at 1 percent of total health care spending for just 5 years. Also, it assumes that half of any savings that accrue from lower health care costs will be reinvested in the endeavor, which is similar to what many accountable care organizations are doing; furthermore, it is assumed that there will be a shift in provider payment away from fee-for-service to per capita payment. This scenario also emphasizes greater adherence to guidelines for preventive and chronic care and also serious efforts to coordinate care by eliminating unnecessary services that increase cost but do not improve health. Together, Milstein said, this combination of strategies represents an evolution toward higher-value preventive and chronic care. Simulated results show that these downstream investments can deliver relatively fast, focused impacts but that their effects tend to plateau (see Figure 3-9). Models can also have mixed results on cost and inequity. While this scenario decreases dependency on hospital inpatient stays, which in turn lowers cost, there are also fewer premature deaths, more primary care visits, more services for prevention and chronic care, and more extensive use of self-care products such as prescription drugs, all of which increase costs elsewhere in the system. “What is the balance of those? I can’t do that in my head, and that is exactly why we need com-
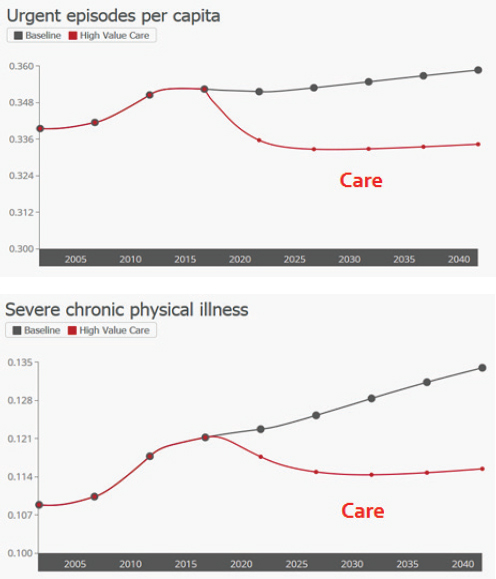
SOURCE: Milstein presentation, April 9, 2015.
puters to play this out against the other changing dynamics in a region,” said Milstein.
A second scenario tested a more balanced approach, with those same downstream components now coupled with upstream investments to enable healthier behaviors and safer environments. According to that model, the added emphasis on healthier behaviors and environments
could unlock much greater health and economic potential, Milstein said, noting that the upstream elements yield broad progress on health, cost, equity, and workforce productivity (Milstein et al., 2011). The effects can be large, he added, but they accumulate gradually (see Figure 3-10).
The health consequences from the combined, balanced scenario grow stronger over time, although the distinct benefits compared to the first scenario do not become apparent until after about 8 years. The same is true for cost savings. The larger suite of initiatives is more expensive to implement, but it may still be affordable when coupled with gains from the downstream reforms. Milstein claimed that with health care costs on track to grow even larger, many regions may not be able to afford not to make these cost-saving investments. In one scenario, for example, although downstream investments save nearly $1 billion, when combined with upstream investments funded by gain-sharing agreements, the savings are 50 percent greater (see Figure 3-11). The challenge, as this scenario shows, is that there is an initial increase in spending that may make the necessary initial investments difficult to secure. “There is typically a worse before better pattern,” Milstein said. “In all scenarios where you are making these investments, the question is how fast you get that yield and how happy are you with that yield.” Another important insight from
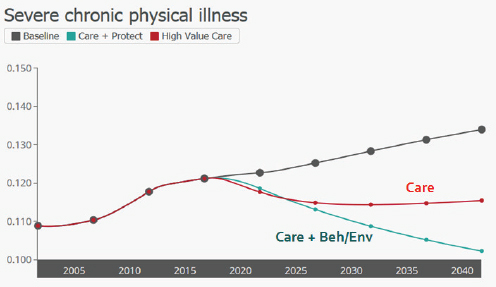
NOTE: Beh = behavior; Env = environment.
SOURCE: Milstein presentation, April 9, 2015.
