
The Haystaq System: Past, Present, and Future
HERBERT R.KOLLER, ETHEL MARDEN, and HAROLD PFEFFER
I. Introduction
A. BACKGROUND MATERIAL ON PATENT SEARCHING
Literature searching has been distinguished from information retrieval by some authors (1, 5), and within the field of literature searching the peculiar characteristics of patent searching have also been set forth (2–4). The literature contains discussions of various philosophies of searching systems, each of which is derived from a different appraisal of and theory as to users’ needs (1, 6, 7). To round out the discussion in the present paper, a few characteristics of patent searching and some of its practical implications are given.
Patent searching is that type of literature searching which is performed by patent examiners when (1) determining the novelty of a concept claimed in an application for a patent; or (2) (if novel) finding the nearest similar related concepts previously known and published. The Patent Office library includes within its files over 2.8×106 domestic patents, twice this number of foreign patents, and thousands of serial publications and books. This library literally deals with every field of technology, running the gamut from pins and needles to printing presses, and from antibiotics to submarines. About 2000 searches are made each day in the normal operation of the Office, and each search includes from one to upwards of twenty distinct questions. It is estimated that about 20 per cent of the searches made are in the chemical field, about the same fraction relate to the electrical and electronic arts, and the remaining 60 per cent deal with mechanical and miscellaneous fields. The disclosures of patents in the chemical arts vary in the amount of information they contain from a single, very specific “recipe” to a very generic disclosure of a series of related processes, each illustrated by a large number of examples. The compounds in-
HERBERT R.KOLLER and HAROLD PFEFFER Office of Research and Development, U.S. Patent Office, Washington, D.C.
ETHEL MARDEN National Bureau of Standards, Washington, D.C.
volved in a disclosure may be described specifically or generically, and it is common for a genus to be set forth in the so-called Markush type of structural formula. (See Section II.A, “Factors Considered.”)
Haystaq is one of many possible types of mechanized searching systems which could have been designed for Patent Searching. Obviously some systems are better equipped than others to satisfy the needs of patent searchers. Some suggested criteria by which systems may be evaluated will be found in Appendix A.
Patent searching is not at all restricted to patents, as the name might suggest. The total field of search does indeed include patents of all countries, but it equally embraces periodicals, textbooks, catalogues, abstract services, and every other form of publication. Many persons other than patent examiners make the same type of literature search; for example, research workers embarking on new investigations, patent attorneys, and lawyers in general.
This type of search is characterized by questions variable in scope from the most generic to the most specific viewpoints. In addition, general combinations as well as subcombinations, equivalence between concepts, negative concepts, and certain syntactical-logical artifices (e.g., Markush formats) are all of importance.
B. HAYSTAQ: SOME GENERAL CONSIDERATIONS
The characteristics of the Haystaq system have been described elsewhere (4, 8); therefore, this paper is principally concerned with new developments and additions to the system. In general, Haystaq includes four parts: (1) a data preparation routine for the library making up the disclosure file of information to be searched (see Appendix D); (2) a data preparation routine for the question, which is set up in the form of a model answer; (3) the search routine; and (4) the checkout routine, which evaluates apparent answers to questions and provides the output of the system. The greatest part of the effort so far has been expended on the search routine since (a) the objectives of the two data preparation sections can be achieved manually so long as the system is not yet in a large scale operational phase and (b) the checkout routine in extenso is not essential to the searching routine.
Haystaq simulates the manual type of search performed by patent examiners in that it effects a serial scanning of each document in the file. While at present its routines are being coded for the NBS SEAC, full development of the system will be predicated partly on features available only in a more advanced machine. Some of the desirable characteristics of such a machine will be discussed below.
In order to achieve a reasonable working model, the research has been
focused on the field of chemistry, although it is quite apparent that minor modifications will permit the inclusion of other fields of knowledge in the system. The file is organized in the most convenient arrangement for the human searcher. Thus, within each document the largest segment of disclosure treated as a unit is a complete process, including all the steps disclosed. The next largest segment of disclosure treated is a composition or admixture. Each composition is subdivided into groups of codes representing the individual ingredients (or “items”) which it contains. The individual codes are known as descriptors. Since disclosures may vary from simple to very complex statements, any or all of the above levels of organization may be involved.
The system must provide the utmost flexibility with regard to the manner of formulating questions. This need stems from several sources: (1) A very-large file requires a high degree of discrimination to provide exactly (and only) those disclosures which are desired. (2) The same piece of disclosed information can answer a large number of questions, each reflecting a different interest. (3) The ingenuity constantly exercised in phrasing patent claims and the constantly shifting focus of interest in the industrial community result in the continuous generation of new ways of expressing essentially the same or related ideas (2, 3). Examples of types of searches which must be provided for are given in Appendix B.
II. Current work
A. FACTORS CONSIDERED
Among the aims of the Haystaq system, as stated in a previous report (8), is the construction of a prototype system. This would permit additional studies as to the requirements and design of a machine system, and provide a basis for constructing improved search systems. Any results obtained from the study of the prototype are a function of the sufficiency of the system, and the sufficiency of the system itself depends upon how well it fulfills the users’ needs.
Several problems, set aside for further study at the time of the initial effort, have now been tackled. These are (1) the Markush problem, (2) the creation of an effective classification scheme for the preparation of schedules of items, and (3) the necessity of giving the user greater flexibility in posing questions to the system.
1. “Markush group” is an art term used in the Patent Office for designating a synthetic genus whose scope is determined by a listing of its members. The first system devised was capable of handling this situation where the genus was defined by listing individual compounds, e.g., the class consisting of phenol, mono-chloro-phenol, mono-amino-phenol, and mono-ethyl-phenol. How-
ever, another method exists for defining such a group by means of a structural formula showing the portion of the molecule common to all the embodiments, to which is attached a variable member, which is then defined. The same example in the structural format appears in Fig. 1. Where the number of em
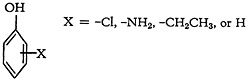
FIGURE 1.
bodiments is small, it becomes a simple matter to decompose such generic formulas into their component embodiments and encode them individually. But it is not uncommon to find such formulas embracing hundreds, indeed thousands, of specific embodiments. One example which was discovered contained over 64,000,000,000 embodiments. It is completely unrealistic to think in terms of decomposing such compact forms into specific embodiments for encoding from the point of view of the number of man-hours involved, the amount of storage required and the time to be consumed by a computer in scanning this mass of data. On the other hand, there are obvious and distinct advantages in being able to compress so much data into an extremely compact form. The problem is serious because the great majority of chemical patents as well as much of the non-patent literature have utilized this device for more than twenty years. The system was therefore designed to process questions in this form.
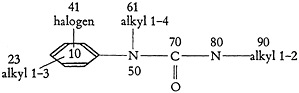
2. Compounds are sometimes defined by generic descriptors alone, sometimes by pure structure configurations alone, and very often by a hybrid of both. Consider the example of the latter situation which is illustrated in Fig. 2.
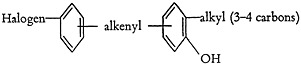
FIGURE 2.
The terms “halogen,” “alkenyl,” and “alkyl” in a topological network of elements become quite embarrassing in an attempt at tracing an element-by-element path from one portion of the molecule to another. If this example is considered as a question, it is evident that the system should permit recognition of chlorine, bromine, iodine, or fluorine as species of “halogen”; and “propyl,” “isopropyl,” “butyl,” or “isobutyl” as species of “alkyl (3–4 carbons).” In
other words, the compound of Fig. 3 should be recognized as an answer. Previous attempts at creating a classification based upon a hierarchical arrangement of generic and specific terms have fallen by the wayside. The large num
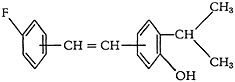
FIGURE 3.
ber (practically limitless) of generic and subgeneric terms which can be generated presents such a confused picture of overlapping relationships as to preclude the construction of one comprehensive hierarchy. The usefulness of any comprehensive system will be measured to a large extent by its ability to give full effect to the genus-species relationship.
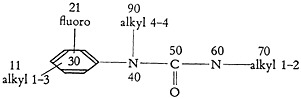
3. The patent examiners, who are among the potential users of the system, are not limited in their searches to mere determinations of the novelty of a compound. Because of legal peculiarities in the patent system, compounds which are similar within certain prescribed limitations are acceptable as answers. Thus, if a question involves the compound of Fig. 4, an acceptable answer may very well be found in any of the structures shown in Fig. 5.
