
4
Future National-Scale Needs
Forecasting the future national needs for advanced computing is difficult. The recent revolution in data-centric computing emphasizes both the broad generality of computation and the difficulty in forecasting what future needs will emerge as new methods and opportunities arise. In addition, the end of Dennard (frequency) scaling and the move to massive parallelism and new computing architectures mean that many existing applications will need to be updated or replaced in order to make effective use of forthcoming systems. This chapter discusses previous approaches for discussing needs that were based primarily on floating-point performance and makes recommendations for how to think about the more complex, multidimensional requirements for computing and data systems in the future.
4.1 THE STRUCTURE OF NSF INVESTMENTS AND THE BRANSCOMB PYRAMID
For the past 30 years, National Science Foundation (NSF) investments in advanced computing have focused on the top two levels of the Branscomb pyramid (Box 4.1): leadership-class and center-class machines (Figure 4.1). Although the Branscomb pyramid has been invoked (and revised) for decades, it focuses only on the computational aspects of the portfolio. Variations have appeared over the years that include other axes, such as storage and bandwidth (see Chapter 5), but the pyramid remains as a useful, albeit incomplete, organizing principle.
The pyramid conveys more than just a portfolio of computational capability that spans five (or more) orders of magnitude in performance. It implies that there is substantial congruence in the programming models up and down the pyramid. Moreover, there is an expectation that the number of users roughly scales with the horizontal extent of each level. If the pyramid is to represent resource consumption, then these last two issues must be considered.
In the area of programming models, Kogge and Resnick1 showed that there was a significant discontinuity in 2004 with a sudden growth in the diversity in architectures in the TOP500 systems. Kogge and Resnick noted that this was the result of barriers to the previous several decades of increases in single-core performance, more memory per chip, memory latency, and interconnect performance. In 2004, there was growth in multicore systems relying on simpler cores and slower clock speeds, slow growth in memory density, and complex interconnects. Thus, the advanced computing portfolio began to be a combination of heavyweight architectures (e.g., Cray XE6 nodes for National Center for Supercomputing Applications’ Blue Waters),2 lightweight architectures (e.g., IBM BlueGene/Q for Argonne National Laboratory’s Mira), hybrid architectures (e.g., Cray XK7 for Oak Ridge National Laboratory’s Titan or the Intel Xeon Phi nodes on Texas Advanced Computing Center’s [TACC’s] Stampede), and heterogeneous multicore systems on a chip (e.g., ARM Cortex).
The current expectations are that scientists can use the same codes across a broad range of systems and that U.S. vendors do not develop chips and packages uniquely for the highest-end systems. However, future performance improvements to the largest-scale systems may require even more exotic technologies to cope with such issues as resilience, power management, and energy efficiency. As a result, the high-performance community is currently exploring whether those seeking the very highest performance will have to adopt new programming models, tools, and practices sooner. On the other hand, users of both scientific and commercial systems see considerable value in maintaining a common programming model across the spectrum—from the single chip in handheld devices to the largest multi-processor systems.
Regarding the number of users at each level of the pyramid, there are economic and cultural pressures that sometimes work to increase the
___________________
1 P.M. Kogge and D.R. Resnick, Yearly Update: Exascale Projections for 2013, Sandia Report SAND2013-9229, Sandia National Laboratories, October 2013, http://prod.sandia.gov/techlib/access-control.cgi/2013/139229.pdf.
2 Strictly speaking, Blue Waters is a hybrid machine, but is predominantly lightweight because only about 16 percent of the nodes include GPUs.
