
Printing Chemical Structures Electronically: Encoded Compounds Searched Generically with IBM-702
W.H.WALDO and M.DE BACKER
Objective
In a paper entitled “Routine Report Writing by Computer” by Waldo, Gordon, and Porter published recently in American Documentation, announcement was made of an industrial research report writing system where a large-scale computer functioned as its core. The paper made reference to a new method of encoding the structures of chemical compounds for automatic storage and retrieval. The input from the raw data was simple enough to be handled by clerks. The output was a printed structure recognizable and acceptable by a trained chemist. Furthermore, the computer was programmed to permit generic searches to be made.
This paper describes the details of the structure coding, methods of searching, and retrieving, as well as a discussion of some of the things that we have been able to do and plan to do in the future. It is hoped that this paper will be the basis for discussion, further research by others, and whatever changes that are necessary to bring about a full-dress review of the whole field of chemical structure codes and ciphers. The chemical profession is sorely in need of a generally accepted method for indexing the structures of organic chemicals.
Discussion of other systems
In 1945, Dr. D.E.H. Frear of Pennsylvania State University (1) generated a code which through the cooperation of many competent chemists was adapted by the National Research Council’s Chemical-Biological Coordination Center. This represented the first full-scale attack in this country on the problems
W.H.WALDO and M.DE BACKER Monsanto Chemical Company, St. Louis, Missouri.
of correlating chemical and biological data and searching for the members of a family of compounds encoded from the literature.
Since that time many ciphers have appeared which were designed to permit the indexing and searching of chemical compounds, such as those of Dyson, Wiswesser, Silk, Gruber, Wiselogle, and Gordon-Kendall-Davison.
To evaluate these systems the cooperation of one hundred chemists throughout the United States was secured to encode and decode compounds by several of these systems (2). The results of the experiment were particularly revealing in that not only were the ciphers not chemically unique but it was especially difficult to regenerate the original compound from the cipher.
Since the appearance of these ciphers, two other systems of recording chemical structures have been announced that are based upon a topological principle. Topology is involved also in the system described in this paper, which, incidentally, was independently conceived prior to the announcement of either of the other systems.
These two systems that involve the principles of topology are those of A.Opler and T.R.Norton (3) and L.C.Ray and R.A.Kirsch (4). Both the systems are in operation and further attention is directed to them for comparison with the system described in this paper.
The principle of topology involved here assumes that a chemical represented by its structure consists of hard cores (the chemical elements involved) joined by rather flexible links (the several types of chemical bonds). It is further assumed that these hard cores and links flexibly connected may be twisted into a large but finite number of shapes. Long alkyl chains can be stretched or bent, hexagonal and other ring systems may be squeezed into rectangles; rings may also be stretched to permit the inclusion of bridge-heads. The various moieties may be twisted about to permit the writing of any structure that can be displayed on paper.
Our system has two features not found to our knowledge in any other. The encoding is simple enough to be done by trained clerks. The output may be a two-dimensional printed structure easily recognizable by trained chemists. Both of these advantages were specified requirements when the project was undertaken.
Monsanto’s approach
The project was undertaken at Monsanto for reasons similar to the several others previously mentioned. We are in dire need of some method to index structures and permit their retrieval by classes. The program was undertaken, strangely enough, not by a librarian, nor by a document custodian, but by a
technical editor. The reason lay in the belief that the solution to the critical structure problem would open up the entire field of chemical documentation to machine handling.
Every discussion of machine documentation in the field of chemistry ultimately results in a discussion of chemical codes and means of recognizing selected groups of chemicals from the rapidly increasing list of known compounds. Three years ago when the project was in the discussion stage, we at Monsanto felt that once the structure storage problem appeared to be solved, the solution should be only a part of an entire machine documentation system.
We also felt that our research program should proceed in small increments, each increment being reduced to practice before investing in the next increment. Such a procedure, a typical industrial approach, guaranteed a maximum return for a minimum of investment.
There was another design criterion in our philosophy of approach. This criterion involved the belief that any mechanized documentation system was doomed to economic failure if it was not a total system. Partial systems have been studied for many years, and the results of their work have laid the basis for this conclusion. The system must be designed around the capacity of the machine rather than try to force a machine to do some segment of the classical technical information system.
