
5
Investment Trade-offs in Advanced Computing
Owing to the success of computing in advancing all areas of science and engineering, advanced computing is now an essential component in the conduct of basic and applied research and development. In a perfect world, investments in advanced computing hardware and software, together with investments in human expertise to support their effective use, would reflect the full range and diversity of science and engineering research needs. But, as discussed in Chapter 2, the gap between supply and demand is significant and continuing to grow. In addition, developments in data-intensive science are adding to the demand for advanced computing. From the smallest-scale system to the largest leadership-scale system, one of the challenges of advanced computing today is the capacity requirement along two well-differentiated trajectories—namely, high-throughput computing for “data volume”-driven workflows and high parallel processing for “compute volume”-driven workflows. Although converged architectures may readily support requirements at the small and medium scales, at the upper end, leadership-scale systems may have to emphasize some attributes at the expense of others.
Moreover, within a given budget envelope for hardware, the criteria for future procurements should reflect scientific requirements rather than simplistic or unrepresentative benchmarks. There is no single metric by which advanced computing can be measured. Although peak floating-point operations per second (FLOP/s) is the most common benchmark, even within the simulation community it has long been known that other
aspects of computer performance, including memory bandwidth and latency, are often more important.
Finally, advanced computing is more than hardware. Investments in software, algorithms, and tools can help scientists make more effective use of resources, effectively increasing the computing power available to the community.
The trade-offs to be considered are many, with different impacts on advanced computing cost and capability. This chapter starts by considering trade-offs associated with the volume of compute and data operations, applies them to investments in systems designed for simulation and data-intensive workload, and considers converged solutions (Section 5.1). This example was chosen because in the near term, it is perhaps the most critical trade-off that the National Science Foundation (NSF) must consider, as it balances the needs of existing computational users against a rapidly emerging data science community. The chapter then turns to another critical trade-off, between investments in production and investments to prepare for future needs (Section 5.2). Several investment trade-offs faced by NSF in simulation science, along with their impact, are discussed in Section 5.3. An example portfolio illustrating how NSF might address these trade-offs is sketched out in Section 5.4.
5.1 TRADE-OFFS AMONG COMPUTE, DATA, AND COMMUNICATIONS
Supporting both simulation and data-driven science requires making trade-offs among compute, data, and communications capabilities. At a conceptual level, workflows for the simulations of physics-based models are typically compute-volume driven in that they require a higher number of arithmetic or logical operations per unit of data moved. An illustrative example is many-body simulation of the electronic structure of molecules or materials, which is dominated by the contraction of dense, multidimensional tensors. On the other hand, workflows for developing or refining models by utilizing data from experiments or simulations are typically data-volume driven in that they require a larger number of units of data moved per arithmetic or logical operation. Examples include the analysis of genomic data from large studies or the analyses of streaming data. Further, in areas where scientific advances may be imminent at the confluence of both of these approaches—for example, in Earth systems science, where climate and weather models can be coupled to data from observatories—workflows will likely exhibit a complex mix of both of these aspects.
The communication-volume dimension refers to the speeds at which data chunks from very small to very large sizes can be moved efficiently
within the system. Such communication is accomplished through networks that may connect processors directly or via/across memory and storage subsystems; technology trends typically point to one or more orders of magnitude differences in the latencies per operation at a processor, memory, or storage element. Consequently, communication networks can be configured to serve efficiently the critical set of latencies at appropriate bandwidths. Now, high performance for a particular workflow will depend not only on how its data and compute-volume dimensions tap into the corresponding dimensions, but perhaps even more crucially on how the software implementation and algorithms underlying the workflow match the communication dimension.
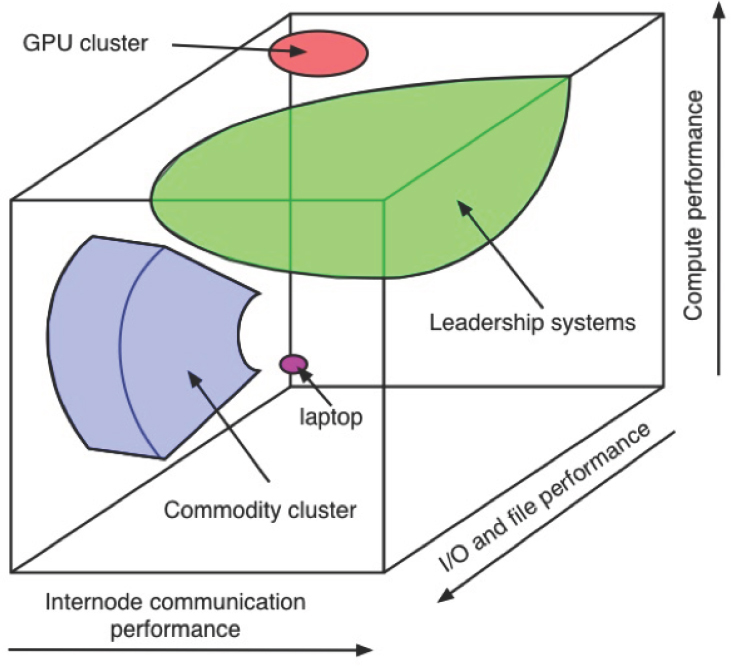
A key question to consider is how the different types of workflows can inform advanced computing designs and specifications so that they can be provisioned appropriately to advance national priorities for discovery and innovation. Here, the major dimensions of advanced computing, as shown in Figure 5.1, play a critical role. The compute-volume and data-volume dimensions of advanced computing architectures are closely related to the corresponding compute and data dimensions of scientific workflows. However, the correspondence to the communication-volume dimension1 is more complex, and it drives the space of trade-offs in regard to how desirable levels of performance may be obtained for specific types of workflows.
