
2
Background
2.1 STUDY TASK AND SCOPE
The National Science Foundation (NSF) requested that the National Academies of Sciences, Engineering, and Medicine carry out a study examining anticipated priorities and associated trade-offs for advanced computing in support of NSF-sponsored science and engineering research. The scope of the study encompasses advanced computing activities and programs throughout NSF, including, but not limited to, those of its Division of Advanced Cyberinfrastructure. The statement of task for the study is given in Box P.1. This final report from the study follows the committee’s interim report issued in 2014.1
In this study, advanced computing is defined as the advanced technical capabilities, including both computer systems and expert staff, that support research across the entire science and engineering spectrum and that are so large in scale and so expensive that they are typically shared among multiple researchers, institutions, and applications. The term also encompasses higher-end computing for which there are economies of scale in establishing shared facilities rather than having each institution acquire, maintain, and support its own systems. At the midscale, the demarcation between institutional and NSF responsibility is not well established (Box 2.1). For compute-intensive research, it includes not
___________________
1 National Research Council, Future Directions for NSF Advanced Computing Infrastructure to Support U.S. Science and Engineering in 2017-2020: An Interim Report, The National Academies Press, Washington, D.C., 2014.
only today’s supercomputers, which are able to perform more than 1015 floating-point operations per second (known as “petascale”), but also high-performance computing (HPC) platforms that share the same components as supercomputers but may have lower levels of performance. As used here, the term encompasses support for data-intensive research that involves analyzing terabytes (and increasingly petabytes) of data as well as modeling and simulation.
Historically, and even now, NSF advanced computing centers have focused on high-performance computing primarily for simulation. Although these applications are essential and growing, the new and very rapidly growing demand for more data-capable services still needs to be addressed. This chapter looks chiefly at traditional HPC, while the new opportunities and challenges of the “data revolution” are emphasized in Chapters 4 and 5.
2.2 PAST STUDIES OF ADVANCED COMPUTING FOR SCIENCE
In the early 1980s, the science community developed several reports regarding the lack of access to advanced computing resources. The 1982 report Large-Scale Computing in Science and Engineering, known as the “Lax report,”2 was jointly sponsored by the Department of Defense (DOD) and NSF, with cooperation from the Department of Energy (DOE) and the National Aeronautics and Space Administration. It focused on the growing importance of supercomputing in the advancement of science and the looming gap in access to and capability of these resources. The Lax report noted that the United States was at risk of losing its lead in supercomputing and that the development of new systems (especially those relying on new architectures such as massively parallel machines) would require continued investment by the federal government and that the commercial sector could not be expected to provide the necessary research and development (R&D) support. The report proposed four thrusts for a national program:
- Increased access to supercomputer resources through a nationwide network,
- Research in software and algorithms for the expected changes in hardware architectures,
- Training of staff and graduate students, and
- R&D for future generations of supercomputers.
___________________
2 Panel on Large Scale Computing in Science and Engineering, Report of the Panel on Large-Scale Computing in Science and Engineering, National Science Foundation, Washington, D.C., 1982, http://www.pnl.gov/scales/docs/lax_report1982.pdf.
The Lax report led to the first round of NSF supercomputer centers established in 1985-1986. While a subset of these centers continued through 1997, the director of NSF commissioned the Task Force on the Future of the NSF Supercomputer Centers Program in 1994, chaired by Edward Hayes.3 The report of the task force, issued in 1995, put forth many of the points from the Lax report, noting that supercomputing would enable progress across many areas of science and this progress would depend on continuing development of highly trained personnel as well new algorithms and software. The Hayes report made many recommendations that focused on both “leading-edge sites” and broader partnerships that would include experimental and regional facilities. The net result was that the report recognized that there would be fewer leading-edge sites to accommodate more systems below the apex of the computational pyramid. This was manifested as the Partnership for Advanced Computational Infrastructure (PACI) from 1997 to 2004. PACI was supplemented by the terascale initiatives in 2000, which led to the creation of the TeraGrid in 2004, which transitioned to the present-day Extreme Science and Engineering Discovery Environment program.
