
The Power of Simple Models in Manufacturing
JAMES J. SOLBERG
Despite being admonished repeatedly to “keep it simple,” most of us who deal with technical issues in manufacturing persist in developing evermore complicated models. There are some good reasons (and also a few bad ones) for doing so. At the heart of the matter is the fundamental reality that manufacturing processes are complex. As we advance in our understanding of these processes, it seems natural to incorporate additional complexity in models. Another contributing factor is the increasing power and availability of computers. With this increasing capability comes the opportunity to compute what we never before could compute, and this opportunity presents compelling temptations to see how much we can do. Furthermore, we tend to associate the quality of a model with the degree to which it faithfully represents the system and conditions it purports to model. If we are forced for whatever reason to make simplifying assumptions or to omit details, we regret the necessity and view the step as a loss, a deficiency, a compromise between what we would like to do and what we are able to do. Of course, we know that models always involve some degree of simplification, but we are generally reluctant to introduce more than is forced upon us.
I will call this concern for the faithful correspondence of a model to its referent a concern for validity. The thesis of this paper is that we—those of us in the research community who have been developing models for manufacturing—have been preoccupied with validity to the point that other im-
portant attributes of models have been neglected. In particular, we have sacrificed clarity, generality, and (most important) credibility. The ultimate consequence of this imbalance is that many of our models are not used.
Some cynical observers have gone so far as to accuse academics of deliberately introducing obscurity into their papers in the interest of preserving the mysteries of their priesthood. Others have suggested that the “publish or perish” pressure and all that goes with it creates an environment in which complexity and obscurity will inevitably flourish (Grassman, 1986). My personal view is that the situation is due not so much to insidious forces as to simple lack of attention to important matters. My hope is that well-meaning scholars can and will adjust their behavior when they see that they could be much more effective than they have been. Certainly, they have a good deal to gain in respect and influence if they do.
WHY WE MODEL
There are many categories of modeling technique, including optimization, simulation, control theoretic, systems dynamics, queueing, and statistical, methods. Each of these categories is defined by conventions, terminology, standard formulations, and methods. Specific models usually fall into one of these distinct categories, although one occasionally encounters hybrid models that cut across the boundaries. All of these modeling techniques have had their capabilities extended greatly over the past few decades. With the increase in power and availability of computers, we have been able to deal with many more parameters. Perhaps the possibility of doing what we could not do before has lured us into accepting without question the view that more detail is better.
We usually do not think very much about what a model is for, since we all understand what these various techniques do. Let us say, to be general, that the basic purpose of any model is to expose the truth about some aspect of reality. However, and this is the point I wish to emphasize, exposure involves more than discovery; the truth must be understood and believed in order for it to carry any influence in the making of practical decisions. In seeking technical validity, being sure that what we think is true really is, and is not just an artifact of the model, we can easily fall into the trap of building so much into the model that the details or the structure conceal the very truth we want to expose.
Even inexperienced interpreters of models know intuitively that many things can go wrong in models: assumptions might be faulty, the data that went in might have been wrong, the computer program might have bugs, results might be misinterpreted, and so forth (Houston, 1985). Even after the creators of a model have established to their own satisfaction that the model is technically valid, few people are gullible enough to accept the
creators' conclusions at face value. Particularly when the details are hidden within computational chains and loops inside a computer, most of us have learned from experience to maintain a healthy skepticism about artificially generated data. The larger and more complicated the model, the more skepticism is appropriate. Thus, we are left with the ironic dilemma that the harder we try to be correct, the less likely we are able to convince others that we are.
Most of us are acutely aware of the danger of believing in the results of a model when it is wrong. Let us call this a type I error, following the terminology used in statistical hypothesis testing. We usually mitigate or guard against such errors by stressing validation. The other kind of error, which corresponds to not believing that what a model indicates is correct when in fact it is, can be called a type II error. In this terminology, we say that in attempting to avoid type I errors, we often increase the likelihood of a type II error. Or, to say it yet another way, we seek validity at the expense of credibility.
Perhaps one reason we tend to neglect the possibility of type II errors is that credibility involves the perceptions and psychology of the beholder, whereas validity is more a property of the model itself. Another factor may be a greater fear of the dangers of a type I error: being wrong seems worse than not being believed. Nevertheless, these two types of errors are equally detrimental to the successful application of models.
Apart from issues of credibility, another consequence of excessively complex models is decreased generality. As we add details or complicate the structure, we are forced to make more and more assumptions. Although these assumptions may be entirely valid for the situation at hand, the increased specificity limits the range of applicability. If conditions change, or slight variations need to be considered, the model may no longer apply.
Yet another deficiency of complex models is the cost of developing and operating them. If the time required to collect the data necessary to run a model is excessive, or the expertise required to interpret the results is unavailable, or the time required to obtain results exceeds the time available for considering the decision, then the model cannot be of much help.