5.2 TRADE-OFFS FOR DATA-INTENSIVE SCIENCE
When making design and investment trade-offs for systems that support data-intensive science, one needs to consider the entire workflow, from instrument to scientific publication, and optimize the entire infrastructure, not just individual systems. One key trade-off is that investments in capabilities for data processing and long-term storage need to be balanced against each other accordingly. For example, in a project that collects data over several years, data are analyzed as they are collected and typically continue to be analyzed for several more years. In this case, the project is required to store the data, analyze them, and almost always to reanalyze them as algorithms improve and as new data arrive. As another example, a design that allocates more time to computing capabilities may complete its analysis faster but may not be able to store
___________________
1Communication volume is used here as shorthand for the more accurate and complex representation of internode communication, including latency, point-to-point bandwidth, bisection bandwidth, network topology and routing, and similar characteristics. Latency in particular is critical for many applications; some algorithms require high bisection bandwidth.
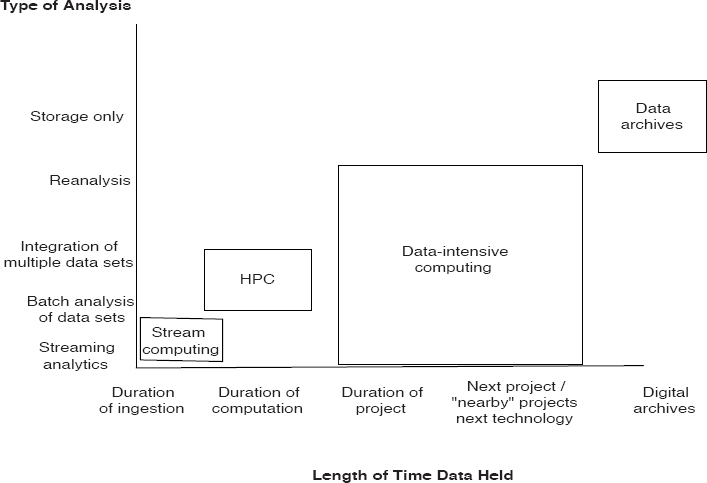
sufficient data to carry out the analysis of interest. Consider two designs with different allocations between the compute and storage allocated to a project. As Figure 5.2 illustrates, some projects may reanalyze all of the raw data throughout the project and so must keep the data online. Another important aspect of data-intensive science to keep in mind is that as different large data sets are integrated and the results analyzed, there are usually new types of scientific discoveries that are possible. Data-intensive projects often provide data to other projects that may use their data as part of a broader “integrative analysis.” The trade-offs concern balancing how much data can be stored and for how long with how many processors can be used to analyze the data and how the communication network can be optimized for analysis and for efficient redistribution of the data to other interested parties. When instruments, computers, and archival sites are geographically distributed, the data they produce may be processed and consumed at multiple sites, requiring special attention to the wide-area networks needed to transfer the data, how data should be staged and consolidated, and so forth. For experiments, deciding how much data to save is a trade-off between the cost of saving and the cost
of reproducing, and this is potentially more significant than the trade-off between disks and processors.
In summary, for data-intensive science projects, one must balance the amount of data that can be stored with the capability and capacity of the workflows for analyzing the stored data. Second, trade-offs in the workflows themselves must be optimized. For data-volume-driven workflows, scientific outcomes are best achieved when the advanced computing is configured for efficient, high-throughput processing at scale with communication attributes directed toward efficiencies at the processing and storage layers for continuous updating and reanalysis of petabyte-sized data sets. Consequently, achieving U.S. leadership in this space requires achieving such capabilities at scale through an appropriate balance of advanced computing attributes in the networked storage elements in regard to the data-volume and communication-volume dimensions and in the processing elements in regard to the compute-volume dimension to achieve high throughput of data analyses workflows.
