
The Descriptive Continuum: A “Generalized” Theory of Indexing
FREDERICK JONKER
ABSTRACT. This article first notes the importance of the indexing problem in mechanized information retrieval: not only is the degree to which information can be retrieved entirely determined by the adequacy of the system of indexing, but the total cost of the mechanized information control system is to a large extent likewise determined by the indexing system.
In view of this overriding importance of indexing systems, the paper points out the desirability of general criteria common to all indexing systems, which can be applied to any possible indexing system in evaluating its suitability to a particular information control problem.
In an attempt to find such criteria common to all indexing systems, and establish a “generalized theory” of indexing, the history of information control is traced from the earliest classification systems through subject heading systems to the latest developments such as Uniterm indexing.
The various causes underlying the evolution of the art are likewise analyzed. In the light of this analysis the basic cause of an information retrieval problem and the degree of severity of the problem lie in the degree of diffuseness of information. Diffuseness is the degree to which required information is contained within other, only indirectly related, information items and subjects. The greater the degree of diffuseness, or unrelatedness, the more severe is the problem of information control.
In the historical analysis it is shown that the increasing diffuseness of information forced the art away from classification systems to subject heading systems, and from these to simple keyword indexing. It is shown that there is a gradual transition from one system to the other and that no sharply delineated basic differences exist between any of these systems.
The generalized theory of indexing postulated in this article therefore looks upon all indexing systems as a continuum, the descriptive continuum. The main parameter of this continuum is the average length of the “entries” or “headings” used. At one end of the continuum or “spectrum” is keyword indexing; subject heading indexing is somewhere in the middle, while hierarchic classifications are at the other extreme. The average length of the
FREDERICK JONKER Documentation, Incorporated, Washington, D.C.
The work reported here was done under the sponsorship of the Directorate of Advanced Studies, Air Force Office of Scientific Research, Contract No. AF 49(638) 91.
headings or descriptive terms used determines the position in the continuum.
Throughout the continuum, all other parameters behave as functions of the average term-length. Some of these parameters are:
Potential depth of indexing
Permutability of indexing criteria
Degree of hierarchial definition of indexing
Potential need for a coordinating mechanism
Retrieval noise
Size of the access apparatus
False coordinations
Capacity for handling semantic indeterminacy
These parameters are discussed and explained. They are believed to contain all the considerations basic to the indexing problem.
The theory indicates that once the main parameter, average term length, is determined, all other properties of the indexing system are fixed. For every information collection there is an “optimum” position in the continuum, according to which the collection should be organized. This optimum position is determined by the diffuseness of the information in that particular field.
In any mechanized system of information storage and retrieval there are three distinctly separate problems:
-
The indexing problem. The problem of assigning to a certain item of information a number of “terms” characterizing this item of information. The word “term” is used here in its broadest sense and comprises any form of “class,” “subclass,” “subject heading,” single words or combinations of words. The indexing problem is common to manual as well as mechanized information control systems. In non-mechanized information control systems the following two problems do not enter.
-
The coding problem. The problem of converting terms into a code so that they can be stored in a machine.
-
The machine systems problem. The problem of selecting a machine system which can store and manipulate the coded information.
This paper is concerned with indexing. The determination of the particular form of coding and machine system which will best suit the requirements of any particular problem at hand is basically a matter of engineering expediency. Ultimately it reduces to problems of cost. Almost any compatible combination of coding and machine system can in principle perform any required form of information search. However, some machines may be better suited to a particular information control problem than others. The “best” system is simply that with the lowest total cost for the required information entry and search operations.
All problems in information storage and retrieval can ultimately be reduced
to one single factor, cost. All “improvements” in this field, and many other fields, basically aim at one thing and that is lowering of the total cost of a system able to meet a certain specified performance.
Mechanization would seem to be the answer to this problem. But in general, the cost of the intellectual work of indexing is roughly on the same order of magnitude as the combined cost of the clerical work of entering the data in a machine and the cost of the information control machine itself. Therefore mechanization can be only a partial answer. The other part to the answer must be found in more economical systems of indexing which provide greater depth of indexing at lower cost. It is this consideration that gives the problem of indexing its tremendous importance.
The various systems of indexing in use today confront us with a picture of conflicting claims. Rather than single out and discuss their differences, we will here attempt the opposite and look for elements which these apparently conflicting systems have in common and attempt to establish one single “unified” or “general” theory of indexing.
The suspicion that such a general theory must exist seems to find confirmation in the pattern of evolution of many of the sciences, particularly the physical sciences. New fields of science usually start with the observation and measurement of a number of freshly discovered phenomena, which are vaguely felt to be related. As the new science progresses, closer and closer relationships between these phenomena are discovered. Finally a generalized theory and generalized equations become possible. Many sciences which do not lend themselves to mathematical quantification exhibit basically the same pattern of development. The evolution of a science always seems to progress from the understanding of a large number of relationships, each linking a limited number of phenomena to one single relationship relating all observed phenomena.