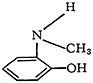
FIGURE 4.
Thus, 5(a) and 5(b) are illustrative of positional isomers of Fig. 4 in which all the functional groups are alike, but their relative positions are different.
Figure 5(c) is illustrative of a situation where all the requirements of the question are met, but the compound has something in addition. If the user required an exact match of the question structure 5(c) would not be acceptable, nor would 5(a) or 5(b). However, if he specified the question as a fragment of any larger configuration, 5(c) would be a valid answer.
Figure 5(d) shows an example of a compound which is a higher homolog of the question, the only difference being in the length of the chain of carbons attached to the nitrogen.
While none of these has the same effect as a direct anticipation, nevertheless they are all valid answers unless they can be rebutted by an applicant.
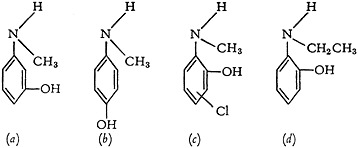
FIGURE 5.
In order that the user be given maximum flexibility in stating his question, the system must permit him the option of indicating, for each point of the molecule in question, whether he will or will not accept positional isomers, whether he will or will not accept homologs and whether he will or will not accept as answers compounds of which the question represents a fragment.
B. THE SYSTEM
In the original search program of Haystaq, chemical compounds were described by a limited schedule of coordinate chemical descriptors. Sufficient definition was thus given to a search request for a specific compound to eliminate a large number of disclosures. This procedure was based upon the anticipated use of a topological element-by-element search, such as the routine written by L.C.Ray (9), whenever required, which would employ the data resulting from the previous operation to give a conclusive answer.
The present system represents an improvement in the search for chemical compounds in the light of the problems outlined above. It is based upon a judiciously selected, comparatively small basic vocabulary of functional groups. These, so far as possible, have been chosen to coincide with the conventional groups recognizable by chemists. In some instances terms have been synthesized, either for convenience in handling or to add additional flexibility to the system.
Inasmuch as recognition of topological relationships among functional groups is one of the desiderata of the system, a close study of two available systems developed by others was made: the Norton-Opler system (10), which deals with relatively large functional groups, and the Ray system (9), which deals with elements. The functional groups chosen for use in Haystaq were
selected in an attempt to overcome the relative rigidity of the Norton-Opler system and the relative slowness of the Ray system.
It was not found practicable to use stored look-up tables referring to class terms because of the infinite variety of generic terms and the inability to predict or state all the species which may fall under any given genus. It was therefore decided to make all data, both disclosure and question, self definitive. That is, each generic expression utilized in describing a compound is defined in terms of its specific meaning in that particular compound.
The coded chemical descriptors, all having the initial digit 3, are divided into four sections: 3A, 3B, 3C, and 3D.
The 3A section is devoted to a class of terms which are combinations of two or more units of basic functional groups, having constant definitions and recognizable as such by chemists; e.g., anilino, naphthyl, or carboxyl.
The 3B section is limited to generic expressions, i.e., those capable of being represented by more than one specific embodiment. These are defined, where necessary, by reference to the specific groups in 3C which are pertinent to the particular compound under consideration. Exemplary terms to be found in this group are acid, ester, and halogen.
The 3C section contains a list of all the basic functional groups which make up the particular compound and shows the topological relationships among them (without, however, indicating relative positions of attachment).
The 3D section (not yet written) is an element-by-element topological definition of each compound.
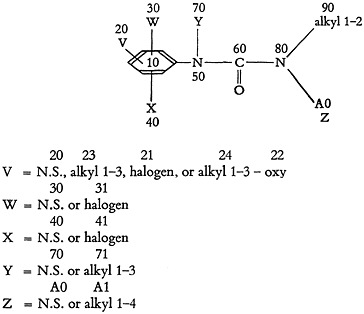
The example of Fig. 6, which is a complex structure having some 1600 distinct embodiments, illustrates a typical structural formula in the literature.
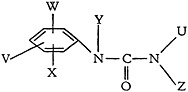
U=an alkyl group having one to two carbons; V−H, a halogen, an alkyl group having one to three carbons or an alkoxy group in which the alkyl has one to three carbons; W=−H, or halogen; X=−H, or −Cl; Y=−H, or an alkyl group having one to four carbons; Z=−H, or an alkyl group having one to four carbons.
FIGURE 6.
Note that in each case, where H is shown as one of the variants in a group, it is in effect stated that one of the variations is the absence of a substituting group. H is therefore substituted by the expression “N.S.” (no substituent).
The structure is rewritten in Fig. 7 in composite form, showing the separation of functional groups, and is arbitrarily numbered for identification of the groups for topological tracing. These numbers are called “designation numbers.” Fig. 7 also illustrates the coding scheme.
This coding does not exhaust all possible terms for 3A and 3B; it is only intended to be illustrative. Research is continuing on terminology. In the 3A terms, the number following the description indicates the number of occurrences. Note that all 3B terms (generic) are defined by reference to the groups found in 3C. For example, “halogen-71” in 3B is defined in 3C as a chloro group. The ether of 3B is defined by the 3C terms phenyl, oxy, and alkyl, and is therefore an aryl-alkyl ether.
The first group in 3C identifies piece number 10 as a phenyl group. The first parenthetical expression describes the number of other groups connected to this piece and is expressed as a range. In this case the number may vary, depending upon the particular combination of variable groups which may be present at any one time. Since there are attached one fixed group and three variable groups, each of the latter having as one of its variants a “no substituent” group, the range of connections may vary from one to four.
The second parenthetical expression, which has been left blank, is used only for questions and indicates to the computer whether the exact number of (1) or at least as many (0) connections must be matched.
The remainder of the line indicates that piece 10 (phenyl) is connected to each of the pieces numbered 30, 50, 70, and 90 by a single bond (S).
In piece number 30, M indicates the beginning of a variable group. When one of the variants is “no substituent” (N.S.), that information is stored in the M word.
C. SPECIAL CONSIDERATIONS
(a) Ordering. In all the data, in both question and disclosure, the descriptors in 3A and 3B are presented in an ascending series, according to the numerical values of the codes representing the substantive information. The program thus permits the computer to decide (in searching for a particular term) at the earliest possible moment that there is no available answer. For example, if the code for a question term were 127 and the first three descriptors in the disclosure list were 33, 105, and 148, comparison with the first would indicate that it was too small. This would result in calling for the next word, with the same consequence. However, on comparison with the third word, which is too large, the computer would conclude that there is no answer for the question.
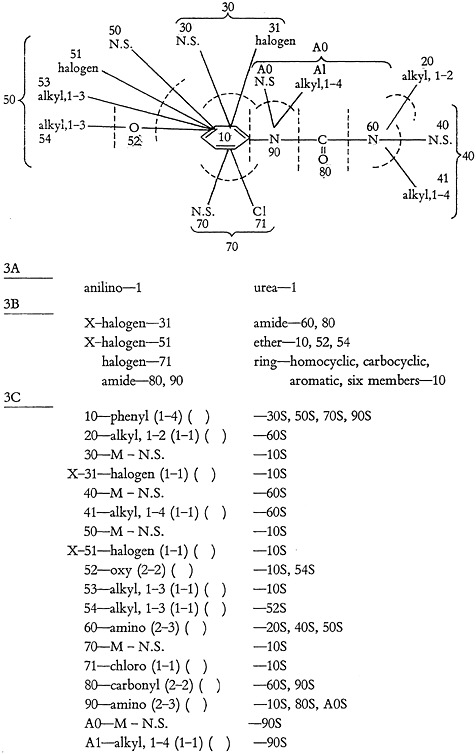
(b) The Question. In the search of Markush type disclosures with Markush type questions in 3C, the computer synthesizes the various combinations of specific embodiments in both question and disclosure. Since this may result in a large number of combinations, some means must be found to relieve the computer of the burden of searching all possibilities. One of the devices employed is the ordering of words in a variable group in the same manner as described above. However, this in itself is not sufficient. It is apparent that for any particular disclosure being searched, not all the variables in the question can be expected to be answered. If fruitless questions can be identified sufficiently early, time can be saved by instructing the computer to disregard them. Consequently the 3A and 3B sections of the question have each been split into two groups, the one containing those terms pertaining to the fixed part of the molecule (3AN and 3BN), and the other containing those pertaining to the variable portion of the molecule (3AM and 3BM). When a 3AN or 3BN term is not matched, the search of that disclosure is immediately terminated. However, failure to find a 3AM or 3BM term results in marking the question 3C pieces referred to, so that they are omitted from consideration when the topological search is made among the 3C terms. The question is re-marked in this manner for each disclosure considered. No terms which are partly fixed and partly variable can be used as 3A or 3B questions. They must all be either one or the other.