5.3 TRADE-OFFS FOR SIMULATION SCIENCE
Looking to the future, a variety of trade-offs will need to be examined with regard to the investments that NSF can make and their potential for enabling high-impact outcomes in simulation science. These trade-offs concern the scale of high-performance computing (HPC) systems and the fact that scale itself can become a tipping point for enabling new and unprecedented discoveries. The pivotal role of NSF in advancing simulation science and engineering through its HPC investments at different scales is readily demonstrated by using the NCSA Blue Waters project and the XSEDE program as illustrative examples. The Blue Waters project has enabled breakthrough scientific results in a range of areas, including an enhanced understanding of early galaxy formation, accelerating nanoscale device design, and characterizing Alzheimer’s complex genetic networks.2 NSF also supports the development and integration of midscale HPC resources through its XSEDE program, which provides HPC capacities to the broader scientific community along with resources for training, outreach, and visualization and supporting research in such areas as earthquake modeling and the simulation of black hole mergers.3 Further trade-offs concern the maturation of simulation science from one-off simulations of a select few critical points of a high-dimensional modeling space to ensemble calculations that can manage uncertainties
___________________
2 See Blue Waters, “Impact,” https://bluewaters.ncsa.illinois.edu/impact-overview, accessed January 29, 2016.
3 XSEDE, “Impact,” https://www.xsede.org/impact, accessed January 29, 2016.
for increases in prediction accuracies4 or enable high-fidelity modeling, simulation, and analyses for cost-efficient and innovative digital engineering and manufacturing.5
The scientific workloads supported by NSF through the Blue Waters and XSEDE programs are largely compute-volume and communication-volume driven, although aggregate memory capacity can be a key enabler for some frontier science applications. A notable point is that Blue Waters provides leadership capabilities in regard to all these dimensions, as shown in Figure 5.2, while some other NSF XSEDE investments provide capacities for such workflows at the midrange. For example, Stampede enables high throughput of low to midscale computations.
Historically, scientific workloads that are compute-volume driven have largely driven the balance of trade-offs in regard to the compute, communication, and storage components of such HPC advanced computing. Further, as described earlier, the trend toward multicore nodes with increasing core counts and very high degrees of thread and core-level parallelism require the use of high-bandwidth and low-latency networks to enable data exchange at the right scale. Additionally, the underlying algorithms and software implementations of the associated scientific workloads have been refined to define a more intricate relationship between how the elements of the advanced computing have to be tuned to provide the right balance along the compute-volume and communication-volume dimensions. Even within a single workflow, different algorithms with different trade-offs between compute and communication may be preferable on a given platform. This makes it difficult to evaluate which platforms are best suited for which applications.
As a consequence of trends in both hardware and software, including multicore nodes with high degrees of parallelism and sophisticated algorithms that require higher levels of data sharing while reducing the number of operations per unit data, the communication-volume dimension is a key differentiator in how trade-offs need to be managed. The advanced systems for simulation science often require that significant fractions of the cost budget are invested in the form of low-latency and high-bandwidth communication networks to couple multicore processor nodes. For example, much of the budget for a system to support simulation science workloads would be allocated to multicore processor nodes
___________________
4 National Weather Service, “NMME: North American Multi-Model Ensemble,” http://www.cpc.ncep.noaa.gov/products/NMME/, accessed January 29, 2016.
5 National Digital Engineering and Manufacturing Consortium, Modeling, Simulation and Analysis, and High Performance Computing: Force Multiplier for American Innovation, Final Report to the U.S. Department of Commerce Economic Development Administration on the National Digital Engineering Manufacturing Consortium (NDEMC), 2015, http://www.compete.org/storage/documents/NDEMC_Final_Report_030915.pdf.
and the network that connects them to enable fast data exchange as the simulations proceed. In contrast, if the same budget was to be directed to serve streaming data science workloads, the bulk of it would go toward the storage network to enable high levels of data ingestion from storage by the multicore processor nodes. Both the Wrangler and Gordon systems funded by NSF are targeted in this manner toward data-intensive computation. This illustrates the contrasts between how trade-offs need to be balanced for serving different workflows.
In summary, for compute-volume-driven workflows, scientific outcomes are best achieved when the advanced computing is configured for efficient parallel processing at scale for a single analysis or simulation. The elements along the communication-volume dimension of the advanced computing (i.e., the interconnects) should be configured toward efficiencies at the processing and storage layers for continuous data exchange and the high-throughput output of data that are the results or outcomes of the processing. It is natural therefore to interpret performance in these HPC systems as they are traditionally known, to represent high levels of coupled parallel processing for compute-volume-driven applications.