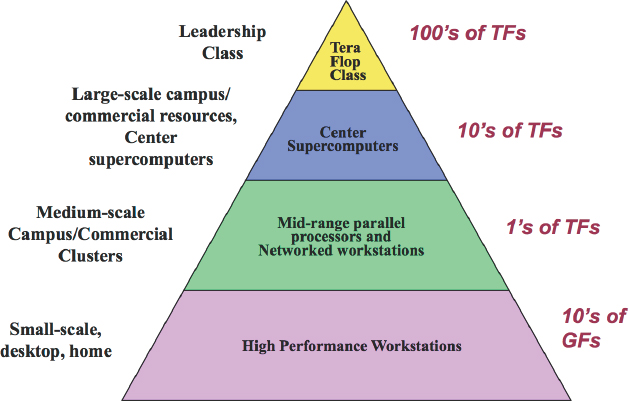
number of users at the top two levels of the pyramid (leadership class and center class). This can be done either through limiting the scope of resources allocated to a single job (number of processors, run time, etc.) or through explicit programs designed to increase the user base (e.g., the MATLAB portal at TACC or specific funding solicitations). Thus, a modern interpretation of the pyramid needs to clearly distinguish between the usage of services and the provisioning of services.
The modern interpretation also needs to recognize that there are significant pressures to build out the resources that are affordable rather than those that are needed. While budget realism is essential, it can lead to an acquisition process dominated by cost considerations rather than one driven by the science requirements. Previous studies of the advanced computing portfolio consistently cite similar science needs (computational fluid dynamics, astrophysics, cosmology, materials science, etc.) and the gap between these needs and the available computational resources. This
suggests that there remains a persistent gap between the science requirements and the advanced computing components that are eventually provided.
Looking forward, the constellation of resources to support science needs is much broader and more diverse than in the past, ranging from cloud-based systems to high-speed wireless networks to the more traditional centers and campus-based facilities. The range of usage models has also widened (Box 4.2), and the science community is generating a flood of new data. Thus, there are more demands from new user communities. Moreover, the adoption timescale is much shorter for new technologies and capabilities. When these forces are coupled, new workflows emerge and evolve much more rapidly.
In addition, although discussions of computing needs often focus on what systems need to be acquired and operated, the effective use of computing systems, particularly large-scale systems that address national needs, requires much more than just computer hardware. Expert staff are needed to operate the systems, diagnose performance problems, and help the user community. Software needs to be tuned and updated for each generation of system, and community codes, which encourage sharing of effort and efficient use of resources, need to be nurtured. New algorithms are needed to address new problems and to make better use of the hardware. Data need to be preserved and curated. These needs must not be forgotten when provisioning computing resources.
4.2 DATA-INTENSIVE SCIENCE AND THE NEEDS FOR ADVANCED COMPUTING
The current generation of advanced computing infrastructure focuses largely on meeting the requirements of workflows for simulation science that has fueled advances across many disciplines over the past two decades. However, the landscape of scientific workflows—the series of computational or data manipulation steps required to carry out a scientific analysis—is evolving rapidly to respond to the remarkable potential that data-driven science (or more colloquially “big data”) holds for answering open scientific questions such as “How do we reliably detect a potential pandemic early enough to intervene?” or (in combination with simulation) “Can we predict new materials with advanced properties before these materials have ever been synthesized?”3
Advances in sensing and measurement from empirical approaches have resulted in a wealth of scientific data that can be utilized to develop
___________________
3 National Institute of Standards and Technology, Big Data Program, see http://bigdatawg.nist.gov/home.php.
new models or refine existing models in order to gain new insights. As the costs of sensors continues to decline, experimental and observational data are being generated not only by large instruments (assembled from many small sensors), but also from large arrays of geographically distributed sensors. Social media feeds are important new data sources for social science research.
More generally, as data accrue from experiments and simulations, and as data from multiple experiments and simulations are integrated, scientific discoveries are increasingly being made from the accumulated and integrated data using advanced computing. This is sometimes known as the “fourth paradigm” of scientific discovery, because it supplements discovery paradigms based on theory, experiment, and simulation.4 Further, there are additional opportunities for scientific insights at the interfaces of each of these paradigms of discoveries.