The 2003 Atkins report4 articulated a more ecological, holistic view of cyberinfrastructure-enabled research, including computing, data stewardship, sensing, activation, and collaboration, to create a comprehensive platform for discovery. It was followed by a series of workshops and reports exploring the role of cyberinfrastructure to particular research communities.5
In 2005, NSF’s Office of Cyberinfrastructure released the solicitation “High Performance Computing System Acquisition: Towards a Petascale Computing Environment for Science and Engineering” (NSF 05-625). This was the first in a series of solicitations along different tracks, culminating in the Blue Waters petascale facility at the National Center for Supercomputing Applications (NCSA) that began operating in 2013.
The past reports present common themes, many of which persist today, as this report will show. Today, advanced computing capabilities are involved in an even wider range of scientific fields and challenges, and the rise of data-driven science requires new approaches. The gap between
___________________
3 Task Force on the Future of the NSF Supercomputer Centers Program, Report of the Task Force on the Future of the NSF Supercomputer Centers Program, National Science Foundation, Washington, D.C., September 15, 1995, http://www.nsf.gov/pubs/1996/nsf9646/nsf9646.pdf.
4 National Science Foundation, Revolutionizing Science and Engineering Through Cyberinfrastructure: Report of the National Science Foundation Blue-Ribbon Advisory Panel on Cyberinfrastructure, 2003, http://www.nsf.gov/cise/sci/reports/atkins.pdf.
5 National Science Foundation, “Reports and Workshops Relating to Cyberinfrastructure and Its Impacts,” http://www.nsf.gov/cise/aci/reports.jsp, accessed January 27, 2016.
supply and demand, noted in the Lax report, remains an important issue. The need to maintain and grow the workforce, especially in regard to the needed skills, remains a persistent issue. The evolution in hardware and the subsequent impacts on algorithms and software has been a recurring concern. However, changes in architectures have been far more disruptive over the past decade, and broad commercial trends influence the HPC market more than ever. Finally, increasing use of large-scale computing by the commercial sector offers some new opportunities and challenges.
2.3 HIGH-PERFORMANCE COMPUTING TERMINOLOGY
This report refers to a number of concepts from HPC. These terms do not have precise definitions but are valuable in referring to qualitative properties of different kinds of computing and computing systems.
- Capability computing refers to computing that requires the most capable systems, typically the most powerful supercomputers.
- Capacity computing refers to computing with large numbers of applications, none of which require a “capability” platform but in their aggregate require large amounts of computing power.
- High-throughput computing refers to the use of many computing resources over a period of time to attack a particular set of computational tasks.
- Leadership class is a term for the most powerful computing systems. This has typically been based on the floating-point performance of the computing system, though a more comprehensive metric can be used. See Figure 4.1 (Branscomb pyramid) for one (though dated) ranking of computer systems from desktop through leadership class.
- High-end computing covers computing from systems larger than a system that a single research group might operate through leadership class systems. There is no accepted definition for how powerful a system must be to be considered a high-end computing system. The terms “supercomputer” and “high-performance computer” have similar, imprecise meanings.
- Ensemble computing often refers to the use of many runs with different input data or parameters to explore the sensitivity of the problem to small changes.
- Tightly coupled computing refers to computations where each computing element must exchange data with some other computing elements very frequently, such as once per simulation time step. Such computations require a high-performance internode interconnect.
- Memory capacity limited refers to applications that have more demanding requirements than others. For example, simulations in three
-
dimensions of large domains can require very large amounts of memory; a 10,000 × 10,000 × 10,000 cube requires 1012 points or roughly 1 TB of storage per variable stored.
- Peak and sustained performance. Peak performance refers to the performance of a computing system that is theoretically possible. It usually refers to floating-point performance and assumes that the maximum number of floating-point operations is performed in every clock cycle. No applications run at the peak rate. Sustained performance is the performance that an application or a collection of applications can sustain over the course of the entire application.
This report avoids the terms “capability computing” and “capacity computing” because they are too imprecise and have also historically been too focused on floating-point performance.
2.4 STATE OF THE ART
The past several decades have seen remarkable progress in computer hardware, algorithms, and software. This section reviews the state of the art in hardware, software, and algorithms, with a particular emphasis on the challenges created by the disruptive changes in computer architecture driven by the need to increase computing power.