5.4 DATA-FOCUSED, SIMULATION-FOCUSED, AND CONVERGED ARCHITECTURES
One of the features of the current era in computing is that there are several distinct architectures for the largest high-performance computers. At the same time, large systems for handling data, especially commercial data systems, are as large or larger in size—and even raw aggregate computing power—as the HPC leadership-class systems. Today, this suggests that there are two types of systems: HPC systems focused on simulation and systems focused on data. The true situation is almost certainly more complex. An issue complicating the discussion is that leadership-class systems for simulation science are operated mainly by research organizations and the government, while leadership-class systems for data science today are operated mainly by industry. Advances in HPC system architectures have generally been shared. In the case of data-intensive systems, some tools have been made open source while others have remained proprietary. Stronger ties between the computer science and computational science communities focused on new data analysis tools, techniques, and algorithms would help bridge this gap.
Some demands can be met by what is sometimes called convergence computing, in which high-performance systems are designed to meet the needs of both high-end simulation science and data science workflows. Indeed, high-performance systems for data-intensive computing in industry are almost always coupled with large-scale storage systems
(Figure 5.1). This coupling is still relatively infrequent in NSF-sponsored projects, and no NSF-supported project has data storage at the scale of a large Internet-scale company. As a simple example, the total online data storage for Blue Waters and XSEDE systems is in aggregate on the order of 100 PB, while online data storage systems at Google can be estimated at over tens of exabytes,6 two orders of magnitude larger. In addition, the architectures at Internet-scale commercial companies are designed for the continuous updating and reanalysis of data sets that can be tens to hundreds of petabytes in size, something that is again rare in the research environment.7 Presently costing several hundred million dollars, an exabyte of storage will become affordable for science applications within a few years because both disk and tape storage are still following an exponential increase in density and reduction in cost. However, bandwidth to the data will likely remain expensive, and it must be borne in mind that any significant analysis of an exabyte data set implies exascale computation. Over time, it seems reasonable to expect researchers to adopt industry use patterns as the necessary software is written. For example, researchers might analyze aggregated video streams to understand social behavior, with much of the large volumes of data not being retained for long.
5.5 TRADE-OFFS BETWEEN SUPPORT FOR PRODUCTION ADVANCED COMPUTING AND PREPARING FOR FUTURE NEEDS
Given the high demand for advanced computing, it will be essential for NSF to focus on and devote the majority of investments to provide production capabilities in support of its advanced computing roadmap. Production support is needed for software as well as hardware, to include community software as well as frameworks, shared elements, and other supporting infrastructure. NSF’s Software Infrastructure for Sustained Innovation (SISI) program is a good foundation for such investments. However, SISI needs to be grown in partnership with NSF’s science directorates to a scale that matches need, where it can then be sustained essentially indefinitely. The United Kingdom’s Collaborative Computational Projects (CCPs) provide examples of the impact and successful operation of community-led activities that now span nearly four decades. Produc-
___________________
6 Precise figures are not available, but a plausible estimate can be found in What If?, “Google’s Datacenters on Punch Cards,” https://what-if.xkcd.com/63/, accessed January 29, 2016.
7 In high-energy physics analyses, enormous data sets are frequently reanalyzed in their entirety, but typically written only once.
tion support is further needed for data management; curation, preservation, archiving, and support for sharing all need ongoing investment. This balance is reflected in the example in Section 5.7.
However, if NSF invested solely in production, it would miss some key technology shifts, and its facilities would become obsolete quickly. Some innovation takes the form of fine-tuning of production systems, but modest, directed investments in exploratory or experimental facilities and services are also needed to create, anticipate, and prepare for technology disruptions.
NSF needs to play a leadership role in both defining future advanced computing capabilities and enabling researchers to effectively use those systems. This is especially true in the current hardware environment, where architectures are diverging in order to continue growing computing performance. Such investments would include (1) research into how to use and program novel architectures and (2) research into how applications might effectively use future production systems. In the first category, longer-term, curiosity-driven research likely belongs as part of the Computer and Information Science and Engineering directorate’s research portfolio rather than NSF’s advanced computing program, which would be focused on roadmap-driven experimentation. Leadership by NSF will help ensure that its software and systems remain relevant to its science portfolio, that researchers are prepared to use the systems, and that investments across the foundation are aligned with this future.
The range of possible options for advanced computing is growing as new architectures for analyzing data, increasing computing performance, or managing parallelism are introduced. One associated risk is that investments end up spread across too many emerging technologies, fragmenting the investment portfolio and reducing the ability to make investments at the scale needed for production capabilities. Another risk is that the criteria used to select among the technologies do not adequately reflect realistic science requirements, as can happen when overly simplistic benchmarks are used, leading to acquisition of systems that fall short in serving the research community.
