
Linguistic Transformations for Information Retrieval
Z.S.HARRIS
ABSTRACT. This paper discusses the application to information retrieval of a particular relation in linguistic structure, called transformations.1 The method makes possible the reduction of a text, in particular scientific texts, to a sequence of kernel sentences, which is roughly equivalent in information to the original text. It seems possible to determine the division into kernels in such a way that each kernel will carry about as much information as is likely to be called for independently of the neighboring information in the article. A text may therefore be stored in this form (perhaps omitting, by means of formal criteria, any sections which are unnecessary for retrieval), and its individual kernels may be retrieved separately. Since the carrying out of transformations depends only on the positions of words in a sentence, and not on knowledge of meanings, it seems possible that at least part of this operation can be performed by machine; the more so since the method does not require any judgment about the subject matter, or any coding of the concepts of a particular science.
1. Language structure
Methods such as are presented here are possible because language can be objectively studied as a part of nature, and it is then found to have an explicitly stateable formal structure. It can be objectively studied if one considers speech and writing not as an expression of the speaker which has particular, introspectively recognized, meanings to the hearer; but rather as a set of events—sound waves or ink marks—which may be said, if we wish, to serve as tool or
Z.S.HARRIS Department of Linguistics, University of Pennsylvania, Philadelphia, Pennsylvania.
vehicle for communication and expression. This set of events, the many occurrences of speaking and of writing, can be described in terms of a structural model. We can say that each such occurrence is composed of parts (mostly successive in time), and that these parts (words, or word parts, or sounds) are collected into various classes, e.g., the class of words N (noun). These classes are defined not by meaning but by the position of the words relative to each other. Any property of language which is stated only in terms of the relative occurrence of physically describable parts is called “formal.”
Each language is found to have a formal structure, and the structures of various languages are similar to each other in various respects. In each language we find that we can set up and classify elements called “morphemes” (word parts, such as prefixes, or indecomposable words) in such a way that the various classes of these morphemes occur (in speech and writing) in a regular way relative to each other. The domain of this regularity is called a sentence. We can identify a few sequences of morpheme classes (and sequences of sequences), and show that every sentence is one or another of these sequences, but this only with the aid of recursive formulations.
In this way, the structure of language can be shown to have algebraic properties. This may seem strange to those who expect language to be irregular or full of exceptions. It is true that there are a great many special details if we try to approach anything like a complete description of a language. And it is true that each word has its own particular range of other words with which it occurs in a sentence; for example, a given noun occurs before certain verbs and not others. Nevertheless, the sequence of word classes that constitutes a sentence is definite for a given language, and even the fact that every word has a unique range of other words with which it occurs turns out to provide a basis for regularities in the language structure, as will be seen in 1.1.2
1.1. TRANSFORMATIONS
For our present purposes, the only structural feature we have to consider is transformations, and as much of language structure as is required in order to operate with these. We begin by defining a construction as a sequence of n word or morpheme classes in terms of which a sentence or another construction is structurally described. For example, AN (as in charged atom) is a two-class sequence, and TN Ving N (as in the atoms emitting electrons) is a three-class
sequence (neglecting the T), both of which constitute a construction “noun phrase” which we may write N′3. N is A (as in Power is evil.) and NV (as in justice sleeps.) are two-class sequences, and NVN (as in Denaturation affects rotations.) or N is V en by N (as in Results were recorded by observers.) are three-class sequences, all of which constitute sentences.4
A construction is satisfied for certain particular members of its n classes if the sequence of those n words (those members of its n classes) actually occur as a case of that construction. For example, AN is satisfied for the pairs (charged, atom), (clean, room), (large, room) and a great many others. T N Ving N is satisfied for the triples (atom, emit, electron), (atom, contain, electron), (molecule, emit, electron), (worker, work, overtime) and a great many others. It might seem that not much can be done with this: the satisfaction list for each construction is very large; and it is impossible to say that one or another n-tuple does not satisfy the construction. Thus we cannot say that the noun phrases charged room or atoms evicting overtime, would not occur somewhere. We can only say that in some sample of the language the pair (charged, room) did not occur in the construction AN, or that even in a very large sample the triple (atom, evict, overtime) did not occur as a sentence construction. Nevertheless, we can obtain a useful result by considering (for a given sample of the language) not the absolute lists of n-tuples that satisfy a given construction, but the similarities among the lists that satisfy different constructions.