The inescapable conclusion seems to be that no true understanding of existing indexing systems and problems seems possible, unless all systems can be seen in the light of more general common concepts, linking all these systems together into a single “closed” system.
One fruitful way to investigate the elements in common among the various systems of indexing is to make a brief study of their origin in history, of their evolution in time. Below we attempt to trace not only the actual events but also their underlying causes.
HISTORY AND ANALYSIS OF THE INFORMATION CONTROL PROBLEM
Until a few centuries ago information control problems, as we know them today, were entirely unknown. The totality of recorded knowledge, at the
time of the early book libraries, was still extremely small. Few books were written and each could easily be classified in one or more of the few then recognized sciences and fields of human endeavor.
Although the origin of classification systems goes far back in history, at no time was much significance attached to classifications until the 18th century “enlightenment” brought about a greatly increased knowledge of the physical world. Most of this new knowledge, to a large extent of taxonomic nature, lent itself readily to classification. Cataloging and classifying became at that time one of the most important goals of science. Classification systems gained an enormous importance. The hope that all knowledge necessary for the understanding of the physical world would soon be complete and fit into a “natural” and “universal” classification system became one of the fondest dreams of the age.
The importance of classification systems was not, however, based on considerations of information storage and retrieval. Such problems at that time hardly existed. It was based solely on the urge to see order in knowledge and to organize all knowledge into one “closed” system. Although subsequent developments relegated classification systems to a far less important position, vestiges of the enormous prestige gained at that time persist today.
The industrial revolution created a new body of knowledge entirely different in nature and much larger, by many orders of magnitude, than all preceding knowledge. Moreover the center of gravity of human knowledge shifted from the natural sciences to the field of technological and supporting sciences; to the knowledge of how to build railroads, ships, airplanes, and powerplants; how to cultivate the soil, cure diseases, etc. Not only did the nature and size of our store of knowledge change radically, but the need to consult the store of information rose rapidly.
It was this technological information which for the first time created a problem of information storage and retrieval. Relatively few problems are encountered in “consolidated,” well-organized information like that contained in encyclopedias, handbooks, and textbooks, where information pertaining to a certain subject has been collected from a great many different sources under one single heading. Only when information is scattered through a great many different articles and reports and when each of these “items of information” contains bits of intelligence related to, or of potential importance to a number of different subjects, does an information control problem arise. It is this diffuseness of technological information which causes and defines the information control problem as it faces us today.
Diffuseness of information implies that items of information may be of interest in a great many problems, uses, and fields of pure and applied science.
It implies that these items should be indexed from each viewpoint of potential importance. The diffuseness of an item of information therefore is measured by the number of potential indexing viewpoints or criteria.
By far the greatest proportion of our present store of knowledge which we need to consult constantly and rapidly is of a highly diffuse nature. This high degree of diffuseness is not something accidental. It is inherent in the very nature of our technological civilization, in the fact that every achievement or finding in any particular field may be of enormous potential interest in almost any other field. It is this potential cross-fertilization which is responsible for the rapid acceleration of progress, which, measured by the time scale of history, almost assumes the proportions of an explosion. Here indexing theory touches the mechanism of progress.
The degree of diffuseness of information is the heart of the indexing problem and the main parameter in the generalized theory of indexing. If an information collection is assembled for very special purposes only, the collection need of course not be indexed to its fullest depth, that is, the indexing will cover only a fraction of the full potential implications of the information. Generally, however, it is desired to index so as to encompass the full potential. In that case the “indexing depth” should cover all foreseeable implications. It should equal the diffuseness of the information.
In assembling the large libraries of the last century so as to contain all the new knowledge, the need for a system of information storage and retrieval was immediately felt. The well-established classification concept was of course the first device these libraries turned to. But it was soon discovered that in the new fields of technology and supporting sciences no classification, no matter how elaborate, could satisfy even the most straightforward demands.
To understand the reason for this sudden breakdown of classification systems in their application to technological information, it is necessary to analyze briefly the problem of “class-inclusion” or, more generally, the problem of “subordination.” Although most severely felt in classification systems, it is basic to any form of indexing.
The simplest form of indexing is encountered when an object is indexed according to only one particular criterion or from one particular point of view. In such a case it is frequently possible to set up mutually exclusive classes. Even when no fully mutually exclusive classes are possible, the degree of overlap of these various classes will in general be small, and serious problems are not encountered.
For example, in the Patent Office where the main problem has centered around structural differences and similarities, it has been possible to maintain until today a classification according to mechanical structure. This has not been
accomplished without very serious problems, as even the analysis of mechanical structure is subject to differences of point of view. Mutually exclusive classes exist only to a limited degree.