As new technologies offering greater performance or other new capabilities begin to mature, decisions must be made about when to shift investments in the new direction. Many applications will benefit from higher performance, some applications may not need more performance, and one also expects new applications to emerge when higher performance thresholds are reached. It may be worthwhile to push aggressively into higher performance to enable some new applications, even if other applications take a long time to exploit the new architectures, or never do so.
Today, accelerators, including general-purpose GPUs and other tech-
nologies that are FLOP/s-rich but memory-poor and, possibly, hard-to-program can provide very high performance at reduced cost for a subset of applications. This can create tension between, on the one hand, moving forward aggressively with these technologies to obtain higher performance, thereby putting pressure on researchers to transition their software and algorithms to use the technologies more quickly, and, on the other hand, allowing sufficient time (and resources) for researchers to undertake such transitions. One possible indicator would be the level of active research on how to use a new architecture effectively. A high level might indicate that it is premature to consider the architecture ready for production systems. This indicator is not perfect; for example, there is still active research on how to use cache effectively.
More generally, the requirements expressed in the advanced computing roadmaps can serve as a guide to when technologies are ripe for transition from exploratory to production status. A requirements analysis is necessary to reveal the trade-offs implicit behind any such investment in NSF-wide infrastructure.
A 10-year roadmap would extend well into the exascale era. By focusing on its advanced computing roadmap rather than the first exascale system, NSF will ensure its investments have long-term benefit and will also assist the wider community in understanding and navigating the associated technology transitions. Although exascale systems may seem remote or even irrelevant to the majority of (but certainly not all) NSF users, technology advances in areas like energy efficiency needed for exascale capability will change the hardware and software landscape and have bearing on the purchase and operational costs of the aggregate capability NSF will need in the future. It will thus be important for NSF and the research users it supports to be involved in the national discussion around exascale and other future-generation computing, including through the recently announced National Strategic Computing Initiative, for which NSF has been designated as a lead agency.
At the same time, it will be especially important that NSF not only is engaged, but is actually helping to lead the national and international activities that define and advance future software ecosystems that support simulation and data-driven science. This includes active participation in and coordination of the development of tools and programming paradigms and the software required for exascale hardware technologies. The Department of Energy (DOE) is currently investing heavily in new exascale programming tools that, through the scale of investment and buy-in from system manufacturers, could plausibly define the future of advanced programming even though the design may not reflect the needs of all NSF science because the centers and researcher communities it supports are not formally engaged in the specification process.
5.6 CONFIGURATION CHOICES AND TRADE-OFFS
There are many choices and trade-offs to consider in allocating resources to computing infrastructure. This chapter has discussed several key trade-offs in detail, but there are many others. Whenever considering trade-offs, it is important to keep in mind that designing for a broader overall workflow almost certainly means configuring a system that is not perfect for all individual workflows; rather, it is able to run the entire workflow more effectively than other configurations. Thus, simply maximizing the performance or capability of one aspect, such as floating-point performance or data handling capacity, will not provide useful guidance.
5.6.1 Capability Can Be Used for Capacity but Not Vice Versa
Perhaps one of the most important items to consider is that not all computing resources are interchangeable. This may seem obvious, but it is often forgotten when computation is described in term of peak FLOP/s, cores, or memory size. In addition, some computations (again, both compute-centric and data-centric computations) are infeasible on systems smaller than a certain size. For example, many simulations require large amounts of memory (in the hundreds of terabytes to 1 petabyte [1 TB = 1012 bytes; 1 PB = 1015 bytes]), frequent exchanges of data, and terabytes to petabytes of data storage for both input and output data. Today, such simulations can only be run on leadership-class systems, such as NSF’s Blue Waters or DOE’s Mira and Titan systems. A simulation attempting to run on a system with a slower network will spend most of its time waiting on data to arrive (while still occupying most of the system memory); on a smaller system, there will not be enough memory to start the application.8 Thus, without a system with these characteristics, such simulations cannot be performed.
On the other hand, large, capable systems can be used effectively for applications with smaller requirements. One argument that is sometimes made is that leadership-class systems ought to be used only for applications that require or can make good use of their unique capabilities. This is overly simplistic and is not looking at the overall objective, which, in essence, is to accomplish the greatest amount and most valuable science within the available budget (or with a minimum of cost and risk). Note that while it might be possible to run smaller jobs at slightly lower cost on a less capable system, the cost advantage is likely to be small given the
___________________
8 In principle, out-of-core techniques, or even virtual memory approaches, could be used to address the lack of sufficient fast memory. But in practice this has the same problem as a too-slow network—the application might run, but it would run so inefficiently as to be impractical (and costly, since it would tie up the system for a very long time).
significant economies of scale that can be realized in large systems. The goal is to be cost-effective over the entire portfolio of applications, not to optimize for each individual application. Moreover, if a large system is running only large jobs, then there are likely to be many unutilized nodes, because a few large numbers of nodes are unlikely to sum up to the total system size. Small jobs can improve utilization and, thus, have a small marginal cost.