If two constructions R, S which contain the same n word classes (with possibly additional individual morphemes, e.g., AN and N is A) are each satisfied for the same list of n-tuples of members of these classes, we call the two constructions transforms of each other:5 R↔S. If the satisfaction list for R is a proper subset of the satisfaction list for S, we say that R transforms one-directionally into S: R→S. For example AN→N is A: every pair satisfying AN can also be obtained in N is A (The atom is charged, etc.), but there are certain subtypes of A which occur in the latter but not the former. Similarly T N1 Ving
N2↔N1VN2 (the subscripts distinguish the different occurrences or members of classes): every triple found in one construction can also be found in the other (compare the examples above with The atoms emit electrons; Denaturation affecting rotations…). And N1VN2↔N2 is V en by N1 as in Electrons are emitted by the atoms; Rotations are affected by denaturation. But ![]() : both may be satisfied for the ordered triple (nature, imitate, art), if we have Nature imitates art and Art imitates nature; but we are likely to find the ordered triple (atom, emit, electron) only in the first (not finding the sentence Electrons emit atoms). Another example: The sentence construction N1, N2, V (e.g., The tapestry, a masterpiece, faded.) is not a transform of N1VN2 (we don’t find The tapestry faded a masterpiece), but it is a transform of the sentence sequence N1V. N1 is N2 (as in The tapestry faded. The tapestry is a masterpiece.).
: both may be satisfied for the ordered triple (nature, imitate, art), if we have Nature imitates art and Art imitates nature; but we are likely to find the ordered triple (atom, emit, electron) only in the first (not finding the sentence Electrons emit atoms). Another example: The sentence construction N1, N2, V (e.g., The tapestry, a masterpiece, faded.) is not a transform of N1VN2 (we don’t find The tapestry faded a masterpiece), but it is a transform of the sentence sequence N1V. N1 is N2 (as in The tapestry faded. The tapestry is a masterpiece.).
1.2. KERNELS
We thus see that many sentence constructions are transforms of other sentence constructions, or of sequences of these, or include subconstructions (such as noun phrases) which are transforms of some sentence construction. Transformation is an equivalence relation among constructions (in particular, sentences) in respect to their satisfaction lists.6 The transformations thus provide a partition of the set of sentences. Furthermore, it is possible to find a simple algebra of transformations by showing that some transformations are products of others (base transformations): for example, TN2 being Ven by N1 and N1VN2 meet the conditions for being transforms of each other (The electrons being omitted by atoms and Atoms emit electrons.); but we can say that this is the product of two transformations which have been mentioned above; N1VN2↔ N2 is Ven by N1 (yielding Electrons are emitted by atoms.) and N1V N2↔T N1 Ving N2 (where the new V is is, and the original Ven by is carried after is as a constant of the transformation; i.e., is emitted by↔being emitted by).
Every sentence structure is the product of one or more (base) transformations of some other sentence structure, or the sum of products of transformations (if its parts are themselves transforms of sentences); if it is not, we say it is the identity transform of itself. If we can suitably mark homonymities, we obtain that every sentence structure is a unique sum of products of transformations. The set of transformations is then a quotient set of the set of sentences, and under the natural mapping of the set of sentences onto the set of transformations, those sentences which are carried into the identity transformation are the kernel of the set of sentences.
In English, these kernel sentences have a few simple structures, chiefly NV and NVPN, NVN and NVNPN, N is N, N is A, N is PN. Every sentence, therefore, can be reduced by transformation to one or more of these; and combinations of transformations of these generate every sentence. The complex variety of the unbounded number of English sentences can therefore be described in terms of a small number of kernel structures, a small number of base transformations with their algebra,7 and a small number of recursive rules for sentence combination and a dictionary.
