
Abstract Theory of Retrieval Coding
CLIFFORD J.MALONEY
1. Introduction
The current feverish tempo of research activity in document retrieval has been accompanied, if not caused, by three other developments, (1) a rapid increase in the record to be controlled, involving new terminology, taking new forms, and appearing under widely dispersed auspices; (2) an increasing need to employ finer detail, to incorporate the new terminology more promptly, and to retrieve documents from unanticipated points of view; and (3) technical developments in the area of information theory, of information processing equipment, and in library science and its tools.
Proposals for more efficient and more powerful literature retrieval have taken a number of different forms. The present paper involves an attempt to develop a general theory adequate to afford a basis for an objective comparison of alternatives. While its main focus is on superposition coding, attention must be directed to virtually all phases of the problem because of their bearing on the superposition aspect.
The paper is concerned with developments involving the application of information theory considerations to the design of mechanical document retrieval systems, particularly those embodying superposition coding. A preliminary discussion of this problem was presented by title at the 1954 Annual Meeting of the American Statistical Association in Montreal, Canada. A description of a specific machine retrieval system whose development motivated the present study has appeared in American Documentation (1).
2. Outline of problem
The overall documentation problem involves: (1) the acquisition and preservation of documentary items, (2) the reception of requests for items involving subject matter and incomplete bibliographical description (or none) and the
CLIFFORD J.MALONEY Fort Detrick, Maryland.
identification of the item from this description (largely the subject matter) and (3) fulfilling the requests, by supplying copies on loan, microfilms, bibliographies, abstracts, or in other ways. The present paper is concerned only with the second stage. Before the advent of mechanical aids (including edge-notched cards), subject control of documents proceeded largely by the proliferation of an ordered set of index entries, primarily in card form. It was recognized that a considerable element of “scanning” or “searching” remained, however. The early machine developments, particularly the edge-notched cards, led to greater stress on scanning and less (or none) on preordering of the file, though this latter has always been an essential ingredient in the C.B.C.C. system.
Unfortunately, no scanning system so far developed has had such a high scanning rate at such a low cost that complete dependence could be put on this approach, though one has been projected (4). Current trends of technical developments seem to emphasize the perfection of “random access” storage facilities, which, then, may reestablish in the new machine technology some, at least, of the advantages of ordering afforded in the traditional card catalogue.
The long scanning period of currently available equipment and its cost, on the one hand, and the preparation and storage costs of complete card indexes on the other, have led to a study of superposition coding by Mooers (5), Wise (6), and Isbell (7). These authors use somewhat different approaches, and each differs from the one under study locally (1). A general theory seems appropriate to compare these and other approaches.
3. Information theory analogue
The analogy of this problem and that encountered in communication has been frequently noted (1–3), but it is believed that attention has usually been directed to the wrong point in the communication analogy. In the latter a “source” produces a “signal” which is coded, transmitted, decoded, and received as shown in Fig. 1. It is believed fruitful to consider that the problem which superposition coding attempts to solve is that of coding a signal source whose
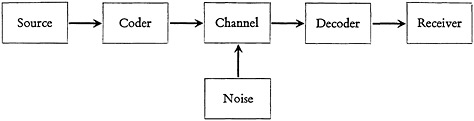
FIGURE 1. Schematic diagram of idealized communication channel.
rate of signal generation exceeds the channel capacity, and that the resulting equivocation is due to the form of signal compression by the encoding process adopted, not to channel noise. Its communication theory analogue would then, more accurately, be cross talk. Noise interference exists, of course, produced by human and machine errors in the operation of the system.
One consequence of viewing superposition coding as a signal encoding problem is that it raises questions of (1) whether other previously unthought of devices are also possible, and (2) the relative efficiencies of various forms of superposition coding. It will be shown that superposition coding is the only possible signal compression system involving the use of two-state devices, though it can be generalized when multistate devices are employed. By contrast, noise must be taken as given.
4. Building blocks
Subject retrieval of bibliographical items involves an informational content expressed in a written or at least recorded form of a specific language, or system of symbols. A purely formal treatment would start with this material (including punctuation, word order, alphabets, and type styles) and derive all details in successive steps. When applied to spoken language, this procedure has been worked out rigorously (9). Some work has been done on the written form of the language (10), though relatively little. Yngve (11) has done work paralleling the work of structural linguists, apparently independently.