On the other hand, most of our present information collections consist of highly diffuse information which requires indexing from many viewpoints, such as: design components, design principles, possible uses and applications, materials used, physical principles involved, sciences involved, production methods involved, etc. Each viewpoint requires an entirely different form of subordination. The technological and supporting sciences have a practically unlimited number of index criteria or viewpoints from which they can be indexed. Some of them may seem extremely trivial. But this apparent triviality disappears in the realization that even the most specialized viewpoints often represent billion-dollar industries to which such parochial viewpoints are vital. As the technological evolution progresses, fresh viewpoints constantly emerge, and older viewpoints change their relative importance or disappear.
It has been strongly felt in the past and is still maintained today that although many varying “special” indexing viewpoints of secondary importance do exist there must be one “absolute” or general indexing criterion which can serve every purpose equally well. “Structure” is often quoted as an example of such an absolute criterion. In the past century, mainly a time of mechanical technology and mechanical (Newtonian) world concept, “structure” has seemed to overshadow all other considerations. But the recent shift of emphasis in physics has shown the relativity rather than absoluteness of this Newtonian viewpoint. There are also in many fields of activity special indexing criteria which seem of preponderant importance, mostly because they were historically the first to emerge and the prevalent nomenclature is still based on them. However, for the purposes of the technological sciences, which present an ever widening and changing spectrum of indexing criteria, no basically absolute criteria nor absolute classifications can be recognized.
The implications of a high degree of diffuseness of information can be illustrated by a very simple classification problem: living beings can be indexed or classified according to a large number of criteria, for example: (A) skeleton structure, (B) reproductive system, (C) circulatory system, (D) digestive system, (E) skin structure, (F) habitat, (G) usefulness to human society. Each criterion or “viewpoint” can form the basis of a “classification.” Figures 1 and 2 show schematically a classification based on criteria A and B, respectively. This form of classification can be termed “single-criterion classification,” The classes A1, A2, A3, etc., or the sub-classes A11, A12, A13, etc., could of course be arranged alphabetically. However, there usually is a more meaningful order inherent in the indexing criterion. This order can, for example, be based upon
a size relationship or a relationship of time or space, on some causal relationship, or on a combination of relationships. For example, in drawing up a classification of internal combustion engines upon the criterion of “structure,” we can
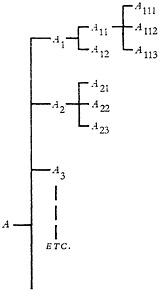
FIGURE 1. Single criterion classification. Classification based on indexing criterion A, skeleton structure.
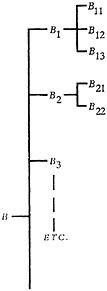
FIGURE 2. Single criterion classification. Classification based on indexing criterion B, reproductive system.
start at the input side of the engine and enumerate all the parts as they contribute and relate to the power generating process. We would in that case start
with the carburetor, and go through the valves into the cylinders; from there on through the pistons, connecting rods, etc., to the power output shaft. This would be a subordination based on a causal principle. To cover all parts of an engine completely, a combination of causal and spatial relationships would be required.
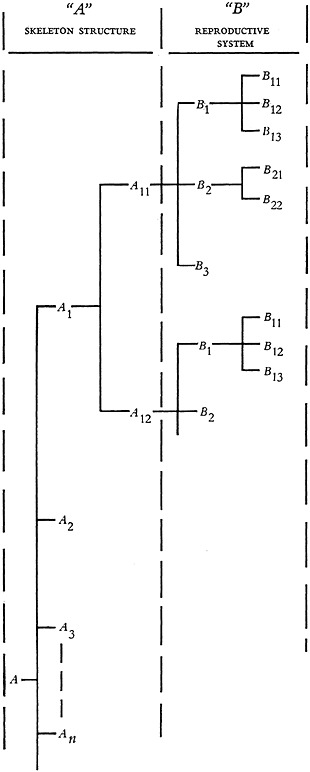
Each of the seven single-criterion classifications of living beings in the example given above, are incompatible and entirely different from the others. Each of these can serve only one particular field of interest or type of user. A “universal” classification, of interest to all possible users, must therefore integrate all these points of view through indexing by all seven criteria. Figure 3 shows schematically a classification based on a combination of only two different indexing criteria. It is seen that the larger the number of indexing criteria, the more complicated such a classification becomes. Although in practice only a small part of all possible combinations will actually be used, the classification system attempts to provide sufficient classes for all anticipated needs. The task is a staggering one. The added task of keeping it up to date by providing for indexing by newer or changed criteria is still more staggering and the cost prohibitive. In practice more than two indexing criteria are rarely used.
Yet the main problem in drawing up a classification system still lies elsewhere, namely, in the decision as to which criterion should be elevated to constitute the main class, and which criteria should constitute respectively the sub-classes and sub-sub-classes.