Reports written for immediate consumption are difficult to index for posterity because of their local jargon. Papers written in Japanese or Russian are difficult to read by Americans unless the readers are especially familiar with the foreign language. Thus total communication is not effected by journal publication. It is, furthermore, generally conceded that no individual scientist is interested in the mass of chemical literature, making critical abstracting virtually impossible. What may be absurd and formless to one man may be the key to the enigma in the mind of another. Also, authors of chemical articles are especially adept in contributing knowledge in an incidental way, incidental, that is, to their primary purpose in writing, so that information may be lost in the communication system, author-referee-editor-abstractor-indexer-searcher.
To avoid these blackouts in our technical communication system, we believe it is imperative that any new system that may be invented has no hope for success unless it begins with the bench worker, passes through all the necessary steps, and concludes with a future user of the recorded facts.
Thus to invent a code for chemical compounds without having in mind at the time the chemist at the laboratory bench doing research, the report writer, the documentalist, the current report reader, and the ultimate retrospective searcher is a mistake. Their interests are only in the information recorded
rather than a complex code by which the information was stored, and the code never can be depended upon to produce a functional, economic, and acceptable tool for furthering chemical research. It is chemical research that we are interested in furthering. Chemical documentation, at best, is a service to chemists.
In our opinion one of the most serious drawbacks of the various ciphers and codes proposed for the storage of chemical structures is the ultimate dependence upon a book of rules that is too thick to be memorized easily. We believe that our system is easily learned and can be readily incorporated into the education and language of chemists.
No matter how appealing, how erudite, how clever, astute, or how novel a documentation system may be, if it is not acceptable or easily sold to the practicing chemists involved, it is doomed to failure. The system must be better than the present system, not in our opinion, but in the opinion of the scientists who are to be its ultimate benefactors. To satisfy management it must have some inherent factor of savings. To satisfy the authors, it must be an improvement on what they are now doing in terms of time and effort. To satisfy searchers, it must be quicker, more complete, and more accurate.
Rewriting Structures
Although our philosophy of approach is independent of the hardware, the details of this work are reproducible only with the 702 or 705. One other important factor in Monsanto’s approach to machine documentation of chemical information is possibly a limitation in so far as this paper is concerned. We had available to us a large-scale electronic data processing machine, the IBM-EDPM-702. All the work has been performed with the 702 or lesser IBM equipment. We hope that our work can be adapted to computers manufactured by other concerns. Some of the work might also be adapted to medium-sized computers. However, many of the rules and conventions that may appear at first glance to be arbitrary were invented to be compatible with the 702.
We believe that this paper describes an entire chemical documentation system from the generation of the information to its ultimate use at a later date. Of course, the key is the storage and retrieval of chemical structures in a manner that meets these criteria.
It may sound impertinent to say that structures to be encoded for machine storage must be accurate, but there is no slander intended. Rather it is recognition that specialists in one branch of chemistry or another often take much for granted when they record a structure of a compound that they have just synthesized. Aromatic rings must have the double bonds shown. Empirical
aliphatic chains leave the geometric isomerism in doubt. The presence of double bonds must be indicated, not assumed. For instance,—CSSR (a moiety) may represent a polysulfide or a dithioate. Since these factors are important for any search, they must be properly encoded and not left in doubt. However, our system does not require the presence of every hydrogen atom to be shown. Indeed, the hydrogen atom has no place in our storage system, and, as you shall see later, the computer has been instructed to determine the proper number of hydrogen atoms for each structure stored.
A structure is stored by first writing the structure clearly and accurately in the conventional form.
The encoding consists simply of rewriting the structure on common cross-hatched paper with numerals used for chemical bonds and single character letters for the elements. Table 1 is a list of the bonds involved.