2. Application to information retrieval
The possibility of applying transformations to information retrieval rests on the fact that, by standards of information or meaning which are of interest to science, a sentence carries the same information as does its transform (after allowing for the differences inherent in the particular transformation, such as being a sentence or being a noun phrase). This is not the case, for instance, for belles-lettres or poetry, or for material where association or the use made of the language vehicle is itself a relevant part of the expression or communication. For scientific, factual, and logical material, however, it seems that the relevant information is held constant under transformation, or is varied in a way that depends explicitly on the transformation used. This means that a sentence, or a text, transformed into a sequence of kernels carries approximately the same information as did the original.8 It is for this reason that a problem like information retrieval, which deals with content, can be treated with formal methods—precisely because they simplify linguistic form while leaving content approximately constant.
The usefulness of transformation to information retrieval is due in part to the fact that scientific report and discussion does not utilize all the structure which is made available by language, such as the differences between transforms of the same kernel, the various verbs and affixes which are roughly synonymous with respect to science, and so on. There is an extra redundancy in language when used in science, and the removal of some of this redundancy, by establishing what distinctions are not utilized, would make possible a more com-
pact and more lucidly organized storage of the content of scientific writing. This is not the same as a reduction of English sentences to their logical equivalents. The tools of logic are not sufficient for a representation of the statements and problems of science.
Transformations make it possible to store a text as a sequence of kernels. One might ask what advantage there is in this as against merely storing the text in original form. If a searcher asks for anything which interrelates two words a, b, the fact that a, b both occur in the same sentence does not guarantee that there is a relation between them; and a, b may be related while occurring in two neighboring sentences (e.g., if there are certain connectives between the sentences). Hence, either he must be given the whole article, or he will miss some relevant sentences and get some irrelevant ones. In contrast, kernels and their connectors specify the relation among words. Hence it is possible to extract, from a storage containing many articles, precisely those kernels or kernel sequences in which a, b are related (or related in a particular way). It thus seems possible both to store a whole article (transformed), to be called out as such, and also to draw upon it, if desired, for individual kernels separately. Problems attendant upon this are discussed in Section 3.
Once a text has been organized grammatically into a sequence of kernels, a further operation of reduction becomes possible. It is possible to compare corresponding sections of various kernels, and on this basis first to eliminate repetition, and secondly to separate out to some extent the sentences that have different status in respect to retrieval; e.g., sentences which are not worth storing, or sentences which should be stored but not indexed, and perhaps even those which should be used as an abstract of the article. The basis for this is discussed in Section 4.
The methods discussed here do not require the exercise of any knowledge of the subject matter of the article, nor do they require any coding of the relevant concepts of each science.
3. Informational kernels
The kernels that are obtained from transformational analysis are determined by the set of transformations that can be found in the given language. It was found that reduction of texts to kernels yielded stretches too small for efficient retrieval. Consider, for example, the sentence:
The optical rotatory power of proteins is very sensitive to the experimental conditions under which it is measured, particularly the wavelength of light which is used.
Transformed down to kernels, this becomes;

We would like to obtain larger kernels, preferably of the size and structure that would provide separate kernels for the separate requests of information search. Larger kernels can be obtained simply by omitting some of the transformations, for each omission of a transformation would leave some section or distinction intact. If we can find that certain transformations are responsible for separating out (into different kernels) items that we would like to keep together, we would omit these transformations, and the regular application of the remaining transformations would give us kernels closer to the size and type we want.
This result can be to a large extent obtained by omitting the transformations that separate adjuncts from their centers.10 As we apply one transformation after another to reduce a sentence (all those which are applicable to that sentence), we reach a stage in which the reduced component sentences have the structure of kernels indicated above (end of Section 1.2) except that the AT and V have various adjunct phrases (A, PN, etc.) associated with them; e.g., The rotatory properties of proteins depend on wavelength (reduced from the example in Section 5). The next applicable transformations here would break this up into:

Here the rotatory properties of proteins is a noun phrase, with properties as center and of proteins and rotatory as two adjuncts. If for information retrieval purposes we omit these adjunct-extracting transformations, we obtain larger kernels that are closer to retrieval needs.