If the example of Fig. 7 were to represent a question, the arrangement would be as follows:
|
3AN |
anilino—1 urea—1 |
|
3AM |
– – – – – |
|
3BN |
amide—80, 90 amide—60, 80 ring—homocyclic, carbocyclic, aromatic, six members—10 |
|
3BM |
halogen—31 halogen—51 halogen—71 |
It is noted that the term “ether” does not appear, since in this example it is in part fixed and in part variable.
(c) Generic expressions in 3C. While generic expressions are ordinarily confined to the 3B section, situations arise, as illustrated in the example of Fig. 7, where a portion of the molecule of a structural formula is described in class terms rather than by some specific embodiment. In this case the 3B terms are repeated in the 3C section, treating them as though they were pieces of basic
vocabulary. Such pieces are marked with an X both in 3B and 3C. In the topological search in 3C, on recognition of such a marked term, the computer is instructed to accept a similar term or any species embraced therein. This is accomplished by a look-up procedure in reverse from the 3C to the 3B section. Thus (referring to the example again as a question), the terms “31-halogen” and “51-halogen” are answered by the terms halogen, chloro, bromo, iodo, or fluoro.
(d) Rings and alkyl groups. The term “alkyl” is of such frequent occurrence that it loses its discriminatory power as a generic expression. This term frequently serves as an additional means of compressing information, as for example “an alkyl group having 1–3 carbon atoms.” The “alkyl” word is therefore given special treatment and has a small subroutine devoted to handling it. The information contained in this word is in fixed fields. One field carries the designation “alkyl.” Another field has information as to the number of carbons involved and is expressed as a range with an upper and lower limit. A third field carries the identification of specific groups. The fourth field is reserved for the question only, and is used to indicate whether the search is for any alkyl group within a specified range or for any homolog at least as large as a specified minimum.
Unsaturated carbon chains are defined in terms of alkyl groups joined through double or triple bonds.
The words which describe rings represent a package of information. Each ring is described in terms of whether it is homocyclic or heterocyclic. If homocyclic, it may be carbocyclic, nitrocyclic, etc. If carbocyclic, it may be alicyclic or aromatic. Heterocyclic rings are described in terms of the kinds and frequency of occurrence of the hetero elements. All rings are further described in terms of total number of elements (i.e., ring size) and double bonds. A special subroutine permits asking for rings in terms of any one or more of the terms described above.
D. THE SEARCH
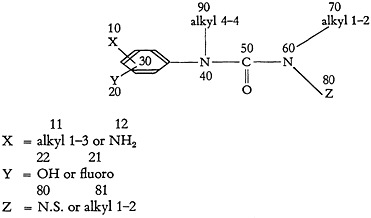
In general, each of the four sections described may be used as a primary basis of search. However, 3A, 3B, and 3C may each operate as a screen for any one of the subsequent sections. One feature of the 3C section is the creation of an Equivalence Table as part of the output. This table identifies each group of a disclosure molecule which represents an answer for the equivalent group in the question. For example, if Fig. 8 represents a disclosure molecule and Fig. 9 represents a question molecule, the Equivalence Table produced would be as shown in Fig. 10.
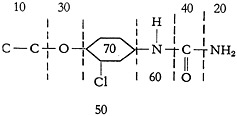
FIGURE 8.
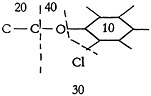
FIGURE 9.

FIGURE 10.
Now if the user specifies that no answer is acceptable unless it shows the exact relationship of the substituent groups on the phenyl, the supplemental question for section 3D shown in Fig. 11 provides exact definition. Bv ref
FIGURE 11.
erence to the Equivalence Table the final element-by-element search spotlights those groups of the disclosure equivalent to question groups 40, 10, and 30, namely disclosure groups 30, 70, and 50. This, of course, has the effect of
pointing the 3D search at the critical portion of the disclosure immediately and avoids the needless tracing along innumerable false trails. Since the Equivalence Table is a necessary part of the 3C search section, it costs nothing additional in the way of programming; on the other hand, it proves to be a bonus for the 3D operation.
The search proceeds in serial fashion through each of the sections, the 3AN and 3BN sections acting as screens for the 3C search, and the 3C acting as a screen for the 3D search, when either of the latter is required.
The first step in the program is a check to see whether a 3C search is required, and, if so, whether there is a sufficient number of words in the disclosure to satisfy the minimum requirements of the question. Detection of an insufficient number results in the reading in of new disclosure information. A check is then made as to whether there are any question requirements for section 3AN. If there are none the search proceeds to the next section. If a 3AN search is required each question word is matched in turn against the entire ordered list of 3A disclosure terms. The prerequisite for bringing up a new question word is the matching of the previous question word. A failure at this level results in discarding the disclosure and trying a new one.
The next step (assuming satisfaction of the 3AN requirements) is to see whether the question involves a 3AM section. If it does not, examination is made of the question requirements of the next section. If, at the satisfactory completion of any section, it is found that all requirements of the total question have been satisfied, the document identification is printed out. If a 3AM search is required, the individual question words are matched against the ordered 3A disclosure list. However, a failure at this level does not have the same effect as in the previous section, since these terms represent variable portions of the question molecule. Instead, the question 3C members, identified through their designation numbers, are marked so that they will be omitted in the topological tracing of the 3C section.
The 3BN section is examined after the 3A section of the Question has been satisfied. Each question word is matched in turn against an ordered list of disclosure 3B terms, in a manner similar to the operation in the 3AN section. When a pair of terms is matched, the question is examined to see whether the generic expression itself (the 3B term) provides a sufficient answer or whether definition of the term is called for. Where no definition is required, the operation proceeds as in 3AN, where a new question term is brought up after matching the previous one. Where definition of the generic expression is a requirement, reference is made to the functional groups in the 3C section, which either individually or in combined form represent the specific embodiment involved. Comparison is then made of the definitions of the question and dis-
closure. Failure to match definitions is equivalent to a failure in the 3AN section, and results in bringing in new data for examination. Note that in this situation the generic term acts as a screen, since it must be matched before any attempt is made at checking definitions. Failure of either the screening operation or matching of definitions has the same effect, namely, discarding the disclosure.
The 3BM section is then checked in the same manner as in 3BN, but the consequences of failure are the same as in 3AM. Since the 3BM terms represent variable portions of the molecule, inability to match them results in the marking of the indicated groups in the 3C section so that they will be omitted from consideration in the topological (3C) search.
Whenever a 3B term in the Question is found to have a special generic mark, no definition is required. If a topological search is indicated, it means that this term appears in the 3C section in place of one of the basic vocabulary units. Whenever this situation arises, all matching 3B terms of the disclosure are stored in a special section of the computer’s memory called the Generic Word Storage. If Fig. 7 represents a Question, the matching terms for “halogen—31” and “halogen—51” are thus stored. When a term marked “generic” is encountered in the 3C section, it is an indication that a corresponding term is acceptable provided it is the same genus or one of its specific embodiments. Thus, in the example an appropriate answer is “halogen” or “chloro” or “bromo.” This is explained in greater detail below.
The 3C section follows very generally the logic of the Ray routine (9) in tracing the topological network of the molecular structures. Assume again that Fig. 7 represents a question. The first word in the 3C section is “10—phenyl.” The 3C words of the disclosure are scanned until a matching word is found or the end of the list is reached. Failure to match again results in the reading in of a new disclosure. Assuming that a match is found for “phenyl,” the number of connections required for phenyl is checked on a consisting or comprising basis as indicated by the question. “Consisting” means that the range of connections of the disclosure must show at least one point of coincidence with the required range, while “comprising” means that the upper limit of the range of the disclosure connections must be at least as great as the lower limit of the question range. If no match is found on this basis, the functional group found is obviously incorrect and another match for phenyl is sought.