What this work shows is that the “meaning” of any sign or sound complex is given by the set of all contexts in which the complex is found. The length of context to be considered in any case can be taken as the minimum length common to repeated occurrences. Different sign or sound complexes which share all contexts are identified, in the case of sounds into phonemes and then morphemes, in the case of written text into letters or diphthongs and then syllables and words. The resulting words, idioms, and phrases, together with punctuation, type style, and word order, express the entire information bearing content of the text.
The retrieval problem (step 2 of the first paragraph of this paper) consists of selecting from the total information-bearing content of each document a fraction sufficient to identify the utility of the document on the basis of later subject enquiries. In general, punctuation and type styles are ignored. Further, “little” words are in most contexts without interest. Some difference of opinion exists as to the value of ignoring grammatical form and word order. These points will be discussed more fully.
The result of this step is that the information content of each document is
given by a selection of words, for which grammatical form may or may not be distinguished, and among which word order may or may not be differentiated.
5. Abstract definition
A general theory must necessarily be able to treat all possible, or at least a large proportion of various coding systems. Further, the several systems should correspond to natural transformations of the theoretical model. Finally, few uninterpretable conclusions should result, though such examples are by no means unknown in applications of conventional mathematical disciplines. Explicit formulation of the document retrieval problem may proceed as follows. To each document in the file assign a “token” A, B, C, D, etc. No two tokens will be identical, since then the documents would be identical. A particular retrieval operation will consist of specifying or enumerating some subset of the totality of tokens. Call this operation a selection. A selection is a specification of the subject matter characteristics of wanted documents in terms of the properties of a query token. Now, in applying the selection to a particular record token, say H, it may or may not be possible to decide whether or not the selection criterion is fulfilled, i.e., whether or not the document is wanted, that the law of excluded middle applies in a somewhat extended (or distorted) sense. Critics affirm that this condition is widespread in conventional subject catalogues. Such a system will be considered “inoperable.” The system may be made operable in either of two ways. The tokens and the selections may be so revised that a decision becomes possible in all cases. Or the rule may be adopted that all cases of doubt are to be selected (or rejected). Selecting all doubtful cases appears a reasonable solution in a document retrieval situation, provided they are not numerous, since the selected documents are to be subjected, at relatively little expense, to intelligent human scrutiny.
By either device it will be assumed that given any selection S1 and any token G, it is possible to tell whether or not G meets the selection criterion S1. Let S1 in turn be applied to all the tokens in the system. Then the universe of tokens will be divided into two sets, the selections and the rejects. Let the class of selections be represented by A1 (for admitted) and the class of rejections by R1. Then every token is a member of either A1 or R1, but not both.
Next, let a second selection S2, also with the excluded middle property, be applied to the collection of record tokens. S2 forms two classes of tokens, A2 of selections and R2 of rejections. Now, it is possible that S1=S2 in the sense that A1=A2, i.e., they select the same concepts and hence the same documents containing those concepts and then R1=R2 and the two selections reject the same documents. A retrieval system in which every selection Si selects exactly
the same documents is of course trivial. Let then S2 denote a selection in which A1≠A2. It may be true that A1⊃A2, i.e., all tokens in A2 are in A1, or A2⊃A1 or that A1 and A2 each include tokens not included by the other (whether or not they include tokens in common). To make progress we will need two further assumptions. Assume that the tokens of the retrieval system include all the selections that will be (or may be) used; that is, that if a token appropriate to a document should appear to be precisely equivalent to a selection provided for by the system, the concept could be entered into the system and would have that selection for token. Then S2 is a member of either A1 or R1 and S1 is a member of either A2 or R2. It is a matter of notation to assume that S2 is in A1. Of course it is in A2. Moreover, all tokens in A2 are wanted when the selection S2 is used, and S2 is wanted (is in A1) when S1 is used. It appears plausible that all of the members of A2 and not merely S2 are wanted when S1 is the selection, and we will take it as our second assumption. This assumption is rendered more plausible on consideration of the meaning of the statement S1 selects S2. In a retrieval context this must mean that S1 is a broader subject than S2, so that S2 is relevant to its treatment. Now, all documents selected by S2 are special treatments of the topic of S2, hence also of the topic represented by S1. The selection relation thus has the three properties.
