
6
Opportunities for the Future
The workshop’s final panel session focused on current work that has important implications for the future of public health policies. Darshak Sanghavi, the director of the Population and Preventive Health Models Group at the Center for Medicare & Medicaid Innovation (CMMI) of the Centers for Medicare & Medicaid Services (CMS), described some of the innovative work that his group is doing to help transform the nation’s health care system. Rajiv Bhatia, the founder and director of The Civic Engine, then spoke about some of the lessons he has learned from experiences in conducting health impact assessments. An open discussion moderated by Steven Teutsch followed the two presentations. See Box 6-1 for highlights from these presentations and discussions.
OPPORTUNITIES IN PREVENTION AND POPULATION HEALTH CARE MODELING1
According to Darshak Sanghavi, a model is a simplified representation of a real-world situation that is used to answer a specific question, and to him, he said, this represents a kind of intelligence or an ability to take something complex and make it simple. At CMMI, he said, intelligent predictive modeling is at a premium because he and his colleagues have
___________________
1This section is based on the presentation by Darshak Sanghavi, Director of the Population and Preventive Health Models Group at the Center for Medicare & Medicaid Innovation, and the statements are not endorsed or verified by the Institute of Medicine.
to engage with a variety of different stakeholders, including patients and policy makers, in a way that resonates, is understandable, and remains true to the facts.
One of the central themes in the workshop discussion about health care and predictive modeling was the need to make decisions based on limited information which may or not be related to the outcome of interest. Sanghavi used reality competitions on television to illustrate this point. In such competitions, the ostensible goal is to identify the most talented performer, and that is done by popular vote, but the real goal, he said, is to win advertising dollars and television viewers. In a drug trial, the ostensible goal is to help a hyperactive first-grader grow into a productive, job-holding adult, while the real goal is to find a drug that leads to improved scores on an attention deficit/hyperactivity disorder (ADHD) symptom assessment. In both cases, Sanghavi said, there is
limited information at first, but the hope is that this limited amount of information will help provide a useful prediction of what will happen at some point in the future.
This is important, he explained, because of the need to use predictive analytics to identify new incentives to move toward better health care that focuses on value and performance. Performance, Sanghavi said, is judged on the basis of meeting surrogate endpoints. For example, the real goal may be to reduce heart attacks in middle-aged men a few decades in the future, but performance is judged based on reductions in cholesterol levels. Similarly, the real goal may be for a hyperactive first-grader to be able to hold down a good job as an adult, but performance is judged based on improved scores on a symptom checklist, or the real goal is to prevent hip fractures in an elderly woman, but performance is judged according to bone density scans in perimenopausal women.
Sanghavi and his colleagues are trying to determine if judging performance on the basis of surrogate endpoints is a good strategy, given that the relation of a surrogate endpoint to the actual desired outcome may be weak or nonexistent and that an intervention can improve the surrogate outcome but also have adverse side effects. “One thing I always think about with predictive modeling is how in actual clinical care the amount of uncertainty is vast,” Sanghavi said. “Given all this uncertainty, how should CMS or any major payer, deal with it in ways that enhance value through the smarter use of predictive modeling?”
One predictive model that he and his colleagues are developing—which Sanghavi said he hopes will soon be cleared for public release—is called the Million Hearts Preventive Cardiac Model, and it represents what Sanghavi called a new way of thinking about prevention. This model was developed with the aim of reducing the number of heart attacks and strokes, a goal that society has deemed important. In the past, efforts to reach this goal have relied on setting and hitting targets for blood pressure, smoking, and cholesterol, but these may not have been the best surrogates to target, Sanghavi said. For example, several different pharmaceutical therapies have been shown to reduce cholesterol levels but increase the number of heart attacks, which suggests that cholesterol level alone is not a good surrogate for heart attack prevention.