2.4.1 Hardware
The past decade has seen an enormous disruption in computer hardware throughout the computing industry, as processor clock speed increases have stalled and parallel processing has moved on-chip with multicore processors.6 The primary drivers have been power density and total energy consumption—concerns that are important in portable devices and increasingly in large data and compute centers due to fundamental cooling limits of packaging and overall facility infrastructure and operations costs. The continued growth in transistor density had been used primarily to add more processor cores, starting with dual-core chips in the mid-2000s to 20-core chips a decade later. But these processors were historically designed to maximize performance without a strong constraint on energy use; a second trend has been the growth of many-core architectures that involve a larger number of smaller and simpler cores, each more energy efficient than a traditional processor. In aggregate, a
___________________
6 For more on this challenge and its implications, see National Research Council, The Future of Computing Performance: Game Over or Next Level? The National Academies Press, Washington, D.C., 2011.
processing chip with hundreds of simpler cores can often provide much higher computational performance than a smaller number of more powerful cores. The many-core designs include graphical processing units (GPUs) and were initially designed as accelerators to a traditional CPU, whereby software primarily ran on the CPU but could offload computing-intensive kernels to the accelerator. More recent many-core designs provide for stronger integration between the accelerator and CPU, allowing for shared memory between the two or stand-alone processors made entirely of many-core chips. Box 2.2 contains further discussion of these architectural challenges.
One consequence of the growth in the use of computing by all aspects of society and not just for science research is that much of the investment by both computer hardware and software vendors is directed at the larger commercial market for computing. An example of this is the use of GPUs in computational science. These processors have been adapted to support computational science, but the initial innovations were made to serve the gaming market. As the commercial markets continue to grow and new applications are developed, advanced cyberinfrastructure will need to continue to figure out how best to exploit innovations and advancements in the greater commercial market.
Looming ahead is the end of transistor scaling, which will mean an end to the current strategy of improving computing performance by adding more cores per chip. The result is unlikely to be a discrete stopping
point in chip density, but rather a continued slowing of improvements based on technical and cost challenges, as well as diminishing returns on investments if the density improvements do not immediately equate to improvements in cost performance of computing devices.
The problem of declining performance improvements is not limited to science and engineering applications, but high-end computing with its emphasis on benchmarks and scaling may be the place where slowing the rate of performance improvements will be most obvious. One place where this slowing of performance improvement can be seen is in the bottom of the TOP500 list, which is based on the performance of a simple dense linear algebra algorithm. Since the late 2000s, the rate of performance improvement for the systems at the bottom of the list (still very fast) has fallen considerably.
Memory system design is also undergoing rapid changes, as new forms of on-package dynamic random-access memory (DRAM) memory provide enormous bandwidth improvements but currently less capacity than off-chip DRAM. At the same time, new forms of non-volatile memory have been developed with much higher bandwidths than disks but somewhat different performance characteristics than DRAM. These features may be of particular interest to data analysis applications, although many simulations are also limited by data sizes and could benefit. These new types of memory may be added to the hierarchy in a current system design, but they may be under software rather than hardware or operating system control. In general, data movement between processors or to memory is expensive in both time and energy, so hardware mechanisms that automatically schedule and move data may be replaced by simpler mechanisms that leave data movement under software control.
Although each of these innovations is designed to increase performance while minimizing energy use, they pose significant challenges to software. The scientific modeling and simulation community has billions of dollars invested in software based on message passing between serial programs, with only isolated examples of applications that can take advantage of accelerators. Shrinking memory size per core is a problem for some applications, and explicit data movement may require significant code rewriting because it requires careful consideration of which data structures should be allocated in each type of memory, keeping track of memory size limits, and scheduling data movement between memory spaces as needed.
Further disruptive innovation is on the horizon. For example, processor-in-memory technology has been advanced as a way to reduce memory latency and increase bandwidth, and memristors could potentially be used for non-volatile memory with a very high density and fast access times.
The scientific computing community therefore must balance (1) leaving software and programming models unchanged and giving up on opportunities for more computing performance that come from these hardware changes with (2) developing new codes based on new programming models, such as those being researched within the DOE exascale initiative, that can exploit the new hardware. Some type of energy-efficient processing and memory system will be necessary for building an aggregate exascale capability that NSF can afford to operate, whether that is in a single system, in many systems, or partially based on commercial cloud resources. The breadth of NSF’s workload and the number of architectural options complicate this decision. On the surface, the many-core processors may be best suited to compute-intensive simulation problems, yet some data analysis workloads, such as image analysis and neural net algorithms, run effectively on GPUs, while highly irregular simulation problems so far do not. Non-accelerator many-core options such as the Intel Phi may provide more familiar programming support and more workload flexibility, but may not achieve the same performance benefits. Further, they are relatively untested and had yet to demonstrate high performance across a wide range of applications at the time this report was prepared.