Si selects Si (1)
Si=Sj if, and only if, Si⊃Sj and Sj⊃Si (2)
If Si selects Sj, and Sj selects Sk then Si selects Sk (3)
Next, assume that every record token J appears in the set of selections; that is, every request is expressed in exactly the form in which some concept is or can be entered into the record. Then, the set of record tokens and the set of selections are isomorphic and each forms a partially ordered set (12). This result is normally accepted implicitly.
Two selections may be adjoined to the set, if not already included. The null selection selects no documents, and the universal selection selects all. With these two members added (if necessary) every “operable” retrieval system forms a lattice (12).
6. Mathematical model
In order to further study the abstract retrieval system defined in Sec. 5 an analytical representation is appropriate. On the basis of the structural analysis mentioned in Sec. 4, assume that all concepts in the system can be arranged in several sets or vectors
(X1, X2,· · ·Xm)
(Y1, Y2,· · · Ym)
(Z1, Z2,· · ·Zm)
etc., where each member in any one vector can be substituted for each of the other elements in at least some contexts and give a meaningful expression (though presumably with an entirely different meaning). By assigning each “meaning” to a particular position in one of these vectors, any given concept can be expressed by assigning unit value to its associated position and zero everywhere else. The concept Xi becomes
(0, 0, 0· · ·0, 1, 0,· · ·0)
A vector with a single unit and all other components zero will be called elementary. The zeros and ones are of course mere arbitrary signs at this stage, and in particular are not to be endowed with any numerical properties. Dashes could have been used for absence of concepts and a check mark for presence. Or the ones can be thought of as tally marks. The numerical quantities are used in the text because they will shortly be endowed with their usual properties. Likewise the expression “vector” is a mere name and endows these objects with no vector properties.
If one concept is followed in some context by a second concept from the same vector, or from another vector, this ordered pair of concepts can be symbolized by the matrix obtained as the axial product of the two vectors. The term axial product is being used to indicate that operation on two vectors, (or higher dimensional arrays) where elements are obtained as all possible products of pairs of quantities, one taken from the first vector and the other from the second. The arrangement in a two-dimensional array is merely mnemonic. Having regard to the non-quantitative role of the vector elements at this stage, the axial product of vectors can be regarded as the two dimensional tabular display formed by writing one vector across the top and the other vector along the left margin, and placing a unit (or check mark) in that cell which has a one both at its head and in its left margin, merely as an indication of joint occurrence. There will clearly be only one such instance. The axial product will appear as the matrix

Matrices of this form will be called elementary matrices. The ordered pair of these same two concepts in the reverse order would be symbolized by the transpose of the above matrix.
An ordered triplet would be symbolized by a three-dimensional matrix or tensor, obtained as the axial product of a vector and a matrix (or three vectors). In the same way mth ordered relations would be represented by m-dimensional tensors, containing a single unit in one cell and zeros everywhere else. The contents of any item in a document collection may be represented by a set of such tensors. If all the relations referring to a document are not of the same dimension or rank, each can be built up to that of the highest dimensional one by inserting zeros on added axes.
On the other hand, the argument of this paper can be followed adequately by thinking of two dimensional arrays, or matrices, only. Further, the matrix or tensor form is introduced for its suggestive power and to facilitate calculation by the rules for tensors. The arrayed collection of zeros and ones will normally be arranged in a linear or two-dimensional pattern for actual entry into the physical retrieval system.
In any retrieval system each of these tensors will be encountered with a certain frequency pt where
(4)
Each tensor can be thought of as a “message” in the retrieval system.
The number of possible tensors is enormous. Most will never occur. Shannon’s channel capacity theorem says that it is possible to replace each by a “code” so that a maximum “transmission rate” is achieved. In the retrieval context the notion of “minimum message length” is more natural. To achieve minimum message length, however, in effect, requires a “memory” adequate to hold all possible tensors and their code “equivalents,” say a serial number in the order of frequency of occurrence. This memory demand is impossibly great (as is in fact true in the communications case). Actually, it would be necessary to provide in the “code dictionary” for every permutation of the axes, since a prescribed order will not be available. The physical form of the “memory” in traditional library systems is the card catalogue. In mechanized systems it may be a file of punched cards, reels of magnetic tape, Minicards, etc.