A good example is provided by the aspirations of the genomics community. Microarray data sets—in which several hundred to several thousand genes were measured under different experimental conditions, resulting in data sets that were megabytes in size—have given way to data sets in which the expression level of the entire genome is measured, resulting in data sets that are gigabytes in size. Similarly, gene chips produce data sets that are kilobytes in size, while whole genome sequencing is producing data sets that are hundreds of gigabytes in size. As a rough rule of thumb, genomic and related clinical data for a cancer patient (assuming normal tissue is sequenced, a tumor is sequenced, and a tumor after relapse is sequenced) are approximately 1 TB in size. A cohort of 10,000 patients requires 10 petabytes of storage, and a cohort of 1 million patients (a goal for the community over the next several years) would require 1 EB of storage.
Another example is the Large Synoptic Survey Telescope (LSST), which will produce a wide-field astronomical survey of the universe using a 8.4-meter telescope and 3-gigapixel camera. LSST will collect 15 TB of raw image data every night that will be processed in near-real time to provide scientists with alerts about new and unexpected astronomical events and reprocessed annually. It will yield a 200 PB data archive by the end of the decade-long survey.
Today, both scientific researchers and businesses use a wide array of data analytics tools. In some areas, large-scale analytics companies such as Google and Amazon—rather than the scientific community—are in a leadership position. In some other areas, the needs of science may not
___________________
4 T. Hey, S. Tansley, and K. Tolle, eds., The Fourth Paradigm: Data-Intensive Scientific Discovery, Microsoft Research, 2009, http://research.microsoft.com/en-us/collaboration/fourthparadigm/.
overlap the needs of industry. For example, the statistical analysis of large, in memory data sets (such as the anticipated output from the LSST) is more similar to a scientific computation that to the type of analyses that have generally interested Google or Amazon. Looking ahead, there may be opportunities for researchers to make better use of the tools and concepts developed by industry or for the industrial and scientific communities to partner more effectively where their needs overlap.
One challenge with respect to the private sector is that salaries for those trained in data analytics can be far higher in the private sector than in the academic research community. This makes it difficult for academic researchers to stay abreast of emerging technical tools that enable data-intensive science. For NSF, this creates two challenges. The first challenge is to act strategically to develop the needed workforce to support both science and business applications. The second is to find ways to keep people with these skills in the science community despite lower salaries—for example, by offering reasonably secure, stable career paths as well as exciting work.
From a technical requirements perspective, infrastructure for data-intensive science needs to consider data acquisition, storage and archiving, search and retrieval, analytics, and collaboration (including publish/subscribe services). Recent NSF requirements to submit data management plans as part of proposals signal recognition that access to data is increasingly important for interdisciplinary science and for research reproducibility. Although the focus is sometimes on the hardware infrastructure (amount of storage, bandwidth, etc.), the human and software infrastructure is also important. Understanding the software frameworks that are enabled within the various cloud services and then mapping scientific workflows onto them requires a high level of both technical and scientific insight. Moreover, these new services enable a deeper level of collaboration and software reuse that are critical for data-intensive science.
When considering cyberinfrastructure requirements, the needs of data-intensive science are often considered as separate from those of the more traditional computationally intensive science problems, such as climate modeling. However, as new massive data sets become available (e.g., the LSST project), the line separating these two types of research becomes blurred. As a specific example, today’s climate models have dramatically increased temporal and spatial resolution compared to models from 10 years ago. Although this has greatly improved model performance, many processes that once could be parameterized simply at coarse resolution now must be included explicitly in high-resolution models. One example is the representation of cloud processes, where the physics are poorly understood and critical parameters cannot be measured.
The June 2014 issue of Philosophical Transactions of the Royal Society5 was devoted to a generation of coupled deterministic/probabilistic models that illustrate a possible convergence between compute-intensive models and data-intensive models.
4.3 FORECASTING FUTURE REQUIREMENTS
Developing science requirements for any large project takes enormous experience and insight (and creativity). Establishing requirements that can be achieved within a cost and schedule framework is even harder. By its very nature, science is unbounded. There are always pressures to improve our understanding or to make better predictions.