Assuming that both the functional group and the number of connections are matched, the information in the first connectivity field of 10—phenyl is scrutinized. This represents the designation number of one of the groups connected to it and the nature of the bond (in this case 30S). The group thus designated becomes the next question descriptor. It is checked first to see
whether it represents a single descriptor or the beginning of a variable group (Markush). In this example, 30 is found to represent a variable group. This descriptor is next checked to see whether there is a no substituent variable. Since there is one, the upper limit of the range of connections is reduced by one in the question “source word” (phenyl), and the range again matched against the range of connections shown in the disclosure source word. Assuming that the matching disclosure phenyl group showed three connections, the range on the question is reduced from “1–4” to “1–3” and therefore is still matched by this disclosure. After acceptance of any term, the redundant connection indications are cancelled in both question and disclosure. However, when an N.S. group is accepted, as in this example, cancellation occurs only in the question. Thus, “30” is cancelled from word 10 and “10” is cancelled from word 30. The next field in 10—phenyl is then examined and word 50 is brought up as the next question. This group also proves to be variable and since it also shows an N.S., the range of connections in phenyl is reduced to “1–2.” An attempt to rematch against the disclosure reveals that the range is too low. Therefore, this combination of variables cannot find an answer in this disclosure. The range in the question is therefore restored to “1–3” and another member of the variable group is brought up as the new question. This is “X-51—halogen.” Recognition of the generic mark (X) activates a look-up routine to discover whether any designation number of the answering phenyl group is to be found among any of the words of the Generic Word Storage. If such a word is found in the Generic Word Storage, it is compared on a substantive basis with the question, and if they agree, the word in the Generic Word Storage is marked to show which question word it answered. The 3C word which defines this generic word is then substituted for it and the operation continues. Redundant connection indications are cancelled from both question and disclosure. If no corresponding term is found in the Generic Word Storage, another member of the group is tried until all members are exhausted. Should a member with an “omit” mark be found, it is ignored and the next member examined.
Either of two conditions may obtain at this point: a match may or may not have been found for “X-51—halogen.” If a match has been found, an attempt is made to continue on the selected trail by looking for other connections from the halogen. If there remain no unmatched connections on this group, the search backs up to the first group that can be found which has uncancelled designation numbers and attempts to proceed forward from that point. In this case, the question word “X-51—halogen” has no further connections; therefore the backup is to the preceding word, “30—M—N.S.” Since that word has no further connections, another step back is made to “10—phenyl”
and the next unsatisfied connection, “70S” is selected. The search then proceeds in a forward direction again. As progress is made forward and backward in the question, there is a corresponding movement through the disclosure. Thus, for example, when the search backs up to “10—phenyl” on the question side it also backs up to the corresponding word in the disclosure. When all selected question words which have been matched have all their connection designations cancelled, it is established that an answer has been found.
Now consider the condition that no match has been found for “X-51—halogen.” On testing for another member of the 50 group, it is found that all members have been tried without finding a match for any of them. This was therefore a blind trail. It is possible that if another answer is found for the 30 group (which was the first connection attempted from “10—phenyl”) an answer may appear for the 50 group. The search therefore backs up to the last place that matched and attempts to find another answer. In the example given, the last accepted connection was for an N.S. member of a variable group; therefore, the range in the parent or source word is restored and the next member of that group is tried. (If this word is anything other than an N.S., an attempt is made to find another answer among the remaining connections in the disclosure word of the last match.) If none of the other members of the variable group can be matched, it is an indication that the apparent answer for the source word was incorrect. Therefore, another attempt is made to find an answer for “10—phenyl.” Since this is the first word, the search proceeds down the list of disclosure words, continuing from where the last apparent answer was found. If another phenyl word occurs, the search again attempts to trace through the structural network from this point. If no other match for phenyl is made, a new disclosure is brought in. In general, when backing up to look for new trails, the attempt is made to find other answers for connections from a source word which already has been matched. When all such attempts prove fruitless, a different match for the source word itself is sought.
E. STATISTICAL
Use of the present word formats requires an average of two computer words for each descriptor. A SEAC word contains forty-four binary digits plus a sign digit. The example illustrated in Fig. 7, with its 1600 specific embodiments, was completely coded with fifty-two SEAC words.
Appendix C describes several test searches made by use of a manual simulation of the machine search.
F. STATUS OF THE SYSTEM
The generalized Haystaq program, which defines the search parameters, has been coded and debugged on SEAC (8, 11). It provides for searching com-
pounds, admixtures, and processes. Amplification of various areas of the program is now in progress. The program for searching chemical compounds in terms of functional groups, which has been described above, appears to have utility per se as a means of searching for individual compounds. By a slight modification, functions or uses may also be included. It is expected to make it an integral part of the generalized search program. At the time of writing, a flow chart for this part of the program has been completed and the machine instruction code is being written. It is hoped that significant results will be available for a report at the time of the Conference. Additional areas for future amplification include the element-by-element topological search (9) and the process search (3, 4). Tests of the searching system must be made to evaluate not only the logic of the system, but also the sufficiency of the various techniques provided in terms of how well they meet the users’ needs.
III. Looking to the future—A long range view
The second paragraph of the introduction gives a clue to the magnitude of the search problem in the U.S. Patent Office. A mechanized searching system which will meet all the needs of the Patent Office must make provision for satisfying the following criteria:
-
The ability to conduct a large number of searches every day, with no long delay interposed between question input and answer output.
-
An output convenient for direct application by the user of the search system. This implies (a) a convenient physical form of output and (b) no “false drops.” (False drops are wrong answers which result from ambiguities in the system.)
-
Files which can in effect be completely searched for each question. (See the section below entitled “Machines with Learning Ability,” part 1.) For the Patent Office, this has implications for the presumed validity of patents. For other users, the completeness of a search may bear on the question of whether a research project is warranted insofar as it does not represent a duplication of another person’s earlier work.
-
Expansibility of the system to permit insertion of all types of information into the library file and to permit relatively easy entry of newly created disclosures. The system must be comprehensive enough to permit any question to be asked, regardless of subject matter.
-
A relatively inexpensive and simple system, both as to inception and operation.
-
Ability to satisfy all the needs of the users. That is, all logical types of questions should be capable of being formulated and the series of answers put
-
out by the machine should reflect no “noise.” Inability to state a question precisely because of limitations in the system results in a broader or narrower question than is really intended. In the broader case, non-pertinent and therefore undesired answers, which constitute “noise,” are developed; in the narrower case, some answers may be lost.
A system of the magnitude required which can meet these criteria can result only from a concerted effort over a long period of time.
The argument that a large, complex searching system geared to the needs of large-scale users, such as the Patent Office, will not be the best solution for small-scale users, who might be satisfied with specialized but simpler systems, is analogous to the old argument for large, fast, expensive general-purpose digital computers vs. smaller, specialized machines. Since the Patent Office is concerned with all of technology, the Patent Office problem inherently includes every one’s technical literature searching problems. Even the Patent Office does not contemplate literally searching all its files for every question. (See the section below entitled “Machines with Learning Ability,” part 1.)
Many disciplines, seemingly unrelated to mechanized literature searching, must be developed far beyond their present state in order to provide some of the tools which will be used in formulating “the ultimate system.” Several related fields are briefly discussed.
A. PRINTED DOCUMENT READING
One of the most voluminous and demanding tasks in setting up a large searching system will be the preparation of the search file (the library file). An enormous expenditure of manpower will be required to analyze and encode the documents and to transcribe the codes onto a permanent storage medium. Since the effectiveness of the system will depend largely upon the accuracy and completeness with which the file is prepared, the importance of this task cannot be overemphasized. This job will ultimately have to be performed by machines if our long-range objectives are to be achieved.
Much work is now in progress in the design of systems of “character recognition” by machines. While most of the effort now being expended in this field is concentrated on the development of equipment which can recognize individual printed or written alphanumeric characters, progress is advancing to the point at which printed words can be recognized by machines and stored in their memories in an encoded form (12, 27).