However, this overshoots the mark, because some phrases which are grammatically adjuncts may be of independent informational interest. It turns out that many of these are phrases which contain the same words as appear in center positions in neighboring kernels. It is therefore useful to introduce a second type of operation, over and above the transformations. This is to compare the words in every long adjunct with the neighboring center words. The result provides a criterion for further transformation. If the adjunct contains (perhaps two or more) words which are centers in other kernels, that adjunct in transformed into a separate kernel; otherwise it is not.
4. Retrieval status of kernels
The operation of comparison introduced in the preceding paragraph is not hard to carry out once we have kernels, each with its two or three centers and their adjuncts. This same operation, once it is introduced, can be put to wider use in deciding how to treat various kernels.
The various sentences of an article differ in informational status, and even certain sentences which may be of interest to readers of the article may not be requested or useful in retrievals. The distinction is sharper in the case of kernels, because transformations usually separate out what we might consider side remarks, comments about methodology or prior science of the article, and so on, from the kernels that carry the central material of the article. This happens because in many cases the different types of material necessarily occupy different grammatical subsections of the original sentence.
If we now compare the centers of the various kernels, we find that the sections which carry the main material of the article are generally characterized by having certain words occur over and over in various relations to each other. These are the kernels from which the abstract should be selected. The kernels of this type are usually also the ones which are likely to be separately useful in answer to search, so that these kernels should be indexed.
Adjoining these kernels are sections which are adjuncts of them or separate kernels connected to them, and which in many cases contain at most one of the words which are centers of the main kernels. These sections often report conditions, detailed operations, and the like, which apply to the main kernel. This material is not needed in the abstract, and in most cases only its most repeated centers would be wanted in an index for retrieval.
There are also metadiscourse kernels which talk about the main material (e.g., discussing the problems of the investigators). These contain words entirely different from those of the main kernels, except that they often contain one word from a main kernel or a pronoun referring to a main kernel. Such
kernels may be omitted from storage except in cases where they are retained as modifiers of a main kernel. In any case they need not be indexed.
Finally, there are in many cases kernels which have a vocabulary of their own, not as repetitively interrelated as the vocabulary of the main kernels. These are often comments about the underlying science of the article, including general methodology; in most cases they need not be stored for retrieval purposes.
This characterization of informational statuses is tentative and rough, but the relevant fact is that properties of the type mentioned in each case can be recognized by means of the comparison operation introduced above. To the extent that there is a correlation between the types of word recurrence and the informational status of kernels, it will be possible to set up the comparison operation in such a way as to make the desired distinctions and thus to determine which kernels are to be stored, which of these are to be indexed, and which abstracted. A great deal of investigation is still required here.
5. Stored texts
The operations indicated above transform a text into a sequence of kernels with standard structure. A convenient way of providing for further operations on the kernels (whether retrieval or further analysis) is to mark off the main internal structures of each kernel, since these will have already been established in the course of applying transformations. Each kernel can be divided into at most five sections:
|
0. |
Connectors (binary operators) to other kernels (e.g., or, because, however, if…. then); unary operators on the kernel (e.g., not, perhaps, surprisingly enough). |
|
1. |
Subject noun phrase: center N and its adjuncts. |
|
2. |
Verb phrase, including its adjunct D and PN (preposition plus noun phrase). |
|
3. |
Post-verb (“object”) N or A or PN phrase: center and its adjuncts. |
|
4. |
Adjuncts of the kernel as a whole (usually PN or connected sentence). |
There are various problems in determining this analysis of each kernel as it is produced by transformations from the original sentence, though in most cases the original sentence structure determines the analysis readily. Nor is this the only way in which kernel structure can be arranged. Of the above sections, 0 and 4 (and perhaps 3) may be empty in a given kernel.