Past NSF efforts have, in general, implicitly constrained requirements, either through budget caps or by technical feasibility. Obviously, there is some iteration between these elements, although the NSF petascale program6 was driven largely by cost and desired sustained computational performance. There was an implicit assumption that the acquired systems would enable a certain class of scientific models and analyses to be addressed. With this approach, there was a risk that the science requirements could have been only loosely coupled to the systems that were acquired, and key areas of science could have been left unserved.
Today, with growing demand for computing and constrained budgets, it has become especially important to understand the relative benefits and risks of different technical approaches for the science portfolio. This section describes some of the challenges NSF will face in developing science requirements for advanced computing.
- Quantifying science benefits. It remains an unsolved (and probably unsolvable) problem to accurately quantify the return on investment in scientific research, and certainly it is not possible to predict the return. But it may be possible to consider the likely costs and risks of different approaches, as well as the possible opportunities, and use these to guide the setting of objectives and priorities.
- Suitable measures of advanced computing performance. It is also important to avoid reducing the requirements to a too simplistic measure, such as peak floating-point operations per second (FLOP/s). The system with the best FLOP/s per dollar may not provide the best value for science
___________________
5 For example, T. Palmer, P. Düben, and H. McNamara, Stochastic modelling and energy-efficient computing for weather and climate prediction, Philosophical Transactions of the Royal Society A 372:20140118, 2014, doi:10.1098/rsta.2014.0118.
6 National Science Foundation, “High Performance Computing System Acquisition: Towards a Petascale Computing Environment for Science and Engineering,” Program Solicitation NSF 05-0625.
-
applications, where sustained, rather than peak, performance is far more important. Key areas of science may have different requirements, such as sustained I/O performance for data-centric applications.
- Rapidly evolving science needs. Any science-driven requirements process must also confront the issue that the science itself is changing rapidly on the timescale associated with large-scale advanced computing acquisition and deployment. Past experience has shown that although a procurement can be completed in several years, large systems sometimes take as long as 10 years from initial concept to full availability to users. A rolling decadal roadmapping process could help inform users about plans for the upgrade and replacement of existing systems and, more generally, the performance characteristics of expected future systems.
-
Responding to the rapid evolution of data-driven science. For example, new classes of weather forecasting models combine the tools of computational fluid dynamics along with data-driven parameterizations to improve forecasts for small-scale (but intense) events. Moreover, these data-driven approaches often rely on ensembles of many model runs. As the network of real-time sensors connected through high-speed links to the Internet grows, these data-driven models will require new capabilities in regard to computation, storage, and bandwidth. Much as with business analytics, these data-intensive methods will be based on near real-time streaming data. Moreover, new technologies could have profound benefits for data-intensive science. One can envision networks of sensors where each sensor node has local compute capabilities that rival the supercomputer performance of only a few years ago. The impact on adaptive computing and sensing could be significant, realizing one of Jim Gray’s admonitions to move computation to the data.7
Such workflows will require autonomous tools to assess data quality and model performance; human intervention and control will not scale up to these new models. Planning for these changing (and often poorly formulated) requirements will require considerable insight. These changing scientific workflows extend to the human side of scientific computing as well. Especially in regards to data-intensive science, reproducibility will be challenging. These requirements will often be as important as the traditional technical requirements of CPU performance, latency, storage, and bandwidth.
- Complex and rapidly changing technology landscape. Just a few years ago, mainstream high-performance computing was limited to commodity x86 processors from Intel and Advanced Micro Devices and IBM Power
___________________
7 A. Szalay and J.A. Blakeley, “Gray’s Laws: Database-centric Computing in Science,” in The Fourth Paradigm: Data-Intensive Scientific Discovery (T. Hey, S. Tansley, and K. Tolle, eds.), Microsoft Research, Redmond, Wash., 2009.
processors. Today, high-performance computing is making use of general-purpose graphical processing units and accelerators, and some designs such as Intel’s Xeon Phi are focused on scientific computing. Looking ahead, more diversity is likely to come in the form of things like integrated non-volatile random-access memory and processors integrated with memory. At the same time, much of the broader commercial industry is focused on the needs of mobile devices.