THE POWER OF SIMPLICITY
Turning from these criticisms of complex models to the advantages of simple models, I propose the following generalization. The power of amodel or of a modeling technique is a function of validity, credibility, andgenerality. Usually, the simplest model that expresses a valid relation willbe the most powerful. By emphasizing the power of a model as a more comprehensive measure of its utility than validity alone, I hope to encourage attention to these other aspects.
As examples of powerful models, I could cite the laws of thermodynamics, Newton's laws of force and motion, and many other familiar “elementary” equations of science. All of these are extremely simple to state but profound in their application. There are a few such laws that apply to manufacturing, such as Little's equation (see Little, in this volume), but surprisingly few such powerful relations have yet been discovered. My hope is that a deliberate effort to find them would be fruitful. This view can be expressed in a second proposition: It is neither necessary nor desirable to build complicated models to deal with complicated situations. Indeed, we should be trying to find a point of view that makes complicated situations seem simple.
Of course, we must be aware that simple does not mean trivial or obvious. We cannot define relations arbitrarily, make capricious assumptions, or generalize recklessly. Einstein is reputed to have said, “Things should be as simple as possible, but no simpler.” Finding the adequate level of detail, the appropriate assumptions, and the elegant formulation is a matter of hard work and inspired wisdom (and perhaps a large dose of luck).
I believe that at least part of the reason that we have few simple models available to us in manufacturing is that we have not yet made a serious effort to define them. In striving to exercise our techniques to their extreme limits, and captivated by our new-found abilities to compute, we may have overlooked opportunities that would benefit us more. It may be too much to hope for laws of manufacturing that are as simple and powerful as the laws of thermodynamics, but we can certainly redirect our emphasis to developing models that are as compelling in their credibility and generality as they are impressive in technique. The goal should be to find not how much can be put in but how little will suffice to get the job done.
AN EXAMPLE
The following discussion is intended only to illustrate how a simple model can expose a general truth in a way that is practical, rigorous, and convincing. The model tracks the progression of a single product unit through stages of completion. It does not matter what the product is, what processes are involved, how long they take, or where the boundaries of the system are drawn.
A product unit is the thing produced. It may be a set of objects (e.g., a batch or an order), and it will generally undergo physical changes as it advances. A product unit could consist of a single workpiece, a subassembly, a batch, or a group of assemblies. A manufacturing unit adds value to product units while consuming time. Each of these terms is defined in such a way that the same term may apply at both atomic and aggregate levels. For example, a manufacturing unit could be a single machine, a group of
machines, a department, a plant, or even an entire industry. This point is important to achieving generality in our results. When we state a result that applies to units of this degree of abstraction, the result will be applicable in many ways.
There are other kinds of units a product unit may pass through in completing its processing. For example, a transport unit changes the physical location of product units while consuming time, whereas a storage unit is passive with respect to value and location, but consumes time. A manufacturing unit may contain other manufacturing units, as well as transport units and storage units.
In this model of manufacturing, only two things happen: time advances and value is added. For any stage of the process, we can portray the change in these two dimensions. We may do this either continuously or at arbitrarily selected times. We will make no assumptions about mathematical continuity, differentiability, or monotonicity of the changes. Although time is irreversible, we could have situations in which value is lost, such as when a process is destructive.
We can now suggest a convenient visualization of a manufacturing unit on a value-time scale, from the point of view of a single product unit (see Figure 1 ). The effect of the manufacturing unit is defined completely by its starting time and value and its final time and value. We can therefore portray the changes in these two dimensions as a rectangle in the value-time plane. We do not necessarily have to know anything about what takes place within that rectangle; we can treat it as a “black box.” Note that this picture does not consider a stream of products —just what one product unit sees in passing through an arbitrarily defined manufacturing unit.
We can string several such rectangles together to portray what a single product unit sees in passing through a sequence of manufacturing units, as
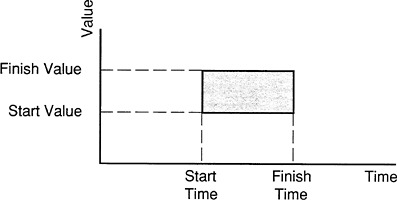
FIGURE 1 One manufacturing unit.
shown in Figure 2 . The level-value lines connecting the rectangles represent the passage of time with no increase in value; hence they represent storage or transport units or possibly other forms of delay. (Incidentally, it is not necessary to assume that the value remains constant during these periods. The level lines are just special cases of rectangles, in which the height is zero. Furthermore, we could treat cases in which value declines during periods of storage, as in the case of perishable commodities, with no change in our approach.)