B. THE MECHANICAL TRANSLATION OF LANGUAGES
This is also the subject of many investigations (13). It requires little vision to foresee a system incorporating the techniques of both the character recog-
nition and mechanized language translation arts. A printed document might be the input for a machine which “reads” the printed page, analyzes the words, sentences, paragraphs, etc., for their meaning and translates them into an encoded form of the original document suitable for machine searching. It is hoped that within the next decade such a scheme for preparing a mechanized searching file will be a reality.
In Appendix D there is set forth one prospective means for using machines to accomplish certain portions of the data preparation task.
C. MACHINES WITH “LEARNING” ABILITY
The concept of machines with “learning” ability has been the subject of much discussion in the past several years (14–16).
Three types of procedure which might be classified as involving quasi-learning by a searching machine are described:
1. Methods which enable the machine to make what are in effect complete searches without actually searching each disclosure in the file
(a) Use of the machine to break down a large file, into smaller classified files. Some people assume that a large file of documents encoded for machine searching should be physically separated into smaller classified collections in order to save a large amount of the time required for searching the entire file. This assumption should be considered in the light both of the nature of Patent Searching and the inherent limitations in “classification systems” which employ any of the schemes in which the units to be classified are entire documents.
This type of classification system generally involves a scheme, as in most manual classification systems, for physical placement of copies of documents. R.A.Fairthorne refers to such a scheme as “Parking” (17). Any scheme which makes use of document classification involves some sort of arbitrarily established rules of superiority. The ability to select a pigeonhole for a document has a certain nicety about it for the classifier. However, the searcher is frustrated in his attempts to retrieve all documents disclosing idea A because of a rule which states that if idea B is disclosed it takes precedence over all other ideas, including A. As a result, those documents which disclose both A and B are hidden from him. Cross-referencing to the A location is a partial solution, but, as will be shown hereafter, it is a practical impossibility to cross-reference any document sufficiently to provide for the needs of all searchers.
Some general characteristics of disclosures of documents, considered from the point of view of Patent Searching, are as follows:
-
All subject matter details of a disclosure are equally important because
-
any one or any combination of them may be the basis for a search. Subject headings are completely inadequate for the patent searcher.
-
All disclosed relationships among the small units of information are equally important for the same reason. Examples of such relationships are combinations, and all their included subcombinations, disclosures of equivalence, and negatively disclosed ideas.
-
Each concept disclosed may be described (and therefore should be approachable in searching) from a great many points of view, and each of these points of view has both generic and specific aspects.
In the light of all these considerations, a rigid classification of entire documents does not suit the needs of the patent searcher, since it inhibits his ability to synthesize the desired classification for each search. It should be noted that an enormous amount of labor is required to keep rigid document classification systems current. Havoc results (in apparently sound schemes) when new developments shift the emphasis from one phase of an art to another.
The argument for physically separating a large file into smaller files is based on the existence of broad, mutually exclusive, categories, such as chemistry and the mechanical arts. Should one be forced to examine a total document collection, including such disclosures as clothes washing machines, when his interest lies in a particular synthetic resin? Surprisingly (only to the uninitiated), the washing machine art may very well be a source of disclosures of synthetic resins which are used in the protective coating for the casing of the machine, or in the manufacture of the agitator element, the tub, the gears, or other parts, and these resins may be the very ones sought. It is impossible to estimate accurately the number of such hidden disclosures, but it is certainly a large number. All who have had experience with manual searching systems are familiar with the accidentally discovered disclosure found in an unlikely place in the classification scheme.
One plan which permits the mechanized searching of files which are smaller than the total collection would begin operations with a single, all-inclusive file. Records would be kept of questions searched by the system. As the total file grows (by the incorporation of additional documents into the system) to such a size that searches become burdensomely long, the records of previously asked questions could be analyzed to discover frequently asked questions involving common types of subject matter. It then becomes feasible, as the need arises, to set up a separate file of synthetic resin disclosures. This would be accomplished by using “synthetic resins” as the question, and having the machine copy all documents disclosing such subject matter onto another storage unit. The copied documents remain in the original file and continue to be available for search on the basis of other subject matter which they disclose. All future
searches for synthetic resins would be made on the smaller file only. Such searches would be equivalent to a complete search of the total file. Almost every search involves some concept which was never before made the basis of a search. A document answering one search may be completely irrelevant for another, and, conversely, those documents which were completely non-pertinent for all previous searches may be exactly the ones desired in a later inquiry.
(b) Learning by experience. A list of questions which have been asked previously can be stored, together with their answers and an identification of the last document inspected in the previous search. In making a search, the “previous question” file would be scanned first. If the question asked proves to be an old one, the previous results are printed and the search brought up to date by searching all subsequently entered disclosures. Where the question is a new one, the entire disclosure file is searched and the new results added to the stored list. This saves searching the entire storage file for every question. This proposal has utility only until such time as the search of the “previous question” file becomes unduly burdensome.
(c) Association of related documents. Encoded disclosures can contain information which leads from one disclosure to all related disclosures and therefore detailed searching is required of only those documents which have some pertinence to the question asked. Suppose that all documents containing the same information are figuratively arranged as points along a line. Following each code in each disclosure an identification of the adjacent document in the line would appear. Where two search criteria are specified, the search is for a disclosure which is at the same time a member of (1) the line representing all disclosures containing the first code and (2) the line representing all disclosures containing the second code. It is thus the intersection of these two lines that is sought. Since two codes may be desired in a single disclosure only in a particular relationship, it becomes necessary to select intersections of a specified type representing that desired relationship. For example, if the search is for A and B in the same composition, either A or B can be used as the initial basis for search. On locating the first document that discloses A, search can then be made in that document for the additional presence of B in the specified relationship to A. If B is not found, the information in the code for A will identify-the next document that includes A, and that document is searched for B. Should one document be located which fully answers the query, the “next document identifications” in both A and B are compared. The search proceeds to the one farthest removed. In other words, if the next B document is farther removed than the next A document, the B document is examined next and B becomes the primary basis for search, with A as the secondary search criterion. This method of searching involves locating one line which is perti-
nent, then examining only members along that line until a proper intersection between the correct lines is located.
2. Methods which enable the machine to find answers which the human searcher did not preconceive
In manual searching, when it is desired to find A and B in a particular relationship X (e.g., A is a fly killer and B is a solvent and the relationship is that they are in admixture in an insecticidal composition), the searcher is aware that such a specific disclosure may not be found in one reference. He therefore looks also for disclosures of A in combination with materials that are equivalents of B, as well as for disclosures of B in combination with materials that are equivalents of A. A reference disclosing A and C in X relationship, or one showing D and B in X relationship, is called a “basic reference,” or “one showing the general or basic combination.” A reference showing the equivalence of C and B in a G relationship, or one showing the equivalence of A and D in an H relationship, is called a “secondary” or “supporting” reference. If the requirement for A and B in an X relationship cannot be found in a disclosure, a combination of a basic reference and a secondary reference must be used.
A program could be written for a machine as follows:
-
The primary question, “Find A and B in the X relationship,” is given to the machine by the user.
-
The machine generates these additional questions: (a) Find A and anything having the function of B (e.g., Y) in the X relationship. (b) Find a statement of equivalence between anything (e.g., Y) and B, where equivalence means that they have the same function, and that function is the same as in (a). (c) Find B and anything having the function of A (e.g., Z) in the X relationship. (d) Find a statement of equivalence between anything (e.g., Z) and A, where equivalence is based upon the function of A, as expressed in (c).
-
Initially, the machine scans each document to determine whether it answers any of questions (a) through (d).
-
If (a) or (c) is found, the machine determines whether the primary question in (1) is answered; that is, that Y is actually B or that Z is actually A.
-
If the primary question is answered, the machine continues to search for answers to the primary question only, dropping questions (a) to (d).
-
If the primary question is not answered in (4), the search continues as in (3).
-
The machine prints separate lists of the documents found as answers for each question.
-
If there are no answers to the primary question, the machine correlates answers appearing on the (a) list with those on the (b) list to find all pairs of documents where Y is the same; a similar correlation is performed between the (c) and (d) lists to find those pairs of documents where Z is the same.