The retrieval system design problem then is to so balance the three factors (1) “memory” or file size, (2) “message length” or searching time, and (3) equivocation or unwanted items that an optimum balance is obtained.
7. Tensor combinations
It has been indicated how relations of any complexity can be represented as m-dimensional tensors, with a single unit in one cell and zeros elsewhere. The linearized form of such a tensor would be extremely long, and hence the consequences of reducing the size is of interest.
A first simplification is possible. The representation of a document in the files is constructed in terms of a sequence of mth order tensors. It would be entirely possible to place all tallies for a given document in a single tensor, which would then have units or tallies in several cells, and zeros in all other tensor positions. Now, it is clear that this consolidation can be reversed and the several component tensors be written separately, given only the combined result, except that we will not know the order in which they originally appeared. If then, the dimensions of the tensors are sufficiently great so that no residual contribution from context is relevant to the retrieval problem, we can consider that the contents of a document are given indifferently by an unordered collection of elementary tensors (i.e., tensors with a unit in a single cell and zeros elsewhere) or by a single tensor with units in several cells and zeros elsewhere.
The analogy of the process by which mth order relational tensors were formed with axial multiplication has been previously noted. The analogy with tensor addition of the aggregation of the several tensors relating to one document with a single tensor of the same rank, but no longer elementary, is immediate, and suggests assigning the zeros and ones their normal numerical roles. In this connection it may be noted that just as in tensor addition, the element in the ijkth cell of the sum depends only on the elements in the corresponding cells of the summands.
Before completing the identification of our zeros and ones with those of arithmetic, the selection process should be examined from this point of view. In tensor language we will be given a “record tensor,” i.e., one from the files, and a “selection tensor,” i. e., one expressing the concept sought, and we will wish to decide whether or not the record tensor meets the selection criterion. If both the record and the selection tensors are elementary, we can select by identity. If, however, all elementary tensors relating to a document have been consolidated into one by tensor addition, the equality criterion will cause rejection. If attention is directed to the one cell of the elementary selection tensor containing a tally, it is clear that the document is wanted if the corresponding cell of the record tensor contains one or more tallies, otherwise not. In logical terms this means that, if the “class” of tallies in that cell of the record tensor “includes” that in the same cell of the selection tensor, selection is desired. In numerical terms this desired result is effected by the ≥relation. If we indicate the number of tallies in this cell of the record tensor by r and the corresponding number for the selection tensor by s, then the selection criterion is
r≥s (5)
In this case, r and s are necessarily unity, but a general symbol is desired for the argument to follow.
Since the selection tensor has zeros in all its other cells, relation (2) is necessarily satisfied by them all. Hence, we can apply the criterion to the record and selection tensors as wholes.
At this stage it is presumed that any query that may be phrased is represented by an elementary tensor in the system, hence that, in all cases, the selection rule can be
R≥S (6)
where the elements of the tensors R and S are positive integers or zero, and S is elementary.
It should be noted that, despite the fact that the inclusion rule and not the equality rule has been used for selection no false selections or “drop-outs” are obtained. This is due to the fact that each unit or tally in the record tensor unambiguously signifies a complete concept. If the tally is present in that cell, the concept is discussed in the document concerned irrespective of its other contents. There is then a reduction in file size (represented by the number of tensors in the system, which by this process has been reduced to the number of distinct documents) without causing false drop-outs. Tokens for the individual record tensors would, however, be extremely long, consist almost entirely of zeros, and have a high level of redundancy.
There is another price. When each document was represented by a full set of distinct elemental tensors, selection could be by the equality relation. Hence, all elements in the selection tensor could be specified. Accordingly it was possible to order the record tensors. When the latter are combined into a single nonelementary tensor, such tensors being brought together by addition of each of their several unit cell entries, a uniquely determinable order is not possible and selection must be by searching.
Generic searches are possible in either situation if elementary tensors designating genera are introduced into the system, or if searches are made on every species in the sought genus.