The various kernels in an article, or in a neighborhood within the article, can be compared in order to discover repetitions. If the words of section n of
kernel m (written m.n) are identical with the words of section p of kernel q, or if m.n contains a grammatical pronoun of q.p, then in position m.n we merely record the address of q.p instead of repeating the words. If only part of a section is repeated this can be indicated by marking this part (as a subdivisional address) and recording the specific address at the point of repetition. If the repetition is of the corresponding sections 1, 2, or 3 in the preceding kernel (the most frequent situation), we may simply leave the repeating position empty. For example,
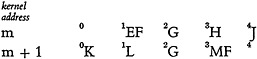
would be recorded:
Articles contain so many repetitions as to make this useful. Similarly, if one kernel contains a whole kernel (or a pronoun of it) within it, we record the address of the repeated kernel in the position which includes it. However, if as often happens the containing kernel is of a metadiscourse type (e.g., We have found that…) it would be recorded (in full or in summary form) in the 0 section of the kernel which it contained, or else omitted altogether. As an example, we take a sentence drawn from the same text as the previous examples:
One phase of this research, the dependence of the rotatory properties of
N1 N2
proteins on wavelength, is recorded here because it is of special importance
V3 C N1V4
to the problem at hand.
The centers of the noun and verb phrases are marked by Ni, Vj.
The structure of the sentence in terms of these phrases is:
N1, N2, V3 C N1V4
Three transformations are applicable here, first separating out the sentence structures, then transforming the constructions within a sentence structure:
1. S123 C S14↔S123. C S14.
2. N1, N2, V3↔N1 is N2.N1 V3.
(S123 indicates the sentence containing the words marked 1, 2, 3.)
Comparison shows that the words of N2 recur as centers of other kernels;
therefore N2 is transformed into a sentence in order to be recorded as a separate kernel:
The dependence of the rotatory properties of proteins on wavelength
V5n of N6 P7 N8
3. V5n of N6P7N8↔N6V5P7N8.
If these three transformations are applied and the section markers are indicated, we obtain:
-
0 1 One phase of this research 2 is 3 2
-
0 1 The rotatory properties 2 of proteins depend on 3 wavelength
-
0 11.1 2 is recorded here
-
0 because 1 2 is of special importance to the problem at hand
Comparison shows that the words of kernels 1, 3, 4 do not recur in the article; these kernels would not be marked for indexing, and it is most likely that further investigation of their word subclasses would lead to their rejection from storage. On this basis also kernel 1 would be replaced by having the words one phase of this research is placed in section 0 of kernel 2.
Various modifications and empirically tested criteria can be added to these operations. For example, if the title consists of N1 plus adjunct X (or if the first sentence of a paragraph contains such N1X) then all occurrences of the N1 in the article (or paragraph) can be credited with a repetition of X, i.e., the N1= N1X. If further investigation specifies the situation in which words like condition, property have the status of pronouns, i.e., in which they constitute repetitions of something previously stated, then these words could, like pronouns, be replaced by the words they repeat (or rather, by the addresses of those words). If a list of synonyms can be established for various relational verbs, classificatory nouns, and the like, it would be possible to consider each of those words a repetition of any of its synonyms. On this basis, for example, kernel 2 above turns out to be entirely a repetition of other kernels in the same article, and can therefore be omitted. Such a synonym list goes part way toward indicating logical equivalence between sentences, but only in the direction and to the extent that scientific writing actually permits.
When there is a connector between two kernels, each time one of the kernels is retrieved, the connected one will be picked up also (except that a kernel may not have to pick up those which are subordinate to it). If the connector at p refers to a kernel m which is not contiguous, the address of m would be added to the connector at p. The instructions for this arrangement, as for the others mentioned above (such as the section division of kernels) could be obtained as a by-product in the course of carrying out transformations.
In the kernels which are marked for indexing, a suitable criterion can be set up; for example, all words may be indexed except those in a stated list (the, some, etc.), or we might index only the center words and the words which are centers of the adjuncts. If someone searches for kernels that connect two words (or their synonyms), the index will yield two long lists of addresses; addresses occurring in both lists give the desired kernels. There are certain strong connectors such that a word occurring in one of the connected kernels may have an important relation to a word in the other (though this is not the case for other connectors or for unconnected kernels). Kernel sequences with such connectors will receive only a single address, so that if a person asks for two words, the index will find the same address under each of them, even if they are in different but strongly connected kernels.
6. Machine application
The nature of the operations which have been described above is such that they may in principle be performable by machine; in particular, they have been based on the position which words occupy, not on meanings. This is, of course, quite different from discovering the structure of a language, which is also based only on the relative occurrence of physical entities, but is not reducible to such simple formulation. The general question about machine performance of these operations hinges on whether a decision procedure can always be found for the requisite work, and on whether it would be sufficiently short in all cases.