Data storage has also undergone its own exponential improvement, with both data densities (bits per unit area) and bit per unit cost doubling every 1 to 2 years. New technologies are providing revolutionary advances and blurring the line between “storage” and “memory.” However, while the technology continues to improve, the rate of improvement has fallen off in recent years. Historically, external storage has primarily meant magnetic hard disk drives (HDDs) in which data are encoded on spinning platters of magnetic media. The vast majority of the world’s online data (some 1-2 zettabytes) are stored on HDD, and this is projected to be the case for at least the next 5 years. Over the course of six decades and driven in part by advances in fundamental material science, HDDs have gone from devices the size of washing machines, storing 3.75 MB, to modern 2.5-in. disks holding 8 TB and up. This expansion in capacity is projected to continue. But capacity is just one of several figures of merit—others include bandwidth, latency, and input/output operations per second (IOPS), which have all advanced at a much slower pace than capacity—and none are anticipated to advance significantly over current HDD technologies that have effective bandwidths of circa 1-200 MB/s, latencies of a few milliseconds, and IOPS of 1-200. This is in part due to the physical constraints of spinning media, but also because investments are focusing on new technologies that are already delivering 1,000-fold advances over HDD in some performance metrics. Parallelism to many disks is required to provide very high data rates. Latencies have not improved as much;
for spinning disks, the latencies are dominated by the disk revolutions per minute and head seek time, which have advanced much more slowly than the densities and transfer rates (bandwidth). In contrast, solid-state disks (SSDs) provide much lower latency and greater data transfer rates. SSDs are presently based on various non-volatile (meaning data persists even without power) silicon memory technologies that will continue to benefit from advances in silicon manufacturing technologies. In the past, SSDs were regarded as both small and expensive, but in the past few years, the capacity of SSDs has approached that of HDDs, and while presently about 3 to 10 times more expensive per byte than HDDs, price parity is expected within several years. With new standards for connecting SSDs to computer systems (e.g., non-volatile memory express), SSDs are now capable of delivering bandwidths of several gigabytes per second, latencies of a few microseconds, and 100,000 IOPS. In addition to use in storage, the price, performance, persistence, and power characteristics of non-volatile memory technologies enable innovations in computer architectures to complement regular DRAM, such as in the proposed DOE pre-exascale systems. In summary, over the next few years, HDD storage capacity will continue to decrease slowly in cost, but various performance metrics will see revolutionary change as non-volatile memory technologies become even more price competitive, and eventually storage capacity itself will fall in cost once silicon technologies dominate.
Advances in storage capacity were critical enablers of the data-intensive Nobel Prize-winning work of Perlmutter (see Box 3.2), as well as the discovery of the Higgs boson at the Large Hadron Collider by an international collaboration storing and analyzing more than 100 PB of data. Diverse other fields of science have been transformed by the ability to manipulate massive data sets from genomics, social networks, video and images, satellite data, and the results of simulations. Looking forward, continued advances in capacity and revolutionary advances in other aspects of data technologies promise new revolutions in science across many fields presently constrained by their ability to store, explore, or analyze their data at sufficient scale or speed.
Because of these relatively high latencies, as well as the limits in bandwidth compared with semiconductor memory, a wide range of memory architectures are being developed with intermediate performance. Some of these will be used closer to the compute elements and have been mentioned above. Others may be used to boost the apparent performance of disks, for example, by providing a higher-bandwidth, lower-latency, temporary buffer that can absorb bursts of data to write to disk. All of these new input/output (I/O) and memory products will need new software and, in many cases, new algorithms that fit their performance characteristics.