The technical landscape now has a range of new service providers beyond the hardware/software companies. Much has been made of cloud services, although most of the discussion has focused on its elastic computation and storage model along with an aggressive pricing strategy. However, a key capability of cloud services is the rich software framework that is available for users. Not only can these services and frameworks be leveraged to support changing science workflows, they can be extended to include new components that can then be made available to other users. The science community rapidly adopts these new “providers,” such as Dropbox, until a new and improved service appears on the market.
Along with the challenges of a changing scientific and technical landscape, any requirements process must recognize that there will always be gaps. For example, one cannot predict with any certainty the technical or business directions of the major hardware and software vendors beyond several years. To give another example, the International Technology Roadmap for Semiconductors makes evident the major technical challenges faced by industry in maintaining the pace of performance improvements several years out. Widely used proprietary software such as CUDA is also subject to rapid change.8 Adoption rates of (or resistance to) new technologies is another challenge. The requirements process must at least consider the economic forces that are driving the technology market as well as the political and cultural forces that either speed or resist adoption. Moreover, it must also recognize that the science community must be capable of using the advanced computing portfolio, which means one cannot follow a “build it and they will come” approach.
4.4 THINKING ABOUT A NEW APPROACH TO DEVELOP REQUIREMENTS FOR ADVANCED COMPUTING
At its heart, there needs to be a rigorous process for development and assessment of the science requirements for advanced computing. The process needs to ensure that these science requirements have substantive
___________________
8 Language standards such as C++, Fortran, and OpenMP are less subject to unexpected changes over the short term.
feedbacks between the science, the technical approach, and cost. It also needs to make explicit what research can and cannot be done within a given budget envelope and with a particular set of acquisition decisions. Moreover, a clear and bounded vision for the types of science that advanced computing will support is needed. For NSF, this will likely mean developing an understanding of how much of the portfolio can be supported by a more data-capable general-purpose platform (and what specific data capabilities are needed), and what is left over that either needs specialized advanced computing supported as cyberinfrastructure, or perhaps topical computing supported in part by the science programs. A more productive view than just focusing on the hardware that can be afforded would be to describe and quantify a set of services that are needed to meet a class of science challenges. Such an approach would allow a more flexible investment strategy (build a specific center, work with cloud service providers, etc.) rather than trying to fit everything into a small set of infrastructure assets.
A process that relies on documented science objectives and assessment of the progress made toward achieving these objectives, rather than simply statements that greater computational capacity will improve understanding of a specific scientific process or phenomenon, can help improve future decisions. For example, such an assessment might show that the ability to run an ensemble of 1,000 short-term weather forecasting models will improve the quality of the forecasts by a specific percentage. These science objectives capture the value of the requirement as a function of benefit and affordability, where benefit is in turn a function of importance, quality, utility, and probability of success. This approach to cost-benefit analysis would allow science communities to understand the linkages between science, technical requirements, and cost, thus allowing more rational analysis of the trade space of science capability, technical requirements, and cost.
The more granularity that can be provided in terms of costs and benefits, the better the decisions that can be made when the inevitable trades need to be made between science, technology, and cost. For example, one must consider the full costs of the advanced computing components, including both the acquisition as well as operations and maintenance costs (including hardware, software, and staff costs). In doing so, one must also consider fixed costs (staff, maintenance contracts, etc.) as well as marginal costs (elastic costs of cloud services, etc.). This is especially important as NSF and the science community are moving toward a model of buying services as needed rather than recognizing the true fixed costs. For example, a scientific programmer may spend only 1 month on a particular project, but the employer needs to provide a full year of salary. The existing supercomputer centers repeatedly note the difficulty in maintain-
ing experienced and highly trained staff as the funding agencies move into a mode of buying talent by the month rather than providing stable support for the expertise the scientific community depends on.