8. Uniqueness of the selection process
In Sec. 7 we established in terms of a tensor model of a document retrieval system that any “operable” system must constitute a lattice, the same result arrived at in more general terms in Sec. 5. Accordingly, any conclusions arrived at by study of the tensor model employing its lattice properties only, necessarily hold for any possible retrieval systems. In the tensor model, we actually are presented with two isomorphic lattices, one of the record tensors
and one of the query tensors. The two are related by a “selection” operation, the ordinary ≥of arithmetic. As this relation is uniquely applicable to a lattice, any other selection relation would have to be isomorphic to it.
We have further seen that it is possible to combine separate record tensors relating to a single document, and yet retain unique selection under the ≥relation. In the tensor model this combining operation takes the form of tensor addition. In order to permit combination, or addition, of tensors of different dimensions or rank, the operation of bordering the smaller tensor with zeros is introduced. Such tensors will be called “augmented.” It is clear that it is still possible to border tensors with zeros even though the tensors to be combined are of the same dimensions and rank to begin with. If this is done we get what is analogous to, but not quite identical with, the “outer” sum or “direct” sum of the tensors.
The direct sum of A and B is
while the direct sum of B and A is
It will be seen that the direct sum is thus order preserving. From the sum we can recover, not merely the separate addends, but the order in which they entered the sum.
This device, however, has no attractiveness as a method for reducing the size of a retrieval system. For the order of the sum is the sum of those in the addends, and the number of elements increased, not decreased. Let A and B be bordered by zeros in such a way that they become:
then the ordinary matrix sum becomes
This result (which we are calling the augmented sum) possesses all the properties of the direct sum of matrix theory under addition and subtraction (or selections). From one point of view it can be regarded as merely a different way of writing an ordered set of individual tensors, since the number of elements is unchanged, and all the information in the separate set is retained in the sum.
We have shown that record tensors in a retrieval system may be combined by addition and by “augmented” addition. We now show that no other combining rule is possible, or more properly that any such rule must be equivalent. For, let A and B be combined by any rule to produce C. Now C must be selected when either A or B is used as query. If C is of different order from A
and B it must be of higher order, and cannot exceed the sum of their orders. For if of lower order the relation R≥S would not always hold even if R were bordered before the operation, and if of higher order, excess capacity would be present in the record tensors which would never function in selection. Hence, C must contain a unit in the same cell as A does, augmented if necessary, and the same for B, though the border zeros will be added to B in a fashion appropriate to this comparison. If C contained a unit in a cell corresponding to neither that for A or B, it would be selected by a query tensor, say D, to which the document did not relate. As this undesirable result buys no compensating advantage, such a combination rule for A and B would necessarily lower the efficiency of the system, and in that sense summation, ordinary or augumented, is the only combination rule applicable to the tensor representation of a retrieval system.
9. Tensor reduction
The preceding discussion concerned one way in which the “memory” or file size of a retrieval system might be reduced by reducing the number of tensors relating to any one document at the cost of introducing a new operation, file searching. This new operation, in the present state of technology involves equipment which is bulky, expensive, of low capacity, and/or time-consuming. Progress in reducing these limitations is proceeding rapidly. But, the present discussion, being theoretical, applies, so long as the searching process has not been reduced to the vanishing point.
The preceding section described how the file size or memory requirement of a retrieval system could be reduced to one tensor per document. Further reduction therefore can come only from reduction in the size of the individual tensors. Four devices are of common application in reducing the capacity requirements of individual tokens in a retrieval system, which in the present model means reducing the size of the individual tensors.
The first is merely to restrict the system to a special purpose. This has the effect of eliminating a number of items from the axial vectors altogether, and hence reducing their order. It reduces the retrieval problem involved to the same extent, thus making correspondingly less necessary the other tensor size reduction devices. The cost is that the special code resulting is not compatible with general codes or with other special codes, thus making accession separate operations in each system. The advantages of centralized cataloging and/or broad classification as tools in acquisition have not been clearly demonstrated in the present manual organization of documentation, but this conclusion does not prejudice their suitability in a machine system. The device of special classi-
fication is otherwise largely out of the hands of the system designer, being a function of the nature of the retrieval design problem, and not a tool to be used in its solution.
The second tensor size reduction process also results in axial vectors of smaller order and involves entering species under suitable genera eliminating from the system provision for indicating the dropped species. This device too reduces the order of the axial vectors.