If, in the example, it should be decided to use criterion A, “skeleton structure” to draw up the main classes, and criteria B, “reproductive system” and C, “circulatory system,” etc., for the sub-classes and sub-sub-classes respectively, this classification would be most useful from the point of view of bone specialists. However, a user interested in criterion G, “usefulness to human society,” would have to consult all sub-sub-classes to find all information in the system of potential interest to him.
Where a very specific purpose is concerned, this form of classification can provide quite a useful tool. For example, for a research laboratory interested in data on stress failures of engine parts, a classification of engines based on engine structural components and parts as a main indexing criterion and the various forms of load and stresses responsible for failures as sub-criteria would serve the purpose admirably.
The above form of classification can be termed an “unpermuted multiple-criterion classification.” In such unpermuted classifications, each item of information need be classified in only one way. No cross-reference structure is required. If an article contains more than one item of information, for instance, information on heat stress in turbine wheels and on torsional vibration stress in
crankshafts, each of these items of information will of course have to be indexed distinctly and separately from the other. However, no cross-reference structure is yet called for.
The unpermuted multiple-criterion classification is the most frequently used form. It is generally considered to be the “purest” form of classification. For the purposes of the generalized theory it will be considered the definition and general model of a classification. The reasons for this will become apparent below.
Unpermuted multiple-criterion classifications can meet only special purposes, those in which the subordination of indexing criteria lends itself to the requirements of the special purpose, as in the example of engine failure data. A “universal” information retrieval system to meet all possible requirements would, therefore, have to consist of a larger number of different classifications, each with a different hierarchial subordination or “permutation” of the indexing criteria. In size and cost this would be a truly astronomical proposition.
Instead of keeping the different classifications separate, it would seem natural to integrate or merge them into one “universal” system. But when attempt is made to effect such a merger it is found that there simply are no relationships between the classes (other than that of their symbols) upon which their order can be based. In other words, there is no real practical alternative to merging the main classes A1, A2, A3 · · · and B1, B2, B3 · · · of all these classifications alphabetically according to the first letter of main classes.
However, in doing this the concept of meaningful hierarchial relationships is abandoned. Even small amounts of permutation virtually force this abandonment. Therefore permuted classifications can no longer be considered “true” classifications.
Far more serious, in achieving the final merging the very purpose and advantage of a classification, namely, ease of searching, is defeated. Not only has the size become prohibitive, but the searching ease is no better than in a conventional subject heading system. Such a “classification” is exactly identical to a theoretically complete, fully permuted subject heading system. In practice, a permuted classification can never hope to be complete, and is extremely fragmentary at best. Permuting a classification requires that each item of information be classified in as many ways as the number of permutations of the indexing criteria on which the classification is based. It also requires a corresponding cross-reference structure.
Summing up, it can be said that classification systems have been found practical only under two conditions: (a) where there is an unambiguous and unchanging subordination of the indexing criteria as well as of the retrieval criteria; (b) where the indexing criteria are fixed and very limited in number.
In other words, hierarchic classifications are practical only where information of a low degree of diffuseness is concerned and the system is intended only for one particular special use.
The difficulties encountered in classifications have intensified as the degree of diffuseness of the information has increased. As a result libraries have tended more and more toward alphabetic systems, although there remains in Europe a strong core of support for classification in general and the U.D.C. in particular.
This transition was a gradual process leading to a continuing replacement of hierarchial classification by alphabetical subject heading systems. Many existing classifications actually are mixed forms which show many characteristics of the subject heading list. The alphabetic subject heading list relieves the system of the embarrassing necessity to decide which criteria to subordinate to other criteria. It provides a less bulky and less expensive apparatus that is easier to maintain and has sufficient flexibility for incorporating new indexing criteria.
With the emergence of special libraries serving industry and Government and with the related development of technical information and research data centers, alphabetic subject headings were in turn challenged by “descriptors,” “Uniterms,” or keyword indexing. Where the need was felt for the use of terms consisting of a combination of two or more single words, some form of mechanical “combinatory,” “coordination,” “collation,” or “coincidence” device was used. These devices made it possible to search by all possible combinations and permutations of terms, without the need of incorporating these combinations and permutations in the subject heading list.
Before analyzing the merits of keyword indexing, the two main components of an information storage and retrieval system will be briefly discussed. These components are:
-
The information store or the memory. In a conventional system this would correspond to the card catalog consisting of the filing cabinets with the catalog cards.
-
The access apparatus, which provides for proper “access” to the memory. In a conventional system this would correspond to the printed subject heading list or printed classification schedules, usually in book form.
Although these two components can be physically combined, it is always possible in any information storage and retrieval system to distinguish between their two functions.
