
Vishwas Chavan1
Global Biodiversity Information Facility
I am going to focus on how we are working to resolve the issue of data citation for biodiversity data at the Global Biodiversity Information Facility (GBIF), located in Copenhagen, Denmark. For those who have not heard about GBIF, it is a multilateral intergovernmental initiative established in 2001 with 52 countries as members and 47 international organizations. GBIF’s main objective is to facilitate free and open access to biodiversity data. Our data is available through a portal and currently, includes 312,000,000 data records about existence of lands and animals across the globe from over 1800 data resources that has been contributed by 342 data publishers.
Why do we think that data citation is important? We believe that data citation will encourage our data publishers to publish more and more datasets. Therefore, it will improve data discovery. It will also provide some kind of encouragement for data preservation. Furthermore, it will provide incentives to those who use the data through improving the credibility of the interpretations that are based on the data.
What is the current practice of data citation in the GBIF network? Let me explain this with an example. A user comes to GBIF’s portal and searches for the term “Panthera Tigris.” She gets 696 records from 37 different datasets, which are published by 31 different publishers. The current citation style just says “access through GBIF data portal” and lists out all the access points of those 37 datasets. The problem with this practice is that it doesn’t tell me what was the search string unless and until I can make an explicit statement about it, how many records were retrieved, how many data publishers contributed to the retrieved data, when search was carried out, who are the original contributors of the data, and who plays what role in the process from collection to publishing of the data?
So, certainly there is a need to work around these challenges. What is needed is a data citation mechanism with a defined citation style that can provide recognition to all stakeholders involved with their roles, such as who is the producer of the data, who is the publisher, who is the aggregator, and who provided curation service to the data. Given the complexity of our network, we require cascading citations, which are citations within the citations. Furthermore, we need a data citation service whereby a publisher can go and register its citation and all documents of metadata. Finally, we need a discovery service, which resolves to the full-text citation and links to the underlying data.
One of the first things that we think we need is a best practices guide for how to cite data. For that, we require two types of recommended styles. One is related to publisher supplied dataset citation and the other is related to query based citations. The publisher supplied dataset citation would obviously need to consider the types of publishers (e.g., an individual, a group of
______________________
1 Presentation slides are available at http://sites.nationalacademies.org/PGA/brdi/PGA_064019.
individuals, or an institution). We also need to recognize individual’s role in creating the dataset. We need also to identify when it was first released or whether it is a one-time release or frequently updated. Also, the citation should link back to the primary URI of the dataset and then the citation itself needs to have a persistent identifier (preferably DOI) so the entire citation string can be resolved. Also, we need to consider the date of the first release, the latest updates, and the number of data records that we can actually access from a particular dataset.
Table 17-1 provides a sampling of GBIF’s styles for potential citation strings or styles for the publisher supplied citations.
| Complete formulation | Short formulation | |
| Style 1 | Publisher (individual) with one-time release of dataset | |
| Publisher (YEAR), <Title of the data resource>, <total nos. of records>, published <modes of publishing>. <Primary access point>, released on: <release date>. <Persistent Identifier>. | Publisher (YEAR). <Persistent Identifier1>. | |
| Style 2 | Publisher (individual) with frequent update or release of dataset | |
| Publisher (YEAR). <Title of the data resource>, <total nos. of records>, published <modes of publishing>. >Primary access point>, first <released on; release date>, <current version no. or last updated released on (date)>, <Persistent Identifier>. | Publisher (Year first published're leased -). <Version no., or last updated released on (date)> . Persistent Identifier. | |
| Style 3 | Publisher (group of individuals) with one time release of dataset | |
| Publisher J, ..... and Publisher n (YEAR). <Tide of the data resource>, <total nos. of records>, published <modes of publishing>. <Primary access point>, released on <release date>, <Persistent Identifier>. | Publisher 1 etal. (YEAR). Persistent Identifier. | |
| Style 4 | Publisher (group of individuals) nith frequent update or release of dataset | |
| Publisher 1,..... and Publisher n <YEAR). <Title of the data resource>, <total nos. of records>, published <modes of publishing>. <Primary access point>, first released on' <release date>, <current version no. or last updated/released on (date)>. <Persistent Identifier> | Publisher 1 etal. <YEAR (Year first published released -)>. <Version no.,or last updated released on (date)>. Persistent Identifier. | |
| Style 5 | Institute consortium (multiple contributors) nith one time release of dataset | |
| <Publisher as Institution / Research Group ' Consortium> (YEAR). <Tide of the data resource>, <total nos. of records>. <Contributed by contributor l(role), contributor 2 (role)..... contributor n(role)>, '<published (modes of publishing)>. <Primary access point>. released on- <release date>. <Persistent Identifier>. | <Publisher as Institution / Research Group / Consortium> (YEAR). <PersistentIdentifier> | |
| Style 6 | Institute, consortium (multiple contributors) nith frequent update or release of dataset. | |
| <Publisher as Institution '' Research Group ' Consortium> <YEAR (Year first published released -)>. <Tide of the data resource1>, <total nos. of records>, <Contributed by contributor l(role), contributor 2 (role)..... contributor n(role)>, <published (modes of publishing)>. <Primary access point>.<Version no., or last updated released on (date)>. <Persistent Identifier> . | <Publisher as Institution / Research Group / Consortium > <YEAR (Year fust published 1 released -)>, <Version no., or last updated released on (date)>, <Persistent Identifiers> | |
In the case of the query based citations, where we need to have citations within citations, there are two types of citations that we think are required. One is query based citations and the other publisher supplied dataset citations. Such a citation needs to have multiple types of persistent identifiers that have been assigned or used by publishers themselves.
So, going back to the example of the user who searched for the term “Panthera Tigris”, a hypothetical exemplification of this search is presented in Figure 17-1. This query based citation will resolve to complete computer citation and it can also link back to the snapshot of the retrieved data, which are cited. This is how it will look like when you resolve the DOI:
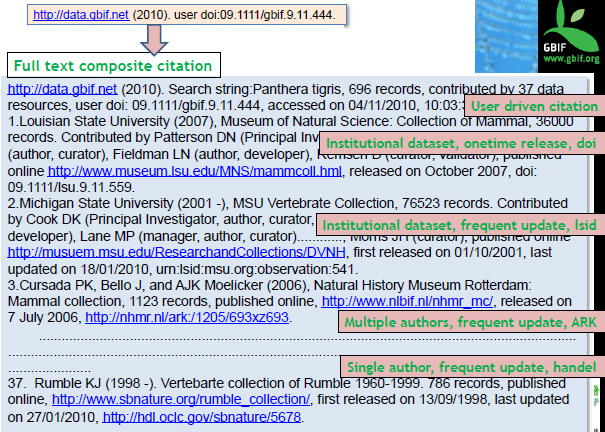
FIGURE 17-1 Hypothetical search result.
Let me conclude with a summary of the implementation and next steps. The main challenge to implement this mechanism is the complexity of data management itself. How do we make sure that all our data publishers are going to follow through the citation style that is being proposed? There is also the complexity of the data network because many publishers publish the data through more than one access point.
Therefore, we urgently need to have all these citation styles propagated in the form of a best practice guide. However, we also need to remember that there are social challenges related to updating the current practices. Finally, somebody has to come forward to run the data citation service. These are some of the challenges that we are currently trying to address.
This page intentionally left blank.