Although this report avoids the terms capability (instead referring to leadership-class systems) and capacity (systems that can run large numbers of jobs, none of which require a leadership-class system), this point can be most concisely expressed as “capability can be used for capacity but not vice versa.” This critical point, reflected in Recommendation 2.2, calls for NSF to operate at least one leadership-class system so that the science that requires such systems can continue to be conducted.
As discussed above, a system that is optimized for data-driven science that requires processing (and reprocessing) large numbers of mostly independent data records needs capabilities not required on systems optimized for simulation. In particular, there is a greater need for a large amount of persistent storage; it may also be important to prefer higher bandwidth to independent storage devices—for example, having large numbers of compute nodes, each with several disks, over a unified system that provides access of all data to all nodes, as is common on “classic” supercomputers. In a perfect world, NSF could deploy several such systems, each optimized for a different workload. Unfortunately, in a budget-constrained environment, NSF will need to make some trade-offs and, in particular, consider alternative approaches to provisioning the necessary resources.
Although there are clearly applications that are dominated either by floating-point-intensive work or by data-intensive work, there are many problems that require a combination of capabilities. For example, some forms of graph analytics require the same sort of low-latency, high-bandwidth interconnect used in leadership-class HPC systems. In fact, the systems that dominate the Graph500 benchmark9 are all large HPC systems, even though this benchmark involves no floating-point computation. Similarly, there are other features, such as large memory size, high memory bandwidth, and low memory latency, that are desirable in leadership-class systems for a wide range of problems, be they data-centric or simulation/compute-centric. Thus, it is best, as illustrated in Figure 5.2, to consider leadership-class systems as a spectrum of systems with different emphases. With enough funds, several large-scale systems could be deployed, each making different trade-offs in this space of con-
___________________
9 See the GRAPH500 website at http://www.graph500.org, accessed January 29, 2016.
figuration parameters. One can have several large-scale systems making different trade-offs, or different subsystems of a coupled system that make different trade-offs. If simulations increasingly ingest experimental data and increasingly require in situ analysis, then the latter solution may work better.
Arguments like these suggest that an economy of scale implies that all resources should be centralized to gain maximum efficiency from the system. However, this is not correct, because it takes more than just hardware to provide effective advanced computing. Instead, a balance needs to be struck that provides resources large enough to tackle the critical science problems that the nation’s researchers face while also providing systems tuned for different workloads and the expertise to ensure that these scarce and valuable resources are effectively used. It is also important to have several centers of expertise to ensure that the community has access to several different perspectives. An example of a possible set of trade-offs is given at the end of this chapter.
Deploying a flexible hardware platform capable of addressing a wide range of data-centric, high-performance, and high-throughput workflows is just the first step. Also essential are deploying and supporting the associated software stacks and addressing the challenges and barriers faced by researchers and their communities who will use the systems for their research and education.
5.6.2 Trading FLOP/s for Data Handling and Memory Size per Requirements Analysis
In the short run, even as it develops a more systematic requirements process, NSF needs to ensure continued access to advanced computing resources (which include both data and compute and the expertise to support the users), informed by feedback from the research communities it supports. In the longer run, it is essential that NSF use a robust requirements-gathering process to guide the selection of system configurations needed to ensure continued access. This will necessarily involve trade-offs of different capabilities, as each choice will have a significant cost. While this must be driven by the requirements analysis, one likely trade-off will be to improve data handling and memory size at the expense of peak FLOP/s. Some NSF systems have already done this; Blue Waters, with large amounts of memory, high input/output (I/O) performance, and a large number of conventional CPUs to support existing applications, is a good example. Wrangler is another good example of this trade-off in practice, although at a much smaller scale than Blue Waters. Note that the configuration of Blue Waters was guided by a process that required demonstrated performance on full applications, including reading input data and writing results to files, rather than just benchmarks and that this
significantly influenced the configuration of the system. The roadmapping process recommended in this report would ensure that future systems would be similarly aligned with the needs of the community.
5.6.3 Trade-offs Associated with Rewriting Code for New Architectures
When considering these trade-offs, it is important to consider the tension between maintaining compatibility with legacy applications and providing the highest performance for new applications. Note that there is a huge investment in scientific software that is not only written but also tested and (perhaps) understood. This code base cannot be rewritten without a significant investment in time and money. The financial cost is real and must be considered when evaluating the cost advantage of a new architecture. At the same time, if a new architecture is likely to persist, then that cost will only need to be paid once. An example of a new architecture that required many applications to be rewritten is the successful adoption of distributed memory parallel computers, along with message-passing programming, more than 20 years ago, which enabled an entire class of science applications.