Keyword indexing as formalized, for example, in the Uniterm system, shows the most spectacular advantages in setting up new libraries. No expensive pre-made subject heading list nor classification schedule is necessary nor is it hard to acquire familiarity with the access apparatus. Keywords or
ideas taken from or suggested by the text are used as index terms. After the collection has reached a certain size, the vocabulary of terms will automatically retard its growth and will stabilize itself. The only “maintenance” required is the provision of a cross-reference structure to take care of synonyms, etc. In its simplest form keyword indexing provides the greatest possible retrieval power, as any single term or any combination of index terms can be used to retrieve an item of information.
The cost of such systems usually is only a small fraction of the cost of a conventional system.
If properly indexed, an item of information is indexed by any keyword that is or could possibly become of importance to any potential user of the item of information. Therefore it is also automatically indexed by any or all possible combinations of these terms. The combinations normally include all subject headings or classes and subclasses by which this item of information would have been indexed, had a subject heading list or a classification system been used.
These advantages are, however, bought at a price. This price is the acceptance of a rudimentary “access apparatus,” usually consisting of no more than an alphabetic listing of the complete vocabulary of index terms in use in the system. Such a listing cannot directly tell the user, with a generally desired degree of assurance, what information is contained in the system. For example, a vocabulary of index terms listing the term “water” as well as the term “pump” does not necessarily imply that the system contains any information on water pumps, nor does the presence of the term “jet” as well as the term “engine” necessarily imply the presence of information on jet engines. In other words, there is no way of ascertaining a priori whether the combined terms “water pump” and “jet engines” are “true” or “false” combinations, until the search process is completed.
Another disadvantage may be the lack of hierarchial definition within each indexing criterion. Indexing tends to be performed at the level at which the concept happens first to be referred to, in the text. For instance, an Army General indexed by the criterion of military rank is simply indexed by the term “generals” instead of “field officers,” or “officers” or “soldiers,” or any combination of both. A broad search for everything on “soldiers” may therefore require a number of individual searches by each of the above terms. For these purposes a cross-reference structure has to be maintained in the access apparatus. As a result of these weaknesses of the access apparatus an exhaustive search by a combination of terms may require a number of individual searches by various combinations of various terms. Therefore the low indexing cost is obtained at the price of somewhat higher search costs. However, since in most information
collections the data input load is far greater than the output or search load, this theoretical disadvantage is of little practical significance.
It is possible to alleviate this weakness of the retrieval mechanism by using longer index terms. Instead of the elementary terms “water,” “pump,” “jet,” and “engine,” combined terms like “water pump” and “jet engine” can be used. A vocabulary of index terms will in this manner become more suggestive of the contents of the information system and fewer individual searches will be required to obtain full search results.
Lengthening the average index term produces changes in two other parameters. The first change is a reduction of retrieval power. In using the combined terms “water pump” and “jet engine,” we can no longer retrieve complete information by the broader terms “pumps” or “engines.” Also, if the item of information likewise dealt with water jets but was not indexed by this term, as water jets seemed at that time of no interest to the users of the system, the possibility of retrieving by the term water jets at a later time is lost. Indexing by the elementary terms “water,” “pump,” “jet,” and “engine” would have preserved this possibility.
The other parameter change accompanying a lengthening of the index terms is a reduction in the false combinations of terms. With the true combination “water jets,” the false combinations of, for example, “water engine” and “jet pump” have likewise disappeared.
If this process of lengthening of the index terms is continued, the combination of terms may eventually attain the length of full-fledged subject headings. The need for retrieval by a combination of two or more of these single terms will have been greatly reduced, while the alphabetic listing of the vocabulary of index terms will have attained the structure of a subject heading system.
At the end of this historical analysis of the indexing art a few words on “meaning” seem desirable. It is urged by some, that the information storage and retrieval art devise means of indexing by “meaning” or “true classes” instead of just “words.” The substance of this problem can be stated as follows: “meaning” is only arrived at by a common agreement on what certain terms will be considered to mean or what terms will be used to describe certain notions. This is in essence standardization of language. Such standardization is from time to time undertaken by the various learned bodies and engineering societies. Without some form of standardization, whether organized or spontaneous, no intelligent communication of any kind is possible, and any form of communication should use standardized language as far as available.
Certainly the indexing art should use standardized language to the fullest possible extent. However, standardization of definitions and the process of
indexing are entirely different. Standardization of meaning should preferably be undertaken by or sponsored by the societies representing the various fields of endeavor, so that this standardized meaning may become universally acceptable. The information control art should, where possible, promote standardization of meaning. It should, nevertheless, be realized that the information storage and retrieval art by its very nature finds its greatest use at the frontiers of progress in fields of research with new and not yet consolidated concepts. This is precisely the area where new words and concepts are constantly being formed.