Much of the analysis of language structure is based upon comparison of the positions of a great many words in a great many sentences. This would take too long on a machine. However, the results of this analysis can be built into the machine. For example, there can be a dictionary which gives the class membership of each word, or, where a word is a member of more than one class, determines the class membership on the basis of the class membership of neighboring words. And there can be a list of transformations, each stated in terms of a particular class sequence; if a transformation depends upon particular members of a class this would be indicated under those members in the dictionary. Nevertheless, there may remain various distinctions which are necessary in order to determine the applicable transformation but which cannot be recognized by the machine in terms of the material immediately available to it. The most obvious case is that of homonymities, where no formal division is possible because two different transformational products have the same physical shape.11
In other cases, an analysis (or a choice between two analyses) is decidable, but on the basis of such a network of subclass relations as a human being can keep in mind but is beyond the storage and time capacities of machine use. In such cases it may be necessary to pre-edit the text, that is to insert at certain points in the text marks which the machine would use in deciding what transformation to use. This editing would require only a practical knowledge of the language, not any special knowledge of the subject matter.
The possibilities then are about as follows. The original text is first read into the machine (perhaps by a print reader, if one can be developed at least for selected fonts in which the major journals are printed). If any pre-editing marks are needed, they would be included in the text; word space, punctuation marks, and paragraph space will of course be noted. The machine then works on a sentence at a time, getting from its dictionary the class and special transformations of each word in the sentence. The representation of the sentence as a sequence of classes (with occasional markers for special transformations) constitutes, with the aid of a stored program for separating out the main phrases, the instructions for carrying out the transformations. (This is not done by a simple left-to-right reading of the marks.) These transformations produce from the original sentence a sequence of tentative kernels, each with its connectors and main grammatical sections marked.
At each paragraph division the machine would institute the comparison operation over the kernels of that paragraph (and perhaps with a check of the main kernels of the preceding paragraph). First, the main words of each long adjunct would be compared with the centers of the various kernels, to see if the adjunct should be transformed into a kernel. The words of each section of each kernel would then be compared in order to replace repetition by kernel-and-section addresses. This would have to be done over stretches longer than one paragraph. Here as elsewhere various simplifications are possible. For example, it might be sufficient to compare the various sections 1 with each other and with the sections 3. There would be few repetitions between these sections and section 0 or 2. Also, the machine might stop this comparison operation if it has gone through say a paragraph plus two sentences (i.e., into the second paragraph) without finding a repetition to the section it is checking. A table of synonyms could be used to extend what is considered a repetition.
Next, the centers of each kernel would be compared to see which kernels have the same centers in different relations (e.g., with different adjuncts), and other characterizing conditions. The results of this comparison would indicate whether a kernel is to be rejected or transformed into a section (chiefly 0) of an adjoining kernel, or stored, and whether it is to be indexed, and perhaps whether it is to be included in the abstract. The kernels would then be stored,
and their centers or other indicated words would be marked with their address and sent to the index storage.
The whole of this work—linguistic analysis, formulation of the transformations, characterization of informational status, and machine application—is far from done. The remarks presented above indicate only the results at the time of writing.
7. Further possibilities
One advantage in the operations proposed here is that they pave the way for further reduction and organization of scientific texts. Discourse analysis would be a step in this direction; transformations are a preliminary to it, while the comparison operation may be considered the first operation of discourse analysis. If further steps become mechanizable in a reasonable way, it would then be possible to carry out further comparisons and reductions on the stored standardized kernels of the text.
More important, as a by-product of analyzing and storing a great many texts it may be possible to collect experience toward a critique of scientific writing and an indication of useful modifications in language and in discourse structure for scientific writing. Science uses more than logic or mathematics but less than language; and in some respects it uses formulations for which language is not very adequate. However, since scientific communication operates via language (except for mathematical expressions, graphs, and illustrations), detailed investigation of how the language is used gives us some picture of what would be a more useful quasi-linguistic system for science.