3. Methods which enable the machine to supply the best answer it can when a set of alternative questions is asked.
When it is desired to make a very specific search, the searcher keeps in mind the possibility that the exact answer he wants is not available. He therefore poses search questions which vary in scope from his specific question up to the broadest question which will satisfy him. Thus, he sets the outside limits, both most specific and most generic, which satisfy his needs, and he may include certain searches of intermediate scope as well. The most specific search could be made on the total document file, and should no answers be forthcoming a broader search could be made. This process would be repeated until the broadest satisfactory search is completed. If answers to any of these questions are found, no further runs are made, since the answers retrieved are the most specific available. Such a system of alternately asking questions of and receiving answers from the machine has been aptly called “conversing with the machine.” This would be a relatively time-consuming method of operation.
A more satisfactory approach, which would permit the machine to carry on a “monologue,” would operate in the following manner. Let a series of questions, A, A′, A″, A′″, and A″″ (listed in order of increasing desirability), be propounded at the beginning. The order does not necessarily reflect either an order of variation of the size of a combination or an order of variation of genericity.
Searching would begin with question A. If an answer to A is found, a determination is made as to whether it also satisfies questions A′ or A″, etc. Assume that the first reference found only answers A. The identification of the document is recorded and searching continues. Suppose that the next answer found satisfies A, A′, and A″. Then the answer previously found is discarded since a more desirable answer has been obtained, and questions A and A′ are dropped. The search continues on the basis of question A″. On locating the next reference, determination is made as to whether it satisfies only A″ or whether it also satisfies the more desirable A′″ or A″″. If eventually A″″ is located, the only answers given as output reflect A″″ disclosures, but if A″″ is not found, the most nearly desirable answer available is given. By using this approach, in one pass through the stored data answers would be obtained within the defined limits of the search as near the most desirable answer as is available.
D. THE FIELD OF LINGUISTICS
Several projects under way are concerned with structural linguistics (18–20). Analysis of sentence structure is a useful technique for determining the intended meaning of an ambiguous expression. In addition, there are many problems relating to the recognition of a single concept whenever it is expressed in diverse ways.
The development of a large-scale retrieval system will depend largely upon the results of long-term research in concept classification. That word classification has little significance is apparent when it is recognized that the “natural language” of printed documents will seldom, if ever, be found to be the best language for machine use. Languages are, after all, tools for the symbolic expression of ideas, and each language uses its own symbolism (the vocabulary) and grammar (rules for concatenating ambiguous vocabulary symbols to express particular, distinguishable concepts). It would be unexpected to find two such different kinds of entities, as are men and computer-like machines, “thinking” in the same language.
However, a humanly useful output from any machine system must be in a language which is intelligible to the human. In the case of a literature searching system, this might be in the form of a secondary type of output such as a bibliographic listing or an abstract, or it might be in a primary form, such as a printed copy of the document, a microfilm, a cathode ray tube display, a magnetic tape for audio presentation or the original document itself. Empirical bites into the linguistic problems have been made (in the program described in Section II) by the use of internal definitions, “look-up” features, and the possibilities of using unlimited numbers of 3A and 3B terms.
E. SOME MACHINE DESIGN PROSPECTS
In general, Haystaq can be regarded as an example of one general approach to a large-scale, mechanized literature searching system. As previously stated, it simulates to a large extent the search performed manually by a human searcher. No economic feasibility studies have as yet been made since this system is still highly experimental. It has been primarily an exercise in developing methodology in a field in which no guiding generalities have been established.
Large-scale systems which would be completely satisfactory are probably a considerable way from us. It is of interest to note that in one very large machine manufacturing corporation, research projects are considered to be short range if their probable duration is as much as three to five years. There are
pressures to effectuate crash programs for solving the information access problems. These must be deferred to, but the restricted long-term prospects for narrow-gauge searching systems must be kept clearly in mind (21). As has been the usual story in technological developments, not only must we walk before we can run, but we must also crawl before we can walk.
A look at probable trends in the foreseeable future and possible trends in the years further ahead follows. For the time being, we shall have to be content with machines that, in general, are improved versions of the presently known general purpose computers. These have been designed to handle either (1) mathematical problems (the so-called scientific computers) or (2) business management problems (the so-called data processing machines). The operations which can be performed are generally the same in either case, but the facilities provided in the former emphasize internal operating ability (since a relatively large amount of computation is performed on relatively small amounts of input data in mathematical problems), whereas the latter place more emphasis on input and output (since business problems generally require a relatively small amount of computation on each of many units of input data). However, since many problems are coming to light which require both large amounts of input and output equipment and fast internal operating speeds, the distinctions between scientific computers and data processing machines are not so important as formerly.
In contrast to these problems which deal with quantitative information, the literature searching problem requires a machine designed primarily for handling qualitative information. Recognition of specified small units of information and the complex webs of relationships among such units must be among the primary functions of this machine. Any computation performed in searching will be purely incidental. What is desired primarily is not arithmetic calculations but flexible matching ability. The “orders” available on a searching machine should be tailored to the job they are to do. Searching programs written for existing machines are handicapped by operating under the guise of mathematical processes, and this procedure involves many red-tape operations.
Present-day computers operate in a serial manner, one piece of data being treated only after another has been processed. Various schemes have been employed in different machines in an attempt to overcome this handicap. These include (1) overlapping the non-productive portions of two successive operations, (2) providing for simultaneous input, output and computations, (3) enabling the machine to carry out fully independent operations simultaneously in different parts of the computer and (4) providing faster operating input, output, and computing components. Until machine designers can provide us with real searching machines (and it is the responsibility of documentation
specialists to educate the machine designers on the characteristics desired in such equipment) all these techniques must be used.
A machine system which would facilitate searching (based on the present type of general purpose computers) might include a cascade of machines, employing non-fixed word lengths, having a choice of types of output, ultra-high speed input and internal operation, and certain types of quasi-learning features.
The cascade of machines referred to would employ special searching mechanisms for each of several parts of the search. Each machine would operate at a level of intensity somewhat greater than the previous one. The documents selected by the first machine on the basis of very broad criteria would become the input for the second machine. The output of the second machine (selected on a more intensive basis than the output of the first) would become input for the third, and so forth. For example, disclosures selected on the basis of general chemical criteria would be fed into a machine specialized for making topological structure searches. The output from this stage would become the input for a checkout routine machine. The output from this last machine would be fed into a microfilm reproducing machine to supply the user with the ultimate output of the system. If the criteria for the several specialized machines were properly selected, all machines could be kept operating in a gear train type of synchronization, the speed of operation of each machine being balanced against its own workload.
Ultimately we will have methods of searching literature by means of a fully mechanized system. Machines will be given copies of printed documents and will then proceed to prepare their own encoded library files. Searchers will be able to put their questions to the machine orally in a common, natural language. Much learning ability will be inherent in the system, so that as they become more experienced the machines will search more efficiently. The searching machines will be parallel machines, born and bred for their job. (See Appendix E and paragraph (j) of Appendix A.) At that time, we will have available an operating embodiment of the “automatic library” envisioned by Vannevar Bush (22, 23).
APPENDIX A Evaluation of literature searching systems
Mechanized literature searching systems may be described from many points of view. Descriptive factors may relate to (a) characteristics of the original document collection, including its physical attributes as well as the types and scope of included information, (b) the methods and tools for classifying, indexing, and encoding the document collection to prepare the search file, (c) characteristics of the search file, (d) the formulation of search questions, (e) searching and retrieval techniques, (f) the output of the searching operation, (g) the updating of the search files, (h) the searching machines, and (i) personnel requirements and economic factors.
Comparisons among systems must be based largely on their effectiveness in fulfilling the needs for which they have been designed. The success of a system, from this point of view, will depend upon several criteria. (1) The size of the file and the extent of its heterogeneity balanced against the frequency of use of the system and the complexity of question types will determine the degree of discrimination or resolving power necessary to separate wanted from unwanted disclosures. (2) “Noise,” resulting from undue breadth in the permissible questions and “false drops,” resulting from ambiguities in the system, can be tolerated only to the extent that they do not detract from the utility of the output to the user and to the extent that they do not deter the user from formulating the exact questions to which he must have answers. (3) The amount of detail used in describing concepts disclosed in the document file of a searching system will depend upon the needs of the users. (4) Sufficient flexibility in the logical types of questions permitted must be provided to satisfy users’ needs.
It is believed that when a retrieval system is to be designed, the following questions must be considered together with points (1)–(4) above.