Standardization of meaning will always be far behind the emergence of these new concepts, as a period of crystallization and stabilization is always required before standardization can be successfully undertaken. Therefore, any indexing system used on “frontier” information should be able to function even if no sharply defined meanings have yet been established. This would seem to be a conditio sine qua non for indexing advanced research data. Keyword indexing would seem to meet this requirement. In the absence of single well-defined terms, a number of possible alternative terms can be used. On the other hand, a classification having a hierarchial subordination requires well-defined terms in order to determine this subordination. Hierarchial classifications therefore seem unable to function in areas where semantic indeterminacy still prevails.
Summing up, indexing by “meaning” is not a difficult problem where standardized terminology is available. The real problem and challenge is indexing in areas where no such standardized terminology is yet available, and in making information retrieval systems work despite the absence of standardized language.
Generalized theory of indexing
DEFINITION OF THE CONTINUUM
In the preceding sections, the history and evolution of information retrieval problems has been traced. During this evolution the entire range of possible systems from classification to indexing by the smallest possible terms has been traversed. The entire spectrum of possible indexing systems having thus been laid bare, the formulation of a generalized theory now becomes possible.
The evolution has been a gradual process during which one system automatically developed into another. But it must be recognized as an irreversible, unavoidable process which took place under the pressure of changing conditions and needs.
In the light of this analysis the various known indexing systems appear to
form a continuum rather than contrasting systems. As the function of this continuum is the “description” of information contained in the collection by means of “terms” suited to adequate information storage and retrieval, this continuum might further be referred to as the “descriptive continuum.”
The descriptive continuum is schematically illustrated in Fig. 4, a, b, and c. The parameter which determines position in the continuum is the average length of index terms, measured simply as the average number of letters per term throughout the information collection. This has been selected as the main parameter of the general theory of indexing, defining the continuum (Fig. 4c). Relative to this parameter, the various types of indexing find their respective positions in the continuum roughly as shown in Fig. 4b. Depending upon the width or narrowness with which we define each of these systems, the areas covered by their designations either overlap to some extent, or leave a certain amount of gap. However, no matter how narrowly we define the areas of these systems, the entire spectrum is in practice actually used.
One end of the continuum represents indexing exclusively by the smallest single words available in the language. That is, it uses the smallest “units” available. Such a system will therefore use the largest possible number of terms per item indexed. At this position in the continuum we would, for example, index an article on the “erosion of turbine buckets in bunker-C oil burning jet engines” by the individual single terms “erosion,” “turbine,” “bucket,” “bunker-C,” “oil,” “jet,” and “engines.” This is the area of keyword indexing in its purest form.
On moving away from this end of the descriptive continuum, the average length of the index terms increases. In the preceding example individual terms like “jet,” “engine,” “turbine,” and “bucket” would gradually be replaced by combined terms like “jet engines,” and “turbine buckets.” This takes us gradually out of the area of “keyword” indexing into what starts to resemble a conventional subject heading list. As the average length of the terms continues to increase and we begin to use terms like “jet engine, turbine bucket” or “turbine bucket, jet engine,” and “erosion, jet engines,” we have reached the area of the subject heading list.
The other extreme of the continuum represents the area of hierarchic classification, where we index by the longest possible terms and only one term is required to index an item of information. At this position in the continuum, an article on the “erosion of turbine blades in bunker-C oil burning jet engines” would be indexed by classes, sub-classes, sub-sub-classes, etc., for example as follows: “internal combustion engines, steady-state engines, gas turbines, turbine blades; liquid fuel, mineral fuel, bunker-C oil; wear, erosion.” For the purposes of this general theory, the above classification must be considered one
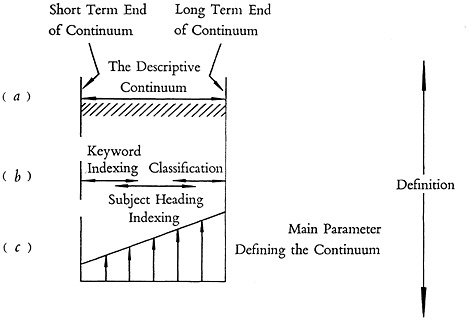
FIGURE 4. (a, b, c) The descriptive continuum. (c) Average length of index terms.
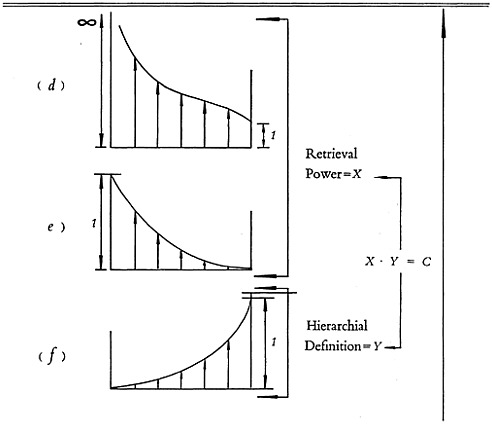
FIGURE 4. (d) Potential depth of indexing and retrieval; allowable diffuseness of information; number of terms per item of information. (e) Permutability of retrieval criteria. (f) Degree of hierarchial definition of indexing.
single indexing “term,” since it designates only one particular place in the classification.