A better strategy for preventive cardiology would take into account a number of surrogates, and Sanghavi used an iPhone app, the atherosclerotic cardiovascular disease (ASCVD) Risk Estimator from the American Heart Association and the American College of Cardiology, as an example. The app uses cholesterol, high-density lipoprotein (HDL) cholesterol, systolic blood pressure, sex, age, ethnicity, smoking status, and whether an individual is being treated for hypertension or diabetes to calculate a 10-year risk for atherosclerotic cardiovascular disease. To show
how it worked, Sanghavi displayed the score for a hypothetical individual with a 60 percent 10-year risk of heart attack, and he explained that the incentive would be based on reducing that aggregate risk score, not on any of the specific risk factors that were used to calculate that score. “And because we know this is a predictive analytical model,” Sanghavi said, “we know that this will correlate to the endpoint of interest over the long term. This is one of the first times that we believe that we can start to incentivize prevention in a whole different way using a predictive modeling algorithm.” The strength of this model, he added, comes from the fact that cardiology is a field rich in data from extensive, well-run clinical trials, but it is his hope that this type of model will pave the way for other analytical models.
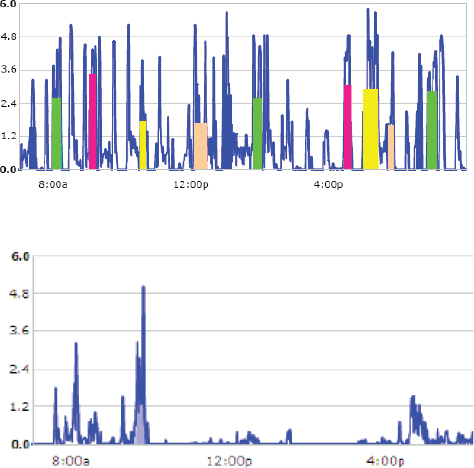
Data for predictive modeling can come from many sources, and the key is to use those data to provide feedback that will change behavior, Sanghavi said. For example, pediatric obesity is tied to inactivity, and as an illustration Sanghavi showed the data from a pedometer that his 4-year-old son wore on a trip to Disneyland and in daycare (see Figure 6-1). Seeing this data convinced Sanghavi to create more activity opportunities for his son.
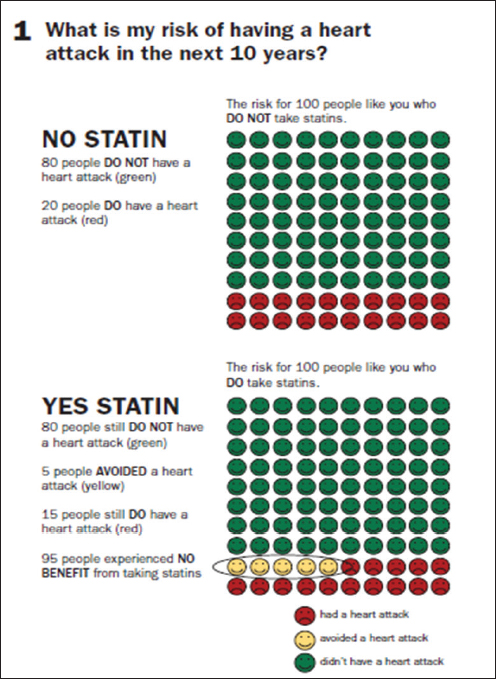
Similarly, seeing the data from the ASCVD Risk Estimator provides feedback that a patient and physician can use to change behavior and lower the risk score. Having said that, Sanghavi was critical of the claims being made for the ability of statins to reduce the risk of heart attack by as much as 36 percent, when the important number to convey to patients, he said, is their absolute risk of having a heart attack (see Figure 6-2).
In his brief closing comments, Sanghavi said that he and his colleagues are developing a model that will be used to determine how best to structure accountable health communities to address problems while efficiently using resources. He also provided a link to an interactive and predictive analytical model that evaluates the spread of HIV and cost per HIV infection averted for various interventions and public health strategies in two settings, New York City and East Africa.2
LESSONS FROM MODELS FOR POPULATION HEALTH3
In the workshop’s final presentation, Rajiv Bhatia discussed some of the experiences that he has had over the past 15 years of conducting health impact assessments (HIAs), which he described as a trans-disciplinary decision-support practice that anticipates the health effect of
___________________
2See http://torchresearch.org.
