
22- Data Citation and Data Attribution: A View from the Data Center Perspective
Bruce E. Wilson1
Oak Ridge National Laboratory and the University of Tennessee
One of the several things I am doing right now is pushing the question of how to enable scientific collaboration and, in particular, how to put in place the technology to do that. I am also working with my colleges at the University of Tennessee to look at these issues from a sociological perspective.
For three years, I was the manager of the Oak Ridge National Laboratory (ORNL) Distributed Active Archive Center (DAAC) for biogeochemical dynamics. It is one of NASA’s Earth Observing System Data and Information System (EOSDIS) data centers managed by the Earth Science Data and Information System (ESDIS) Project. The ORNL DAAC archives data produced by NASA’s Terrestrial Ecology Program, as well as data of particular interest to scientists funded by that program. The ORNL DAAC provides data and information relevant to biogeochemical dynamics, ecological data, and environmental processes that are critical for understanding the dynamics relating to the biological, geological, and chemical components of Earth’s environment.
I also spent eighteen years in private industry. I mention that because this experience influences in some ways my perspective on data citation and attribution issues. In addition, I have had some involvement in projects with the National Biological Information Infrastructure, at the USGS, and I continue to work on the citizen science side of data submission and data citation for the U.S.A. National Phenology Network (USA-NPN).
At the ORNL DAAC, we make sure that the data generators get credit for what they have done. An incentive for data attribution is to ensure that the data center gets credit for hosting the data as well. We also want to understand what data are or are not being used. For example, we have good statistics about how many times datasets were downloaded. These data show that, on average, it takes about 18 to 24 months from when a dataset gets downloaded to when it gets cited, if it gets cited or referenced at all. We found that some datasets are downloaded more, but may be cited less. Does that indicate that the data are hard to use, that there are barriers to being used, or that there is something wrong with the data? There is typically no single answer to that question, and it is something to investigate on a dataset-by-dataset basis.
This kind of use metrics (not only of downloading, but of actually using a dataset) can be extremely valuable for the data center to understand its business model and operational environment. For example, it helps us understand how the data are being used outside of the scholarly context.
Tracking the use of an individual dataset is important, but what is the value for a data center if these data were used in a university study, for example? What is the value to the data center and
______________________
1 Presentation slides are available at http://www.sites.nationalacademies.org/PGA/brdi/PGA064019.
to the sponsor if we did something that made the data easier to use in undergraduate education classes? So, it is arguably valuable to the science and scientific community, but how do we measure that? How to we understand those kinds of uses?
Here is an example of dataset citation:
Gu J. J., E. A. Smith, and H. J. Cooper. 2006. LBA-ECO CD-07 GOES-8 L3 Gridded Surface Radiation and Rain Rate for Amazonia: 1999. Data set. Available on-line [http://www.daac.ornl.gov] from Oak Ridge National Laboratory Distributed Active Archive Center, Oak Ridge, Tennessee, U.S.A. doi:10.3334/ORNLDAAC/831.
We started adding the DOI to this citation style about five years ago. The major reason for adding the DOI was that we had a citation without the DOI and some journals rejected it because it was not a valid long-term citation.
We put the DOI into it because the DOI is an established standard and one that the publishing community, in particular, uses. Using the standard that makes sense to publishers helped to reduce the barriers to adoption of data citations. And a second key point is that the citation contains key information we need: the names of those who created the dataset, it tells where to find the data, and it has a persistent identifier Let me now focus on the data center roles and responsibilities in this process. I think a key role here is the issue of stability. Data centers need to provide stability through using persistent identifiers and ensuring technical, social, and organizational sustainability.
Data centers also have to encourage use and make it easy for users. We need to make it easy to download datasets like a bibliographic set. Furthermore, we have to work on challenges such as what does the identifier points to, how to handle continuous data, sub-setting, on-demand data, as well as issues related to scalability of the data management process. We have to work on some fundamentally different paradigms and be willing to take some risks about changing our business model.
Let us now see how our datasets actually get used. The Figure 22-1 shows the growth in cited versus referred databases. Compiling the information for this table was an effort of multiple weeks by the ORNL Library and the ORNL DAAC staff.
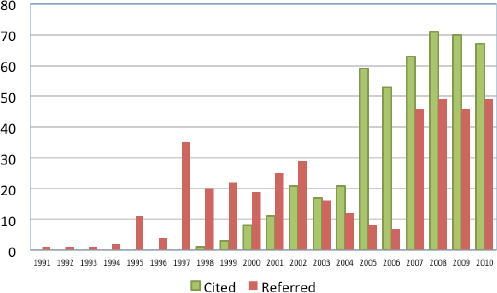
FIGURE 22-1 Growth in cited vs. referred databases.
This diagram shows an increased number of datasets cited versus referred. By “cited” we mean that the ORNL DAAC dataset is in the bibliography or in the requested format; and by “Referred” we mean that we infer, from the text of the article, that one or more ORNL DAAC datasets were used in the work. ORNL DAAC requests that data be cited in the list of references.
This time series provides evidence of some changes in scientists’ behavior towards data citation and attribution. The best way to facilitate and promote this change is through having more champions. Academicians and scientists are only going to do something if somebody who is successful tells them that it has worked.
This page intentionally left blank.