A related issue is the one of scientist productivity versus achieved application performance balanced with efficient use of expensive, shared computational resources. As this report stresses, the goal is to maximize the science that is enabled and supported by advanced computing. An individual scientist may rightfully be focused on the fastest path to discovery and not be concerned about computational performance unless it is essential to completing the computations with available resources or time, such as is the case for the massively parallel applications running on Blue Waters. However, efficient utilization and maximum scientific productivity of a fully allocated, shared facility requires that the majority of cycles are consumed by well-optimized software. As systems become increasingly complicated and hard to use effectively, a burden has been put on the science teams as well as the computing facilities to create and maintain application codes that run efficiently on a range of systems. Many users are concerned about the difficulty in moving their codes to new architectures. In the short run, this means that production systems cannot be predicated on users needing to rewrite their applications to use new architectures. They also cannot depend on unproven software technologies to make existing or new applications run efficiently on new architectures. This concern with productivity also applies to new applications. Not all architectures are easy to use efficiently, and some algorithms remain very challenging to parallelize—for example, parallelization in time.
These observations relate to the relatively short run. However, NSF
also needs to be planning well into the future for a post-CMOS [complementary metal-oxide semiconductor] era. Here, the divisions of the Computer and Information Science and Engineering directorate other than the Division of Advanced Cyberinfrastructure (ACI) can play a role by ensuring that the requirements of the science community are included in computer science and engineering research on future device technologies and architectures.
5.6.4 Trade-offs Between Investments in Hardware and in Software and Expertise
Following on the theme of maximizing the science, today’s hardware is challenging to use efficiently and, despite many attempts and interesting ideas, this is unlikely to change. NSF has already established several services that support application developers in making better use of the systems, both for XSEDE and for the PRAC teams on Blue Waters. The initial investments in the SISI program are a good start. They have the potential for broad impact if the investments reach sufficient scale, are sufficiently focused on the nitty-gritty of improving the engineering of codes, and are sustained over a sufficient period, if not indefinitely, with both external review and community-based requirements analysis being essential ingredients. Recent NSF-sponsored work10 points to plausible mechanisms that could be adopted to assess the science impact of software as well as establish directions and locations for future investments. Investments in future hardware must continue to be considered together with support for using those systems, and that support must be organized for effective delivery.
5.6.5 Optimizing the Entire Science Workflow, Not the Individual Parts
Furthering the topic of getting the most science from the system, it is important to optimize for the entire scientific workflow, not just each part separately. This is for two reasons: first, as is well known, the global optimum is often not made up of a number of local optima. Second, it may not be possible to afford an optimal solution for each part of the problem. An example of a common yet incorrect trade-off is to design a system to meet the floating-point performance needs of a benchmark that is thought to represent an application. Yet in practice, the full application may require file I/O, memory bandwidth, or other characteristics. In
___________________
10 J. Howison, E. Deelman, M.J. McLennan, R. Ferreira da Silva, and J.D. Herbsleb, Understanding the Scientific Software Ecosystem and Its Impact: Current and Future Measures, Research Evaluation, 2015, doi:10.1093/reseval/rvv014.
addition, the science may require running pre- and post-processing tools, visualization systems, or data analysis tools. It is critical that the entire workflow be considered. Note that the Blue Waters procurement was one of the few for leadership-class systems that required overall application performance, including I/O, as part of the evaluation criteria; as a result, this system has more I/O capability than most systems with the same level of floating-point performance and is, in fact, as powerful for I/O operations as the leadership-class systems planned by DOE for 2016-2017.
5.6.6 General-Purpose Versus Special-Purpose Systems
There are some applications that on their own use a significant faction of NSF’s advanced computing resources. It may make sense, based on an assessment of the science impacts, to dedicate a system optimized for those applications (either together or singly) and provide a general-purpose system that can handle (most/many) of the remaining application areas that require a leadership-class system. For example, such systems may have smaller per-node memory requirements or per-node I/O performance; they may require simpler communication topologies but place a premium on the lowest possible internode communication latency. Similarly, as discussed above, an architecture focused on data volume will devote a much higher part of its cost to I/O than a system focused on compute or communication. While it may still be more cost effective to have a single machine that is good at all aspects of advanced computing (the convergence approach), it is essential that options that consider a small portfolio containing either specialized machines or access to time on specialized systems be considered.