A third common procedure is to truncate complex relations to binary, or triadic relations. This has the effect of restricting the dimension or rank of the record tensors to matrices or tensors of rank three (or whatever). A relation involving more terms would be reentered until all terms appeared.
The fourth simplification is to ignore the distinction between relations exhibiting the same concepts, but in different order. Here, instead of eliminating vector components, or axes, we instead must seek the analogue of the process in adding units to the tensors in the system. In fact, a unit will be given for each point which can be reached by employing the axes in all possible orders. A three-element relation would thus lead to 3!=6 tallies or entries in the record tensor.
All three of the other tensor simplification devices can be viewed from this point of view as a unifying principle. Dropping components in a tensor can be viewed as entering a zero for this term in all record tensors. The terms will of course then have no selective power which is the consequence of dropping them from the system. Entering species under genera is equivalent to entering a unit in the genus, and zero in all its species wherever any one of the species is encountered in classifying a document. Dropping axes is equivalent to entering zero in every cell of the dropped portion of the record tensors.
Conversely, we can disregard completely the model relation which these tensors bear to record tokens in an informational system and ask: “What natural rules would lead to accompanying entry of tallys in tensors by a set of symmetrically arranged satellite entries?” It is clear that one such rule would be to make entries in every tensor in some specified point, line, or plane wherever any tally is called for anywhere. This is a generalization of restricting the scope of the system. Another rule would be to enter zero in points, lines, or planes, but the identity of the last varying accordingly to the location of the tally entered in the given record tensor. This rule includes entering species under genera and limiting the rank of record tensors. Finally, each tally can be accompanied by a cluster of points not all in any point, line, or plane. If this cluster is a “regular” one, it correlates with disregarding order in the relation entered into the retrieval system.
In summary then, adding zeros in cells of a theoretically conceived relational
tensor according to specified rules endows the set of tensors with the same informational properties as a retrieval system limited in an isomorphic fashion.
The consequences of these restrictions on the retrieval system in making selections in that system may be examined in purely mathematical terms on the modified record tensors. It is found that no essentially new device will be produced. This is a tribute to the ingenuity of preceding library and documentation investigators. If valid, the present essay establishes that procedures radically different in principle would appear to conflict with seemingly essential characteristics of an informational retrieval system.
In each case there is a loss of the ability to make sharp distinctions in retrieval. It is presumed that the distinctions lost are of lesser importance than those retained. This effect may be due to two entirely different characteristics of the process. On the one hand, it may be true that only one of the amalgamated record codes occurs with any frequency, or at least, when retrieval is conditioned by additional specifications. Thus “animal as a friend and companion” suggests a horse, dog, or cat when viewed as a friend of man, boy, or old maid. The numerical measure of this redundancy is given by the summation of the frequency of occurrence of the unwanted items.
(7)
where j is the one item in the combined group which is desired.
A second way in which the loss of discriminating power is not too great is that the amalgamated classes are all at least related and hence may be worth examining for possible relevance.
There will be no false drop-outs or selections owing to chance whether all truncated tensors are combined by augmented or ordinary summations.
10. Coordinatization
Preceding sections have outlined a procedure employing a system of tensors as a model of any possible retrieval system. The number of bits required to hold each tensor is given by the product of the orders of the dimensions. Both order and dimension can be reduced by (1) restricting the field of applications of the system, (2) use of generic terms, (3) limiting the degree of relationships in the system. All tensors relating to one document can be combined into one by tensor addition without loss of discriminating power, but at the cost of requiring a searching operation in retrieval.
Returning to the consideration of the separate tensors in which order is distinguished, each will consist of Πdi cells where di is the order on the ith dimension, each cell containing a zero except for one cell, which will contain a
unit. It is of course universal to choose a different form of record, which we will regard as a coordinatized form of these tensors. Instead of a single tally in one cell of an mth dimensional vector, a tally will be entered in each coordinate vector of the tensor. The bit requirement is thus lowered from Πdi to Σdi, and now m tallies are used rather than one. Queries must be expressed in the same form, of course, and will consist of m vectors, each with a single unit. So long as the coordinate vectors relating to one concept for each document are kept separate, no random or specious drop-outs occur, and this still holds after augmented addition.