TABLE 1
|
1=single bond 2=double bond 3=triple bond 7=ionic bond, designating salts, complexes, etc. 8=the point of attachment bond, where there is an indeterminate number of C atoms in a chain 9=the point of attachment is in doubt where there exists indeterminate geometrical isomerism /=a special bond, symbol used in rare cases to indicate single bonds only. |
Table 2 is a list of the single character letters that we have used to represent the elements involved in the structures. We hasten to point out that our problem is primarily with organic chemicals.
TABLE 2
|
C=carbon N=nitrogen O=oxygen S=sulfur P=phosphorus X=chlorine Y=bromine I=iodine B=boron L=silicon F=fluorine R=any wholly covalent moiety M=all other elements |
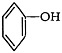
The elements and bonds are placed in the squares of the cross-hatched paper to compare exactly with the original chemist-written structure. To show the general principle, consider the structure of phenol.
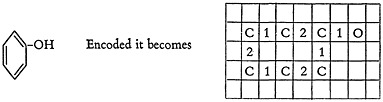
You will note the following conventions: (1) the aromatic resonance is frozen into the alternating sequence of double and single bonds; (2) there are no hydrogens in the system, thus a single bonded oxygen represents a hydroxyl group; (3) the hexagonal benzene ring, so common to organic chemistry, becomes a rectangle. This form of the organic structure is now ready for a keypunch operator. To make it convenient for her the structure must be “boxed” and punctuated, viz.
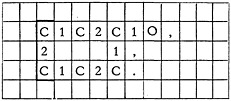
The “box” is simply the left-hand, top, and bottom limits of the structure. The punctuation is the right-hand limit. Boxing and punctuating make it a simple matter for the keypunch operator to enter the structure onto a punch-card.
All structures are handled in an analogous manner. The rules presented so far are sufficient to handle the great majority of compounds, including many steroids. However, there is a relatively large number of compounds that require some special handling.
Compounds with an odd number of elements in the ring (five or above) are handled by repeating the appearance of one of the bonds three times, so that the rectangular configuration is maintained. For example:
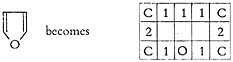
Three-membered rings and penta-substituted elements such as phosphorus and nitrogen, a relatively infrequent occurrence, are handled with a slash.
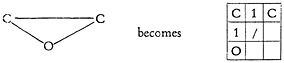
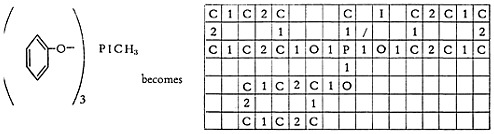
An alkylated phenol, where the position of the side chain on the ring may be unknown, is handled with the 9. For example:

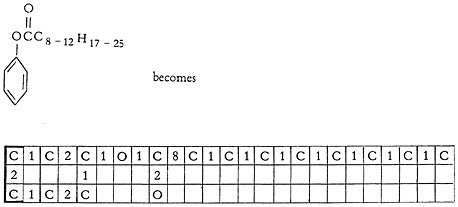
If the side chain is made from, say, a mixture of fatty acids, the 8-bond is used, and the lowest number of carbon atoms possible in the mixture is written out. Thus:
Sodium acetate shows the use of the ionic bond 7.
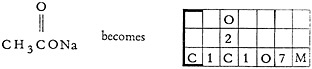
Figure 1 shows how the structure for strychnine can be handled.
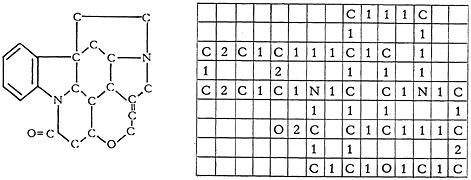
FIGURE 1. Encoded structure for strychnine.
Terpenes and other compounds with bridgehead structures create what appears to be a problem in geometry. But the problem was resolved by using the same principle as was used for 5-membered rings, namely repeating the bonds in the outermost rings a sufficient number of times to permit the inclusion of the bridgehead within.
Figure 2 presents the structure of codeine as an illustration. Arbitrarily we have limited the number of characters in the horizontal line to 98 since the computer is limited naturally in the length of line it can print. Furthermore, we have limited the number of rows arbitrarily to thirteen to accommodate our report-writing program (5).