It will be noticed that this classification is an (unpermuted) multiple-criterion classification, having structure as its main criterion, fuels as sub-criterion, and operational troubles as a sub-sub criterion. In practice, most classifications will not have more than two indexing criteria, so that the possibility of indexing at will by additional criteria such as operational troubles is lost at this end of the continuum.
Derived mathematical parameters
In addition to the main or defining parameter, average term length, the descriptive continuum possesses a number of “derived” parameters which are functions of the main parameter.
The most important derived parameter is the potential depth of indexing. This parameter, which is proportional to the number of potential index criteria per item that can be used, is shown schematically in Fig. 4d. For a pure classification system this value is unity, since one cannot index by a larger number of indexing criteria than those that have specifically been built into the classification. As we move away in the continuum and shed the constraints of classification systems discussed in earlier sections, larger numbers of indexing criteria can be utilized without undue penalties in cost and complication. When we reach the other extreme in the continuum almost unlimited indexing depth becomes practical.
This and other parameters show that, in general, the more diffuse the information, the more advisable it is to keep to the short-term end of the continuum.
Indexing depth, however, involves more than just the number of indexing terms that can be combined for a search. A related derived parameter is permutability of retrieval criteria, schematically shown in Fig. 4e. In a classification for retrieval by one indexing criterion only, this must be the criterion on which the main classes are based; for retrieval by two criteria these must be the criteria on which the main classes and first sub-classes respectively have been based, etc. We cannot retrieve by a single criterion which forms only the sub-classes, or the sub-sub-classes. At this end of the spectrum, the permutability is therefore equal to zero. On moving toward the other end of the spectrum more and more permutability of retrieval criteria is obtained, until at the short-term end of the continuum, full permutability is available.
Together the two parameters discussed above determine the accuracy with which information can be indexed and the detail in which information can be retrieved. We will therefore lump together these parameters in the term
retrieval power. This is the most important single feature of an indexing system.
A third derived parameter is what can best be termed hierarchial definition of indexing. (See Fig. 4f.) In a classification system this parameter is equal to one. That is to say, there is a 100 percent hierarchial definition, since to index by any one criterion is to index by all possible hierarchial levels. In our previous example of an item of information on the “erosion of turbine blades in bunker-C grade oil burning jet engines,” each of the three possible indexing criteria “structure,” or “fuel,” or “operational troubles” was indexed by all possible hierarchial levels: the structure as “turbine blades, turbines, steady-state engines, internal combustion engines”; the fuel as “bunker-C grade oil, mineral fuel, liquid fuel.” Operational troubles could have been indexed as “erosion, wear,” if the classification had provided for the possibility of a third indexing criterion.
At the other end of the continuum, the area of key word indexing, hierarchial definition disappears out of the “retrieval apparatus.” By using our previous example again and indexing this document by “structure,” it then becomes more or less arbitrary whether to index simply by the term “turbine blades” or by the next higher level such as “gas turbines” or by a still higher level or any combination of these.
In selecting index terms there are only two degrees of freedom, namely the index criterion we use and the hierarchial level within this criterion. The first degree of freedom corresponds to the combination retrieval power shown in Figs. 4d and 4e. The second corresponds to the degree of hierarchial definition shown in Fig. 4f.
Although no exact mathematical relationship is as yet available, it seems clear that greater hierarchial definition can only be obtained at the expense of retrieval power, and vice versa. This must be considered the first basic law of the descriptive continuum. If X designates the “retrieval power” and Y designates the hierarchial definition, it could be roughly expressed as follows: X · Y =Constant.
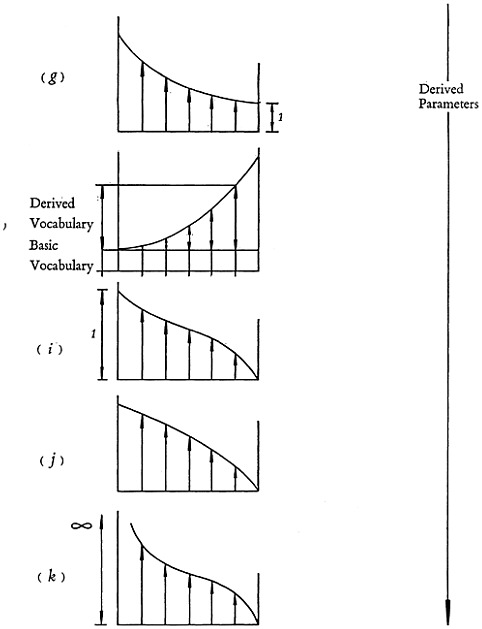
When a search has to be performed in a system located at the short term end of the continuum where the hierarchial definition is low, a complete search may involve a number of individual searches using terms of different hierarchial level. In a search by two terms of different indexing criteria, each having a number of possible hierarchial levels, it is necessary to search by each of all possible permutations. In contrast with this, at the other extreme of the continuum, the area of pure classification, only one search is required. The number of individual searches required for a complete systems search is schematically shown as a parameter in Fig. 4g.