If order is not distinguished, each coordinate vector will have m tallies rather than one, and selection will produce analogous results to the extent that a query for any order will select records from the file for all possible orders. Whether this is tolerable or not depends on the given system. Mooers (5) has shown how to avoid this consequence if worthwhile. If the present system is a general one, Mooers’ device must fit into it.
The linearized form of the full tensor representation which, it will be recalled, has a tally in a single cell, and zeros in all others can be viewed as a form of direct coding. The consequence, that neither augmented nor ordinary summation leads to false drop-outs in this circumstance shows that as long as concepts can be entered into a system as a single tally, by direct coding, false dropouts will not occur.
When however, the coordinate representations for each of the several concepts relating to one document are combined by ordinary addition, the phenomenon of false drop-outs arises. We have not strictly speaking defined ordinary summation of the coordinatized form of a tensor, but will do so as the ordinary addition of corresponding coordinates. It is immediate that this operation retains the properties needed in a retrieval system.
In a lattice the union of two elements A and B is not unique and may be obtained as the union of two other elements C and D. As the union has the ordinary inclusion property with respect to any element leading to it, the union of A and B includes either C or D, and vice versa. This, in the retrieval situation, is the false drop-out phenomenon.
A preliminary operation is available prior to coordinatization of the retrieval tensors. If two (or more) vectors are combined not by axial multiplication but by the conventional form of direct vector sum, the result is a vector of order equal to the sum of the orders of its factors, and which provides for dyadic relations (or the dyadic prefix of higher degree relations). This is the mathematical representation of what Mooers does.
Finally, what is really the converse of this process, the positions on any axis can be grouped arbitrarily according to some rule, and tallies placed in a posi-
tion within each group to designate each concept for that axis. Since, again, single concepts are represented by multiple entries, ordinary addition will lead to false drop-outs on the criterion.
Multiple tallies may be assigned to single (if complex) concepts in either of two ways. If done arbitrarily, attention can be given to minimizing coincidences upon ordinary summation, which means minimizing false drop-outs. If done according to some rule, one rule can be to convert the lattice into a serially ordered set (which we know can always be done). That conversion may be accomplished by classing together all elements for which the lattice relation holds, then arbitrarily choosing a new element, not in the chain, and forming a new chain, and continuing until all elements are in some chain. Then the chain can be numbered serially, and the number of any element will be given by the number of its chain, and its position number within the chain. If now chain numbers are direct coded, then they will not overlap on ordinary summation and hence false drop-outs will not occur as to chain number on selection by ≥. This will be a classified code.
11. Derivation of drop-out percentage
Treatments of the problem of the number of drop-outs which will occur under superposition coding are given by Wise (14) and by Mooers (5). Following Wise, let
X=number of concepts entered in the record
H=number of positions in coding subfields
G=number of positions with an entry
Y=number of subfields
Fd=“dropping fraction” or number of selected record
M=number of concepts specified by a query
Wise gives the formula for the number of drop-outs, assuming (1) random coding of concepts, and (2) random association of concepts in documents as
(8)
A treatment by the use of the method of this paper would proceed by seeking the interpretation in terms of elementary tensors of a record token. If Gi positions are occupied in each of the Y coding subfields of the record token then all X concepts can be reconstructed by selecting a position from each subfield in turn. Additional concepts, however, will also be given, by this process, since
the number of all possible selections, one from each subfield, will in general exceed X. The number will be
(9)
The number of possible codes in the system is given by HY. Each record token divides this total possible number into two portions, one, given by (9), of concepts which will select this token, and one containing all that will reject it. Let a selection be specified. Then its A class will contain all records for which its code is included in the set (9). The probability of this occurrence in complete generality is well known, see Uspensky (15), but will not be used here.
A second selection will divide the entire record collection in an analogous fashion. The two selected classes A1 and A2 will include records in common if documents in the file treat both subjects, or if both codes can be formed from entries in one document. Both cases are covered by the requirement that the code combination for either selection code be contained within the selected class of the other, all those combinations not present in both selection classes being rejected.
The probabilities associated with these events are given by those for occurrence and of joint occurrence of concepts in the material in the file, and hence are in principle computable on the basis of “language statistics.”