Another component of the requirements analysis is to identify the linkages and dependencies across NSF’s advanced computing portfolio. Such systems engineering across a diverse portfolio will not be simple, but it is essential to developing a resilient portfolio that can support a wide range of science areas. Advanced computing requirements should also take into account the science needs (because NSF provides advanced computing to research communities funded by other federal agencies) and contributions of other federal agencies (because some NSF-funded researchers make use of advanced computing provided by other federal agencies).
Today, most users of NSF’s advanced computing infrastructure have no understanding of the value of the resource that they have been granted. While rationed (through the allocation process), advanced computing resources are for the most part “free” (there is no charge for them). This leads to a mindset that puts little value on making efficient use of these resources, particularly because there is no way in the current system to trade, for example, computer time for expert help in tuning applications. As a first step, building an awareness of the value and cost of computing resources may lead to a more holistic and comprehensive approach to using the advanced computing resources. One possible way to do this would be to provide a dollar value of the computational resource granted. There are some dangers in this approach; the goal is to build awareness of the costs and value, not create a chargeback mechanism. Section 6.3.8 describes a possible pilot project to explore the benefits, risks, and problems with such an approach.
This process will yield a much more thorough understanding of the complete costs and technical feasibility of the portfolio in the context of documented science objectives. This will inform an analysis of trade-offs that will modify the approach to fit within economic and political realities. Balancing its primary science mission with the need to operate infrastructure will require constant assessment by NSF, as noted in the recent decadal survey of the ocean sciences.9
4.5 ROADMAPPING
The Department of Energy (DOE) has created a roadmap for future advanced scientific computing research systems that provides research-
___________________
9 National Research Council, Sea Change: 2015-2025 Decadal Survey of Ocean Sciences, The National Academies Press, Washington, D.C., 2015.
ers with a view of what capabilities to expect (Figure 4.2). By describing the next 3 to 5 years of leadership computing systems, DOE has given the community useful information about the general characteristics and organization of the next DOE leadership-class systems. The longer-term roadmaps are less concrete but still provide information about the general intentions of DOE: continue increasing single machine performance, which contrasts with keeping the single machine performance about the same but increasing the total number of machines.
NASA and other mission agencies have regularly employed a roadmap process that outlines a small set of science themes that will engage the scientific enterprise over the next few decades.10 These themes then serve as a framework for a series of notional missions or activities that address specific questions in the theme. Some of these questions may need to be addressed sequentially (e.g., the approach to one question may depend on the knowledge gained from answering another question), while others may proceed roughly in parallel. Taken together, the notional missions lay out a roadmap that is based on scientific progress at each stage. However, unlike a decadal survey, the roadmap also lays out options and multiple pathways and identifies the scientific and technical challenges.
A fundamental aspect of the roadmapping process is that it is driven by the science themes, rather than simply a quest for a certain level of technical capability. Also, the process lays out options and challenges. Lastly, it links scientific progress to technological capabilities, rather than a “build it and they will come” approach. Maintaining a linkage between science need and technological capability is an important aspect of effective roadmapping.
Implementing a roadmapping process that reflects all of the research supported by NSF advanced computing will not be easy. For one thing, as Dennard scaling has fallen off, there is growing pressure to use domain-specific hardware to achieve greater computing performance. For another, the requirements have become more diverse as the range of science using advanced computing has grown. Specialized accelerators, storage facilities, or other capabilities may be needed to enable some research objectives efficiently, and it will in any event be difficult to roll up requirements into a sufficiently small set. It may be necessary to develop separate road-
___________________
10 For example, the end-to-end challenges in managing massive research data are considered in NASA Earth Science Technology Office/Advancd Information Systems Technology (ESTO/AIST) Big Data Study Roadmap Team, “NASA Earth Science Research in Data and Computational Science Technologies,” September 2015, http://ieee-bigdata-earthscience.jpl.nasa.gov/references/aist-big-data-study-draft-summer-2015.