To make the search program somewhat easier we have ruled further that
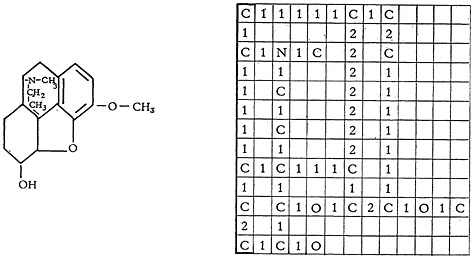
FIGURE 2. Encoded structure for codeine.
long saturated straight chains may not be bent after the second carbon.
Coordinate covalent bonds are ignored as such and are represented as a 2.
There is a myriad of ways of writing a given structure. It makes no difference how this is done so long as it is accurate. The computor will seek out all variations.
Storing Structures
In our system each compound has a number assigned. The key punch operator punches the information from the coded sheet in a continuous sequence onto 80-column IBM cards. The structure for phenol is in the conventional form:
in encoded form
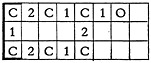
and keypunched in an IBM card:
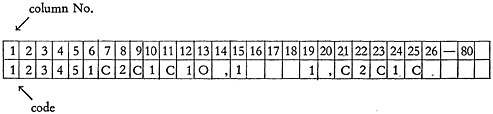
The first five columns of the card are punched with the compound identification number. Column 6 is a sequence control position for card numbering, and the balance of the card is for structure data storage. A maximum of ten cards may be used for each record, allowing storage of 740 characters of structure data.
The program or instructions for the computer are stored permanently in a small deck of IBM cards. All data cards to be added to the structure file are entered in the computer along with this program load deck.
Each group of cards comprising a complete structure is transcribed through the computer to magnetic tape into the form of a variable length record. Since the record size may vary from 45 to over 700 characters, the variable length feature allows maximum reading and writing speed in computer operations.
Only significant data are sent to and from input-output devices. The maximum number of records may be stored on a reel of magnetic tape for the same reason.
As the record is being transformed from the punched card format to the output format, the 702 calculates certain control information it needs in order to remember how to reproduce the structure when called upon. It counts the number of horizontal rows in the structure (three for phenol); it also counts the number of columns in each row of the structure beginning at the left edge as indicated by the box line and terminating with the punctuation. Editing is then performed by the 702 to ensure that the structure does not contain an incorrect number of rows and that each row does not contain an improper number of characters.
Incorrectness occurs, of course, as a result of human errors. We have noted two empirical coincidences; both of which are used in this editing process. Because of the ever present sequence of elements and bonds and the sound chemical principle that a bond must lie between two elements, the number of rows in our rewritten structures must of necessity always be odd, 1, 3, 5, · · · 13. Similarly the number of characters in any row must be odd, since all elements are single-character symbols as are the bonds. However, the last position in every row is signaled with a punctuation mark. Thus the number of characters in a row is always even, two through ninety-eight. When errors are detected, the structure is rejected for entrance to the permanent file. If correct, the control numbers are stored as a part of the structure record.
Thus, for phenol, the record may be represented:

The 32 blanks are reserved for the molecular formula. The computer, after the structure is stored in this manner, proceeds to calculate the molecular formula and insert it in its proper place in the record.
As the formula is being constructed, further checking by the machine is performed to determine the accuracy of the input data. The rules established for coding structures are integrated in the program so that the computer is able to take a fairly sophisticated look at the chemist’s coding and the keypunch operator’s work. It will not allow any atom to have too many or too few bonds, nor is a “7” bond code permissible with atoms for which ionic bonds are not “legal.” Improper atom and bond codes and misplaced characters are recognized by the computer, as are various other types of errors.
There are, of course, many errors the computer cannot possibly detect. If the chemist intended to code benzene:
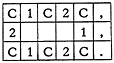
and coded cyclohexane instead
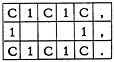
the computer is blind to the error.
For the structure determined to be erroneous by the machine, a record is written showing the structure as coded, together with a message indicating the reason for rejection. These are checked by a coder and necessary corrections are made prior to re-entry to the computer.