The last major component of high-end computers is the internode interconnect; that is, the network that is used to move data between compute elements or between centralized data storage and the compute system. Although the performance of these interconnects has also increased significantly, with bandwidths for proprietary networks used in HPC systems of 40-80 GB/s per link being typical, the latencies have not improved much in recent years, with high-performance interconnects having latencies on the order of 1 microsecond. Commodity interconnects are one to two orders of magnitude slower, with link speeds of 1 GB/s being common, and with 10 GB/s available at the high end of commodity interconnects.
The manner in which the links are connected is also important. There are three separate but related decisions. One is the topology of the connections. High-end supercomputers link nodes directly together in an n-dimensional torus. For example, the IBM BlueGene/Q uses a five-dimensional (5D) torus; the Cray Gemini network uses a three-dimensional (3D) torus, with two compute nodes connected to each torus node. A second is the switch radix—how many ports each switch has. A third is whether the network uses switch notes that are distinct from processor nodes. Recently, interconnect design principles from HPC, such as more highly connected networks with better bisection bandwidth and latencies, have been adopted for commercial applications.7
Also of importance is wide-area networking, which is critical to the success of NSF’s advanced computing, especially in terms of providing access and the infrastructure necessary to bring together data sources and computing resources. The size of some data sets is forcing some data offline or onto remote storage, so storage hierarchies, storage architectures, and WAN (wide area network) architectures are increasingly important to overall infrastructure design. NSF has made significant investments in wide-area networking. The Internet2 network plays an important role in connecting researchers. It carries multiple petabytes of research data and also connects researchers globally with peering to more than 100 international research and education networks. Wide-area networks have a distinct set of technical, managerial, and social complexities that are beyond the scope of this report.
___________________
7 See, for example, A. Singh, J. Ong, A. Agarwal, G. Anderson, A. Armistead, R. Bannon, et al., “Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network,” presented at the Association for Computing Machinery Special Interest Group on Data Communication (SIGCOMM), 2015, http://conferences.sigcomm.org/sigcomm/2015/pdf/papers/p183.pdf.
2.4.2 Software
Although computer hardware will to continue to improve, the rate of improvement has been slowing down and producing increasingly disruptive programming features. Software for scientific simulations for parallel systems with more than a handful of processing cores has largely been written in a message passing model (e.g., with MPI) using domain decomposition, where the physical domain or other major data structures are divided in pieces assigned to each processor. This works especially well for problems that can be decomposed statically and where communication between processes is predictable, involving a limited number of neighbors along with global operations. The assumptions underlying this model are that (1) locality is critical to scaling, so the application programmer needs to do the data decomposition, (2) the network and processors are reliable, and (3) the performance is roughly uniform across the machine. At the same time, many of the data analysis workloads processed on cloud computing platforms have used a map-reduce style in which independent tasks are spread across nodes and results are aggregated using global communication operations at intermediate points. This model allows for hardware heterogeneity or variable-speed processors, but does not permit point-to-communication between tasks. Both models have proven powerful in their own setting.
The relative stability until recently of the hardware platforms has allowed a rich set of libraries and frameworks for simulation to emerge, many supported by NSF (Box 2.3). This includes libraries for sparse and dense linear algebra, spectral transforms, and application frameworks for
climate modeling, astronomy, fluid dynamics, mechanical modeling, and many more. To manage the overall power consumption of larger future systems, it will not be viable to carry out larger computations simply by scheduling threads on more cores. The processors themselves will need to become more energy efficient. As a result, scientific software will need to be revised to take advantage of power-conserving processor features like software-managed memory, wider serial instructions, and multiple data architectures. Scientific libraries face these challenges but are also a point of leverage, allowing multiple applications to benefit from optimizations to new architectures. Looking ahead, substantial investments in software will also be required to take advantage of future hardware, as will research to address new models of concurrency and correctness concerns.
The virtual machine abstractions in the commercial cloud have enabled a different class of applications, with complex workflows for data analysis built and distributed as an integrated software stack. These are particularly popular in biology and particle physics.