3This section is based on the presentation Rajiv Bhatia, founder and director of The Civic Engine, and the statements are not endorsed or verified by the Institute of Medicine.
SOURCE: Sanghavi presentation, April 9, 2015.
a decision prospectively. HIAs, which were started in European countries in the 1990s and brought to the United States in 1999, are intended to serve the knowledge needs of democratic decision making using a few different types of models. They use conceptual models to explain the nexus between policy and health, and they use quantitative models to quantify the effects of decision on health determinants and outcomes.
As an example of a model used in HIAs, Bhatia showed a map of areas of San Francisco with an unacceptable air pollution health risk based on the levels of airborne particulate matter found there—levels that are known to be associated with an unacceptable mortality risk—and also on the levels of airborne carcinogens, which are associated with a separate
SOURCES: Mayo Clinic, 2015; Sanghavi presentation, April 9, 2015.
unacceptable risk (see Figure 6-3). The model used to calculate air pollution health risks was produced by combining two off-the-shelf models, one to model air pollution and the other to translate air pollution levels into health risks. The problem that this HIA was trying to address was that in San Francisco, as in most cities, there is one air pollution monitoring station that is located far from any significant air pollution sources and that therefore cannot identify pollution hot spots. Using a model that had been developed to identify areas in San Francisco that exceeded federal and state pollution levels, Bhatia and his collaborators helped the city’s planning office justify and craft a policy to prevent poor indoor air quality in new housing. With the help of the model’s output, San Francisco passed the first ordinance in the country that imposed a higher standard for ven-
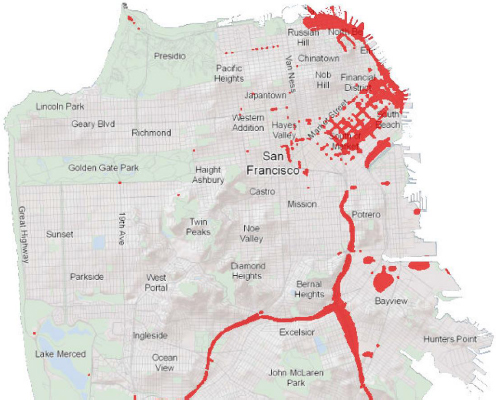
NOTE: Locations exceeding health standards marked in red. Health Based Standards: Fine particulate matter (PM2.5) concentrations greater than 10 micrograms per cubic meter (including background levels) and excess cancer risk greater than 100 per 1 million people exposed.
SOURCE: Bhatia presentation, April 9, 2015.
tilation in buildings erected near air pollution hotspots, and the city later imposed a transportation impact fee for those hot spot regions. The health outcomes and costs associated with traffic air pollution were added to the total costs of adding an additional vehicle to the city, which were then used to justify a fee that developers would pay for every additional vehicle that they would be causing to be brought into the city, Bhatia said. He added that this model was also used to examine how targeting weatherization programs to pollution hotspots could have additional social benefits.
Another use of HIAs was to identify hotspots for pedestrian injuries and fatalities in San Francisco. The object of this modeling exercise was to examine how the patterns of pedestrian injuries related to the design and operation of city streets. Using a binomial regression model that took as its inputs vehicle and pedestrian volumes, traffic speed, road and intersection characteristics, and area population characteristics, the model explained about three-quarters of the variance in pedestrian injury density among city census tracts and produced risk information to inform city planning decisions. Traffic volume accounted for a third of the explained variation, Bhatia said, and quantifying the pedestrian injury risk attributable to traffic volume has contributed to policy solutions, including the imposition of the aforementioned traffic impact fee on new development as well as changes in the focus of police enforcement and in the approach of the city’s traffic engineers to pedestrian safety. In fact, Bhatia said, the results of the model triggered a new focus on calming traffic on busy arterial streets.