Hydrogen atoms are not coded as a part of the structure in our system. This poses another problem for the computer in calculating the molecular formula. It must recognize that in phenol, coded:
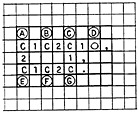
one hydrogen atom is located at each position A through G. The computer recognizes this, and adds the necessary number of hydrogens to the molecular formula. For carbon this is easy. The infallible rule of 4 covalent bonds permits this computation without the computer being too sophisticated. The halogens also give no problem since organic halogens are bonded with only one covalent bond. Likewise oxygen has only two covalent bonds. However, nitrogen, phosphorus, and sulfur are not so easily handled, and a set of rather sophisticated rules is written into the molecular formula program so that the computer can recognize amines from azides, sulfites from sulfonates, and phosphites from phosphonates, etc.
When the formula has been calculated, the complete structure record, in-
eluding the molecular formula, is written from the central computer to magnetic tape. A complete tape record has the following format:
The apparently correct structures are also written in the same manner as those in error, but with no error message. These may then be scanned by chemists for errors unrecognizable to the 702. All the new structures, in an updating run, are thus printed in the original coded form. (These output structures, incidentally, are written on magnetic tape initially, and printed later with peripheral equipment, thereby releasing the computer for other work.)
One reel of magnetic tape produced by the 702 may hold over 25,000 typical structure-molecular formula records. Thus, a single file, consisting of only a few reels, contains all information necessary for searching and printing many thousands of chemical structures.
Preparing the search question
A chemist proposing a search of the chemical structure files for a specific substructure or chemical moiety must state precisely the elements, bonds, connections, and so forth, he desires to locate. The search specifications supplied are transformed to IBM cards, and become the set of rules by which the computor will perform the search.
Search questions such as finding all the derivatives of diphenylamine are meaningless to the computer. The chemist posing the question must determine for the computer what is meant by a derivative. It can pull out for the chemist all diamines, all compounds having two carbon atoms in a sequence (substituted ethylene), or it can pull out all compounds having the sequence:
Control data include the molecular formula requirements and the substructure, coded in the same manner as the structure record. Further control information is utilized to control the switching network during the search.
One coded form of the substructure is entered to the computer. As pointed out before, there are many different ways in which a group of elements and connectors may be coded. The coded substructure may appear in the structure in the form as coded on the control card. In most cases, however, it will be
in any one of the many other mutations possible. A benzene ring, for example, may appear:
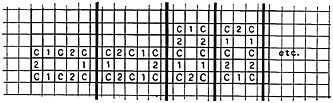
The difficulty in performing searches of this type of record becomes obvious. With several chemists acting in different ways at different times, similar structures may be coded in many different ways. Little education is needed for a human being to code the chemical structures for input to the computer, but this is counterbalanced by the fact that much education is necessary for the computer to locate substructures in the coded form. The advantage is, of course, that the chemist’s time is available for more important duties that computers cannot perform; and our educated computer must be put to work.
The instructions for the computer can, to a certain extent, be compared with the instructions one would give a clerk who knows nothing about chemistry to scan a file for substructures. He would be told specific things must appear in certain forms, and no other type of thing should be considered. It is much easier however, to program a human being to recognize equal mirror-type images, modulo 90° turns, long bridge bonds, and such, and how to reject much of the file at a single glance. Unfortunately in this case, the computer cannot react as a human being.
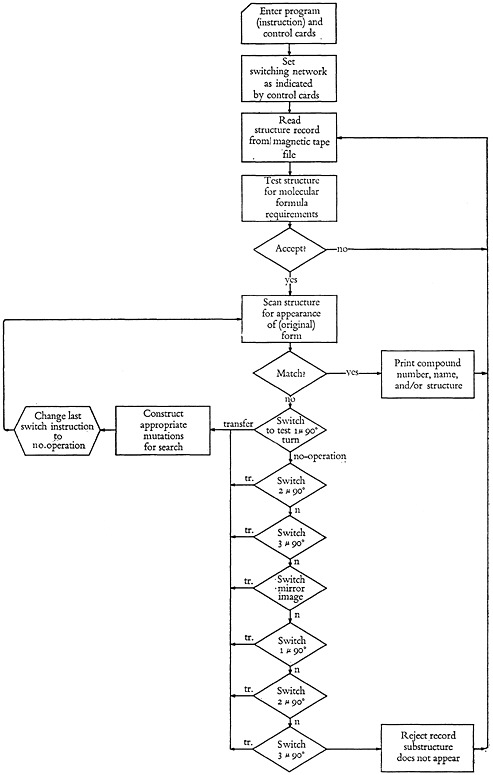
Outline of the search program
The program deck, containing all the instructions necessary to perform any type of search, is entered into the computer with control cards necessary to perform the specific search.