2.4.3 Algorithms
The situation is even more complicated for algorithms, where improvements in algorithmic complexity are harder to predict. Not all of the improvements fall into a general category, but some of the common approaches include hierarchical algorithms, exploiting sparseness or symmetry, and reducing data movement. In simulation problems, both the mathematical models of a given physical system and the algorithms to solve them may be specialized to a problem domain, allowing for more efficient computations. The same is true for data analysis, where some pre-existing knowledge of the data may permit faster analysis techniques. Machine characteristics may also affect the choice of algorithms, as the relative costs of computation, data movement, and data storage continue to change across generations, along with the types and degrees of hardware parallelism. Minimizing the total work performed is generally a desirable metric, but on machines with very fast processing and limited bandwidth, recomputation or other seemingly expensive computations may pay off if data movement is reduced, and memory size limits can make some algorithms impractical. Future algorithmic innovations will still be essential for addressing more complex simulation problems—for example, modeling problems with enormous ranges of time- or space scale, or problems that combine multiple physical models into a single computation. They will also be needed for new problems in data-driven science, such as enabling multimodal analysis across disparate types of data, interpreting data with a low signal-to-noise ratio, and handling enormous data sets where only samples of the data may be analyzed. New algorithms will
also be needed to take advantage of future hardware with its new forms of parallelism and different cost metrics, including algorithms that can detect or tolerate various types of errors. Finally, scientific discovery at the boundary of simulation and observation will require new algorithms to measure uncertainties, adjust models dynamically to fit observed data, and interpret data that are incomplete or biased.
Although research into algorithms will continue to have large payoffs in some domains, it does not replace the need for increasingly capable machines. Algorithmic improvements have historically gone hand-in-hand with hardware improvements, provided that the algorithmic advances can be effectively implemented on the advanced hardware. Machine learning algorithms based on neural networks, for example, are only effective because of the performance of modern hardware, and the massive high-throughput computations of the Materials Genome Initiative would not be possible on the hardware available two decades ago. So while hardware performance gains will be increasingly difficult in the future, substantial algorithmic improvements for some problems are probably impossible. For these problems, decades of work on algorithms have led to optimal solutions, and further improvements must come from hardware and operating system software (Box 2.4).
2.5 NSF INVESTMENTS IN ADVANCED COMPUTING
Since the beginning of NSF’s supercomputing centers program in the 1980s, its Division of Advanced Cyberinfrastructure (ACI) and its predecessor organizations have supported computational research across NSF with both supercomputers and other high-performance computers and provided services to a user base that spans work sponsored by all federal research agencies. Although a large fraction of the leadership-class investments have been driven by the mission-critical requirements of DOE and DOD, NSF has played a pivotal role in moving forward the state of the art in HPC software and systems.
ACI supports and coordinates a range of activities to develop, acquire, and provision advanced computing and other cyberinfrastructure for science and engineering research together with research and education programs. A significant fraction of ACI’s investments have been for two tiers of advanced computing hardware; a petascale computing system, Blue Waters, deployed in 2013 at the University of Illinois, and a distributed set of systems deployed under the eXtreme Digital program and integrated by the Extreme Science and Engineering Discovery Environment (XSEDE). XSEDE makes eight compute systems located at six sites available to researchers along with a distributed Open Science Grid and visualization, storage, and management services. Resource allocations for both tiers are made through competitive processes managed by the Petascale Computing Resource Allocations Committee (PRAC) and the XSEDE Resource Allocation Committee (XRAC), respectively. As things stand currently, roughly half of all available computing capacity will shut down in 2018 with the anticipated end-of-life decommissioning of Blue Waters.
One of the major contributions of NSF to computational science has been the development of software: application codes, libraries, and tools. NSF’s implementation of the Cyberinfrastructure Framework for 21st Century Science and Engineering vision8 identifies three classes of software investments: software elements (targeting small groups seeking to advance one or more areas of science), software frameworks (targeting larger, interdisciplinary groups seeking to develop software infrastructure to address common research problems), and software institutes (to establish long-term hubs serving larger or broader research areas). Investments at the larger/broader end are supported under the cross-foundation Software Infrastructure for Sustained Innovation program, while those at
___________________
8 National Science Foundation, “Implementation of NSF CIF21 Software Vision,” http://www.nsf.gov/funding/pgm_summ.jsp?pims_id=504817, accessed January 27, 2016.
the smaller/narrower end are supported by the relevant science and engineering divisions.9
Not included in the ACI portfolio are investments in computer science research infrastructure, such as the GENI (Global Environment for Network Innovations) testbed. Such resources are important research resources but belong more properly to the specific research program within NSF. Also not included is basic research into algorithms and software, which while also vital, is supported by other research programs in NSF (both within Computer and Information Science and Engineering [CISE] and the other science divisions) and at other federal agencies such as DOE.