-
Should the main approach to subject matter be on a statistical (i.e., probability) basis (as in all coordinate indexing systems) or on a precise basis? If the system is constructed on a statistical basis, how much redundancy is desirable? For re-entrant systems [see (h) below] using serial computers, a combination of statistical factors for “screening” followed by the use of precise factors for the ultimate selection appears to be desirable.
-
Should the organization of subject matter be based upon discrete units at varying levels of intensity or is a topological network of all disclosure factors preferable? Again, a combination of these approaches appears to permit question flexibility so that a user may ask his question in the form most indicative of his actual interest.
-
Should a limited number of “subject headings” (telling in broad terms what the document contains) be used, or should all subject matter details be included? Because a system designer cannot predict exactly what questions will be asked, he must provide for a multilateral approach to each document and make all the disclosed information details equally accessible.
-
Are the words used in a disclosure adequate to describe the subject matter, or must the concepts implied by the words of the disclosure be made available for retrieval?
-
Although the primary concern is for a literature searching system, will there also be a demand for such uses as “Information Retrieval” and “Browsing?” Any
-
literature searching system employing “encoding-in-depth” inherently includes in the search file the kind of data useful in an information retrieval system. A modification only of the type of output would be required to employ the file in this dual role. Browsing is based upon a philosophy which is basically different from searching or information retrieval, but the nature of search files is such that a searching system can be designed to provide facilities for browsing.
-
How much “noise” and what per cent of “false drops” are tolerable? It is not true that a large-scale searching system must have some degree of each of these disturbing characteristics.
-
Is it necessary to store the disclosures so that the original document can be reconstructed, or is it adequate to provide clues to the subject matter in the documents being searched? In part, the answer to this question depends upon the form of output provided and the use made of the output.
-
To what extent should the system be a re-entrant one? This refers to the ability of the machine to retain, manipulate, and compare various pieces of information presented to it at different instants of time. The answer is largely determined by the complexity of questions permitted and is limited by the type of searching machine used. Questions (a) and (b) are related to this one.
-
Should the file be static or kinetic? Hand-operated notched-edge card systems exemplify the former type, while any of the systems employing the ESM—101 with IBM cards is an example of the latter. Factors such as the time to make a search, the complexity of questions permitted, and the possible size of the file must be analyzed.
-
Should the system employ a serial or a parallel approach? No sound theoretical reasons exist which substantiate the passive acceptance by many documentation specialists of the concept that it should take more time to search a large file than it does to search a small one. Only the present-day absence of machine technology for large-scale parallel searching is lacking. Some systems provide for several questions to be asked simultaneously when one serial pass through the file is made (24, 25). The parallel system contemplated here does not involve parallel questions; what is contemplated is a parallel or simultaneous approach to all documents in the file. (See Appendix E.) In such a system, no prolonged interval need exist between the instant when the question is put into the machine and the instant when the output is obtained. Questions could be asked one after another at the same rate of input as data is fed into present-day electronic computers.
-
What types of logical subject matter systems must be devised to permit the formulation of all desired questions?
-
What are the costs involved in setting up the system? Initial costs include document accession, system development and programming, data file preparation, machine acquisition or rental, and the employment and training of necessary personnel. Initial outlays should be amortized over a reasonable operating period. A large first expenditure may be less costly in the long run than a smaller first cost for a system requiring extensive maintenance.
-
What is the cost per search for operating the system? The cost of updating the files, which must be considered as a continuing operation, must be added to the expense of performing a search.
-
In devising and setting up a full-scale system, how much time will be required before productive operation is possible? A system conceived along superficial lines
-
will lend itself to earlier exploitation, but will require more effort in the later incorporation of desirable features than if they had been included initially. Careful planning plus the provision for more detail and more logical ability than appear necessary in a first appraisal will generally be worth the investment in time required.
-
How long does it take to make a search and is that length of time satisfactory? Formulation of the question in machine language, programming the machine, actual running time, and obtaining the output in a usable physical form must all be taken into account.
-
How difficult is it for a user to frame a question? If the user must master a complex coding system before he can make use of the system, he is less likely to accept it and use it to best advantage. An educational program to acquaint users with the facilities provided by the system is required. A practical method of operation permits the user to state his question in common language, and a technically trained person, who is intimately familiar with the system, translates the question into the system language.
APPENDIX B Some exemplary types of questions
|
1. |
A or B or C |
where A, B, and C represent different specific compounds, any one of which will satisfy the question. |
|
2. |
A+B+C |
where A, B, and C represent different compounds which must be disclosed in admixture. |
|
3. |
abc |
where a, b, and c represent different aspects of a single compound. |
|
4. |
(a) abc or def |
similar to type 1, but each compound is described in terms of several aspects. |
|
|
(b) abc or abd |
where the two compounds have some aspects in common. |
|
5. |
(a) abd+def |
similar to type 2, but each compound is described in terms of several aspects. |
|
|
(b) abc+abd |
where the two compounds have some aspects in common. |
|
6. |
ab (without c) |
similar to type 3, but one of the stated aspects must be not present. |
|
7. |
ab (no c) |
similar to type 6, but the disclosure must positively exclude aspect c. |
|
8. |
a (without b)+ b (without a) |
similar to type 5, but the two compounds have no common characteristics. |
|
9. |
(A or B)+(C or D) |
where A, B, C, and D represent different compounds. Note that neither (A+B) nor (C+D) is requested. |
|
10. |
abc or ab |
First choice (abc) is a more specific concept than the second choice (ab). |
|
11. |
|
This is an example of a Markush structural formula. Neither is a valid answer. |
Types 12–15 represent processes, where A, B, C, etc., represent the various materials present in the different steps of the process.
|
12. |
|
|
13. |
|
|
14. |
 |
|
15. |
|
APPENDIX C Test examples ofHaystaq run on Simulac
The logical sufficiency of the flow chart for the system described in Section II was checked by manually simulating the activity of the computer on several test problems, each involving Markush structures. During such tests several errors in housekeeping operations were discovered and corrected. Code checking time on the machine is expected to be substantially reduced by this method of pretesting. Simulac is the simulation of an automatic computer on a blackboard.
TEST 1
(Question 1 has 1600 unique embodiments, Disclosure 1 has 48 unique embodiments, and hence the search of this disclosure by this question is the equivalent of 76,800 separate searches.)
Question 1:
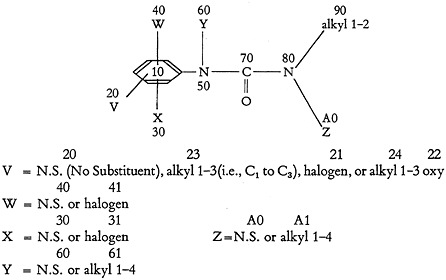
FIGURE 12.
Simulated print-out, test 2: No embodiment found:
Note. This was a “worst case” situation, no answer being possible, and none was found.
TEST 3
(Question 3 has 10 unique embodiments, Disclosure 3 has 8 specific embodiments and this search is the equivalent of 80 separate searches.)
Question 3:
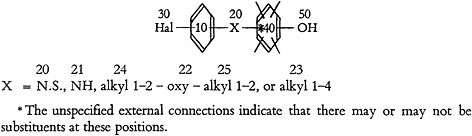
FIGURE 18.
Disclosure 3:
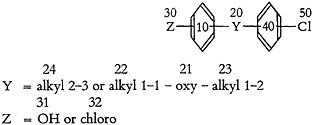
FIGURE 19.
Simulated print-out, test 3: Question embodiment:
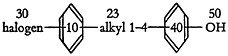
FIGURE 20.
Satisfied by Disclosure embodiment:
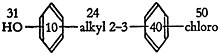
FIGURE 21.
APPENDIX D The use of machines as aids in the preparation of search files
Since the character recognition and mechanical translation arts are not yet sufficiently developed to permit machines to perform the entire job of preparing the search files from printed documents, we must make the best possible use of machines to help human workers perform this exacting and voluminous task. The following is one proposal for a contemplated method of data preparation to be used in the Haystaq system.
A technically trained person will read and analyze each document, note the portions to be encoded, and then prepare a formal abstract or summary of the subject matter. This abstract will indicate the organization of the various levels of disclosure, “index numbers” of the compounds (items) included in the several admixtures (compositions) disclosed, indications of the compositions involved in the various processes, the “accidental” descriptors, and indications of alternativeness, negation, conjunction and other relationships. (“Accidental” descriptors are those characteristics of a material which come to light only because of the environment disclosed for that item in the particular document being treated.) The subject matter of the abstract will then be encoded and transcribed onto punched cards.