We have available for high-speed scanning the molecular formula file, which is part of the structure record. As each structure is considered, the molecular formula is compared with the “molecular formula” of the substructure or moiety sought. If the substructure contains strange elements, the structure being compared is rejected by the machine. Furthermore, if the search requirements demand a greater number of any given element than is presented in the particular stored structure, it will be rejected by the computer.
If the desired molecular values are available in structure, then the detailed search begins. With the aid of the control cards entered with the search pro-
gram, the computer gets its ideas as to whether certain mutations of the substructure desired should be considered. It is a waste of time for the computer to re-search the structures for a 180° turn if this is identical to the input substructure. If the substructure desired is a ring of carbons connected by single bonds, such as
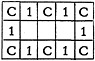
the mirror image of the structure, as well as the second 90° turn, is identical with the original form. It will be necessary to search for the first 90° turn, since it takes on the form
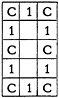
The third 90° turn need not be tested as it is identical with the first.
Depending on the nature of the search question, and control information given the computer, the search continues until a match is found, or until the whole structure has been scanned, no equality found, and the structure rejected.
Figure 3 is the basic flow of the manner in which the 702 attempts to find what it wants.
Retrieving
In addition to the structures, the names and certain laboratory test results of many thousands of compounds have been stored in our system. The method of retrieval must be sufficiently variable to make optimum use of this large mass of data and its versatile availability. The data are stored in three different “files,” name file, structure file, and results file. Physically these files are reels of tapes. Retrieving this information for use is, of course, dependent upon the search question. However, there is a variety of output techniques available, not only because of the versatile 702 hardware, but also, because of the flexibility built into the manner in which these files have been stored. The versatile 702 permits output in the form of punch cards, tape, or paper printed by a high-speed printer. The printer can give a single copy, multiple carbon copies, or paper mats for offset printing. The data may appear in any of these forms
from merely a list of compound identification numbers to relatively sophisticated research reports.
The computer uses the compound serial number as its primary identification tag. Once the computer is aware of the serial number of the compound it is seeking, it can then be instructed to print out either a Chemical Abstract’s systematic name, its structure, or any or all of the test results stored.
Because of the limited number of different characters available on the printer, certain conventions had to be adopted for the complex organic nomenclature involved. Thus all Greek letters, o, p, m, s, n, etc., had to be written out in their English equivalents as: alpha, ortho, etc. Similarly subscripts and superscripts appeared as, super-2, and sub-4. Parentheses, also unavailable, appear in our names as #.
Some names of complex compounds are too long to be printed on one line, so that some ingenious programming was necessary to hyphenate these names.
Retrieving the structures in a printed form is a relatively obvious step. Since the computer knows the number of rows in each structure, the number of characters in each row, and a punctuation mark signalling the end of each row, the computer is simply instructed to pick up each row and print it in the proper sequence on the page. In this manner the structure is regenerated identically with the input. It has taken surprisingly little practice for chemists to be able to identify these computer-printed structures with the same ease as any chemist does with the classical structures. Our Monsanto chemists have assured us that they have found the computer-printed structures very easy to interpret, and they feel that the price of changing the conventions from the classical to the computer-printed form is a small price to pay for the ability to make generic searches among thousands of compounds and to have the resulting structures immediately available for study.