Comparison with Wise’s special case is obtained by taking all probabilities as equal and independent and using expected values. In this case the residue class is given by GY for a single selection. All possible classes are given by HY, and hence the ratio of the number of items in the selection class A, to the total number of possible codes in GY/HY=(G/H)Y. In the case of independent selection by M codes this leads to (G/H)YM.
Conclusions
A. Any retrieval system forms a lattice. More precisely the set of record tokens and the set of query tokens, real and potential, form isomorphic lattices.
B. The tokens of either set can be represented as m-dimensional tensors. If separate tensors are devoted to each m-dimensional (or lower) relation in each document, then every tensor in the system will be elementary.
C. Only two methods are available for combining the tensors for the several concepts relating to a single document, ordinary and augmented tensor addition.
D. If the full m-dimensional tensors are combined in either of the two admissible ways, by ordinary or augmented addition, selection will be unique.
E. If combined by augmented addition, searching will be required, and a very large memory capacity, file size, as well. Selection may be by equality or partial ordering.
F. For tensors combined by ordinary summation, only one possible selection relation is available for selecting documents dealing with a subject represented by a query tensor, the lattice partial ordering relation ≥; memory requirements are reduced to one tensor per document but ordering is not possible, so that searching is required.
G. Tensor size may be reduced by (1) restriction of system scope, (2) use of generic rather than specific concepts, (3) disregarding order in relations, and (4) restricting the complexity of relations entered in the system. Each of these devices has a natural interpretation in terms of the tensor model.
H. Great economy in bit requirement is introduced by expressing record and query tensors in coordinatized form, with one tally per coordinate.
I. Coordinatized records combined by augmented addition result in no additional reduction in memory and require searching since ordering is not possible, but yield unique selections, either by equal or inclusion selection.
J. Coordinatized records combined by ordinary addition yield minimal searching length and file requirements but produce false drop-outs. The incidence of false drop-outs is measured by the combinations which can be formed from the coordinates initially entered into the sum.
K. Formulas for calculating drop-out fractions without assuming random coding can be based on “language statistics” appropriate to a given application.
REFERENCES
1. C.J.MALONEY. A Remington Rand retrieval system, American Documentation vol. IX (1958), p. 1–12.
2. KARL F.HEUMANN. Information theory in library and documentation activities, LC Inf. Bull vol. 13, Sept. 27, 1954, Appendix II.
3. R.M.FANO. Information theory and the retrieval of recorded information, in Documentation in Action edited by Shera, Kent, and Perry, 1956.
4. LOUIS N.RIDENOUR. Storage and retrieval of information, Proc. Eastern Joint Computer Conf. Nov. 7–9, 1955, Boston.
5. CALVIN N.MOOERS. Putting probability to work in coding punched cards, 112th Meeting, American Chemical Society, New York, 1947.
6. CARL S.WISE. Generalized punched-card codes for chemical bibliographies, 112th Meeting, American Chemical Society, New York, 1947.
7. A.F.ISBELL. A practical application of a punched-card system utilizing the superposition of codes, 114th Meeting, American Chemical Society, Portland, Oregon, 1948.
8. CLAUDE E.SHANNON. A mathematical theory of communication, Bell System Technical Journal, July 1948, p. 379; Oct. 1948, p. 623.
9. ZELLIG HARRIS. Methods in Structural Linguistics, 1951.
10. BOLINGERS. Visual Morphemes, Language, vol. 22 (1946) pp. 330–340.
11. VICTOR H.YNGVE. The translation of languages by machine, in Information Theory, 3rd London Symposium, Colin Cherry, editor, pp. 195–205.
12. GARRETT BIRKHOFF. What is a lattice? Am. Math. Assoc. Monthly, vol. 50, No. 8 (Oct. 1943), pp. 484–487.
13. F.I.MAUTNER. An extension of Klein’s Erlanger program: Logic as invariant theory, Am. J. Math., vol. 68 (1946), pp. 345–384.
14. C.S.WISE. Mathematical analysis of coding systems, Chapter 20 of Punched Cards, edited by Robert S.Casey and James W.Perry, 1951.
15. J.V.USPENSKY. Elementary Number Theory, McGraw-Hill, New York, 1954.


