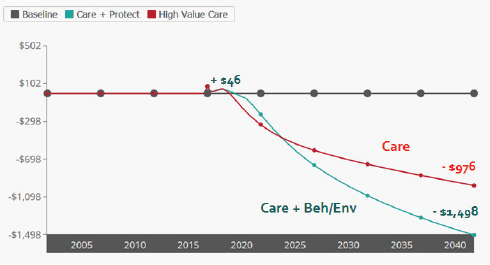
NOTE: Beh = behavior; Env = environment.
SOURCE: Milstein presentation, April 9, 2015.
these modeling exercises, he added, is that balanced strategies can drive greater economic productivity which provides a return beyond that from simply reducing health care costs.
This is a well-designed model that has been widely tested and closely matches dozens of observed times series data, Milstein said. But, like all models, it is still an inexact representation of the real world. One limitation, he added, is its 25-year time horizon, which is much shorter than a full life course, which would be needed to accurately represent the benefits of other investments, such as intervention in early childhood. The model also has a relatively high level of aggregation, which is appropriate for its focus on strategy designs, Milstein said, but if one wanted to delve into, for example, the details of which behaviors would make the biggest difference, that would require a different type of tool which was focused on tactics and specific program portfolios.
One of Milstein’s biggest priorities is to guard against two extremes that are fraught with peril: an overreliance on an imperfect model versus an under-reliance on analytical tools to compensate for known flaws in people’s mental models. Decisions made in the absence of a credible model essentially depend on people’s ability to think through the complexity of a vast health system, which turns out to be notoriously difficult, if not impossible.
In his closing comments, Milstein said that he and his colleagues have examined carefully the conditions under which models can help leaders make big breakthroughs in their practice. “It is very rare for a model, in and of itself, to drive change. It really is best done when it is coupled with a sense of strong stewardship by people who come to the table thinking of themselves not as leaders of their institutions or thinking of their own narrow self-interest, but recognizing that they are part of a system upon which we all depend,” said Milstein. Working through the economics of marshalling and governing common resources is a large part of this stewardship, he added. “Having a sound strategy and the muscle to enact it means very little if you can’t gather the resources to direct to those priorities.”
DISCUSSION
Robert Kaplan from the Agency for Healthcare Research and Quality began the discussion by asking the panelists to react to the following information. Over the past 20 years, Kaplan said, most major randomized controlled trials in preventive medicine have shown that the intervention does not make much difference, even though almost all of those trials have positive effects for surrogate outcomes. On the other hand, almost every modeling study using surrogate outcomes predicts that there should be positive effects. Both the modelers and the researchers carrying out the trials then claim that the other approach is wrong because it is too simplistic. Pasqual replied that he and his colleagues discussed this very issue in detail, using the Vioxx crisis as a starting point. One thing they found is that the design for the Vioxx randomized controlled trial screened out the very people who were most likely to experience the adverse effects that later caused trouble. In his opinion, he said, the current approach to hypothesis testing that drives trial design is flawed, and it is only recently that Bayesian methods and other analytical models that can handle distributions that are not Gaussian, binomial, or in general well-behaved and that can make use of all of the available data have become amenable to analysis in a meaningful way.
John Auerbach from the Centers for Disease Control and Prevention asked the panel to talk about the challenges associated with having non-homogeneous populations and, in particular, with having subpopulations that may be affected differently by different interventions. Too often, he said, models that may be true for general populations are used to make extrapolations about the efficacy of an intervention in a subpopulation with different characteristics. Milstein responded that there is nothing like modeling and the need to make explicit the assumptions that go into a model to expose the fact that the data may not exist to support all of those
assumptions for all populations. If there are reasons to suspect that an intervention may be less effective in one group than in another, the model can be run over a range of scenarios, some more pessimistic and others more optimistic. What is important, he said, is to craft a research agenda that asks which interventions need to be tested more consistently across many different contexts and groups. Mendez added that models also provide a framework for understanding where assumptions are important and where they are not and where more data are needed to better understand the effects of heterogeneity. Pasqual noted that hierarchical Bayesian approaches are particularly useful for better understanding how subpopulations fit into the larger general population.