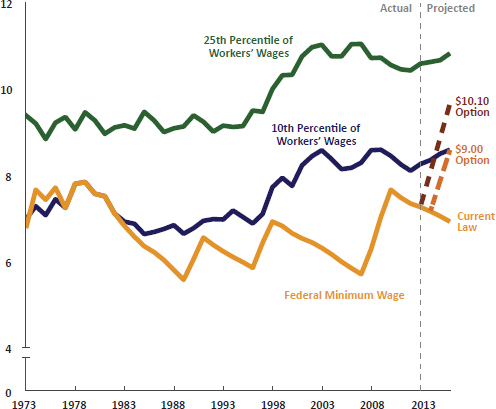
One of the first HIAs that Bhatia and his colleagues performed looked at the health impact of changing the minimum wage in California. Again, this effort required combining two models, one that related the minimum wage to the distribution of income per household, and the other that related income to mortality (see Figure 6-4).
Bhatia said that each of these models had tremendous limitations and involved making numerous assumptions, but that they were good enough for the purposes they needed to serve. Health data and science do not usually have leading roles in public policy beyond the health care and environmental sectors. “The uses of HIA and modeling were highly selective and opportunistic and focused on timely policy issues where we already had constituents engaged in the issues and constituents that we anticipated to be ready users of the information generated,” Bhatia said. He also noted that modeling in HIA is purpose driven. In the case of the examples he presented, for instance, the modeling was done to solve a defined problem for which specific gaps in knowledge were limiting factors in developing a policy solution. “The models were directed toward finding a particular piece of information: Where are the areas with air pollution above a certain standard, and what was the attributable risk
SOURCE: Bhatia presentation, April 9, 2015.
of pedestrian injuries to differences in traffic volume or traffic speed?” Bhatia added that he expects that policy systems will respond to the new information based on an understanding of existing regulatory systems and stakeholder and agency interests. A primary audience for the models and the information they generated were community constituencies, which then used the information from the models as evidence for their arguments in the policy process.
Bhatia said that one of the most interesting and innovative aspects of this work was that he did not have to create a model but was able to use models that had already been built. He did have to find these models, but after that it was a matter of getting local data to apply to the model. For example, a prototype for the pedestrian injury model had been developed and validated by the Federal Highway Administration, and Bhatia and his colleagues took that best practice model and replicated it in San Francisco. Similarly, the air quality models were approved and used by
environmental agencies but had not been applied to looking at street-by-street differences in air pollution levels. In the case of the impact of wages on health outcomes, there were well-described models linking income and health outcomes, but there was no model linking wages and health outcomes, which required Bhatia and his colleagues to join up models that linked wages with income and income with health outcomes.
One conclusion that Bhatia said he drew from his experience is that simpler and easier-to-explain models work best. “The models did not represent the whole world,” he said, “but they represented important pathways that we could use convincingly to influence decisions.” He also said that the low specificity and long latency of the determinant–outcome relationship hampers the credibility of models in public policy. For example, mortality is a powerful and motivating outcome, yet it is affected by multiple factors over a lifespan. Another lesson he has learned is that information value comes from explicitly linking policy endpoints (e.g., wages) and health outcomes, legitimizing community arguments, attributing and localizing risks, and supporting policy implementation.
Looking to the future, Bhatia said that the field is very far from modeling the social production of health over the lifespan and that the current research on population health determinants is often disconnected from public policy research. For example, in 2008, when he was looking at the health impact of paid sick days, he could find only four studies on the impact of paid sick days on overall health, the best of which was in the economics literature. Few health researchers thought of paid sick days as a determinant worthy of study, which Bhatia thought was striking.
In his opinion, too few epidemiological studies examine public policies as risk factors directly, which limits the evidence available for modeling how policy affects health. The public health sector looks at and acts on community-level data on conditions, while the health care sector looks at and acts on individual-level data on clinical outcomes, which creates a disconnect among sources of evidence. Models that would be useful for prevention and public policy could benefit from population health information systems that integrate clinical outcomes collected routinely by health care systems with individual-level social, economic, and environmental factors.