Another parameter of importance to the economics of the system is the size of the access apparatus. This is indicated in Fig. 4h. At the short-term end of the
continuum the access apparatus consists merely in the alphabetic list of the smallest single words used for indexing. This basic vocabulary is usually very small.
At the long-term end of the continuum, the access apparatus includes combinations of these single words. The number of these combinations increases greatly as the combinations get longer and longer.
Fig. 4i shows the need for a mechanical coordination or coincidence mechanism as a function of the main parameter, average term length. At the short-term end of the continuum, a coordinating mechanism is indispensable. At the other extreme end no such mechanism is required. In the middle of the continuum there may be a need to search for the coincidence of subject headings. Without a coordinating mechanism, the potential depth of indexing and retrieval shown at the short-term end in Fig. 4d remains a potential only. The same conclusion holds for all other parameters. The actual values of the parameters which are obtained will otherwise be far less favorable.
Fig. 4j shows the possibility of false coordinations of two or more terms as a function of the average term length. As explained in the previous section, it is zero at the long-term end of the continuum and a maximum at the short-term end. False coordinations do not result in loss of information, but in the retrieval of some non-pertinent documents among all the required pertinent documents. It is a “noise” factor usually having a minor nuisance value only. This parameter is therefore of little practical importance.
Figure 4k shows the capacity for handling semantic indeterminacy, that is, the capacity of an indexing system for indexing in areas where a sharply defined and well-standardized vocabulary is not yet available. As explained previously, classifications cannot handle this type of “frontier” information at all. The closer the position to the short-term end of the spectrum, the greater the capacity to handle semantic ambiguities or indeterminacy. At the extreme short-term end, it increases to an almost infinite degree, and even the vaguest concepts can be described by putting a number of different terms together to form a kind of telegram-style description of the concept. Any one or any combination of these terms can then be used to retrieve the information item.
The general theory of indexing as presented above is open to mathematical treatment. The parameters presented so far are mathematical in nature. The curves shown are of course only schematic indications of the true mathematical functions. Determination of their exact shapes will have to await the establishment of the correct mathematical relationships. A complete mathematical interpretation of this general theory is planned.
Cost parameters:
In addition to these operational parameters a number of others could be
listed. These would be cost parameters. Although the full mathematical development has not yet been achieved, certain general conclusions seem possible.
-
Cost of indexing. It is lowest on the short-term end of the spectrum and highest on the long-term end; the closer to this end the indexer operates, the greater will be his need to consult the existing access apparatus, and the higher will be the indexing cost.
-
Cost of access apparatus. This parameter will follow roughly the same pattern as the indexing cost.
-
Search cost. A pure hierarchic classification should in theory allow immediate retrieval by a single search, with no required mechanical searching aid. This makes for low search cost. On the short-term end of the continuum every search question may involve a number of individual searches, and some form of search machine is required. Higher search costs can therefore be expected. However, this factor can be reduced in significance by the choice of a proper coordinating mechanism, as will be explained in a subsequent paper.
As far as the total costs are concerned, the general conclusion seems to indicate that normally the overall cost of operating a system, that is the total input cost (cost of entering the data) and total output cost (cost of searching) will, in most cases, be considerably lower at the short-term end.
SELECTION OF POSITION IN THE CONTINUUM
When we have information of low diffuseness, which does not require more than one or two different indexing criteria, and when these criteria have always the same hierarchial subordination, we can in theory operate at any point in the continuum and use either classification or keyword indexing. Generally speaking, however, the cost will be much lower at the short-term end, so that we will normally select this end of the continuum. One possible exception is the case in which the input load is very small and the search load very high. In this case the low indexing cost of the short-term end is of little help and the low search cost of the long-term end would definitely be desirable.
For information of high diffuseness for which permutability of the indexing criteria is required, we have no choice but to operate at the short-term end of the continuum regardless of the ratio of input to output load, as it is only at the short-term end that full permutability and the highest possible indexing depth are available.
The present paper represents the first attempt to commit this general theory to print. We are fully aware that this first writing may still be far from complete and may contain many weak points and inconsistencies in its presentation. But we hope it will contribute to a better understanding of the problems of indexing and may serve as a foundation upon which in time a fully mathematical theory of indexing can be erected.






