5.6.7 Midscale Versus High-End Systems
Important scientific discoveries are made not just at the high end of the compute- and data-intensive scales, but also in the midscale and low end. Because of the improvement in software applications and tools and accessible training, there is a growing demand for the use of midscale advanced computing infrastructure. Work at the midrange produces a large number of scientific publications and supports a large scientific community. The requirements for midscale computing will only grow as improvements in software make it easier and easier to take advantage of these resources.
The Hadoop software ecosystem provides an interesting example of what is needed for midscale systems to become widely usable. Traditional HPC clusters, around since the mid-1990s, were challenging to use until the message passing interface (MPI, a standardized message-passing system that runs on a wide variety of parallel computers) matured, soft-
ware was developed that could leverage it, and students were trained to use it. Similarly, it was not until Hadoop emerged and began to mature that the same clusters could be easily used for data-intensive computing (especially of unstructured data). A Hadoop software ecosystem had to be developed and students trained to use it. Demand is just beginning to rise as this data-intensive ecosystem matures and researchers are trained to use it.
As advanced computing technology advances, midscale users will benefit from work to develop easily used software and standardized configurations that can be scaled to different sizes and thus readily reproduced to serve larger communities through foundation, university, and industry partnerships.
5.7 EXAMPLE PORTFOLIO
NSF needs to act now in acquiring the next generation of computing systems in order to continue supporting science. The following is just an example of the sort of portfolio for hardware, together with supporting expertise, that NSF could consider, along with some explanations for the choices. This is not a recommendation; rather, it is an illustration of some of the options with the rationale behind them.
- One or two leadership-class systems, configured to support data science, traditional simulation, and emerging uses of large-scale computation. Such systems are needed to support current NSF science; by ensuring that there is adequate I/O support, as well as interconnect performance and memory, such a system can also address many data science applications. These systems must include support for experts to ensure that the science teams can make efficient use of these systems. Continuity of support for advanced computing expertise is essential because people with these skills are hard to find, train, and retain. Note also that these systems may not be optimal for any one workload, but can be configured to run the required applications more efficiently than other choices. Also, these systems should not be limited to running only applications that can run nowhere else; to ensure the most effective use of these resources, they should be used for a mixture of what might be called capability and capacity jobs, with priority given to the jobs that cannot be run on any other resources. In the case where funding is extremely tight and only one system is possible, that system must complement other systems that are available to the nation’s scientists, such as those operated by DOE, and memoranda of understanding among agencies may help ensure that the aggregate needs of the research community are met.
- A cooperative arrangement with one or more operators of large-scale
clouds. These are likely to be commercial clouds that can provide some access to a system at a different point in the configuration space for a leadership-class data system. This addresses the need for access to extremely large systems optimized for this class of data-intensive research. Conversely, because the commercial sector is rapidly evolving and scaling out these large-scale clouds, it makes sense to lease the service rather than attempt to build one at this time.11 Note also that the commercial sector is investing heavily in applied research for these platforms, which suggest that NSF emphasize support for basic research.
- A number of smaller systems, optimized for different workloads, including support for the expertise to use them effectively. It is important to have enough providers to provide distributed expertise as well as two types of workforce development: training for staff and training for students. Currently, XSEDE effectively provides this access to smaller systems optimized for different workloads. This capability is essential in supporting the breadth of use of advanced computing in NSF.
- A program to evaluate experimental computer architectures. This effort would acquire small systems (or acquire access to the systems without necessarily taking possession of them) and work with the research community to evaluate the systems in the context of the applications that NSF supports.12 This program will help inform the future acquisitions of the systems in the above three points, as well as inform basic research problems in computer and computational science, such as programming models, developer productivity, and algorithms. This approach differs from research testbeds for basic computer science; while important, those testbeds should be defined by the particular research divisions that need them.
- A sustained SISI program. Continue to learn from the SISI program and apply lessons learned to long-term investments in software.
___________________
11 Once NSF is using a large amount of time on a cloud, the cost of contracting with a service provider will need to be compared to the cost of operating its own cloud system. Many of the economies of scale that work for the cloud providers are applicable to NSF; the decision should be made based on data about the total costs.
12 Some centers are already evaluating systems with NSF and external funding. TACC supports Hikari (funded by Hewlett Packard and NTT) for exploration of the effectiveness of direct high-voltage DC in data centers supplied by solar power, and Catapult (Microsoft-funded) evaluates the effectiveness of a specific field-programmable gate array-based infrastructure for science. Other centers are conducting similar activities. The Beacon system at the National Institute for Computational Sciences, partly funded by NSF, provided access to Intel Xeon Phi processes before they were deployed in production systems by TACC. The team that proposed Beacon included researchers from several scientific disciplines, including chemistry and high-energy physics.



