Index numbers are unique numbers assigned to each specific compound contained within a collection. Each index number will be represented by an index card (one or more punched cards) which will contain (a) synonyms for the compound, (b) the index number, (c) the structural codes (the types used in 3C and 3D), (d) the empirical formula (computed by machine from the structural codes) and (e) the fixed descriptors (the types used in 3A and 3B). Such an index card will be prepared the first time that a compound is encountered in preparing the search file.
To compile the complete, encoded disclosure, the machine will record on magnetic tape all codes present on the abstract cards and intersperse in the proper places the codes from the appropriate index cards (except the element-by-element structure code). The tape so prepared will then be processed by the machine according to an “editing” program. This program will generate and insert into the code data for various “mechanical” screens as well as “housekeeping” information for use by the machine in performing the search. Following the editing routine, the encoded data will be checked for mechanical and logical errors by use of another computer program. Since Haystaq employs the element-by-element structure codes on a secondary tape, these codes will be similarly copied from the index cards in the preparation of that tape.
Question data will be similarly prepared.
In order to provide easy access to the desired index cards, an unambiguous filing system must be employed. It is planned to make use of one of the available indexing schemes which generate unique ciphers for each compound (26). Since these ciphers lend themselves to a systematic alphabetization, they can be employed in the manner of tabs on library catalogue card files to enable a machine to locate index cards which contain the detailed codes needed to supplement the abstract in preparing the complete search file.
APPENDIX E Some comments on parallel searching and memory devices
The system now being devised for tests on SEAC (and all other systems so far proposed) operates in such a manner that a limited number of questions is held in relatively fixed storage and the entire—very large—collection of permanent data to be searched is serially compared with the internally stored static questions. This is comparable to the FBI’s looking for a person whose characteristics they know by making the entire population of the country come to Washington and walk past the FBI building in single file.
A more desirable approach would be to keep the large volume of data to be searched in a static, fixed storage and to use the questions as input. Under such a system, the search would proceed directly from question to location of an answer (if any existed) in the static fixed storage. Questions would be asked serially in rapid succession and the output speed could be made to depend upon the speed with which questions could be propounded as input. This would be of the same order of speed as the input in the system first mentioned above.
By what means could the disclosure file be stored so as to provide truly parallel (i.e., simultaneous) access to all disclosures and permit instantaneous retrieval? Emphasis on memories providing large capacity, rapid access, and rapid retrieval has led to the development of a large volume of factual information concerning the characteristics of a variety of memory systems. More emphasis must be placed on determining the basic characteristics of memory systems in general. Research in this direction could well lead to the birth of systems radically different from any now contemplated. More consideration should be given to deriving systems which can provide unlimited polydimensional access to stored information. Presently available storage devices are relatively bulky in size and most of them are at best two-dimensional in character.
Some work has been done along the lines of polydimensional storage but a more intensive effort in this direction is needed. With the accent on research in solid state physics today, perhaps some investigations into the use of intersecting planes in a crystal, as a memory device, might be in order. Or perhaps some bright young scientist might investigate the use of complex wave forms as storage media and their response to question wave forms by (1) analysis and (2) subset or component wave matching. The area of “self-tracing cross-path systems” should be investigated since such systems offer a possible means for storing and retrieving complex types of internal relationships of disclosures. (See Section III, under “Machines with Learning Ability,” part (c), for one concept of a self-tracing cross-path system.)
It is desired to de-emphasize neither the importance of volume or cost in storage requirements, nor the speed of access and retrieval, since these are important economic factors. However, the economic aspects of this field should be considered secondary to the principal task of bringing to a higher state of maturity the relatively elementary electronic machines of today as tools for information retrieval and literature searching. The “automatic library” of Bush (22, 23) and other men of vision must be capable of being embodied in some usable form if the results of human investigations in the realm of science are to be made available to further workers in the field, and the concepts mentioned above must be pursued before this end can be attained.
REFERENCES
1. METCALFE, J., Information Indexing and Subject Cataloguing, The Scarecrow Press, Inc., New York, N.Y., 1957.
2. NEWMAN, S.M., Problems in Mechanizing the Search in Examining Patent Applications, Patent Office Research and Development Report No. 3., Department of Commerce, Washington, D.C., 1956.
3. LANHAM, B.E., J.LEIBOWITZ, and H.R.KOLLER, Advances in Mechanization of Patent Searching—Chemical Field, Patent Office Research and Development Report No. 2, Department of Commerce, Washington, D.C., 1956.
4. LANHAM, B.E., J.LEIBOWITZ, H.R.KOLLER, and H.PFEFFER, Organization of Chemical Disclosures For Mechanized Retrieval, Patent Office Research and Development Report No. 5, Department of Commerce, Washington, D.C., 1957.
5. BAR-HILLEL, Y., A Logician’s Reaction to Recent Theorizing on Information Search Systems, American Documentation, 8, [2], 103–113 (1957).
6. LUHN, H.P., A Statistical Approach to Mechanized Literature Searching, International Business Machines Corporation, Research Center, Poughkeepsie, N.Y., Jan. 20, 1957.
7. PERRY, J.W., and ALLEN KENT, Documentation and Information Retrieval, Interscience Publishers, Inc., New York, 1957.
8. PFEFFER, H., H.R.KOLLER, and E.MARDEN, A First Approach to Patent Searching Procedures on Standards Electronic Automatic Computer (SEAC), Patent Office Research and Development Report No. 10, Department of Commerce, Washington, D.C., 1958.
9. RAY, L.C., and R.A.KIRSCH, Finding Chemical Records by Digital Computers, Science, 126, 814–819 (1957).
10. OPLER, A., and T.R.NORTON, New Speed to Structural Searches, Chemical and Engineering News, 34, 2812–2816 (1956).
11. Digital Computer Newsletter, Journal of the Association for Computing Machinery, 4, [4], 547–548 (1957).
12. HATTERY, L.H., Public Administration Review, 17, [3], 159–163 (1957).
13. LOCKE, W.N., and A.DONALD BOOTH, Machine Translation of Languages, The Technology Press of the Massachusetts Institute of Technology, Boston, and John Wiley and Sons, Inc., New York, 1955.
14. WILKES, N.V., Can Machines Think? Proceedings of the I.R.E., 41, [10], 1230–1234 (1953).
15. SHANNON, C.E., Computers and Automata, Proceedings of the I.R.E., 41, [10], 1234–1241 (1953).
16. FRIEDBERG, R.M., A Learning Machine: Part I, IBM Journal of Research and Development, 2, [1], 2–13 (1958).
17. FAIRTHORNE, R.A., The Patterns of Retrieval, American Documentation, 7, [2], 65–70 (1956).
18. NEWMAN, S.M., Linguistics and Information Retrieval: Toward a Solution of the Patent Office Problem, Monograph Series in Linguistics and Language Studies No. 10. Georgetown University Press, Washington, D.C., 1957.
19. NEWMAN, S.M., Linguistic Problems in Mechanization of Patent Searching,
Patent Office Research and Development Report No. 9, Department of Commerce, Washington, D.C., 1957.
20. Electronic Computer Study of English Syntax Patterns, Technical News Bulletin, National Bureau of Standards, 41, [6], 84–86 (1957).
21. SHERA, J.H., Research and Developments in Documentation, Library Trends, 6, [2], 187–206 (especially p. 202), (1957).
22. BUSH, V., So We May Think, Atlantic Monthly, pp. 101–108, July, 1945.
23. BUSH, V., For Man to Know, Atlantic Monthly, 196, [2], 29–34 (Aug., 1955).
24. BAILEY, M.F., B.E.LANHAM, and J.LEIBOWITZ, Mechanized Searching in the U.S. Patent Office, J. of the Patent Office Society, 35, [7], 566–587 (1953).
25. OPLER, A., Dow Refines Structural Searching, Chemical and Engineering News, 35, [33], 92–96, (1957).
26. Which Notation? Chemical and Engineering News, 33, [27], 2838–2843 (1955).
27. Seeing—Eye Computer, Time, 71, [11], 61, (1958).






