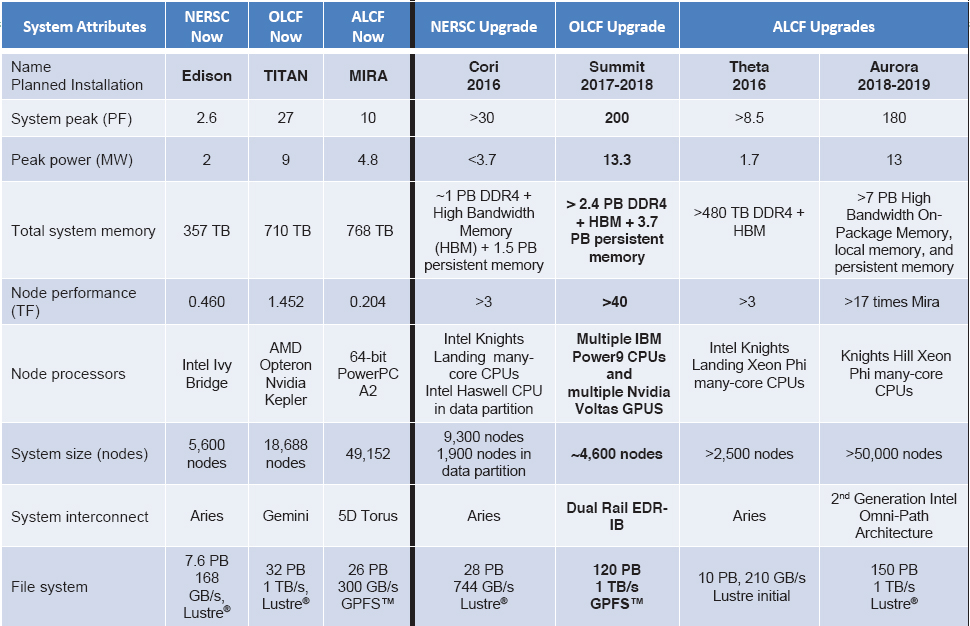
maps by science area, and then aggregate similar needs across areas (e.g., the use of unstructured grids and iterative linear methods in simulations).
Another challenge is determining a good configuration for a computing system that requires more than just a measure of the number of operations per second (e.g., clock speed) or size of data (e.g., disk space). Research has shown that simple benchmarks are, individually, rarely predictive of the performance of an application, and even collections of benchmarks give only a rough estimate.11 Highly accurate performance estimates, while possible, remain a difficult and time-consuming process. As a result, the community has relied on a very simple measure of computing performance, based on floating-point performance only. For example, XSEDE allocates resources in service units (SUs), which are related to the performance of High-Performance Linpack. This reflects the peak floating-point performance of a system but little else. Allocations under the PRAC program for Blue Waters are in node-hours, which is more easily related to the specific system but is not easily convertible to SUs or node-hours for a different system. A first step would be to gather more information about the needs of applications. Relevant measures include memory size and bandwidth, data size and bandwidth, interconnect bandwidth and application sensitivity to interconnect latency, integer and floating-point performance, and long-term data storage requirements. Some of this information could be gathered by tools designed for this purpose, applied to an application running on a current system, reducing the burden on the computational scientists. An example of what the first step in this process might be is presented in Box 4.3.
Despite the challenges and the likely imperfections in the roadmaps that are developed, it should be possible to develop roadmaps that provide enough guidance to the community to be worthwhile. By focusing on the overall picture rather than the high-resolution details, roadmaps can indicate to the community what the major investments will look like. This will allow researchers to make better decisions about future research. It will also allow researchers to start preparing their software to be ready for future systems—for example, by providing advance notice about significant changes in architecture or configuration.
___________________
11 See, for example, L. Carrington, M. Laurenzano, A. Snavely, R. Campbell, and L. Davis, How Well Can Simple Metrics Represent the Performance of HPC Applications?, in Proceedings of the ACM/IEEE SC 2005 Conference, 2005, http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=1560000.



