Marc Gourevitch from the New York University School of Medicine asked Milstein how the ReThink Health model makes predictions in the aggregate over time. Milstein responded that the model is not actually making predictions about the future because the world is complicated and models cannot anticipate surprises, nor are these models trying to estimate what the health of the population or the cost of health care will be in 25 years. What the models are doing, he explained, is playing out the consequences of actions taken now to see how long and how strong those effects can be and what the general trajectory of their effects might be relative to a clearly defined status quo scenario. “The purpose for building the model is to ask if it is within our latitude of influence to change present circumstances,” Milstein said. From the users’ perspective, these models enable them to think about the how the choices that they make today may play out over a long period of time. “My understanding is that this is a valuable perspective for leaders to have,” Milstein said.
A workshop participant from the National Association of County and City Health Officials, commenting on the widespread use of data by local health departments to improve public health and the time limits of those data, asked the panel to talk about the challenges and successes they have experienced in gathering the data needed to support models at the community level. Milstein said that the issue of getting the right kind of data at a regional level in a timely manner was something that those at ReThink Health were very conscious of when they began constructing the organization’s model. The discipline that goes into building such a model is intertwined with how the model represents phenomena, and that representation depends on having data. “Everything that ends up in the model has to be linked to evidence,” Milstein said. It is the case, he added, that there is a great deal of information and uncertainty in the available data, including experiential data that have not been formally documented but that can provide valuable information about how these systems tend to work and how they have been changing over time. Milstein also said that the ReThink Health model maps data from more than a dozen dif-
ferent sources into a common framework, and as such, it does not rely on one dataset. For example, though the goal is to get as much local data as possible, the ReThink Health model also uses datasets from state and national sources, and it makes demographic adjustments that are subjected to uncertainty analysis to fill gaps at the local level. Fortunately, he noted, the health area is a data-rich environment. “That does not make for perfect models, but it does make for well-informed ones,” he said. Having said that, Milstein added that there is a need for more consistent longitudinal data, and he said he hopes that as modeling gains more traction, it will create a demand for better longitudinal datasets.
Addressing a question from Russo about whether ReThink Health uses data from the community, Milstein said that he would never start a modeling project without access to community data, but that there is always a need to turn to other data sources for data elements that are not available locally. In California, for example, the enhanced California Health Interview Survey is a rich and valuable source of information for representing cities in that state. He added that if a region is systematically different from the state average for some reason, his team can address that using local data. As a final comment, he emphasized that the lack of data is not an excuse to not model.
Jeffrey Levi from the Trust for America’s Health commented on the lack of data that are collected on the effectiveness, value, and cost of interventions and asked the panelists what type of standardized information they would like to see gathered by federally funded and philanthropically funded studies collect so that their models would be more robust. Mendez replied that one of the important data gaps in tobacco control concerns how people transmit smoking behavior and how people communicate their intent to quit or to engage in smoking. “These social networks are becoming more and more important in order to study this area of tobacco control,” Mendez said. “We are looking at the landscape that is much more heterogeneous right now and is much more complex, and we don’t have a good dataset that would inform how these interactions are going to play out.” Milstein added that almost every part of the model and modeling process could be better informed, but that when it comes to representing initiatives and what-if scenarios, his wish list for better data would include information on the cost to implement specific innovations, the extent to which they were actually implemented, and the percentage of the population they reached.
Staying on the topic of data gaps, Robert Grist from the Institute of Social Medicine and Community Health said that one area that had not been mentioned so far was the lack of data on the political constraints that affect interventions. “I am wondering how modeling can begin to incorporate political factors that influence the kinds of interventions that
are considered politically realistic,” Grist said. “In the absence of that kind of information, I am not sure we are going to get the kind of political accountability that we would need to change the system in ways that would promote public health.” Pascual replied by asking if there would be a way of coding this kind of unstructured information so that it can be captured in one of his models. Mendez said that there is no formal way to incorporate the type of feedback that can influence decision making through the lens of a political agenda. What is possible is to conduct some type of sensitivity analysis with regard to possible delays in implementing a policy. Patrice Pascual from the Children’s Dental Health Project spoke of a recent modeling project she was involved in that examined ways of reducing cavities early in childhood. Those running the project dealt with the political ramifications of the model’s findings by taking those results to the community and letting the members of the community think about the political ramifications of the different pathways the community might take to achieving a goal. As the final comment in the discussion, she noted that this approach speaks to the comments from Victor Dzau about taking results to the community and letting the community take action.




