In accord with our stated policy at Monsanto of making this research work in documentation pay for itself in each step along the way, we have been successful in using the computer to write one-page laboratory reports from data supplied to the keypunch operators from the laboratory notebooks of several scientists evaluating uses for compounds as they are synthesized.
Printing these reports requires the name file, structure file, and test results file to be fed to the computer in accord with the appropriate program. The output is a single sheet of paper showing the serial number of the compound being studied, its name, structure, all the raw data recorded, and a brief evaluation. Further details of the use of our 702 for routine report writing are given in the paper “Routine Report Writing by Computer,” by W.H.Waldo, R.S.Gordon, and J.D.Porter (S).
Preparing final report tables
After building a considerable file of the names and structures of organic chemicals, spending over a year storing application-test data for computer use, and with the experience of writing the simplest forms of reports of application testing, we found ourselves in a position to make further use of these data.
In the writing of classical reports, data are frequently recopied for progress reports, memoranda, interim reports, special reports, process reports, and final reports. To be able to record these data once and employ a machine to do the recopying is music to the ears of an industrial chemist. From the documentalist’s standpoint such an idea suggests the Utopia where several reports by cooperating research groups confirm rather than contradict because all the data come from the same set of punched cards accurately reproduced by a machine. However, probably the most important advantage in making repetitive use of test data stored on punched cards is the potential of releasing thousands of man-hours of highly skilled scientific personnel from the drudgery part of report writing, that of copying reams of data over again.
We have called the requests to regenerate stored data for the second, third, or more times, “bonus questions.” It is in this area that savings from machine documentation really pay off.
We have conducted an ever increasing number of searches in answer to these “bonus questions.” Twice so far we have searched the same set of molecular formulas for remarkably similar requests from two different departments of the company for two entirely unrelated reasons.
The first search of this type, because of our inexperience, took about twenty minutes of computer time; the second less than ten. The whole operation from receipt of request to mailing of the reply took less than half a day.
The intriguing part of the molecular-formula file is that it may be searched for any combination of elements in any order. It has been suggested that if Chemical Abstracts were to store their molecular-formula indices in this way, they would be able to print all possible variations in book form by offset duplication at a price that all of us would gladly subscribe to or could easily afford. Such a book would permit many generic searches to be made by hand through clever processes of elimination. For example, if one searched the file for all compounds having two or more nitrogen atoms he would get all the diazo compounds in one handy stack. It is true, of course, that azides, diamines, triamines, etc., would also appear. But the file to be hand-searched would require amazingly less time than to go through the Chemical Abstracts Index in its present form for polynitrogen compounds.
The most frequent bonus question, at this stage in our work, has come from the testing laboratories. They have asked for their test results to be searched by electronic equipment to produce lists for them, just lists; they have asked for lists of numbers and names of compounds that were tested under conditions B, but not C; lists of compounds that showed activity of some nature A without having been analyzed in test D; lists of names of all the compounds for the past five years that have had X and Y test results in common. The requests are just beginning to come in as the men are becoming aware of how this electronic equipment can save them days and even weeks of plowing through old records to dig up information that belongs in reports. These men are especially thankful because it saves them time, drudgery, and, most important, the chance of human error is drastically reduced.
A program is now being prepared and tested to produce an even more valuable set of tables. This program will answer a further bonus question. The question was to examine all the data for a given test during 1957 and perform a minor calculation on every piece of data recorded in this test and then prepare a table of compound number and name with these calculated results on an offset master properly paginated so that the sheets, when duplicated, can simply be punched and inserted into the scientist’s final report.
Of course we are not replacing the thinking mind of the scientist with an electronic and mechanical machine. It will be a long time, if ever, before any scientist is relieved of the responsibility for defining his research program and listing his objectives in the introduction of his reports. And if it ever becomes possible for a piece of hardware to replace the scientist in drawing conclusions from the results of experimentation, science will indeed have lost its luster. The computer simply prepares the tables of data in novel and interesting fashion so that the scientist has more time to be creative, analytical, and to think.
By the time this paper is being discussed at the International Conference on Scientific Information some searches will have been made for the most difficult and far reaching bonus question we have asked of our system. We will be able to say how successful we were in making generic searches from a file of organic structures.