The last point Bhatia made was that model building is a technical process, and technical research is usually the easiest element of a successful policy process. You can find a way to model a relationship well if there is motivation to do so, Bhatia said. “The more important questions are what information do we need to make better decisions, who wants the information, and how will they use it.” The answers to those questions lead to design criteria for an initial modeling exercise, but ultimately
model building is an interactive and collaborative process that will also involve the users who have to apply a model and see if it works for the purpose at hand.
DISCUSSION
Sharon Cooper opened the discussion by asking Sanghavi if CMS considers unintended consequences when it models the impacts of potential policy changes, particularly with regard to reimbursement, given the challenges of states such as Georgia that are largely rural and that are already experiencing a shortage of physicians. Sanghavi replied that this is a problem that needs to be addressed through risk adjustment, whereby physicians are paid more for treating higher risk patients, and that CMS is working through the challenges of addressing this issue.
David Kindig then asked Sanghavi if his group at CMMI is thinking about how to model making reimbursements for improvements in the short term but also reward physicians for gains that may come from downstream factors that require longer time frames to show their effects. Sanghavi’s response was that in the switch from a fee-for-service to a pay-for-performance reimbursement model, the goal is to first demonstrate near-term benefits and savings before trying to tackle longer-term effects. Pasky Pascual said that he has a mental model of how a modeling process should go and that when he considers the future of modeling, he thinks about two important points in a model’s life cycle. When a model is given to the users, he would like to see it reduced to the level of an app and at the beginning of the lifecycle, all data should be available in a structured format, such as XML, that anyone can download and use in whatever application they desire. He cited Major League Baseball as an exemplar for providing years of data that can be downloaded from its website in a standard, machine-readable format. In contrast, Pascual said, every government website that he has accessed data flunks this data format test. Bhatia agreed that there are many encumbrances to accessing the data needed to understand population health dynamics and that more needs to be done to link datasets representing determinants and outcomes. Sanghavi agreed that the current status of data availability from many sources is poor, but that CMS has taken the first step by simply making the data available and is working to do better.
Sanne Magnan said that she was excited by the work being done with the cardiovascular risk calculator because it could be laying the groundwork for providers to build bridges with those working in the community and those working on public health, and she suggested that CMS encourage that trend. She also wondered if CMS was thinking about how to incentivize accountable health communities to invest some of the cost sav-
ings that they will realize in both population health and the social determinants of health. Bhatia made the point that while the health system is responsible for collecting information on community risk factors and health outcomes, it is not the lead actor for fixing those parts of the social system that result in externalities on human health. “One of the challenges in talking to the people in health systems about considering the social determinants of health is that they do not think they can fix those problems and so they are reluctant to collect the information,” Bhatia said. There needs to be a mechanism by which information on socially attributable health risks is used to send a signal to other systems that have the responsibility for solving these problems, he said.
Mary Pittman, of the Public Health Institute, said that she had not heard much during the workshop about the wildcards of technology and other sources of innovation. Telemedicine, for example, could play an important role in alleviating access problems, while crowdsourcing could serve as an efficient method for gathering information quickly. She asked the panelists if they could talk about how they consider wildcards in their modeling activities and how to address getting input through crowdsourcing and other forms of social media. Sanghavi said that the way CMMI is thinking about wildcards is to build flexibility into the methods used to incentivize care. He cited diabetes prevention as an example. The proven way of reducing the risk that prediabetes will progress to full-blown type II diabetes in adults of all ages is via 16 weeks of twice-weekly visits to the doctor, but that is not scalable. However, the Centers for Disease Control and Prevention (CDC) has developed remote technologies that perhaps could deliver the same intervention with equal effectiveness, and the way to model this would be to identify specific outcomes, such as maintaining weight loss for 1 year, while using broad parameters to represent interventions.
Bhatia then addressed Pittman’s question about abundant new forms of information. The challenge, he said, will be for population health interests to guide the information that will be collected. He cited the Apple Research Kit as an example of the willingness of individuals to contribute health data for the public good, and he said it is now up to the public health community to decide what kind of information it wants from this willing population of individuals.