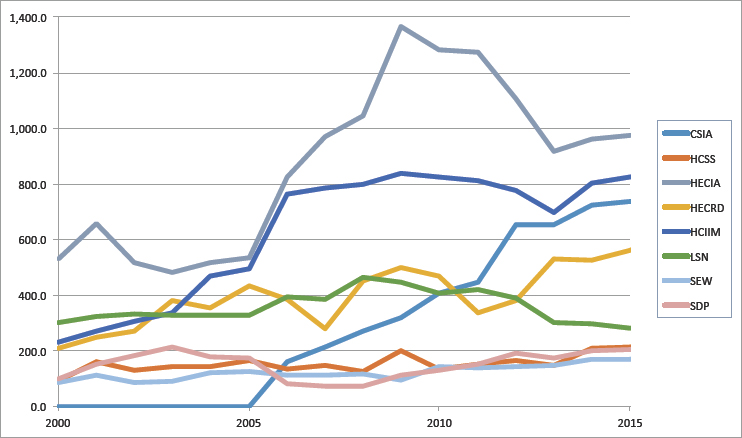
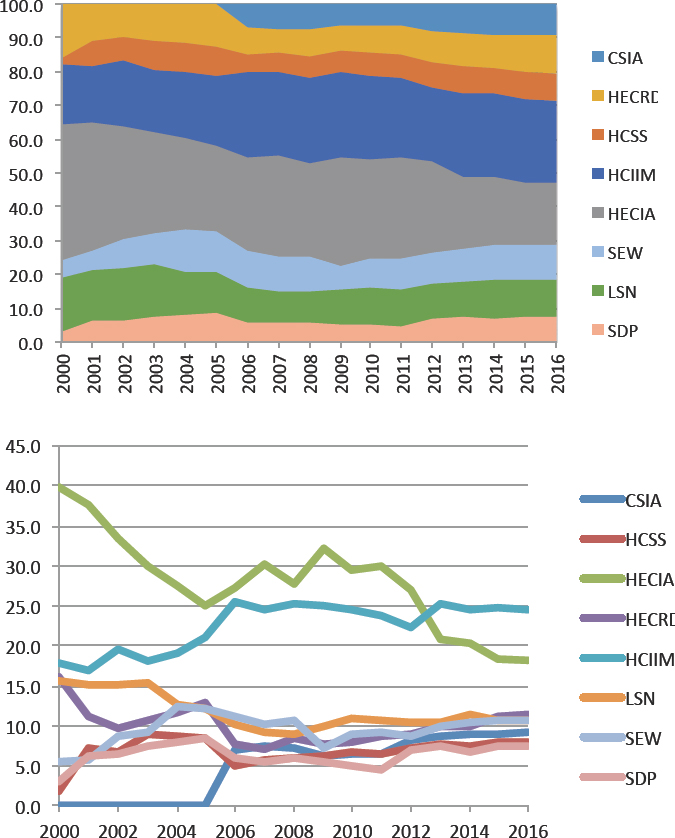
Trends in the overall investment in advanced computing can be seen by looking at the spending amounts reported by federal agencies to the Networking and Information Technology Research and Development program’s National Coordination Office. Figure 2.1 shows the total federal investment in all categories tracked by Networking and Information Technology Research and Development (NITRD) including high-end computing infrastructure and applications (HECIA), a category that shows both long-term growth over the period 2000-2015 as well as a significant fall-off from a mid-2000s investment spike. Note that advanced computing systems have a relatively short useful lifetime. However, NSF’s investments in HECIA have fallen off from nearly 40 percent to less than 20 percent of the total (Figure 2.2a-b), even as demand has grown.