The different rectangles might correspond to workstations or departments in a factory, or, at another level of aggregation, they might represent different plants or warehouses. In a model of the processes involved in new product development, the rectangles might represent design, planning, or tooling. We could also refine the view to see what happens in a manufacturing unit represented by one of the rectangles, as shown in Figure 3 .
We can nest manufacturing units, transport units, and storage units within manufacturing units. We can aggregate or refine to any level without altering the fundamental idea that a manufacturing unit increments value in a period of time.
As an early indication of the value of this visualization tool, let us imagine that we would like to improve the process represented in Figure 2 . Where should we focus our efforts?
Define the “value improvement rate” to be the amount of value increase that a product unit receives by passing through a manufacturing unit divided by the time required. Graphically, this would correspond to the slope of a line drawn from the lower left corner of the rectangle to the upper right corner (see Figure 4 ).
All other factors being equal, we can improve the process within some overall manufacturing unit by either increasing the amount of value added or decreasing the time required; graphically, we would like to increase the
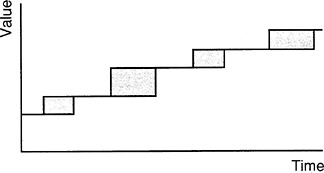
FIGURE 2 Several manufacturing units in sequence.
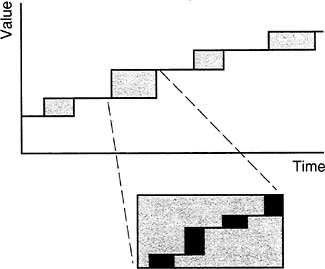
FIGURE 3 A refined view of a single manufacturing unit.
slope of the diagonal. The same interpretation applies at any level of aggregation.
A typical process improvement program will focus on the technology or management involved in just one of the manufacturing units. For example, a just-in-time production control program might be introduced in the unit represented in the second box in Figure 2 —perhaps a plant or one department of a plant. However, we can easily see in Figure 5 that increasing the slope of the second box cannot alone have much of an effect upon the overall slope of the aggregate unit. In fact, if the time saved is just con-
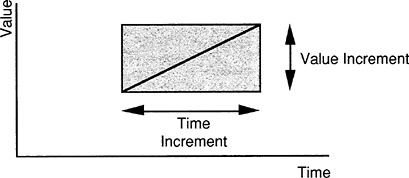
FIGURE 4 Value improvement rate is given by the slope of the diagonal.
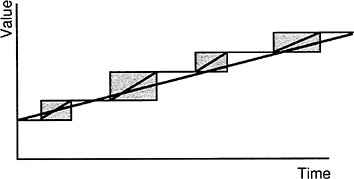
FIGURE 5 The slopes of each unit and the overall slope.
verted into an equivalent time in transport or storage, then the slope of the diagonal of the aggregate manufacturing unit would not be changed at all. This is a fairly obvious point once stated. However, the picture gives strong visual confirmation of the notion that working on one subsystem does not necessarily improve the performance of the whole system.
If Figure 2 or Figures 5 represented a complete system, it would be apparent that any effort to improve the system should go into reducing the time lost in transit or in storage between the four subunits, since each of these has an individual slope that is better than the overall slope. These delay times between manufacturing units are frequently neglected, simply because they fall in the “hand-off” between departmental jurisdictions. In other cases, of course, one unit may stand out as the subsystem needing attention.
It may occur to you that an algebraic model could accomplish what we have shown here, with the added advantage of quantifying the parameters. You may also think of further embellishments that could be added to the model, such as costs or quality measures. If you are tempted to see what you can do with these extensions, you are experiencing the very proclivity to complicate that I have been warning against. However, you are invited to use or vary the model as you please. You may also want to consult a paper by Sullivan (1986) that proposes a similar modeling concept.
CONCLUSIONS
Some 20 years ago, John D. C. Little wrote a particularly cogent paper on the failure of operations research techniques to achieve much acceptance, for some of the same reasons expressed here (Little, 1970). Although his remarks related primarily to applications in marketing, the same comments are equally suited to manufacturing, and the passage of time has done little to change the situation.
By recognizing that the power of a model is directly proportional to its simplicity (rather than its complexity), we may be able to redirect some of our attention to new formulations. I do not expect these to be easy to generate, for it is harder to know what can safely be left out than it is to just put everything in. But there is no doubt that both the user community and the research community would be better served by models that are elegantly simple than by more elaborate constructions that go unused.
Having an arsenal of such simple models available, along with the more detailed techniques that have already been developed, would allow a more rational choice of appropriate complexity. The simple models could be used in preliminary studies, perhaps to identify key issues or to justify further investigations. More elaborate models could be used to fine tune or to explore deeper issues. It is hoped that such a spectrum of possibilities would provide greater acceptance of what the modeling community has to offer.