George Isham asked Bhatia if he could comment further on the idea of collecting data on the social determinants of health at the individual level. Bhatia replied that some health care providers will routinely ask patients about nonclinical risks such as food insecurity or housing instability and will help their patients navigate access to community services that they need. However, he added, collecting the information only in vulnerable populations at the point of care will not provide knowledge of such things
as what the total cost of food insecurity is to the health system. “The only way to get the answer to that question is to collect risk factor information systematically on the entire population, from those that are experiencing problems and those that are not,” Bhatia said. He suggested that payers and insurance plans could lead such an effort. He added that Medicaid in particular would benefit from collecting nonclinical risk factors identified from epidemiological social determinants research at enrollment and using this data to shed light on what the differential cost and utilization of these risk factors are. In an ideal policy system, policy makers and legislators would use this information to make investments in programs that address social and economic needs to reduce health care spending. It will be important, Bhatia said, to develop a more immediate use case for private payers and insurers to get them involved in this effort. One could argue, for instance, that the data could be used in predictive modeling for high-risk events. The data could also be used to support care management and to develop new programs to address some of the social determinants of health.
Isham also commented that Sanghavi’s presentation raised the idea of using modeling as an operations tool for practicing medicine in a sophisticated large-scale environment. Over the past several decades, for example, his organization has looked at preventive care in physician’s offices across Minnesota as a suite of activities that have an evidence base that can be used to build an algorithm for the physician to use to recommend the best set of actions for each patient. With a good corresponding metric, that algorithm can be evaluated over time. To be most useful, Isham noted, the federal government needs to be organized so that it consistently convenes experts to do the science in the rigorous way that the U.S. Preventive Services Task Force does its studies. Today, however, those efforts are scattered across the government, with CDC issuing some recommendations and the Health Resources and Services Administration issuing others, and there is little consistency across these recommendations. Isham suggested that it would be useful for the government to think about the larger systems organizations and pressure points as it begins to look at these composite measures and models. He also noted that there are opportunities to use these data to create predictive analytics for physicians to use at the point of care as well as apps that would engage the public.
Sanghavi agreed with Isham that there is clinical medicine being done at the population level today, and as an example he noted that a hospital might examine its patients census to identify those at highest risk of readmission based on a predictive analytic score and then target those patients for special outreach so that they do not become readmitted. Accountable care organizations also incentivize hospital system clinicians
to take a population-wide view of patients, identify those who are potentially at highest risk of bad outcomes or becoming high-cost patients, and then intervene appropriately. Sanghavi characterized that as a high-level policy decision and said that CMS hesitates to become prescriptive about the actions that hospitals and clinicians should take to address those high-risk patients because that just recapitulates the fee-for-service system.
Having said that, Sanghavi added that there is still a great deal to learn to get to the personal aspect of decision making and the reach the app level that Isham proposed. The challenge is to encourage innovation that will address all areas of health care, not just the “big money” areas such as cardiology. Pediatrics, for example, is not an area where there are big savings to realize today, and in caring for the elderly there are many conditions that affect the quality of life but are not high-cost items. These are areas that CMMI is targeting, Sanghavi said, “so that clinical leaders can approach their chief executive officers and say, ‘This pilot test showed that paying for this value-oriented service, whether it is preventive cardiology or treating ADHD, makes financial sense, so why don’t we build this into our framework?’ That is where we hope innovation can occur.”
A workshop participant asked if it would be possible to develop risk-adjustment measures for social determinants in the Medicaid payment model, and Sanghavi answered that this is an issue that CMS struggles with because it means that if some Medicaid agencies pay more for complex patients, they might choose to pay less for some other group of patients. He added that CMMI can build models to address complexity, but such efforts are multifaceted. Jeffrey Levi commented that it is incorrect to say that the Medicaid system is a zero sum game. “One should not assume that because you are paying more for socially complex patients that there may not in the end be savings from managing that patient in a better way,” he said.