2.6 DEMAND FOR AND USE OF NSF ADVANCED COMPUTING RESOURCES
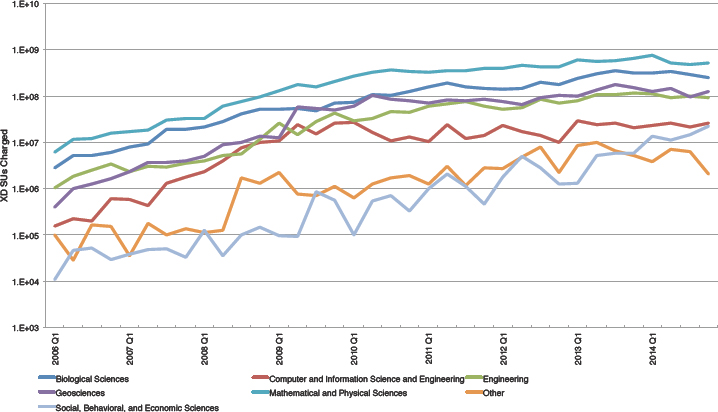
The use of advanced computing resources cuts across research funded by all the divisions of NSF, as shown in Figure 2.3. Data obtained from XSEDE indicate that the number of active users has quintupled over the past 8 years, and the use10 grew exponentially through about 2009. Use increases less rapidly after that, matching the slower growth in available resources (cf. Figure 2.5). The usage patterns over the years indicate significant usage by all of the NSF directorates, including Mathematical and Physical Sciences, Biological Sciences, Geosciences, Engineering, CISE, and Social, Behavioral and Economic Sciences. Notably, use by the Direc-
___________________
9 National Science Foundation, “Implementation of NSF CIF21 Software Vision,” http://www.nsf.gov/funding/pgm_summ.jsp?pims_id=504817, accessed January 27, 2016.
10 XSEDE use is measured in service units (SUs), which are defined locally for each XSEDE machine and normalized across machines based on High-Performance Linpack benchmark results. SUs do not account for other relevant system parameters such as memory or storage use. Also, a large fraction of available SUs in the current XSEDE resources comes from coprocessors that can be used only after significant changes to software and, sometimes, to algorithms as well.
torate for Social, Behavioral and Economic Sciences is continuing to grow exponentially and by 2014 exceeded the use by Mathematics and Physical Sciences in 2005, showing the broad growth in the use of computing across the foundation.
Further, for such infrastructure as XSEDE, NSF supports a significant fraction of non-NSF funded users. With XSEDE, the usage patterns indicate that for large allocations (e.g., over 10 million service units) approximately 47 percent of the allocations are for non-NSF funded users (Figure 2.4). That share includes 14 percent in support of research funded by the National Institutes of Health.
Although it is difficult to know exactly how much advanced computing is required by the nation’s researchers, one available metric is the amount of computer time requested on the XSEDE resources. There is a growing gap between the amount requested, which continues to grow exponentially, and the amount available (Figure 2.5). The implication is

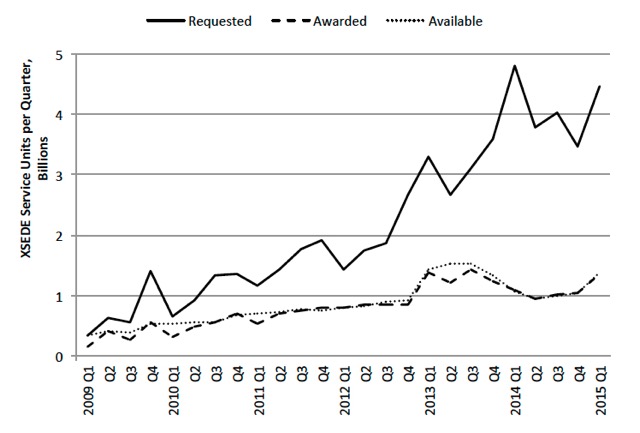
that insufficient computing resources inhibits the effective execution and constrains the scale of accomplishment of already funded NSF science.
2.7 NATIONAL STRATEGIC COMPUTING INITIATIVE
As this study was being completed, an executive order11 was issued establishing a National Strategic Computing Initiative. Section 3a of the order designates NSF as one of the three lead agencies for the initiative and calls for NSF to “play a central role in scientific discovery advances, the broader HPC ecosystem for scientific discovery, and workforce development.” Box 2.5 compares items in the executive order with the major themes of this report.
___________________
11 Executive Office of the President, “Executive Order—Creating a National Strategic Computing Initiative,” July 29, 2015, https://www.whitehouse.gov/the-press-office/2015/07/29/executive-order-creating-national-strategic-computing-initiative.



