The question at present is not whether it is possible for us to perform such a search, but rather how long did it take us, what statistics have we found, and how has it helped Monsanto’s research effort.
Limitations
This paper is not describing a perfect system of chemical documentation by machine. In the first place our files are small compared with the files of Chemical
Abstracts. We have something under twenty thousand compounds stored, a mere sample of the compounds in Beilstein. To say that the problem of scale-up to encompass the world’s knowledge of organic chemistry is simply a matter of dollars is wishful thinking to the realist.
Although we have been able to “teach” the computer a great many facts about chemistry, both of structure and of application, we have made no attempt as yet to teach it chemical reactions or to teach it chemical properties, although we are certain that these things can be done.
Probably the greatest limitation of all in this work is that of personnel. We would all like to make use of this and other systems. If only someone would collect all the data in science and store it properly for us to use, but two things are lacking. There are few people with the proper training who wish to spend their lifetime feeding information to a computer as a mother does her child.
Furthermore, there is the problem of economics. It will take a huge investment to store all of chemistry, but the most glamorous and profitable rewards will not be available until the storage job is up to date.
A final limitation to such a system is a subtle one. There is almost no redundancy in our system. The chances of finding erroneous data stored by accident through the human error of recording or punching or through the very infrequent machine error is entirely left to chance. We have found these errors by tedious proofreading of the output, but this can only be done on a small scale. We have found an occasional error by chance, where someone recognizes that a piece of output data is not as he recalls it should be. How serious this limitation is, only time can tell.
Conclusions and recommendations
This paper has described a total documentation system from the generation of the data at the laboratory bench to retrospective searching. The system is barely in operation, and there is much work yet to be done. Our work, so far, has convinced us that our design premises were desirable, practicable, and attainable. A chemist makes a compound, writes its structure and gives it a name. Information about this compound is processed by clerks for storage in the large-scale computer. Application scientists test this compound and they record their results in their notebook. These results are processed by clerks and stored for the computer. Individual, one-page reports are prepared for distribution automatically by the machine.
Periodic summaries of the stored data are made routinely. Special searches are prepared on demand within a few hours time. These searches may include the selection of any class of compounds definable by structural means. Re-
arrangement or further calculations of the data stored and the automatic comparison of millions of “bits” of information for correlation and leads for further scientific research can be made simply. Finally, generic searches of our file of chemical structures can be made and the proper structures regenerated and printed for further use by our chemists for study or report writing. We seem to be on the threshold of new techniques in the conduct of research and development work. The national problem of the shortage of scientists has given rise to the invention of this and other documentation systems designed to relieve the scientists from many of the chores that historically were the price we had to pay for the privilege of studying nature.
The job is not done. In the tradition of science it is the intention of the authors of this paper through its presentation to invite criticism, comments, comparisons, and improvements during or after this conference.
There may be other applications of the topological method we have employed here for the storage of chemical structures. It seems to us to be applicable to any series of simple systematic diagrams, such as electric circuits, or the diagrams used in architecture, anatomy, botany, and geology.
ACKNOWLEDGMENT
The authors wish to express their appreciation to a number of the members of the Monsanto organization who have contributed materially to the current program. J.D.Porter and R.S.Gordon did much of the early programming and planning. Many of the problems associated with such a radical change in documentation were solved by William Massey, Leon Cooper, and Jill Joyce. The cooperation of the technical staff of the Monsanto Research Departments in Dayton, Ohio, Nitro, West Virginia, and St. Louis, Missouri, is also gratefully acknowledged.
REFERENCES
1. FREAR, D.E.H., Chem. Eng. News, 23, 2077 (1945).
2. FREAR, D.E.H., Chem. Eng. News, 33, 2838 (1955).
3. OPLER, A., and NORTON, T.R., Chem. Eng. News, 34, 2812 (1956).
4. RAY, L.C., and KIRSCH, R.A., Science, 126, 814 (1957).
5. WALDO, W.H., GORDON, R.S., and PORTER, J.D., Am. Document., 9 [1], 28–31 (1958).




















